SIGIR‘21|SGL基于图自监督学习的推荐系统
Posted mishidemudong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SIGIR‘21|SGL基于图自监督学习的推荐系统相关的知识,希望对你有一定的参考价值。
本篇文章主要介绍王翔、何向南老师团队在SIGIR2021上发表的文章SGL,Self-supervised Graph Learning for Recommendation[1]。这篇文章提出了一种应用于用户-物品二分图推荐系统的图自监督学习框架。核心的思想是,对输入的二分图,做结点和边的dropout进行数据增强,增强后的图可以看做原始图的子视图;在子视图上使用任意的图卷积神经网络,如LightGCN[2]来提取结点的表征,对于同一个结点,多个视图就能形成多种表征;然后借鉴对比学习[5]的思路,构造自监督学习任务,即:最大化同一个结点不同视图表征之间的相似性,最小化不同结点表征之间的相似性;最后对比学习自监督任务和推荐系统的监督学习任务联合起来,构成多任务学习的范式。
文章的方法很简洁,这种思想和陈丹琦的工作,基于对比学习的句子表征SimCSE[4]有异曲同工之处,值得借鉴到实际的图表征学习中。相应的代码也开源在:https://github.com/wujcan/SGL[3]。感兴趣的同学可以去阅读一下。

欢迎关注我的公众号”蘑菇先生学习记”,更快更及时地获取关于推荐系统的前沿进展!
1.Motivation
解决目前基于user-item二分图表征学习的推荐系统面临的两大核心问题:
- 长尾问题。high-degree高度的结点对表征学习起了主导作用,导致低度的结点,即长尾的item的学习很困难。
- 鲁棒性问题。交互数据中包含着很多噪声。而基于邻域结点汇聚的范式,会扩大”噪声观测边”的影响力,导致最终学习的表征受到噪声交互数据的影响比较大。
因此,作者提出了图自监督学习的方法SGL(Self-supervised Graph Learning),来提高基于二分图推荐的准确性和鲁棒性。
