手把手教你搭建神经网络(回归)
Posted 羽峰码字
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手教你搭建神经网络(回归)相关的知识,希望对你有一定的参考价值。

大家好,我是羽峰,今天要和大家分享是回归 (regression) 问题,希望通过今天的讲解,各位对回归问题能有个更好的认识。
目录
1.认识回归
回归问题是机器学习三大基本模型中很重要的一环,其功能是建模和分析变量之间的关系。
回归问题多用来预测预测出如价格或概率这样连续值的输出,如预测房价、未来的天气情况等等。例如我们根据一个地区的若干年的PM2.5数值变化来估计某一天该地区的PM2.5值大小,预测值与当天实际数值大小越接近,回归分析算法的可信度越高。相对于分类(classification) 问题,分类(classification) 的目的是从一系列的分类出选择出一个分类 (如,给出一张包含苹果或橘子的图片,识别出图片中是哪种水果)。
面对一个回归问题,我们可简要描述其求解流程:
- 选定训练模型,即我们为程序选定一个求解框架,如线性回归模型(Linear Regression)等。
- 导入训练集 train_set,即给模型提供大量可供学习参考的正确数据。
- 选择合适的学习算法,通过训练集中大量输入输出结果让程序不断优化输入数据与输出数据间的关联性,从而提升模型的预测准确度。
- 在训练结束后即可让模型预测结果,我们为程序提供一组新的输入数据,模型根据训练集的学习成果来预测这组输入对应的输出值。
接下来我们将以 Auto MPG 数据集来说明基本的回归模型是怎样训练的。
2. Auto MPG 数据集
2.1获取数据集
