MySQL表的增删改查(进阶)
Posted 来学习的小张
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL表的增删改查(进阶)相关的知识,希望对你有一定的参考价值。
目录
一、数据库约束
约束就是数据库在使用的时候,对于里面能够存的数据提出的要求和限制.
1.1 NULL约束
not null-指示某列不能存储NULL值.

给id这一列设为not null之后,上图中紫色框里的值就变成NO了.
如果尝试往这里插入空值,就会直接报错:

注意:NOT NULL是可以给任意个列来进行设置,不仅仅是这一个列.
1.2 UNIQUE:唯一约束
unique-保证某列的每行必须有唯一的值,即数据唯一.

如果尝试插入重复的值,就会报错.

1.3 DEFAULT:默认值约束
default-规定没有给列赋值时的默认值,即约定一个默认值.
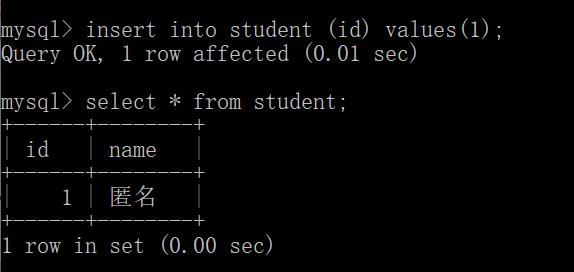
如果没有将名字设置为默认,只插入id的值,此时name就采取了默认值null.

添加名字的默认值约束为匿名:

如果未修改只添加id,name处会显示为null,添加默认值约束之后,此时name处显示为"匿名".
1.4 PRIMARY KEY:主键约束
primary key-NOT NULL和UNIQUE的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
主键约束是最常使用的一个约束,相当于数据的唯一身份标识,类似于身份证号码/手机号码.
对于一个表来说,只能有一个列被指定为主键.

关于主键,典型的用法,就是直接使用1,2,3, 4整数递增的方式来进行表示mysql里面对于这种递增的主键,是有内置支持的,称为"自增主键".
对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1.
create table student(ia int primary key auto_increment,name varchar(50));

当设定好自增主键之后,此时插入的记录,就可以不指定自增主键的值了(直接使用null来表示),交给mysql自行分配即可.
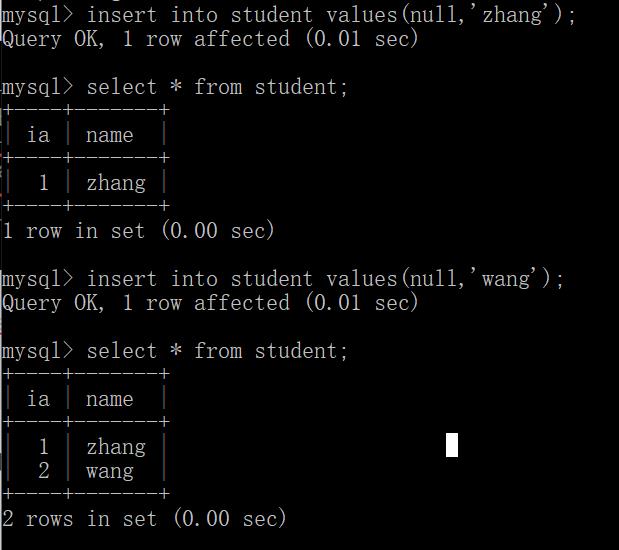
自增主键也可以手动指定id ,一旦指定过之后,后续新插入的数据就都是从8之后来排了.2-8之间的就用不了.再次插入的时候就从8之后开始计数.