核心的思想是,在传统监督任务的基础上,增加辅助的自监督学习任务,变成多任务学习的方式。具体而言,同一个结点先通过数据增强 (data augmentation)的方式产生多种视图(multiple views),然后借鉴对比学习(contrastive learning)的思路,最大化同一个结点不同视图表征之间的相似性,最小化不同结点表征之间的相似性,实际上是一个self-discrimination的任务。对于数据增强,对同一个结点,为了产生不同的视图,使用了3种方式,从不同维度来改变图的结构。包括,结点维度的node dropout;边维度的edge dropout(能够降低高度结点的影响力);图维度的random walk。这种图结构的扰动和数据增强操作,能够提高模型对于噪声交互的鲁棒性。
SGL方法和具体使用的图模型无关,可以和任意的图模型搭配使用。作者在LightGCN[2]的基础上,来引入SGL图自监督学习方法。通过对比学习范式的理论分析,阐明了SGL能够有助于挖掘困难负样本(hard negatives),不仅提高了准确性,也能够提高训练过程收敛速度。通过在三个数据集上的经验性分析,也能够阐明这个SGL的有效性,尤其是在长尾items的推荐准确性以及对于噪声交互数据的鲁棒性。
2.Solution
开篇已经对文章的方法做了总结,即:先做数据增强操作,来产生多种视图;然后通过图编码的方式形成不同视图下的结点表征,并在这些视图表征上做对比学习。最后将对比学习辅助目标和传统的监督目标融合在一起,形成多目标学习的范式。
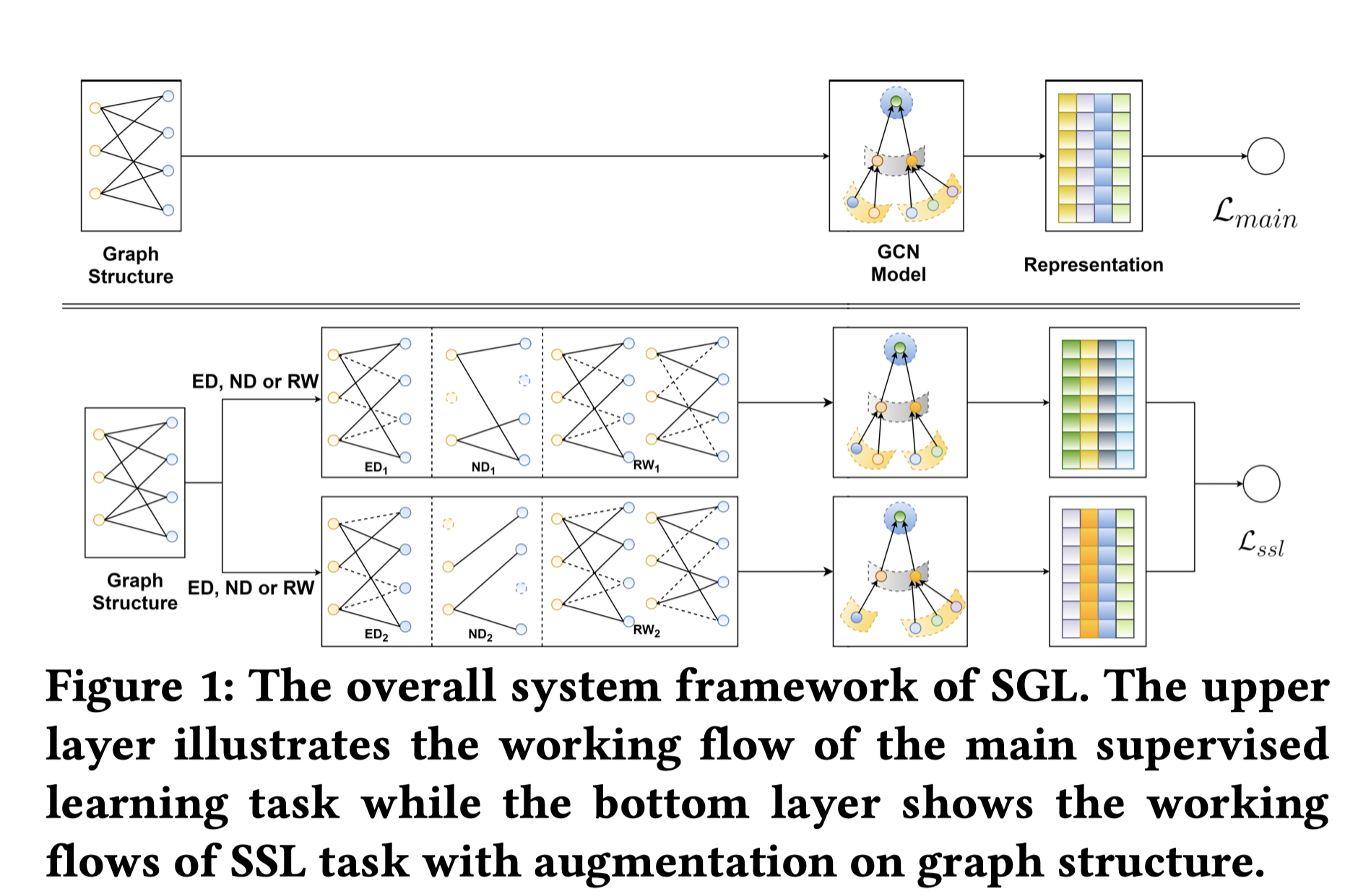
2.1 Data Augmentation on Graph Structure
先看一下GNN进行结点编码的范式:
Z(l)1=H(Z(l−1)1,G),
输入:上一层的结点表征向量和原始图,输出:该层的结点表征向量。具体的卷积步骤,可以参考LightGCN[2]的做法,这里不做过多赘述。
在本文中,要做个小变化,即:原始图G
要进行dropout操作s(G),要做两次,形成两个子视图。形式化地,