本 文使用经典的 Auto MPG 数据集,构建了一个用来预测70年代末到80年代初汽车燃油效率的模型。为了做到这一点,我们将为该模型提供许多那个时期的汽车描述。这个描述包含:气缸数,排量,马力以及重量。
前期配置
# 使用 seaborn 绘制矩阵图 (pairplot)
pip install -q seabornimport pathlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)下载数据集
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_pathDownloading data from http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data 32768/30286 [================================] - 0s 1us/step '/home/kbuilder/.keras/datasets/auto-mpg.data'
使用 pandas 导入数据集。
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\\t',
sep=" ", skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()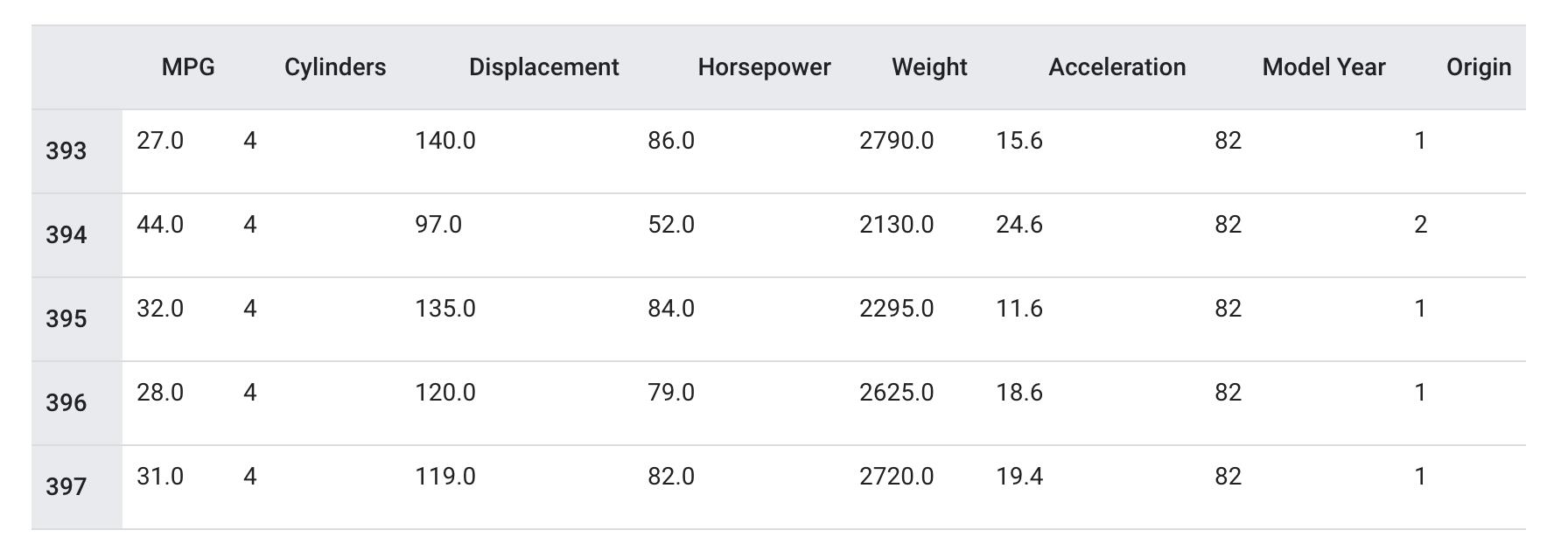
2.2 数据清洗
数据集中包括一些未知值。
dataset.isna().sum()MPG 0 Cylinders 0 Displacement 0 Horsepower 6 Weight 0 Acceleration 0 Model Year 0 Origin 0 dtype: int64
