一个框架统一Siamese自监督学习,清华商汤提出简洁有效梯度形式,实现SOTA...
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个框架统一Siamese自监督学习,清华商汤提出简洁有效梯度形式,实现SOTA...相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
来自清华大学、商汤科技等机构的研究者们提出一种简洁而有效的梯度形式——UniGrad,不需要复杂的 memory bank 或者 predictor 网络设计,也能给出 SOTA 的性能表现。
当下,自监督学习在无需人工标注的情况下展示出强大的视觉特征提取能力,在多个下游视觉任务上都取得了超过监督学习的性能,这种学习范式也因此被人们广泛关注。
在这股热潮中,各式各样的自监督学习方法不断涌现,虽然它们大多都采取了孪生网络的架构,但是解决问题的角度却差异巨大,这些方法大致可以分为三类:以 MoCo、SimCLR 为代表的对比学习方法,以 BYOL、SimSiam 为代表的非对称网络方法,和以 Barlow Twins、VICReg 为代表的特征解耦方法。这些方法在对待如何学习特征表示这个问题上思路迥异,同时由于实际实现时采用了不同的网络结构和训练设置,研究者们也无法公平地对比它们的性能。
因此,人们自然会产生一些问题:这些方法之间是否存在一些联系?它们背后的工作机理又有什么关系?更进一步的,具体是什么因素会导致不同方法之间的性能差异?
为此,来自清华大学、商汤科技等机构的研究者们提出一个统一的框架来解释这些方法。相较于直接去比较它们的损失函数,他们从梯度分析的角度出发,发现这些方法都具有非常相似的梯度结构,这个梯度由三部分组成:正梯度、负梯度和一个平衡系数。其中,正负梯度的作用和对比学习中的正负样本非常相似,这表明之前提到的三类方法的工作机理其实大同小异。更进一步,由于梯度的具体形式存在差异,研究者通过详细的对比实验分析了它们带来的影响。结果表明,梯度的具体形式对性能的影响非常小,而关键因素在于 momentum encoder 的使用。

论文链接:https://arxiv.org/pdf/2112.05141.pdf
在这个统一框架的基础上,研究者们提出了一种简洁而有效的梯度形式——UniGrad。UniGrad 不需要复杂的 memory bank 或者 predictor 网络设计,也能给出 SOTA 的性能表现。在多个下游任务中,UniGrad 都取得了不错的迁移性能,而且可以非常简单地加入其它增强技巧来进一步提升性能。
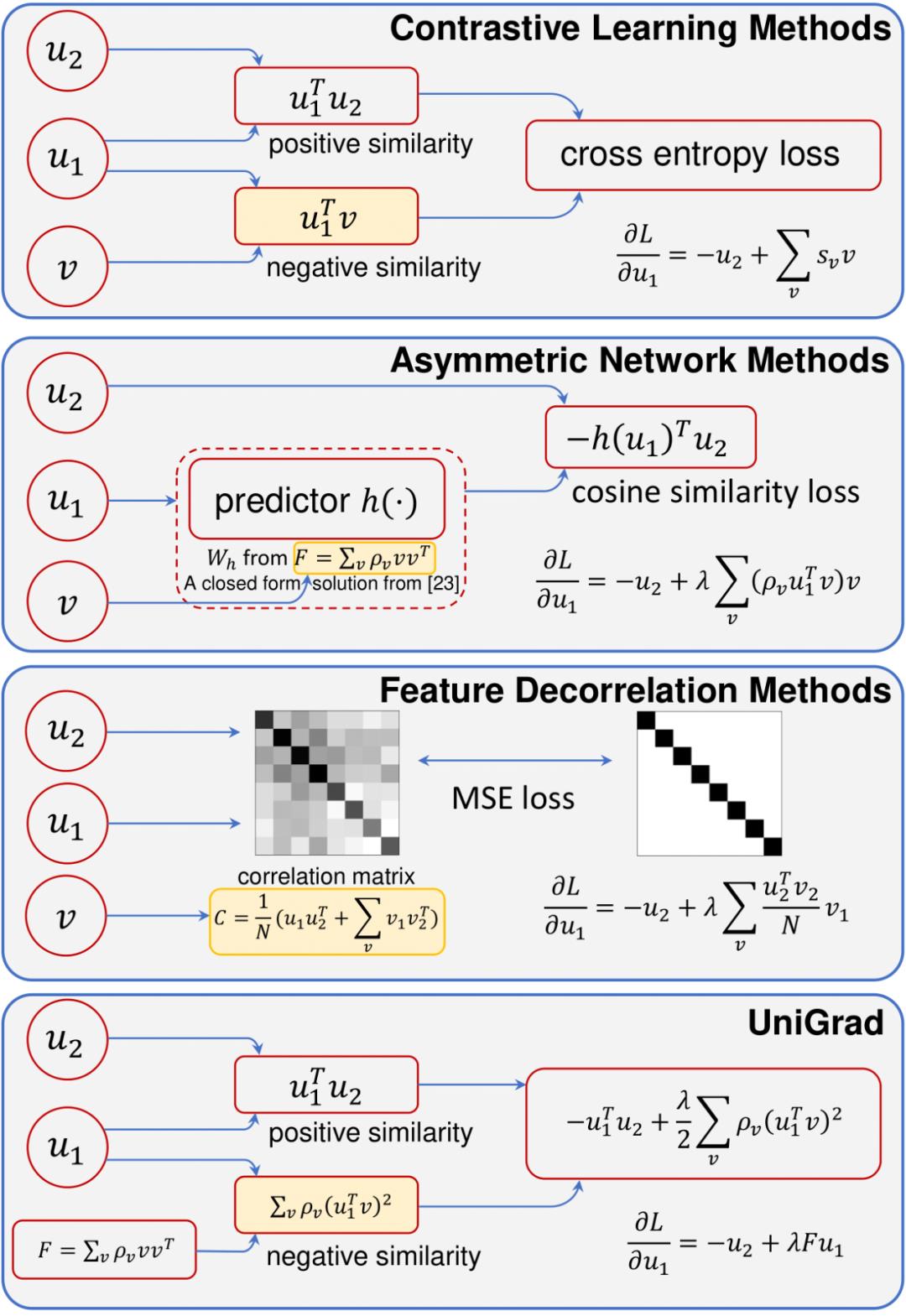
图 1 三类自监督方法与 UniGrad 的对比
统一框架