1.5 FOREIGN KEY:外键约束
foreign key-保证一个表中的数据匹配另一个表中的值的参照完整性。
外键用于关联其他表的主键或唯一键.
语法:
foreign key (字段名) references (主表)列;
外键约束,针对两张表,进行了关联。
在这里创建两张表:
学生表(id,name,classId)
班级表(classId,name)
学生表依赖了班级表,就把学生表称为"子表",班级表称为"父表".
- 首先创建班级表:
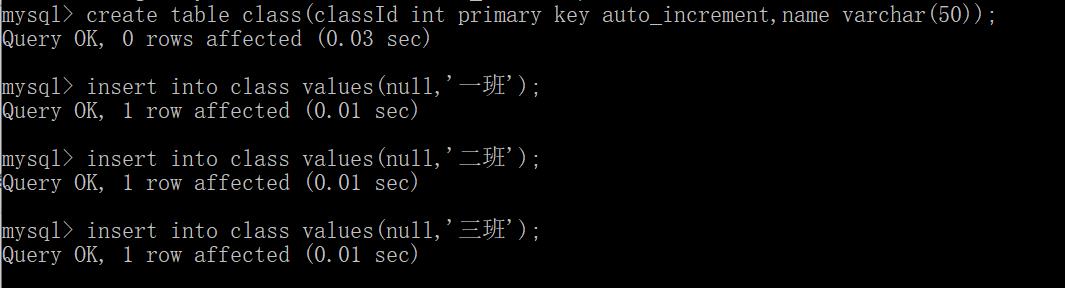
- 然后创建学生表:
create table student(studentId int primary key auto_increment,name varchar(30),classId int,foreign key(classId) references class(classId));
references:叫作(表示依赖关系,当前这个表的classld列就得引用自/依赖于class表的classld这一列)
class(classId):引用的父表的名字叫做class表,引用的父表的列是classld这一列。
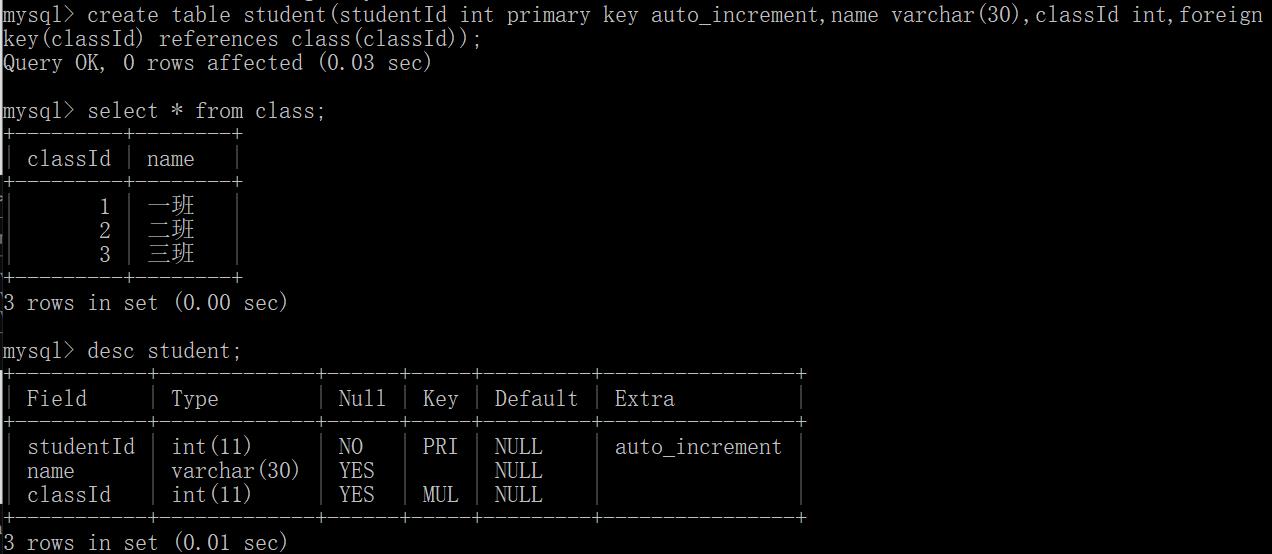
在创建好表之后就可以往student学生表里面插入数据,在插入记录之前, mysql会先拿着这个classld去class表里查一下,看看是否存在,存在才能插入成功。