为了保证这个初始示例的简单性,删除这些行,或者屏蔽掉就行,这里只是看一下数据是怎样的。
dataset = dataset.dropna()"Origin" 列实际上代表分类,而不仅仅是一个数字。所以把它转换为独热码 (one-hot):
origin = dataset.pop('Origin')
dataset['USA'] = (origin == 1)*1.0
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail()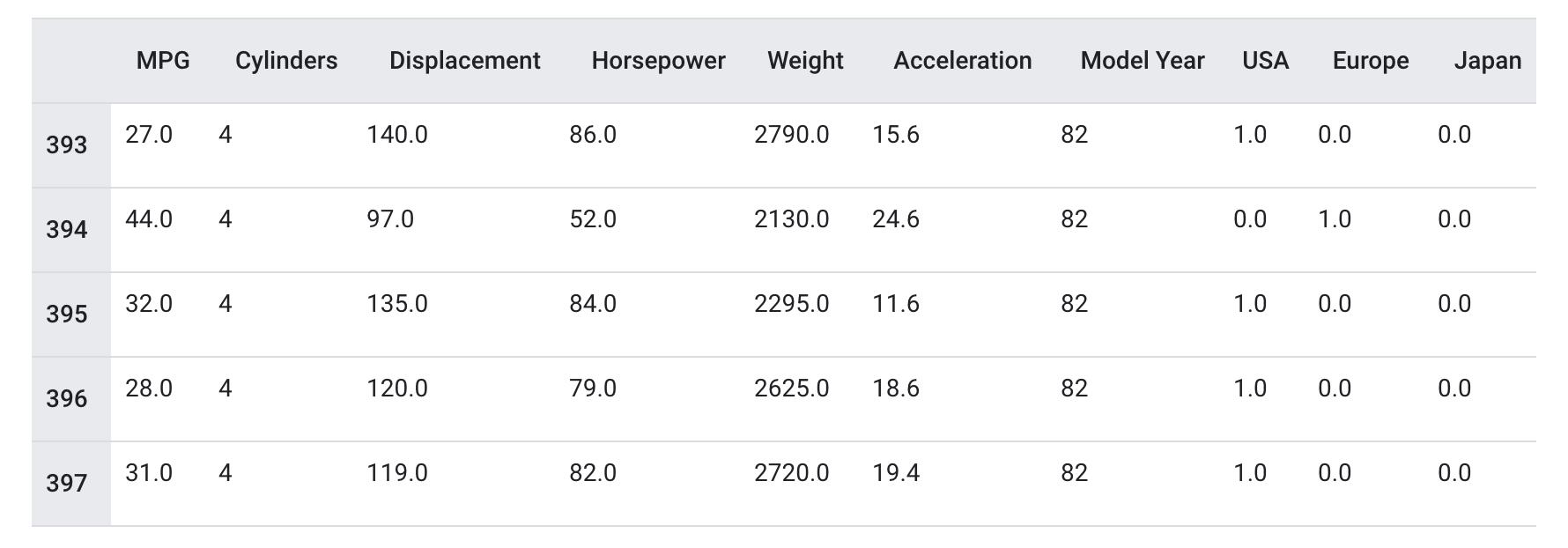
2.3 拆分训练数据集和测试数据集
现在需要将数据集拆分为一个训练数据集和一个测试数据集。
我们最后将使用测试数据集对模型进行评估。
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)快速查看训练集中几对列的联合分布。
sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")<seaborn.axisgrid.PairGrid at 0x7f708ca93e80>
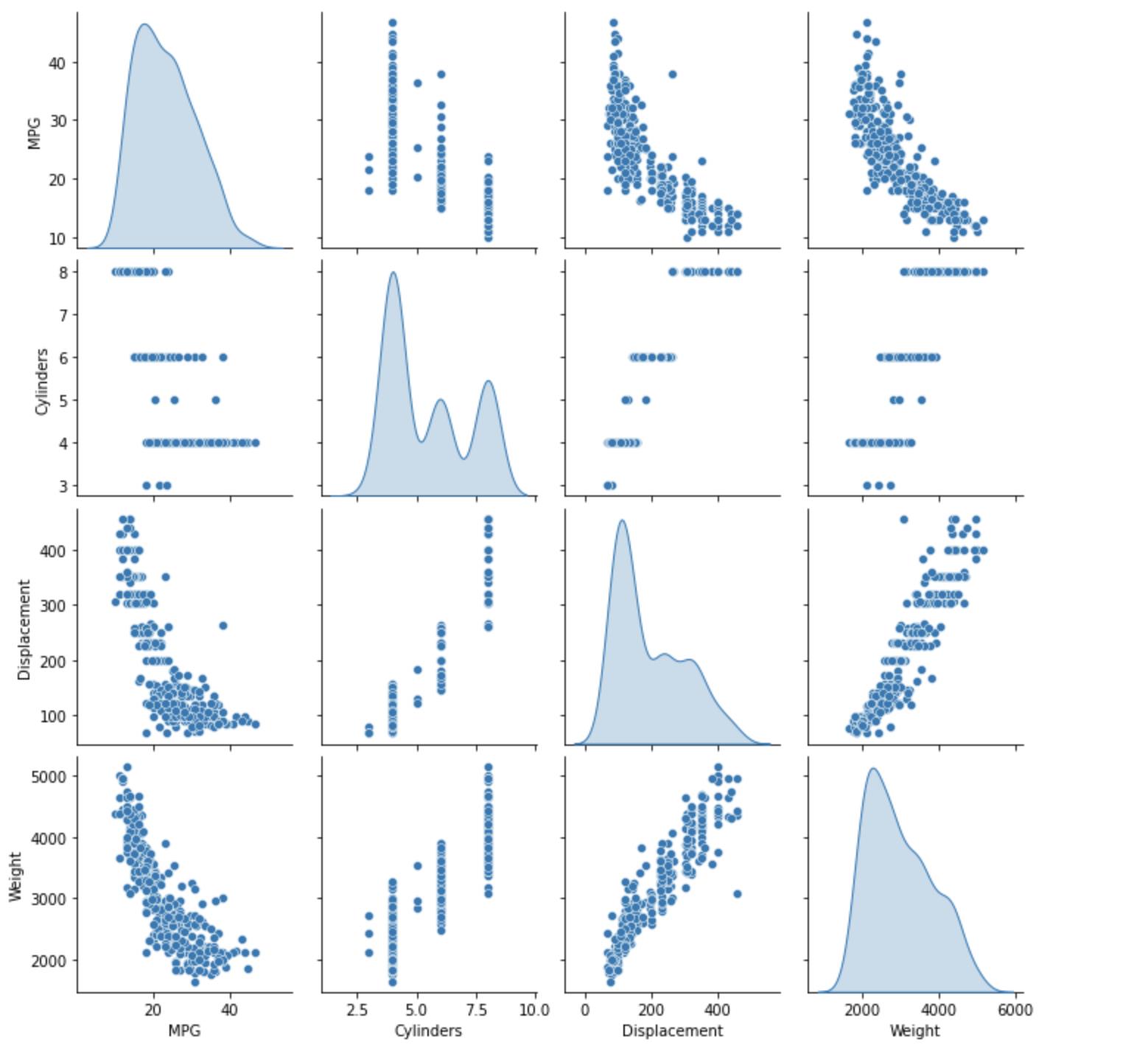
也可以查看总体的数据统计:
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats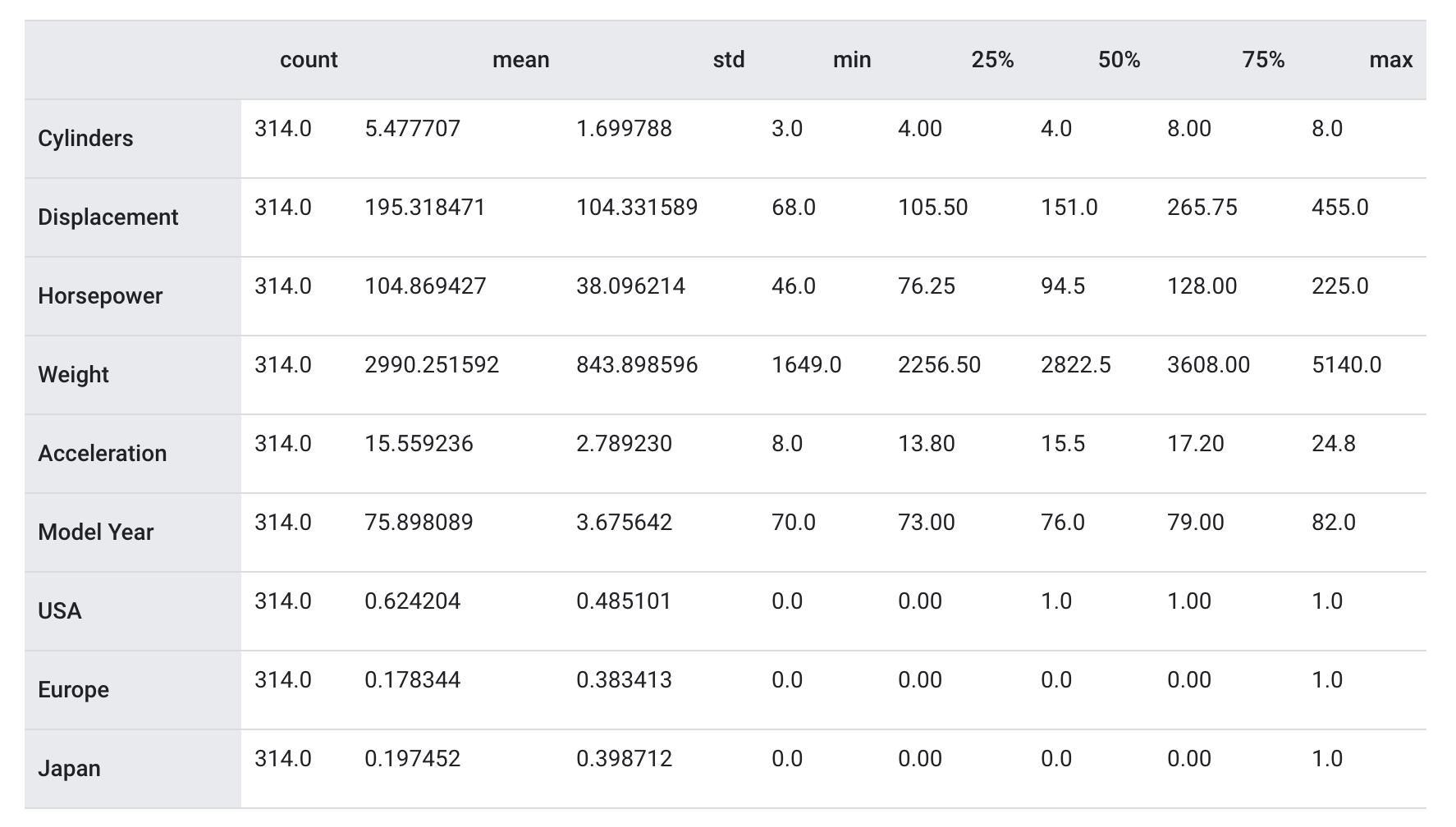
2.4 从标签中分离特征