Z(l)1=H(Z(l−1)1,s1(G)),Z(l)2=H(Z(l−1)2,s2(G)),
下标1和2代表两次完全独立的dropout操作,形成2个视图s1(G)和s2(G),再各自进行卷积操作得到结点的表征Z(l)1,Z(l)2
。具体的dropout操作包括如下三种:
-
Node Dropout:以一定的概率丢掉结点以及和该结点相连的边。
s1(G)=(M′⊙V,E),s2(G)=(M′′⊙V,E)
其中,M′,M′′∈0,1|V|是掩码向量,通过伯努利分布m∼Bernoulli(ρ)来随机生成,其中ρ是dropout概率。M′,M′′
-
完全独立。
-
Edge Dropout:以一定的概率丢掉部分边。
s1(G)=(V,M1⊙E),s2(G)=(V,M2⊙E)
-
类似Node Dropout,只不过对边做的。 -
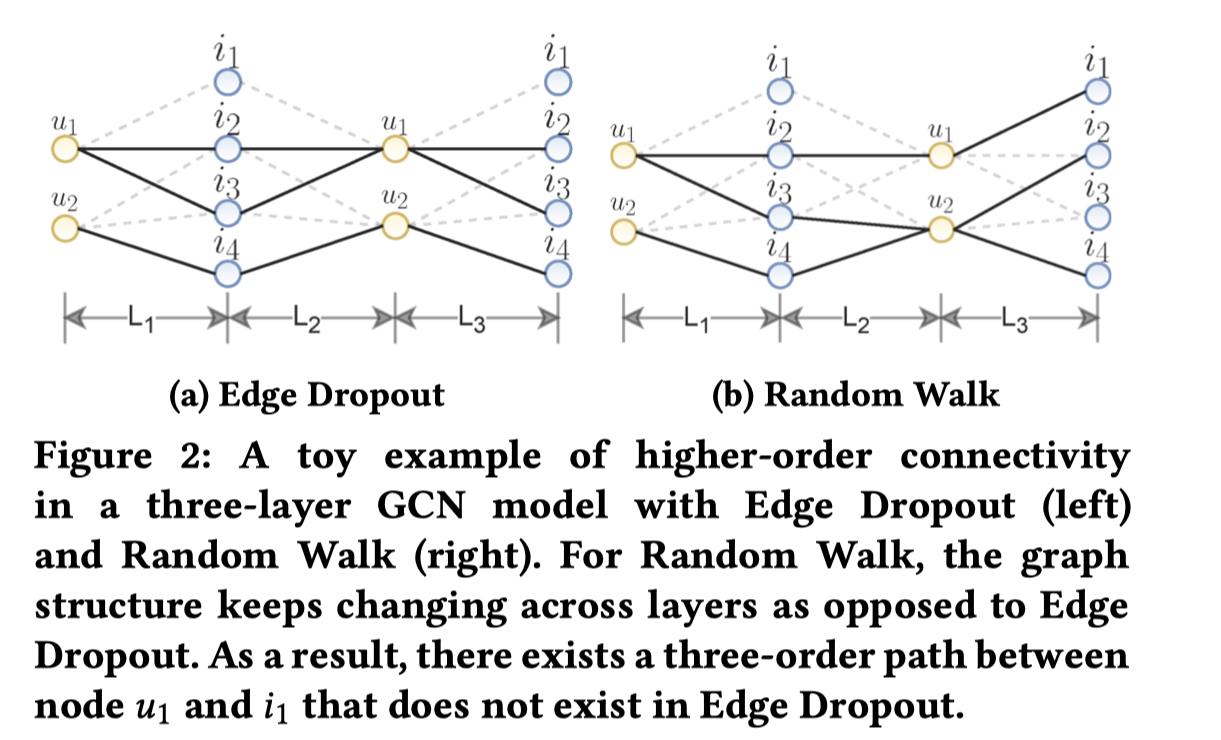
Random Walk:前两种方法,产出的子视图在不同的卷积层之间是共享的,即:不同卷积层面对的子视图是一样的。random walk想要产生layer-aware的子视图,即:不同卷积层输入的图是不一样的,这个实现方式就是针对不同卷积层,都随机生成不同的掩码向量,实现方式也是通过dropout实现的,不同层子图不一样,达到类似随机游走的效果。
s1(G)=(V,M(l)1⊙E), s2(G)=(V,M(l)2⊙E)
- 和edge dropout的差异体现在掩码向量是layer-aware的,多了个上标(l)
-
。
举例如下图,
2.2 Contrastive Learning
同一个结点在不同视图下,可以产生不同的表征向量。作者将同一结点不同视图下的表示看成一对正样本,即:(z′u,z′′u)|u∈U
,而不同结点的表征看成一对负样本,即:(z′u,z′′v)|u,v∈U,u≠v。对比学习的目标期望最大化同一结点不同视图表征向量之间的相似性,最小化不同结点表征之间的相似性。采用了类似SimCLR[5]中的InfoNCE[6]的目标,即:Luserssl=∑u∈U−logexp(s(z′u,z′′u)/τ)∑v∈Uexp(s(z′u,z′′v)/τ)