本节将分析不同方法的梯度形式,首先给出三类方法各自的梯度形式,然后归纳其中的共性结构。从梯度的角度读者也可以更好地理解不同类型的方法是如何工作的。为了方便表述,作者用u表示当前样本特征, v表示其它样本特征,添加下标 ,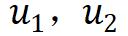 表示不同的 augmented view,添加上标 ,
表示不同的 augmented view,添加上标 ,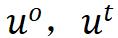 表示孪生网络中 online 或者 target 分支产生的特征。
表示孪生网络中 online 或者 target 分支产生的特征。
对比学习方法
对比学习方法希望当前样本 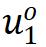 拉近与正样本
拉近与正样本 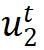 的距离,提升与负样本
的距离,提升与负样本  的距离,一般会使用以下的 InfoNCE Loss:
的距离,一般会使用以下的 InfoNCE Loss:

具体实现时,两类代表性方法 MoCo 和 SimCLR 有许多差异:MoCo 使用了 momentum encoder 作为 target branch 的编码器,而 SimCLR 让 target branch 与 online branch 共享参数;MoCo 使用 memory bank 来存储负样本,而 SimCLR 使用当前 batch 中其它样本作为负样本。
通过对 SimCLR 梯度的略微化简(关闭 target branch 的梯度反传,不会影响最终性能),对比学习方法的梯度可以统一成下面的形式:
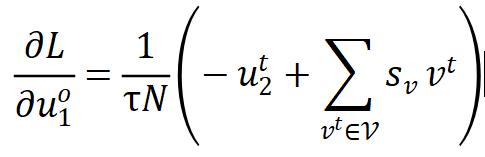
在这个式子中,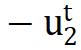 的作用是将正样本拉近,
的作用是将正样本拉近,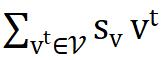 的作用是将负样本推离,因此作者将这两项分别称为正梯度和负梯度。
的作用是将负样本推离,因此作者将这两项分别称为正梯度和负梯度。
非对称网络方法
非对称网络方法只使用正样本来学习特征,并且通过非对称网络的设计来避免平凡解。这类方法一般会在 online branch 后增加一个 predictor 网络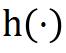 ,同时关闭 target branch 的梯度反传,最终使用下面的损失函数
,同时关闭 target branch 的梯度反传,最终使用下面的损失函数