将特征值从目标值或者"标签"中分离。 这个标签是你使用训练模型进行预测的值。
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')2.5 数据规范化
再次审视下上面的 train_stats 部分,并注意每个特征的范围有什么不同。
使用不同的尺度和范围对特征归一化是好的实践。尽管模型可能 在没有特征归一化的情况下收敛,它会使得模型训练更加复杂,并会造成生成的模型依赖输入所使用的单位选择。
注意:尽管我们仅仅从训练集中有意生成这些统计数据,但是这些统计信息也会用于归一化的测试数据集。我们需要这样做,将测试数据集放入到与已经训练过的模型相同的分布中。
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)我们将会使用这个已经归一化的数据来训练模型。
警告: 用于归一化输入的数据统计(均值和标准差)需要反馈给模型从而应用于任何其他数据,以及我们之前所获得独热码。这些数据包含测试数据集以及生产环境中所使用的实时数据。
3. 模型
3.1 构建模型
让我们来构建我们自己的模型。这里,我们将会使用一个“顺序”模型,其中包含两个紧密相连的隐藏层,以及返回单个、连续值得输出层。模型的构建步骤包含于一个名叫 'build_model' 的函数中,稍后我们将会创建第二个模型。 两个密集连接的隐藏层。
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return modelmodel = build_model()3.2 检查模型
使用 .summary 方法来打印该模型的简单描述。