因为班级classId里面并没有4班,所以下面那条插入不成功。
不仅仅是新增的时候要考虑到外键约束,新增成功的数据如果进行修改,也一样是会存在问题。因为并没有这个班级存在。

student表中的classld是可以重复的,只要是在class表中存在即可。

外键约束,同样也在约束着父表.当父表中的某个记录被子表中依赖着的时候,此时尝试进行删除或者修改,都会失败。

如果有的classId没有在student表中被依赖到,则就可以进行删除。
外键约束的工作原理:
在子表中插入新的记录的时候,就会先根据对应的值,在父表中先查询,查询到之后,才能够执行后续的插入。
这里的查询操作,可能是一个成本较高的操作(比较耗时),外键约束其实要求,父表中被依赖的这一列,必须要有索引,有了索引就能大大的提高查询速度。
1.6 CHECK约束
check-保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
MySQL使用时不报错,但忽略该约束。
drop table if exists test_user;
create table test_user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);
二、表的设计
如何设计数据库,如何设计表?
一个典型的通用的办法:先找出这个场景中涉及到的“实体",然后再来分析"实体之间的关系"。
实体之间的关系
一对一

一对多
1.5中学生和班级的例子。

多对多


可以使用一个关联表来表示两个实体之间的关系。

上表中:学号为1的同学,选了课程编号为1的课程.
课程编号为1的课程,包含了一个学号为1的同学.
张三选了语文课.语文课上有张三.
学号为1的同学,选了课程编号为2的课程.
张三选了数学课.数学课上有张三.
三、 新增
和查询结合在一起的新增操作。把从上一个表中的查询结果,作为下一个表要插入的数据。
首先先创建一个A表:

然后将A表的记录插入到B表中:

在红框中的这个语句中,就会先执行查找.针对查找到的每个结果,都执行插入操作,插入到B中.
我们需要保证,从A中查询出来的结果的列数和类型,和B表匹配.
如果B表的列的顺序和A表不匹配,只要保证A的查询结果的列的顺序和B对应即可。如:
insert into B select id,name from A;
另外,还可以给后面的select 指定一些其他的条件/排序/limit/去重…
插入的实际就是select执行结果的临时表。要保证插入之后数据是合理的。
四、查询
4.1 聚合查询
把多个行的数据进行了关联操作。
4.1.1聚合函数
| 函数 | 说明 |
|---|---|
| count([distinct]) expr | 查询到的数据的数量,null值不会记录到count中 |
| sum([distinct] expr) | 返回查询到的数据的总和,不是数字没有意义 |
| avg([distinct] expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| max([distinct] expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| min([distinct] expr) | 返回查询到的数据的最小值,不是数字没有意义 |
上表中括号里面写的是列名或者表达式。
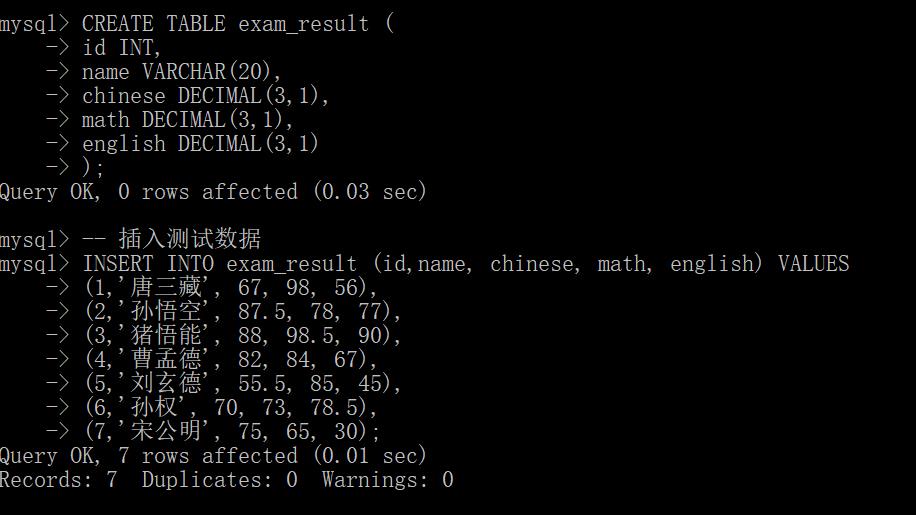
count
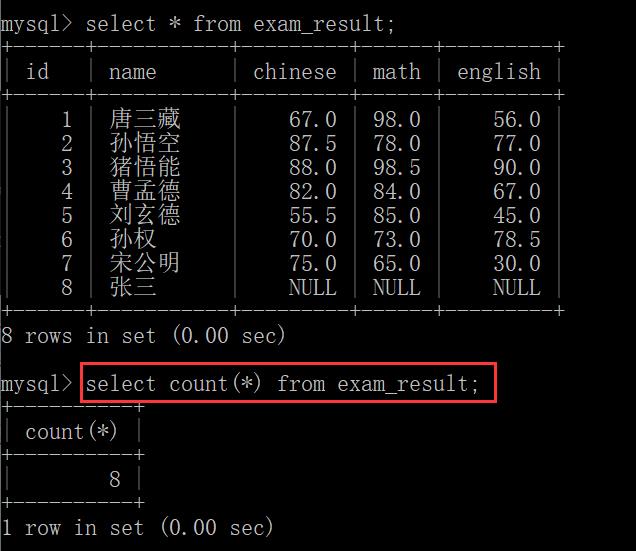
就相当于是针对select * from exam_result;的结果集合进行计算行数.
count这里的参数不一定非要写做*也可以指定某个列,NULL这样的值不会记录到count中。