s是相似性函数,作者采用的是cosine相似性,τ是温度参数。item侧和user侧是对称的,同理可以得到。则最终的自监督学习损失函数为:Lssl=Luserssl+Litemssl
2.3 Multi-task Training
和推荐系统常用的BPR-pairwise损失函数Lmain
结合起来做联合训练,即:L=Lmain+λ1Lssl+λ2||Θ||22
值得注意的是,Lssl没有引入任何学习参数,因此最后一项正则化项都是图卷积神经网络的参数。
2.4 Theoretical Analyses of SGL
这个部分是全文最精彩的地方,作者从梯度贡献角度来理论地分析了SGL方法为何会有效。作者分析了其中重要的一个原因,SGL有助于挖掘困难负样本,这部分样本能够贡献取值大且有意义的梯度,来引导结点的表征学习。
首先,对某个结点u
,求Luserssl(u)关于z′u的导数。∂Luserssl(u)∂z′u=1τ||z′u||c(u)+∑v∈U/uc(v)
c(u)
衡量了正样本u对于z′u梯度的贡献度,v衡量了负样本v对于z′u梯度的贡献度。其中,c(u)=(s′′u−(s′uTs′′u)s′u)(Puu−1)
c(v)=(s′′v−(s′uTs′′v)s′u)Puv
P(uv)=exp(s′uTs′′v)/τ)∑v∈Uexp(s′uTs′′v)/τ))
即为softmax概率值,其中s′u=z′u||z′u||是u结点在对应视图下表征的归一化值,s′′u同理。我们重点关注下负样本v对于梯度的贡献度,即c(v),用L2范数来衡量梯度贡献度,即:||c(v)||2∝1−(s′uTs′′v)2−−−−−−−−−−√exp(s′uTs′′v/τ)
又因为s′u,s′′v都是单位向量,引入x=s′uTs′′v∈[−1,1]来简化式子,即:g(x)=1−x2−−−−−√exp(xτ)
其中,x也直接反映了正样本u和负样本v之间的相似性。根据x的取值,可以把v分为两类:
- 困难负样本,0<x≤1
-
- 存在一定的相似性,模型在隐空间难以很好地将这类负样本和正样本分离开。
-
简单负样本,−1≤x<0
