手把手教你掌握4类数据清洗操作
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手教你掌握4类数据清洗操作相关的知识,希望对你有一定的参考价值。
本文介绍数据清洗的相关内容,主要涉及缺失值清洗、格式内容清洗、逻辑错误清洗和维度相关性检查四个方面。
推荐文章
01 缺失值清洗
相信大家都听说过这样一句话:废料进、废品出(Garbage in, Garbage out)。如果模型基于错误的、无意义的数据建立,那么这个模型也会出错。因此,如果源数据带有缺失值(NaN),就需要在数据预处理中进行清洗。缺失值是最常见的数据问题,有很多处理缺失值的方法,一般均按照以下四个步骤进行。
1. 确定缺失值范围
具体代码如下:
# 检查数据缺失情况
def check_missing_data(df):
return df.isnull().sum().sort_values(ascending = False)
check_missing_data(rawdata)
Income 1
Age 1
Online Shopper 0
Region 0
dtype: int64
对每个字段都计算其缺失值比例后,按照缺失比例和字段重要性,分别制定相应的解决策略,可用图1表示。

图3-6看似明确了不同情况的应对策略,但在实际应用中对特征的重要性判断非常复杂,通常需要到模型中去判断。对数据库进行研究并对所需解决的问题进行分析,可确定哪些特征属于重要特征,哪些特征可以省去或者删掉。
比如我们很难对每个数据的ID(独特编码)进行补全,在有的情境下这些信息是必要信息,不能够缺失,而在有的情境下却根本不需要这类信息。
比如我们有一组网购记录信息,其中包括每个用户在不同时间段的操作。当我们希望对每个用户进行分析的时候,用户名(UserID)就是不可或缺的,那么缺失用户名的数据很可能需要被清除。但如果我们不需要精确到对个人行为进行分析,那么用户名就没那么必要了。
所以在缺失值补全的操作前,**探索数据和深入了解数据库是必要的。**我们必须清楚每个变量所代表的含义,以及分析的问题可能关联的数据。在一个非常复杂的数据库中,在解决某个实际问题时,通常不需要所有的变量参与运算。
2. 去除不需要的字段
本步骤将减少数据维度,剔除一些明显与数据分析任务不匹配的数据,让与任务相关的数据更为突出。注意,最好不要更改原始数据,只是在下一步处理前提取出用于分析的数据。
同时这一步需要考虑之前缺失值的情况,保留对于有些缺失值占比不大或者通过其他信息可以进行推断的特征,去除缺失量太多的数据行或列。对于新手,强烈建议在清洗的过程中每做一步都备份一下,或者在小规模数据上试验成功后再处理全量数据,节约时间,也充分留足撤销操作的余地。
3. 填充缺失内容
具体代码如下:
test1 = rawdata.copy()# 将更改前的数据进行备份
test1 = test1.head(3)# 提取前三行进行测试
test1 = test1.dropna()# 去除数据中有缺失值的行
print(test1)
test1
name toy born
0 Andy NaN NaN
1 Cindy Gun 1998-12-25
2 Wendy Gum NaN
test1 = test1.dropna(axis=0)# 去除数据中有缺失值的行
name toy born
1 Cindy Gun 1998-12-25
test1 = test1.dropna(axis='columns')# 去除数据中有缺失值的列
name
0 Andy
1 Cindy
2 Wendy
test1 = test1.dropna(how='all')# 去除数据完全缺失的行
test1 = test1.dropna(thresh=2)# 保留行中至少有两个值的行
test1 = test1.dropna(how='any')# 去除数据中含有缺失值的行
test1 = test1.dropna(how='any',subset=['toy'])# 去除toy列中含有缺失值的行
test1.dropna(inplace=True)# 在这个变量名中直接保存结果
在实际应用中,第2步和第3步的操作通常协同进行,在判断完维度相关性与重要性后,对想要保留的维度进行填充,最后对数据行进行必要的清洗,以避免可进行填充的有效字段在清洗时被剔除。
1)以同一指标的计算结果(均值、中位数、众数等)填充缺失值。代码如下:
test1 = test1.fillna(test1.mean())# 用均值填充缺失值
test1 = test1.fillna(test1.median())# 用中位数填充缺失值
test1 = test1.fillna(test1.mode())# 用众数填充缺失值
2)通过找寻带有缺失值的变量与其他数据完整的变量之间的关系进行建模,使用计算结果进行填充(这一方法较为复杂,而且结果质量可能参差不齐,可在后期习得数据建模技巧后进行尝试)。
3)以其他变量的计算结果填充缺失值。举个最简单的例子:年龄字段缺失,但是有屏蔽后六位的身份证号信息,那么就可以轻松找出出生年月,算出目前年龄。
4)以业务知识或经验推测填充缺失值。
4. 重新取数
如果某些变量非常重要同时缺失率高,那就需要和取数人员或业务人员进行沟通,了解是否有其他渠道可以取到相关数据。
继续以Income_n_onlineshopping为例介绍,如图2所示。