- sum
sum进行求和. (相对于excel里的求和),把这一列的若干行,进行相加。
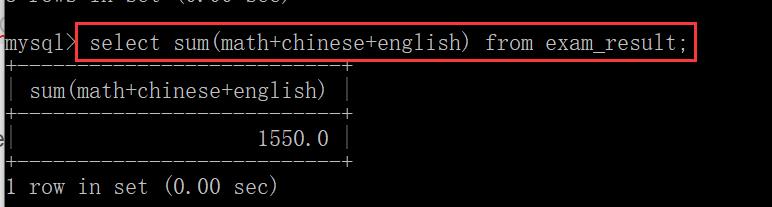
sum这个操作只能针对数字进行运算,不能针对字符串来进行。
- avg
求三科的平均分:
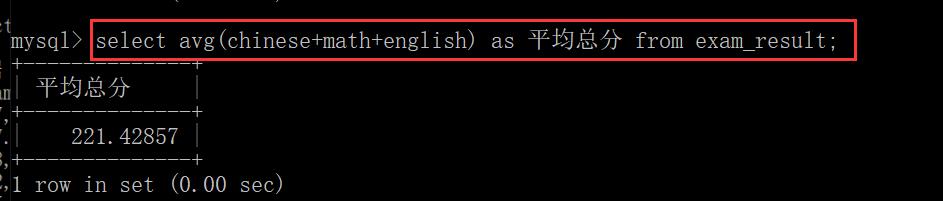
计算avg的时候, NULL这样的记录是不计入其中的,不会影响到平均值的结果。

- max
求数学成绩里面的最高分:

- min
聚合函数,还可以搭配 where字句来使用,可以基于条件进行筛选,把筛选结果,在进行聚合。
返回 > 70 分以上的数学最低分:

4.1.2 分组操作group by
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中.
根据行的值,对数据进行分组.把值相同的行都归为一组.


查询每个角色的最高工资、最低工资和平均工资:

一个sql的执行过程,具体的执行顺序,和书写的顺序并不完全一致。这里先执行group by,把这里的查询结果进行分组,再根据分组,分别来执行每个组的聚合函数。
4.1.3 having 过滤
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,就需要使用having。
group by是可以使用where.只不过 where 是在分组之前执行.如果要对分组之后的结果进行条件筛选,就需要使用having 。
把沙和尚去掉之后,在按照角色进行分类,求平均值:

求每种角色,平均薪资,只保留平均薪资1w以下:

4.2 联合查询
实际开发中往往数据来自不同的表,所以需要多表联合查询。即把多个表的记录往一起合并,一起进行查询。联合查询又叫做多表查询。
多表查询是对多张表的数据取笛卡尔积:笛卡尔积是针对任意两张表之间进行运算的。
笛卡尔积的运算过程:
先拿第一张表的第一条记录和第二张表的每个记录分别组合,得到一组新的记录。继续那第一张表的第二条记录,重复刚才的记录。直到第一张表的记录被组合完为止。
如表a和表b:
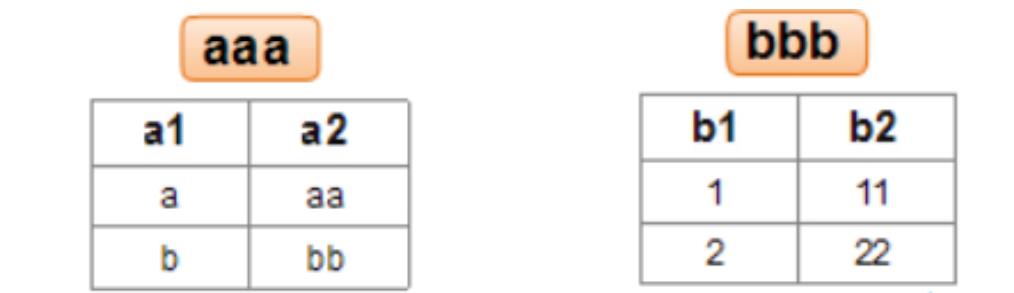
进行笛卡尔积之后:
| a | aa | 1 | 11 |
|---|---|---|---|
| a | aa | 2 | 22 |
| b | bb | 1 | 11 |
| b | bb | 2 | 22 |
针对a、b两张表,计算笛卡尔积,此时笛卡尔积的列数就是a的列数+b的列数.笛卡尔积的行数就是a的行数*b的行数.
在SQL中进行笛卡尔积,最简单的做法,就是直接select, from后面跟上多个表名,表名之间使用逗号分割。
例:
select * from student,class;
笛卡尔积是一个单纯无脑的排列组合,这里的组合结果不一定都是有意义的数据,这里可以使用where进行条件筛选,保留我们需要的记录。
select * from student,class where student.classId = class.classId;
创建四张表并向表中加入数据:
drop table if exists classes;
drop table if exists student;
drop table if exists course;
drop table if exists score;
create table classes (id int primary key auto_increment, name varchar(20), `desc` varchar(100));
create table student (id int primary key auto_increment, sn varchar(20), name varchar(20), qq_mail varchar(20) ,
classes_id int);
create table course(id int primary key auto_increment, name varchar(20));
create table score(score decimal(3, 1), student_id int, course_id int);
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),
-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);
查询每张表:


4.2.1 内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
(1)查询许仙的成绩:
select student.name,score.score from student,score where student.id = score.student_id and student.name = '许仙';

select student.name,score.score from student join score on student.id = score.student_id and student.name = '许仙';

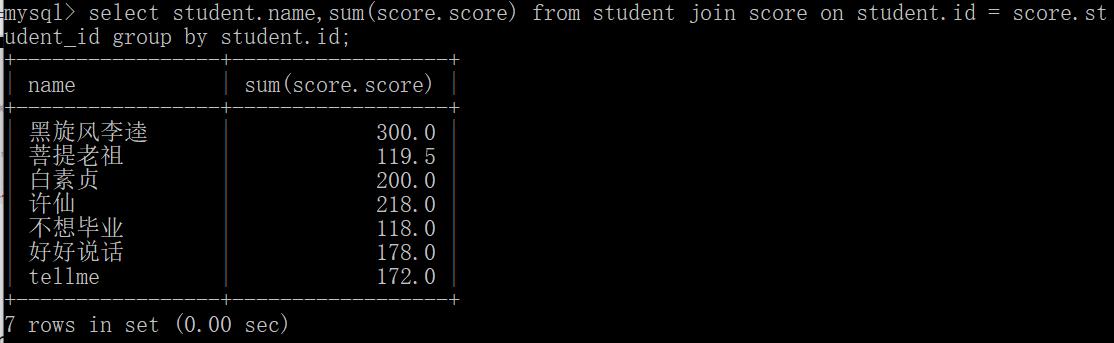
(2)查询所有同学的总成绩,及同学的个人信息:
select student.name,sum(score.score) from student,score where student.id = score.student_id group by student.id;