model.summary()Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 64) 640 _________________________________________________________________ dense_1 (Dense) (None, 64) 4160 _________________________________________________________________ dense_2 (Dense) (None, 1) 65 ================================================================= Total params: 4,865 Trainable params: 4,865 Non-trainable params: 0 _________________________________________________________________
现在试用下这个模型。从训练数据中批量获取‘10’条例子并对这些例子调用 model.predict 。
example_batch = normed_train_data[:10]
example_result = model.predict(example_batch)
example_resultarray([[0.15074062], [0.0973136 ], [0.17310914], [0.08873479], [0.52456 ], [0.05311462], [0.49406645], [0.04333409], [0.12005241], [0.6703117 ]], dtype=float32)
它似乎在工作,并产生了预期的形状和类型的结果
3.3 训练模型
对模型进行1000个周期的训练,并在 history 对象中记录训练和验证的准确性。
# 通过为每个完成的时期打印一个点来显示训练进度
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=0,
callbacks=[PrintDot()])使用 history 对象中存储的统计信息可视化模型的训练进度。
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [MPG]')
plt.plot(hist['epoch'], hist['mae'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mae'],
label = 'Val Error')
plt.ylim([0,5])
plt.legend()
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Square Error [$MPG^2$]')
plt.plot(hist['epoch'], hist['mse'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mse'],
label = 'Val Error')
plt.ylim([0,20])
plt.legend()
plt.show()
plot_history(history)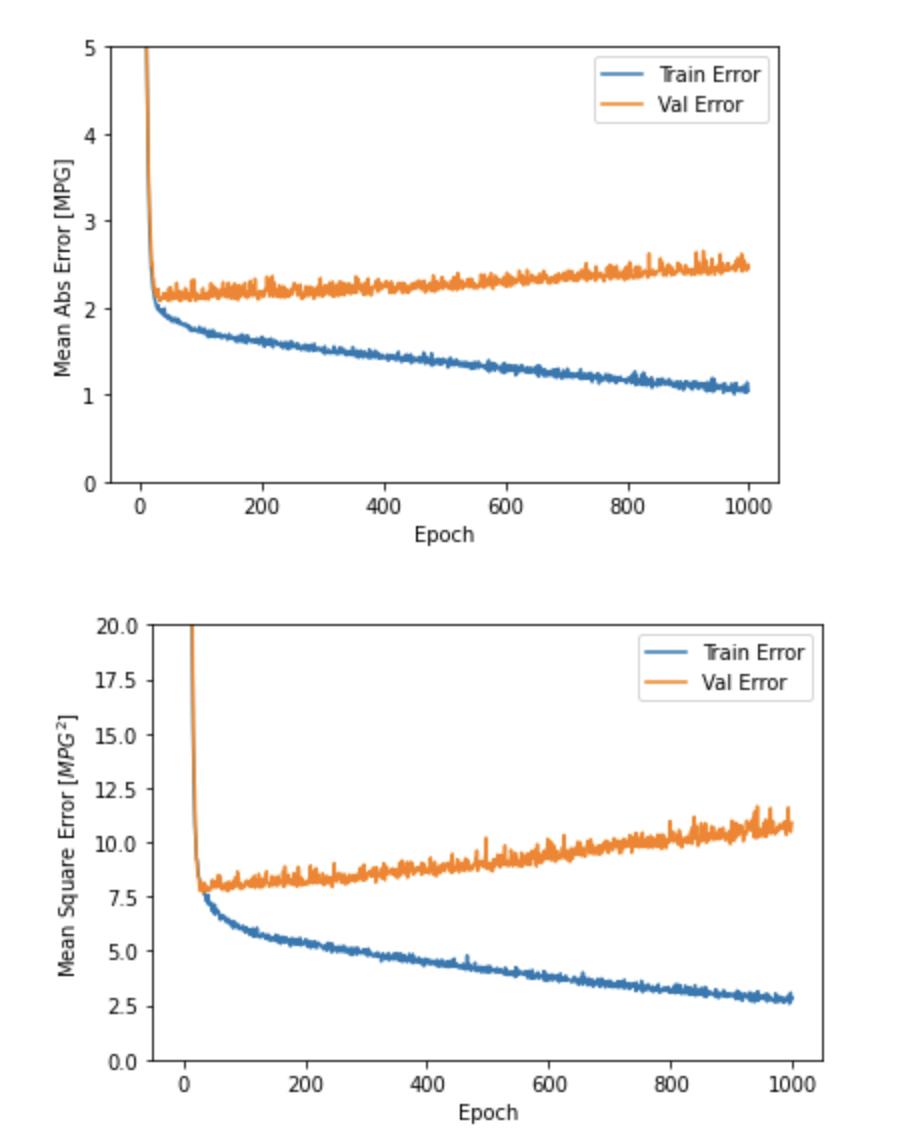