▲图2 查看数据是否存在缺失值
统计各列的缺失值情况,结果如图3所示。
dataset.isna().sum() # 统计各列缺失值情况

▲图3 统计数据缺失值个数
从图3-7可以看出,这10行数据中第4行和第6行的部分值显示为NaN,也就是数据发生缺失。有时数据本身可能并不是在缺失值位置上留空,而是用0对空缺位置进行填充,根据对数据的理解我们也可以分辨出是否需要对0值数据进行统计和转换。
由于数值缺失占比较少,我们可以通过计算填补空缺,这里我们采用平均值填充。
# 设定填充方式为平均值填充
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
# 选取目标列
imputer = imputer.fit(rawdata.iloc[:,1:3])
# 对计算结果进行填充
rawdata.iloc[:,1:3] = imputer.transform(rawdata.iloc[:,1:3])
# 调整数据
rawdata.iloc[:,1:3] = rawdata.iloc[:,1:3].round(0).astype(int)
02 格式内容清洗
如果数据是由系统日志而来的,那么通常会在格式和内容方面与元数据的描述保持一致。而如果数据是由人工收集或用户填写而来的,则有很大可能会在格式和内容上存在问题。简单来说,格式和内容的问题有以下几类。
1. 时间、日期、数值、全半角等格式不一致
这种问题通常与输入端有关,在整合多来源数据时也有可能遇到,将其处理成一致的格式即可。
2. 数据值含有“非法”字符
字段中的值通常是有范围的,有些字符不适合出现在某些字段中,比如:
-
身份证号必须是数字+字母。
-
中国人姓名只能为汉字(李A、张C这种情况是少数)。
-
出现在头、尾、中间的空格。
解决这类问题时,需要以半自动校验半人工方式来找出可能存在的问题,并去除不合适的字符。
3. 数据值与该字段应有内容不符
例如,姓名栏填了性别、身份证号中写了手机号等。这类问题的特殊性在于不能简单地以删除方式来处理,因为有可能是人工填写错误,前端没有校验,或者导入数据时部分或全部存在列没有对齐导致,需要具体识别问题类型后再有针对性地解决。
**格式内容出错是非常细节的问题,但很多分析失误都是源于此问题。**比如跨表关联失败,是因为多个空格导致关键字段进行交集运算时认为“刘翔”和“刘 翔”不是一个人;统计值不全,是因为数字里掺个字母在之后求和时发生问题;模型输出失败或效果不好,是因为数据对错列了,把日期和年龄混了等。
因此,在进行这一步时,需要仔细检查数据格式和内容,特别是当数据源自用户手工填写且校验机制不完善时。
03 逻辑错误清洗
这一步工作的目的是去掉一些使用简单逻辑推理就可以直接发现问题的数据,防止由此导致分析结果偏差。逻辑错误清洗主要包含以下几个步骤。
1. 去重
由于格式不同,原本重复的数据被认为并非重复而没能成功剔除,比如由于空格导致算法认为“刘翔”和“刘 翔”不是一个人,去重失败。由于重名的情况很常见,即使中间空格被去掉后两条数据的值一致,也很难直接决定将第二条数据删除,这时就需要比较其他字段的值。
还有由于关键字值输入时发生错误导致原本一致的信息被重复录入,也需要借助其他字段对内容进行查重。比如“ABC银行”与“ABC銀行”,单看名字可以看出这两条信息大概率是重复的,但只有对比其他信息才能确保去重的正确性,比如对比两家公司的电话与地址是否完全相同。如果数据不是人工录入的,那么简单去重即可。
2. 去除不合理值
如果字段内取值超过合理范围,比如“年龄:180岁;籍贯:火星”,则这种数据要么删掉,要么按缺失值处理。当然最好的做法是在前期收集这种字段的数据时让用户在有限范围内进行选取,以避免此情况出现。可以通过异常值查找去除不合理值。
3. 修正矛盾内容
有时我们拥有多个包含相同信息的维度特征,这时就可以进行交叉验证,修复矛盾内容。比如一个隐去后六位的身份证号,100000199701XXXXXX,而年龄字段数据为18,这显然是不合理的,由于身份证号可信度更高,所以我们应该对年龄字段进行修复。
更好的做法是通过脱敏的身份证号提取出生年月,直接建立新的出生日期字段并用此年龄字段替换用户手动填写的年龄字段。
在真实世界中获取的数据常常会包含错误信息,有的是人为导致,有的是非人为导致,我们可以通过交叉验证及时发现并修复矛盾内容,为后期建模提供更高质量的数据信息。
04 维度相关性检查
当数据库中有多个变量时,我们需要考虑变量之间的相互联系,而相关性就是用来表示定性变量或定量变量之间关系的。相关性研究可以帮助我们了解变量之间的关联性。比如:
-
每日食品中卡路里摄入量跟体重很有可能有较大的相关性;
-
子女和父母血型之间具有高关联性;
-
学习的时间长度和考试成绩通常也有高关联性。
1)检查数据相关性:
rawdata.corr() # 相关性矩阵
结果如图4所示。

▲图4 相关性矩阵
2)检查数据协方差:
rawdata.cov() # 协方差矩阵
结果如图5所示。
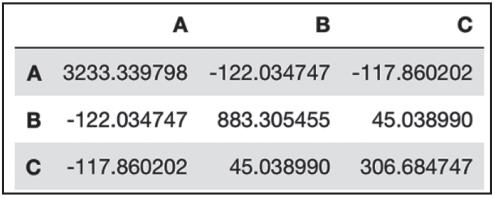
▲图5 协方差矩阵
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于手把手教你掌握4类数据清洗操作的主要内容,如果未能解决你的问题,请参考以下文章