select student.name,sum(score.score) from student join score on student.id = score.student_id group by student.id;
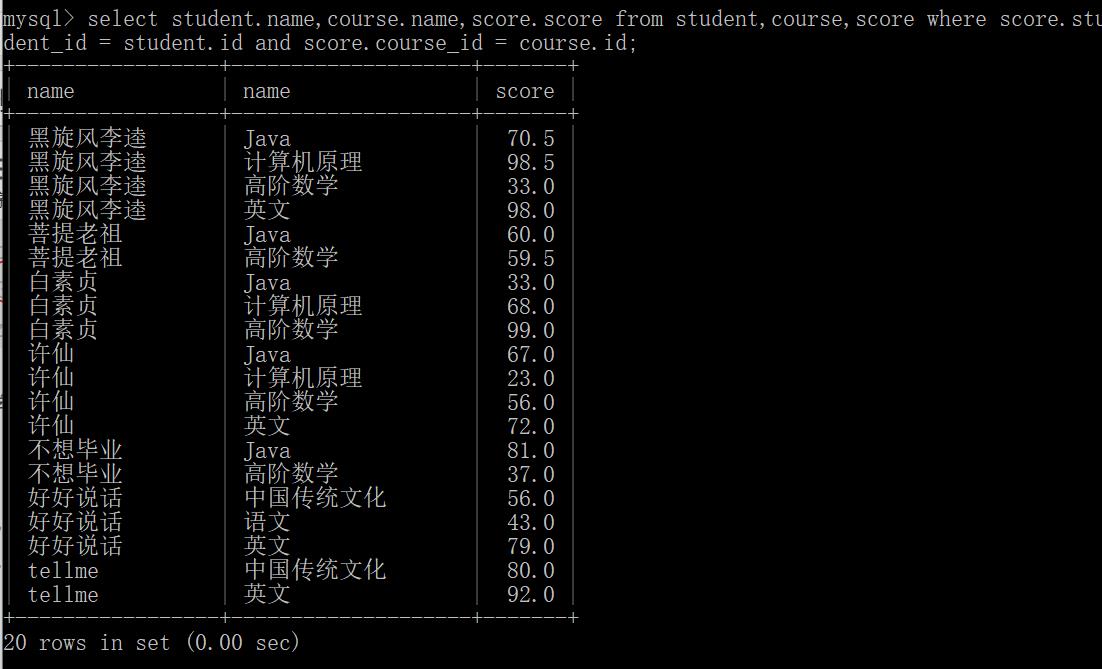
(3)查询所有同学的成绩,及同学的个人信息:
select student.name,course.name,score.score from student,course,score where score.student_id = student.id and score.course_id = course.id;
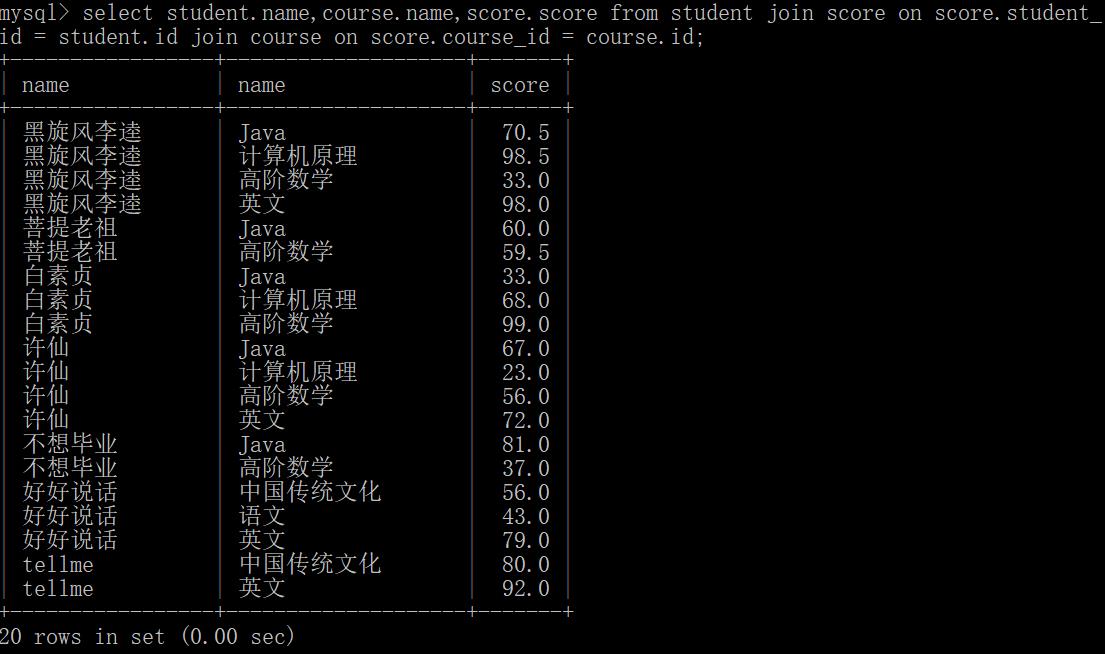
select student.name,course.name,score.score from student join score on score.student_id = student.id join course on score.course_id = course.id;
4.2.2 外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
--左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
例:创建两张表学生表和分数表:
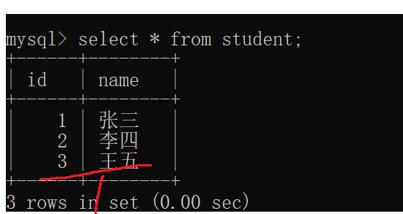