这类方法中,作为代表的 BYOL 和 SimSiam 非常相似,唯一的差异就是是否使用 momentum encoder。虽然这类方法表现出非常优异的性能,人们对它们的工作原理却所知甚少。最近 DirectPred 这篇文章从网络优化的动态过程出发对它们做了初步的解释,这篇工作观察到 predictor 网络的特征空间会逐渐与特征的相关性矩阵的特征空间对齐,基于此,DirectPred 提出了 predictor 网络的一种解析解。在此工作的基础上,作者进一步展示出非对称网络方法与其它方法的联系,特别地,它们的梯度可以推导为
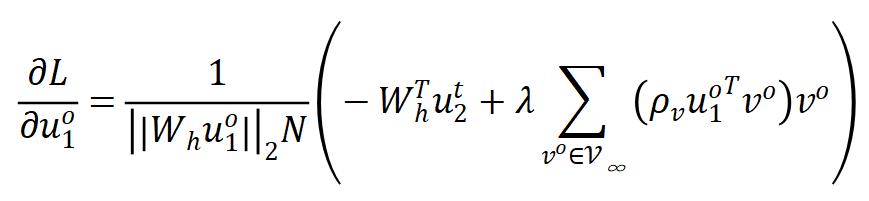
其中  是 predictor 网络的解析解。可以看到,上式同样主要有两个部分:
是 predictor 网络的解析解。可以看到,上式同样主要有两个部分: 是正梯度,
是正梯度,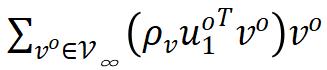 是负梯度。
是负梯度。
粗看起来这个结果非常反直觉:损失函数中没有使用负样本,但是梯度中却出现了负梯度。实际上,这些负样本来自于 predictor 在优化过程中学习到的信息。根据 DirectPred 的结论,predictor 的特征空间会和相关性矩阵的特征空间逐渐对齐,因此 predictor 在训练过程中很可能会将相关性矩阵的信息编码到网络参数中,在反传时,这些信息就会以负样本的形式出现在梯度中。
特征解耦方法
特征解耦方法旨在减小各特征维度之间的相关性来避免平凡解。由于不同工作采用的损失函数在形式上差异很大,作者对它们分别进行讨论。
Barlow Twins 采取如下损失函数:
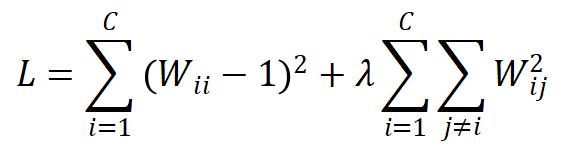
其中 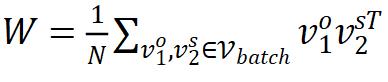 是两个 augmented view 之间的相关性矩阵。该损失函数希望相关性矩阵上的对角线元素接近 1,而非对角线元素接近 0。
是两个 augmented view 之间的相关性矩阵。该损失函数希望相关性矩阵上的对角线元素接近 1,而非对角线元素接近 0。
该损失函数的梯度形式为:
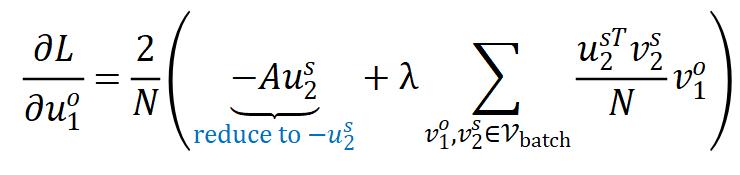
作者首先将第一项替换为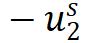 ,同时,原始的 Barlow Twins 对特征采取了 batch normalization,作者将其替换为
,同时,原始的 Barlow Twins 对特征采取了 batch normalization,作者将其替换为  normalization,这些变换都不会影响到最终性能。
normalization,这些变换都不会影响到最终性能。
VICReg 在 Barlow Twins 的基础上做了一些改动,为了去掉加在特征上的 batch normalization,它采取了如下损失函数:
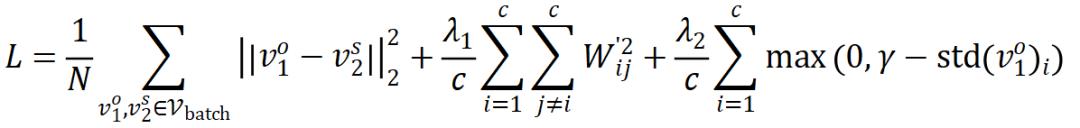