- ,即:v和u
不相似,很容易区分开。
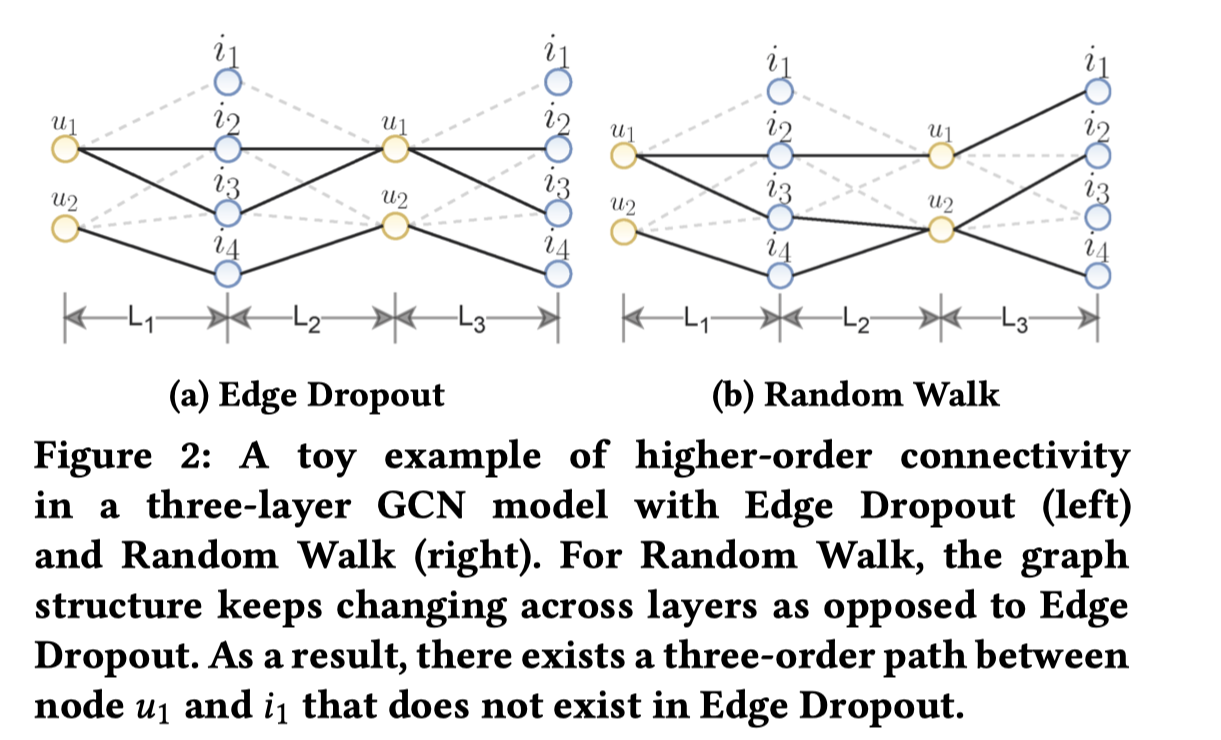
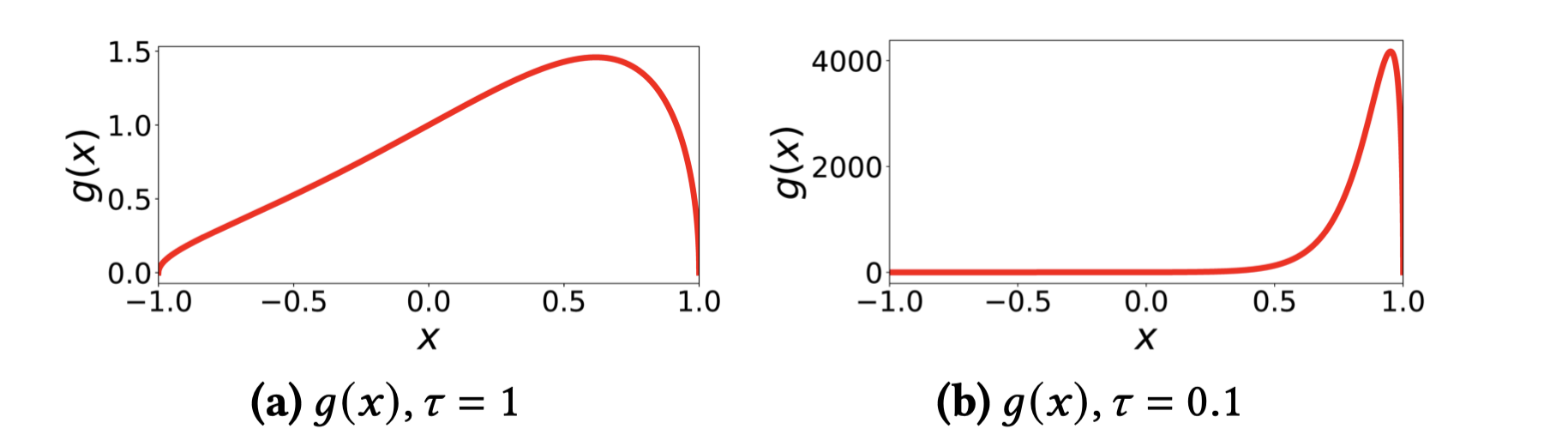
为了观察困难负样本和简单负样本对于梯度的贡献情况,作者画出了g(x)
随着x -
取值变化的变化情况:

-
(a)是τ=1
- 时的情况,可以看出g(x)位于(0,1.5)之间,随着x的变化,g(x)
-
的变化幅度很小,也即:不管是困难负样本还是简单负样本,对于梯度的贡献差距不是很大。
- (b)是τ=0.1
- 时的情况,可以看出g(x)位于(0,4000)之间,随着x的变化,g(x)
- 剧烈变化,困难负样本的梯度贡献度可以达到4000,而简单负样本的贡献度甚至都趋于0。可以看出,困难负样本对于梯度的贡献度很大,能够有效地加快收敛。也可以发现温度参数的重要性。
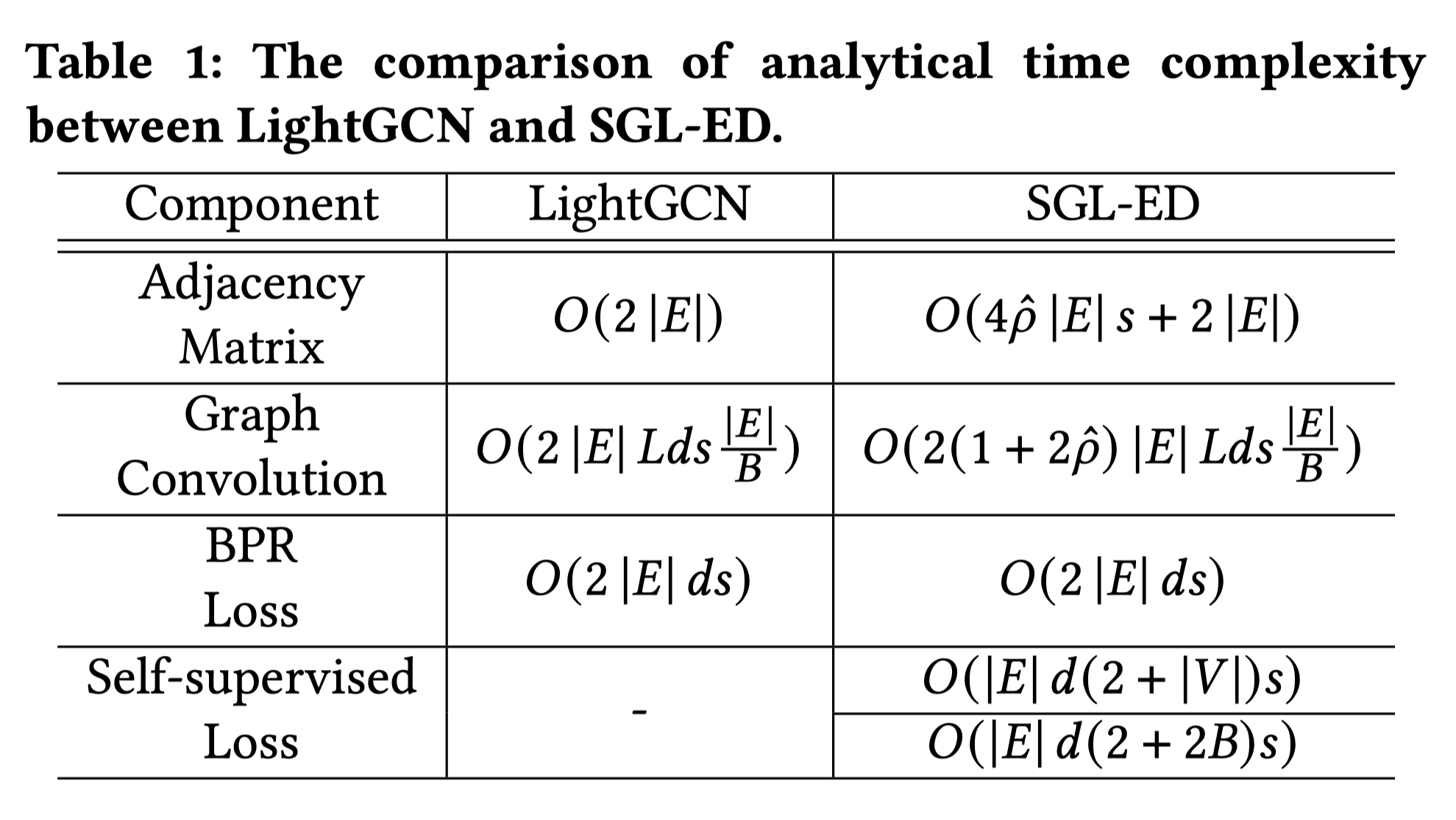
2.5 Complexity Analyses of SGL
除此之外,作者还做了一些复杂度的分析,相比于LightGCN,主要多的复杂度就是数据增强操作,即对邻接矩阵来做;以及自监督学习任务,这个的复杂度主要在于负样本选取,优化思路是拿同一个batch内其他的结点作为负样本,而不是整个图上所有其他结点都作为负样本。总体上,复杂度略涨,是在可以接受的范围内。

3. Evaluation
3.1 Settings
- 数据集:Yelp2018, Amazon-Book,Alibaba-iFashion
- 指标:Recall@20,NDCG@20
- 对比方法:协同过滤方法。
- 二分图协同过滤方法:NGCF[9]、LightGCN[2]
- 自编码器协同过滤方法:Mult-VAE [8]
- 神经网络+自监督学习方法:DNN+SSL[7]
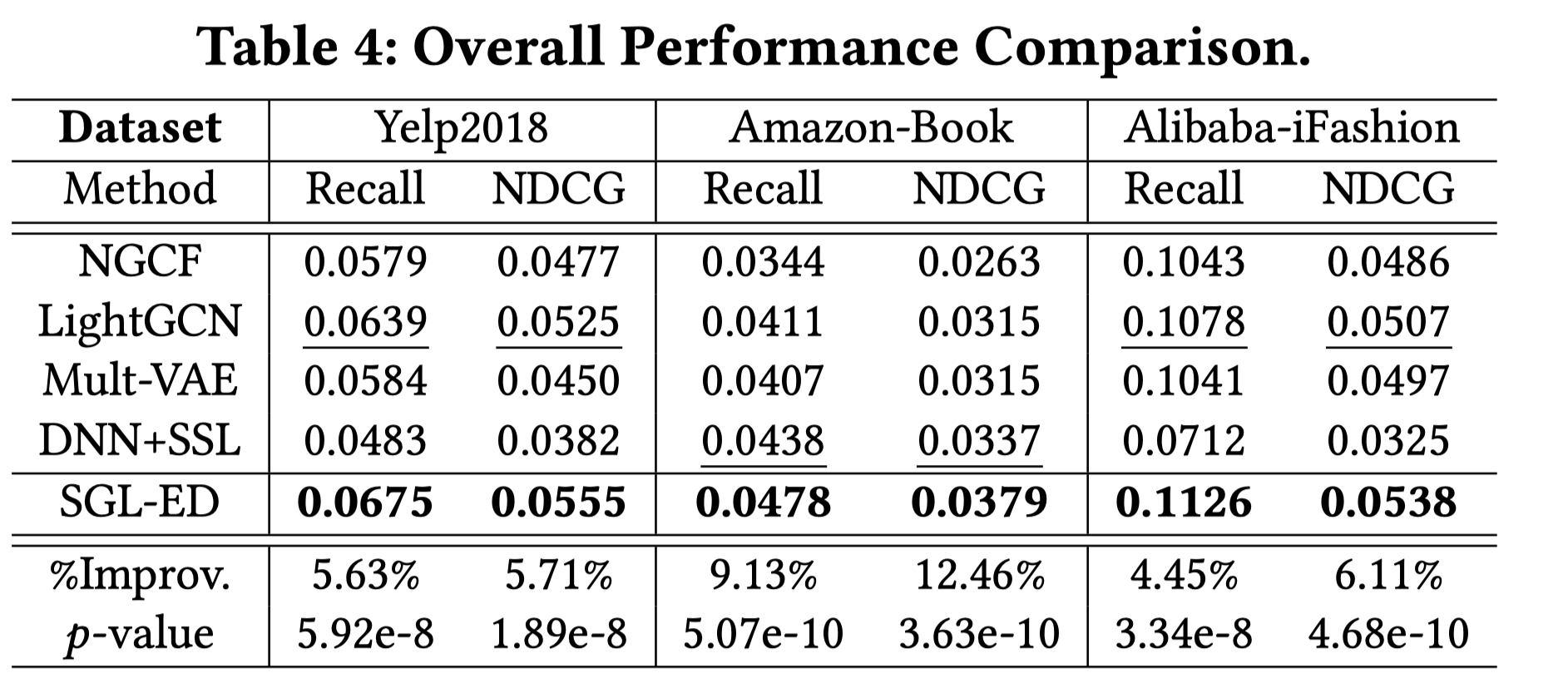
3.2 Comparison Study

可以看出,SGL-ED使用edge dropout的SGL效果比LightGCN好不少。