内连接里的记录就只是包含两个表中同时拥有的记录:
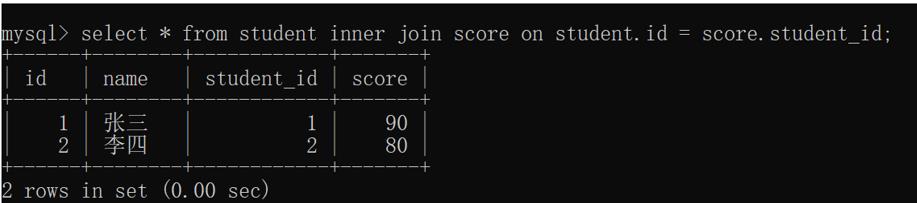
左外连接就是以左侧表为主.左侧表中的每个记录都在左外连接中有体现.

右外连接就是以右侧表为主.右侧表的每个记录都在结果中有体现。

4.2.3 自连接
自连接是指在同一张表连接自身进行查询。就是把自己和自己进行笛卡尔积。
自连接的本质:是把行和行之间的比较条件,转换成列和列。
SQL指定条件,都是按照列和列之间进行指定的。
自连接的关键就是把行转换成列。
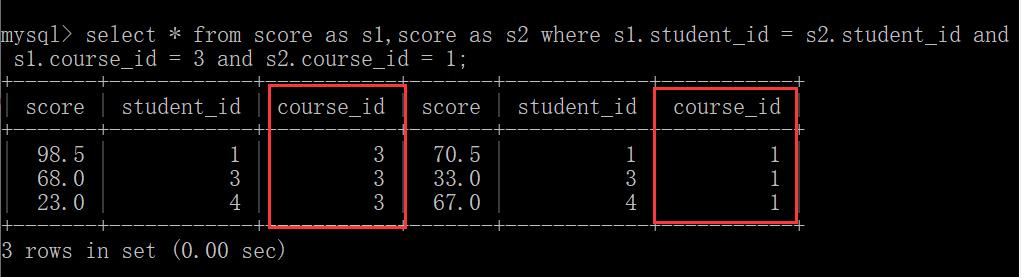
如:显示所有“计算机原理”成绩比“Java”成绩高的成绩信息。