该图表显示在约100个 epochs 之后误差非但没有改进,反而出现恶化。 让我们更新 model.fit 调用,当验证值没有提高上是自动停止训练。 我们将使用一个 EarlyStopping callback 来测试每个 epoch 的训练条件。如果经过一定数量的 epochs 后没有改进,则自动停止训练。
model = build_model()
# patience 值用来检查改进 epochs 的数量
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(normed_train_data, train_labels, epochs=EPOCHS,
validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])
plot_history(history)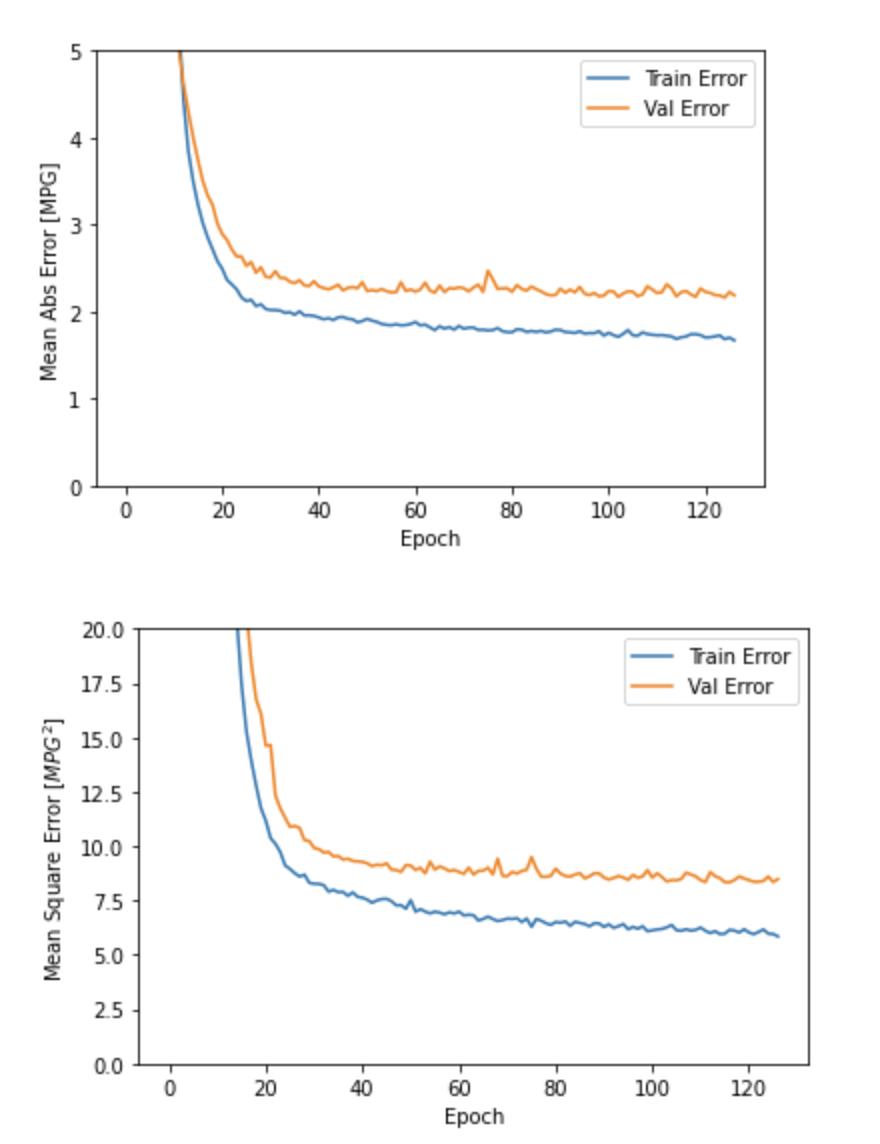
如图所示,验证集中的平均的误差通常在 +/- 2 MPG左右。 这个结果好么? 我们将决定权留给你。
让我们看看通过使用 测试集 来泛化模型的效果如何,我们在训练模型时没有使用测试集。这告诉我们,当我们在现实世界中使用这个模型时,我们可以期望它预测得有多好。
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)
print("Testing set Mean Abs Error: {:5.2f} MPG".format(mae))
3/3 - 0s - loss: 5.9941 - mae: 1.8809 - mse: 5.9941 Testing set Mean Abs Error: 1.88 MPG