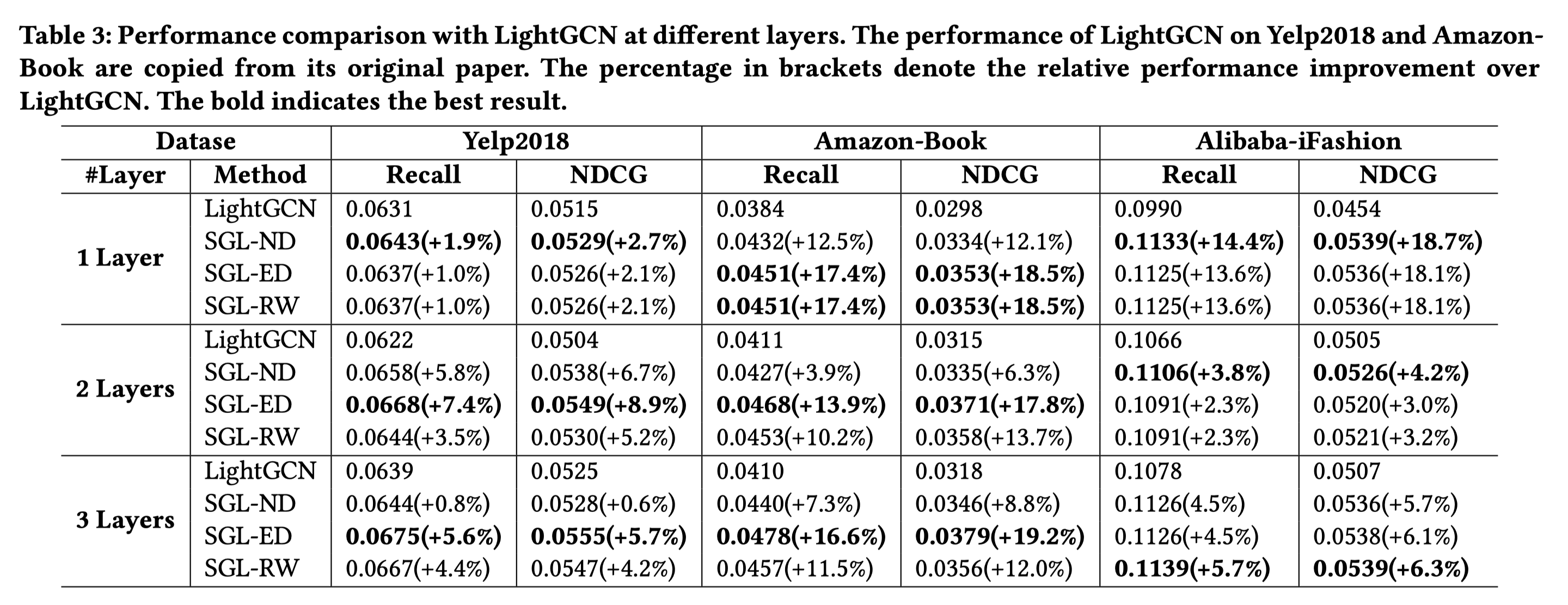
3.3 Ablation Study
- 对比3种不同的数据增强操作。发现SGL-ED总体上效果最好,其次是SGL-RW,最后是SGL-ND。作者认为edge dropout方式能更好地发现图结构中潜在的模式。
- SGL和LightGCN单独对比,SGL基本都是赢的。
- 层数从1到3层变化,效果慢慢变好,说明SGL对于泛化性有一定的帮助,即不同结点之间的对比学习能够有效缓解随着层数的增加导致的过度平滑问题。

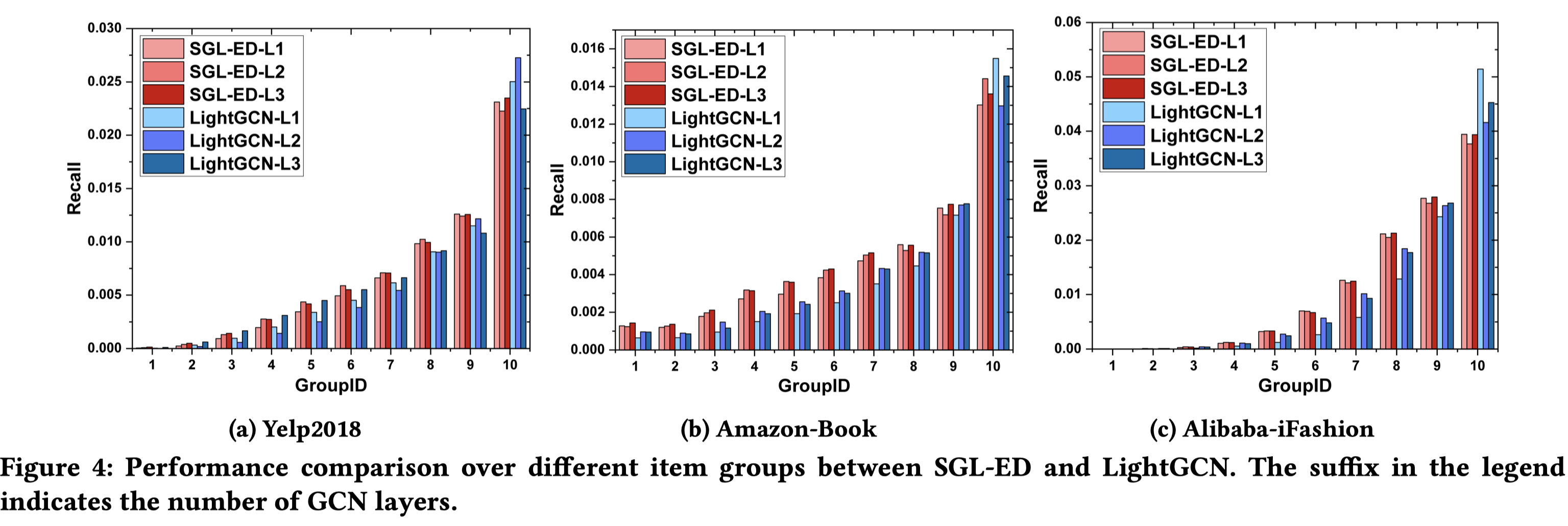
3.4 Long-tail Recommendation
长尾物品的推荐有效性的经验性分析,即:为何能够对长尾物品的推荐有帮助。
作者按照结点度的大小来对结点分组,度数越小则越长尾,然后看看SGL和LightGCN在不同组上的推荐性能差异。

如上图所示,SGL在低度的组别上(分组ID越小,度数越小),指标比LightGCN高不少;在高度的组别上,不相上下,LightGCN有的略好一些。这从经验上说明了SGL对于长尾物品推荐的有效性。
更深入的原因作者没有分析。不过,从这种实验结果可以看出,SGL自监督学习的范式对于长尾、稀疏交互的场景是很有效果的。
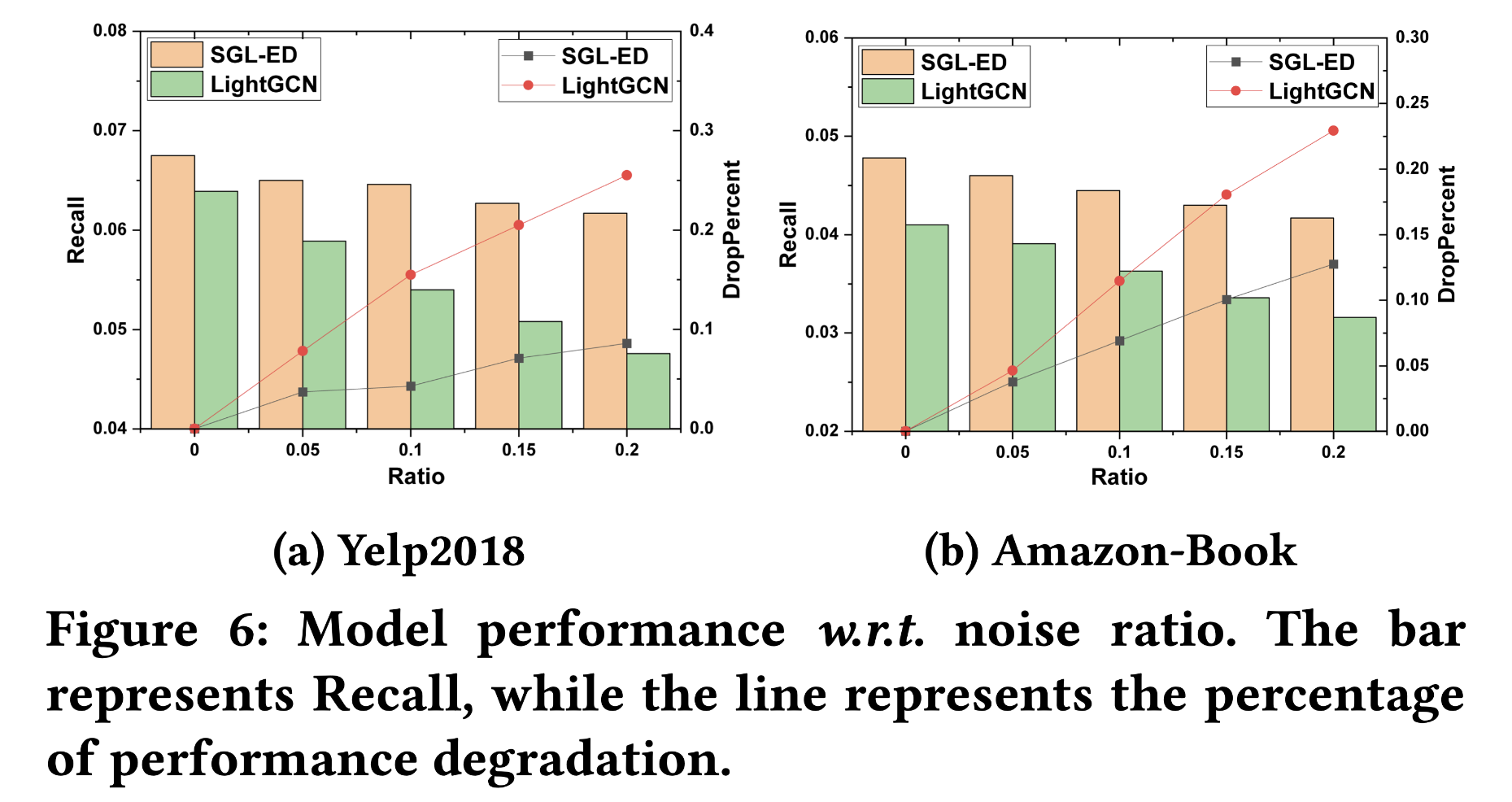
3.5 Robustness to Noisy Interactions
验证SGL的鲁棒性。方法也很简单粗暴,在训练集中加入对抗样本,即一定比例的user-item未交互的样本,然后看SGL和LightGCN在测试集上的表现。

可以看出,SGL依然完虐LightGCN。作者给出的原因是,通过对比学习同一结点的不同视图表征,模型能够有效地发现最有意义的模式,尤其是结点的图结构,使得模型不会过于依赖某些边。总而言之,SGL提供了一种能够去掉噪声交互信息的方法。
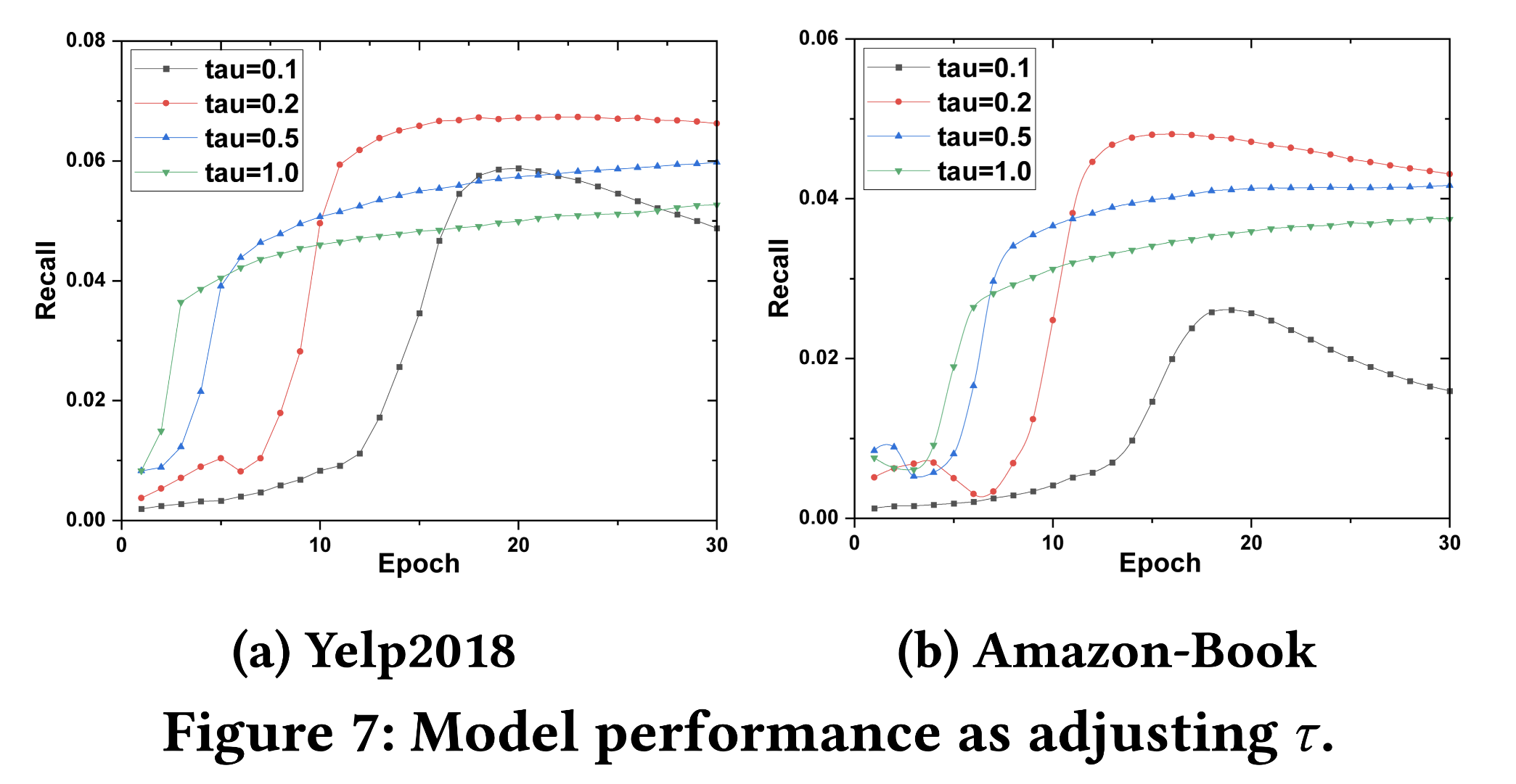
3.6 Other Analysis
-
温度参数τ
的选择,不宜过大,也不宜过小。