从上表中可看出Java和计算机原理的课程Id分别为1和3。

此时,我们可以看出它是行和行之间的比较,要解决上述问题,就要将它转换为列与列之间的比较,这是,就可以用到自连接。
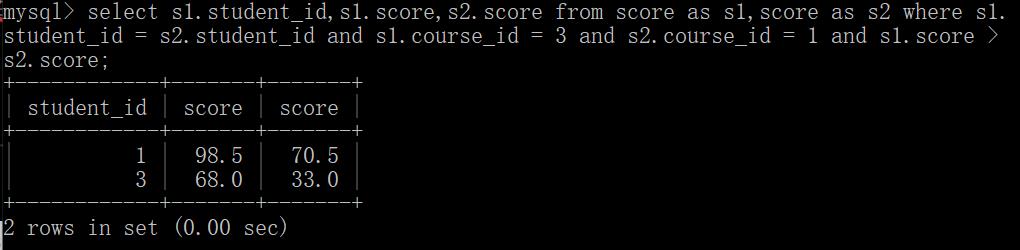
在进行自连接之后,会出现很多无效数据,为了能够更好的进行比较,再加上一些筛选条件,比如,就让s1的课程id只保留3的记录,就让s2的课程id只保留1的记录。
将目录进行简化:
4.2.4 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
子查询就是把拆分好的代码给合并成一个。
- 单行查询:返回一行记录的子查询
如:查询与“不想毕业” 同学的同班同学:
先根据该同学的名字找到其班级Id

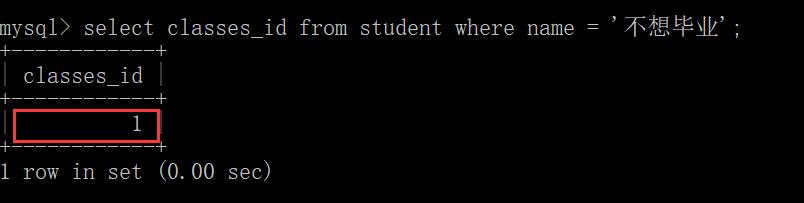
找到“不想毕业”同学的班级id为1,则他就是1班的同学。然后再通过其班级id找到他们班上都有哪些同学:

也可以将这两行sql字句写成合并的sql:
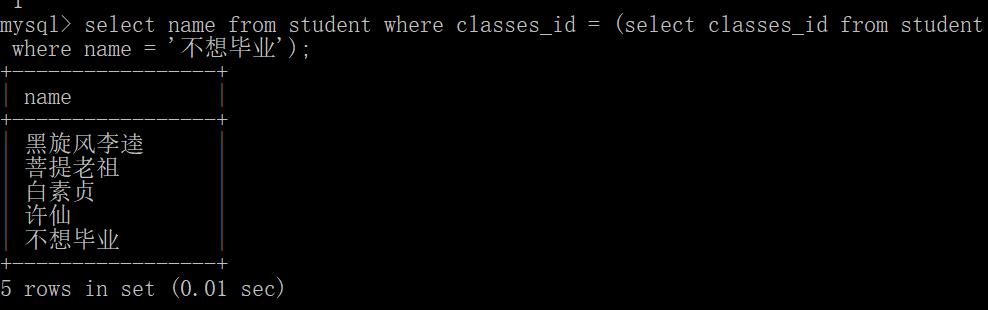
- 多行子查询:返回多行记录的子查询
有的时候子查询可能会查询出多条记录,就不能直接使用=,可能需要用到in这样的一些操作。
如:查询“语文”或“英文”课程的成绩信息
先根据语文和英语找到对应的课程id,再根据课程id找到对用的成绩信息:


同样,也可以把这两条sql合并成一条sql:

4.2.5 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致(通过union把两个sql的查询结果给合并到一起,合并的前提是两个sql查询的列得是对应的)。
- union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
如:查询id小于3,或者名字为“英文”的课程:

此处的union不一定针对同一张表。
上面的写法也可以用or来代替:

union操作会自动的进行去重,union all是不会去重。 - union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
如:查询id小于3,或者名字为“Java”的课程:

以上。
以上是关于MySQL表的增删改查(进阶)的主要内容,如果未能解决你的问题,请参考以下文章