3.4 预测
最后,使用测试集中的数据预测 MPG 值:
test_predictions = model.predict(normed_test_data).flatten()
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])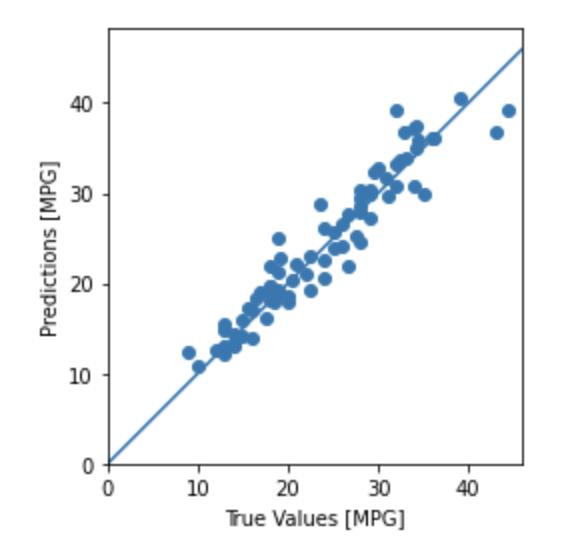
这看起来我们的模型预测得相当好。我们来看下误差分布。
error = test_predictions - test_labels
plt.hist(error, bins = 25)
plt.xlabel("Prediction Error [MPG]")
_ = plt.ylabel("Count")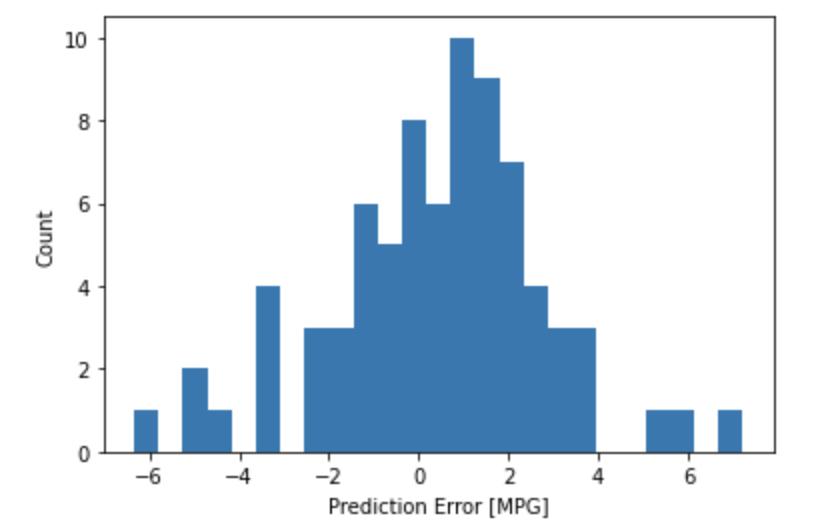
它不是完全的高斯分布,但我们可以推断出,这是因为样本的数量很小所导致的。
至此,今天的分享结束了,希望通过以上分享,你能学习到回归问题的基本流程,基本过程。强烈建议新手能按照上述步骤一步步实践下来,必有收获。
今天文章来源于:https://tensorflow.google.cn/tutorials/keras/classification,新入门的小伙伴可以好好看看这个网站,很基础,很适合新手。
当然,这里不得不重点推荐一下这两个网站:
https://tensorflow.google.cn/tutorials/keras/classification
https://keras.io/zh/
我是羽峰,公众号:羽峰码字,欢迎来撩
以上是关于手把手教你搭建神经网络(回归)的主要内容,如果未能解决你的问题,请参考以下文章