可以看出,τ=0.2
-
的时候最佳。
-
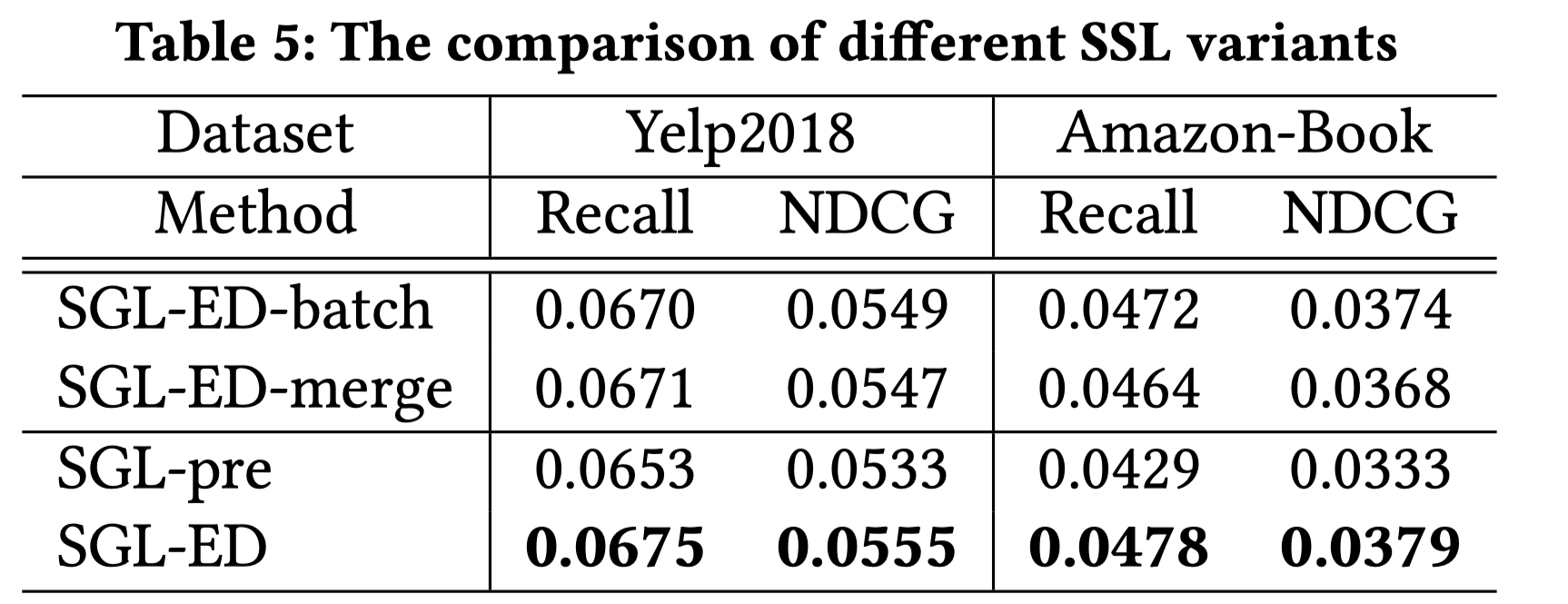
预训练的有效性,自监督的另一种方法是先自监督地预训练结点向量,然后用于初始化结点向量,再通过推荐监督任务来finetune。最终的效果是,SGL-ED>SGL-pre >LightGCN。说明预训练方式也是有效的。
-
负采样方法,
- 在batch内采样同类型结点作为负样本,比如user采用user结点作为负样本。SGL-ED-batch
- batch内采样任意结点,不区分结点类型。SGL-ED-merge。
- 在全域内采样同类型的负样本。SGL-ED。
SGL-ED > SGL-ED-batch > SGL-ED-merge。SGL-ED-batch和SGL-ED差距不是非常大,说明batch内采样是个很好地优化方法。

-
SGL的收敛速度快,这主要得益于困难负样本。值得一提的是,作者提到了一个很有意思的店,SGL的BPR损失下降和Recall指标的上升存在时间上的小gap,说明了BPR损失在排序任务中不一定是最优的。
Another observation is that the origin of the rapid-decline period of BPR loss is slightly later than the rapid-rising period of Recall. This indicates the existence of a gap between the BPR loss and ranking task。
Summarization
SGL方法很简洁,可以快速结合各种图模型,在各种各样的推荐任务上尝试。实验论证也做的非常充分,是个很有借鉴意义的工作。整篇文章看下来,最大的收获是,对比学习的理论分析以及为何能够解决长尾推荐和对噪声交互有鲁棒性的实验论证。作者给出了一些经验的分析,可能缺一些更细致深入的剖析,但是从直觉上给到了很重要的原因。按照我的理解,总结两点,
-
通过数据增强来改变图结构,使得图模型于不会过于依赖某些边或者某些高度结点。