其对应的梯度形式为
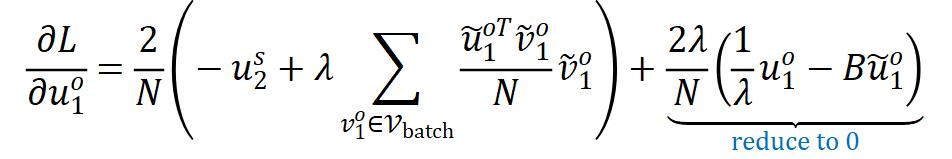
通过对特征施加 normalization,作者可以去掉最后一项而不影响其性能。这样,特征解耦方法的梯度形式就能统一为:
normalization,作者可以去掉最后一项而不影响其性能。这样,特征解耦方法的梯度形式就能统一为:
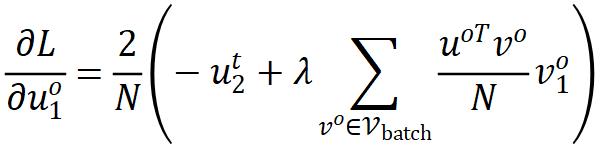
该梯度形式依然包含两项: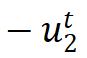 是正梯度,
是正梯度,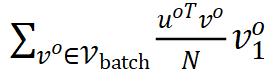 组成负梯度,它们分别来自相关性矩阵中的对角线和非对角线元素。因此,特征解耦方法本质上和其它两类方法非常相似,它们只是在损失函数中将正负样本用不同的形式组合起来了。
组成负梯度,它们分别来自相关性矩阵中的对角线和非对角线元素。因此,特征解耦方法本质上和其它两类方法非常相似,它们只是在损失函数中将正负样本用不同的形式组合起来了。
统一形式
对比以上三类方法的梯度形式,作者发现它们都具有相似的结构:
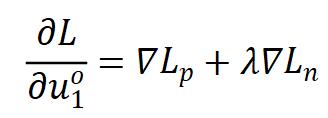
其中, 对应正样本的特征,
对应正样本的特征,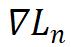 是负样本特征的加权平均,
是负样本特征的加权平均, 是平衡两者的系数,这种相似的结构说明三类方法的工作机理非常接近。
是平衡两者的系数,这种相似的结构说明三类方法的工作机理非常接近。
性能对比
尽管结构相似,不同方法的具体梯度形式依然存在区别,而且 target branch 的类型、负样本集合的构成也都不一样,本节将通过对比实验来探究对最终性能的主要影响因素。
梯度形式
为了方便对比,作者首先在各类方法内部进行化简和对比,最终再对比不同方法。完整的实验结果如表 1 所示。

表 1 不同类型方法性能比较
表 1(ab) 展示了对比学习方法的结果。为了保持公平比较,SimCLR 采用了 momentum encoder,在这样的情况下表现出了和 MoCo 相同的性能。在这里,SimCLR 只用了当前 batch 作为负样本集合,MoCo 采用了 memory bank 作为负样本集合,这说明在合适的训练设置下,大量的负样本并不是必须的。
表 1(c-e) 展示了非对称网络方法的结果。由于带有 momentum encoder 的 SimSiam 就是 BYOL,这里只展示了 BYOL 的结果。表 1(cd) 分别是原始的 BYOL 和 DirectPred 形式的 BYOL,两者的性能相当,这也和 DirectPred 的结论一致。表 1(e) 将正样本梯度中的 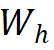 替换为单位阵而没有影响性能,因此,非对称网络方法的梯度形式可以统一成表 1(e) 中的形式。