-
通过对比学习同一结点的不同视图表征,模型能够有效地发现最有意义的模式,尤其是结点的图结构信息,同时还能挖掘困难负样本,提高模型的区分能力。
更多基于二分图的推荐系统文章请参见:
基于二分图表征学习的推荐系统调研:推荐系统中二分图表示学习调研 - 知乎
MM’19 | MMGCN 面向短视频推荐的多模态图神经网络
参考
[1] SIGIR21,Self-supervised Graph Learning for Recommendation
[2] SIGIR20,LightGCN:Simplifying and powering graph convolution network for recommendation
[3] SGL源代码:GitHub - wujcan/SGL
[4] SimCSE: Simple Contrastive Learning of Sentence Embeddings:https://arxiv.org/abs/2104.08821
[5] SimCLR: A Simple Framework for Contrastive Learning of Visual Representations. CoRR 2020
[6] InfoNCE:Michael Gutmann and Aapo Hyvärinen. 2010. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In AISTATS, Vol. 9. 297–304.
[7] CoRR20,Self-supervised Learning for Deep Models in Recommendations.
[8] WWW18,Variational Autoencoders for Collaborative Filtering
[9] SIGIR19, NGCF,Neural Graph Collaborative Filtering
以上是关于SIGIR‘21|SGL基于图自监督学习的推荐系统的主要内容,如果未能解决你的问题,请参考以下文章