替换为单位阵而没有影响性能,因此,非对称网络方法的梯度形式可以统一成表 1(e) 中的形式。
表 1(f-j) 展示了特征解耦方法的结果。对 Barlow Twins 来说,表 1(g) 将正梯度中的矩阵 A 替换为单位阵,表 1(h) 将特征的 batch normalization 替换为  normalization,这些替换都不会导致性能下降;对 VICReg 来说,表 1(j) 去掉梯度中最后一项,同时加上
normalization,这些替换都不会导致性能下降;对 VICReg 来说,表 1(j) 去掉梯度中最后一项,同时加上 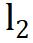 normalization,这对性能几乎没有影响。最后,比较表 1(hj),它们唯一的差异在于负样本系数的计算方式,但是性能上却差异很小,所以特征解耦方法的梯度形式可以统一成表 1(j) 中的形式。
normalization,这对性能几乎没有影响。最后,比较表 1(hj),它们唯一的差异在于负样本系数的计算方式,但是性能上却差异很小,所以特征解耦方法的梯度形式可以统一成表 1(j) 中的形式。
最后,作者对比了三类方法的梯度,即表 1(bej) 的结果。在梯度结构中,正梯度的形式已经统一,平衡系数会通过搜索保持最优,唯一的差异就是负梯度形式,实验结果表明不同的负梯度形式性能非常接近。还值得注意的是,表 1(ej) 的负样本形式非常相似,区别在于表 1(e) 使用了之前所有样本构成的负样本集合,表 1(j) 只使用了当前 batch 集合,这也说明了负样本集合的构建在自监督学习中不是最关键的因素。
Target Branch 类型
之前为了公平对比,作者对各类方法都使用了 momentum encoder,现在来研究不同类型的 target branch 对最终结果的影响,实验结果如表 2 所示。

表 2 Target branch 类型影响
如果 target branch 采取 stop-gradient 的类型,三类方法都表现出类似的性能,这和之前的结论是一致的;如果 target branch 采取 momentum-encoder 的类型,三类方法都能在之前的基础上提升大约 2 个点,这说明 momentum encoder 对不同的方法都能带来提升。
更进一步的,作者观察到一些方法里只有正梯度利用到了 momentum encoder 的特征,于是他们尝试对三类方法都只在正梯度中采用 momentum encoder 的特征。实验结果表明这和全部梯度采用 momentum encoder 具有类似的性能表现。这说明对于自监督学习来说,一个缓慢更新的一致的更新目标是非常重要的。
最终方法
基于上述的统一框架,作者提出了一种简洁有效的自监督方法(UniGrad):
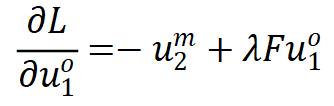
其中 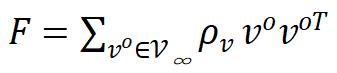 是相关性矩阵的滑动平均。UniGrad本质上就是表 1(e) 的梯度形式,这种梯度不需要额外的 memory bank,也不需要设计额外的 projector,实验表明无论是 linear evaluation 还是 transfer learning,它都能够取得 SOTA 的实验性能。
是相关性矩阵的滑动平均。UniGrad本质上就是表 1(e) 的梯度形式,这种梯度不需要额外的 memory bank,也不需要设计额外的 projector,实验表明无论是 linear evaluation 还是 transfer learning,它都能够取得 SOTA 的实验性能。
图 2 从多个衡量指标的角度展示了不同方法的优化过程。可以看到,不同方法的优化曲线没有明显的差异,这也说明了该方法和之前方法有着类似的工作机制。

表 3 和表 4 展示了 UniGrad 的具体结果。UniGrad 自身能够取得和之前方法相当的性能,并且能够简单地将之前的数据增强方式融合进来,进一步提升性能。在更长轮数的训练中,UniGrad 也能取得不错的性能。
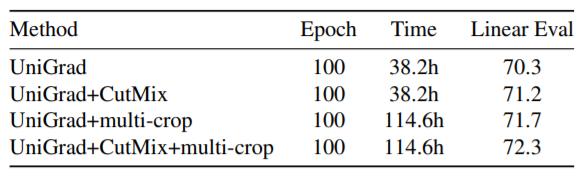
表 3 UniGrad 与数据增强方法结合的性能
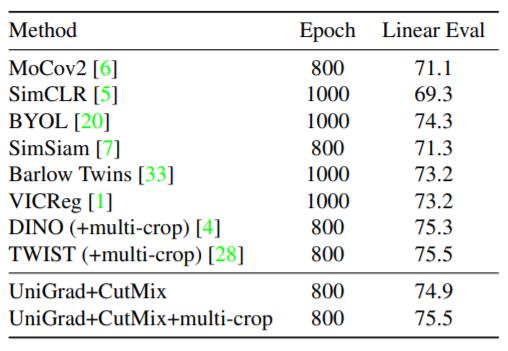
表 4 长轮数下与之前方法的对比
更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!
© THE END
投稿或寻求报道微信:MaiweiE_com
GitHub中文开源项目《计算机视觉实战演练:算法与应用》,“免费”“全面“”前沿”,以实战为主,编写详细的文档、可在线运行的notebook和源代码。
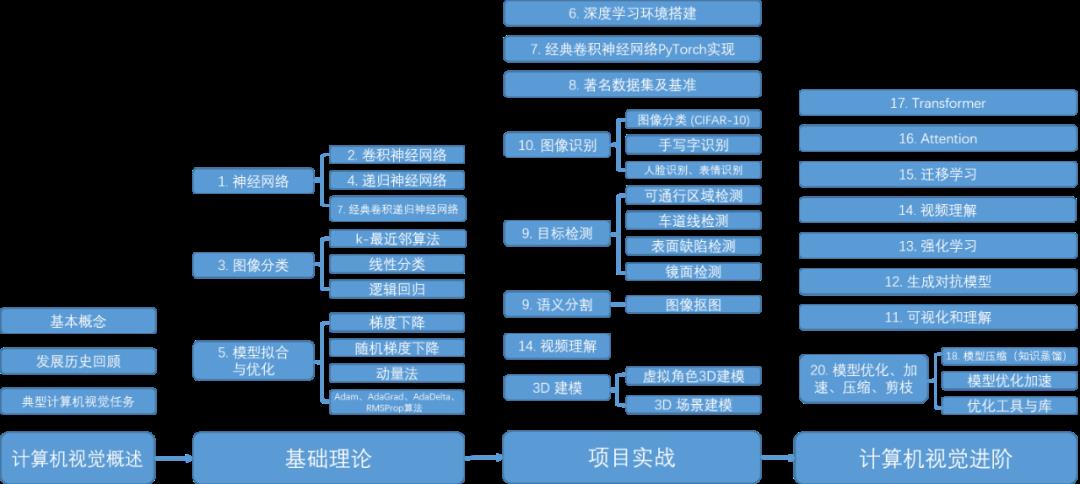
项目地址 https://github.com/Charmve/computer-vision-in-action
项目主页 https://charmve.github.io/L0CV-web/
推荐阅读
(更多“抠图”最新成果)
迈微AI研习社
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve

如果觉得有用,就请点赞、转发吧!
以上是关于一个框架统一Siamese自监督学习,清华商汤提出简洁有效梯度形式,实现SOTA...的主要内容,如果未能解决你的问题,请参考以下文章
2017年计算语义相似度最新论文,击败了siamese lstm,非监督学习