kafka浅谈Kafka的多线程消费的设计
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka浅谈Kafka的多线程消费的设计相关的知识,希望对你有一定的参考价值。

1.概述
转载:浅谈Kafka的多线程消费的设计 看原文去。。。
一、前言
跟RabbitMQ相比,Kafka的分区机制(Partition)使其支持对同一个“队列”分片并行读取,这也是Kafka的吞吐量远高于RabbitMQ的原因之一。
注:当然,Kafka里并无严格的队列概念,此处只是为了便于类比,所以采用了“队列”的说法
但Kafka内部也存在一定约束:每个Consumer Group所订阅的Topic下的每个Partition只能分配给该Group下的一个Consumer线程(当然该Partition还可以被分配给其他Group),也即,站在同一个Consumer Group的角度来看,一个Partition只能被该Group里的一个Consumer线程消费,因为该Partition只能与该Group内的一个Consumer线程建立Tcp连接,而不会与该Group内的其他Consumer建立连接,这意味着该Group内的其他Consumer也无法与该Partition通信(除非发生了Consumer Rebalance)。
注:RabbitMQ的客户端应用则可以多个线程消费同一个队列,因为与Kafka不同的是:
RabbitMQ与客户端应用只有一个TCP连接(长连接),而RabbitMQ与该客户端应用内的多个消费线程都可以基于该TCP连接内的多个Channel来通信
且RabbitMQ不需要记录每个消费线程的最新offset,其得到消费线程的ack回应也只是为了删除消息,因此RabbitMQ的客户端应用可以针对同一个队列开启多个线程来消费。
无论是Kafka官方提供的客户端API,还是Spring封装的Spring Kafka,在消息消费方面,均只是实现了默认情况下的1个Consumer1个线程。若希望1个Consumer有多个线程来加快消费速率,以进一步提升对partition的并行消费能力,则需要开发者自己实现(比如该Consumer一次拉取100条消息,分发给多个线程并行处理)。
因此,默认情况下,每个Consumer Group的消费并行能力是依赖于其所订阅的Topic配置的Partition数量,消费线程数只能小于等于Partition数量,比如Partition数量为3,那么只能最多有3个消费线程来并行消费,如果超过了3个,只会浪费系统资源,因为多出的线程不会被分配到任何分区。
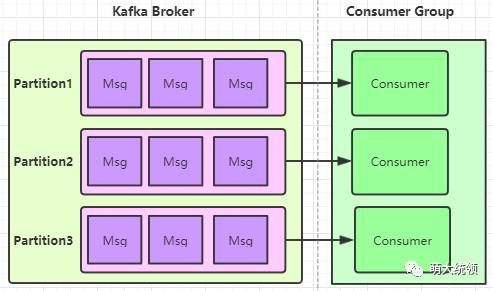
这在一定程度上,也对客户端的并行消费能力造成了一定了限制,默认情况下,要提升并行能力,则只能通过增加所订阅Topic的Partition数量,才能增加消费线程数量,进而才能扩展客户端的并行消费能力。比如:
对现有的Kafka集群扩容(如增加broker实例数量,重新分区,增加Partition的数量)
将部分Topic从现有的Kafka集群中拆分出来,放到新建的Kafka集群中(本质上也属于一种扩容)
以上2种扩展方式不可避免的需要涉及到数据迁移,因此,客观来说,这2种扩展方式相对有点“重”。
如果不想再增加Partition的数量,希望能在现有的Partition数量基础上,进一步提升Kafka消费并行能力,该怎么办呢?
二、Kafka官方建议
关于上面这个问题,Kafka官方的Api文档中其实已有提到对应的一些建议:

翻译过来就是:

即:
方式1-One Consumer Per Thread:
也即本文开头部分提到的的默认方案,即一个Consumer一个线程。该方案最大的优点便是实现很简单,且对于消费速率要求不是很高的情况下,是完全能满足需要的(其实这种方式下的消息速率还是挺快的);但最大的缺点是消费线程受限于Topic分区数,只能通过不断增加Partition数量来提升消费能力的扩展性,而Partition的增长最终还是要受限于broker实例所在机器的资源限制,比如内存区域映射上限(vm.max_map_count)、最大文件打开数(max_open_file),一旦超出这些操作系统级别的资源参数上限,则会造成Kafka内存溢出,无法启动。
注:Linux操作系统的内存区域映射上限(vm.max_map_count)默认值为65530,而Kafka中一个Partition一般会至少对应到2个内存区域映射(index文件+log文件),这意味着每个broker实例只有达到3万多个Partition后,才有可能会超过默认的内存映射数上限。因此,在单个Broker的Partition数量要求不是非常多的情况下(一般也很少会在一个borker上建3万个Partition),该方案是可以完全满足要求的(可以在上线初始化Kafka配置时,为对应的Topic一次性多分配一些Partition),但要注意的是,随着Partition数量的日益增多,这种方案会造成客户端应用存在越来越多的线程资源占用以及大量的TCP网络长连接开销。
方式2-Decouple Consumption and Processing:
该方式可以认为是多线程的处理方案,思路也很简单,即将原来的消费线程分拆为2类线程(拉取线程、工作线程),通过这2类线程的分工合作来完成消息的消费:
拉取线程:只负责kafka消息的拉取、分发和消息offset的提交(可选),但不负责消息的业务处理。拉取线程的数量依旧要受Kafka的“一个Partition只能被该Group里的一个Consumer线程消费”规则的限制,即若该Group所订阅的Topic有N个Partition,则该Group最多只能有N个拉取线程。
工作线程:只负责处理消息的业务处理,但不负责kafka消息的拉取和offset的提交。拉取线程拉取到消息后,便可将消息分发给工作线程进行处理。比如拉取线程一次拉取到100个消息,分发给20个工作线程并行异步处理。
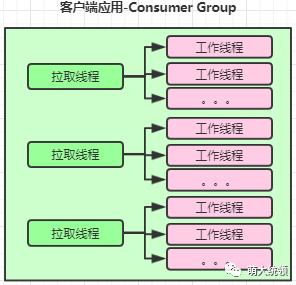
由于工作线程的数量不受Kafka内部规则的限制,且都是无状态的(都在客户端应用进程内),因此,采用该方式最大的好处是,可以在不用增加Partition数量的情况下,只需要增加工作线程数量,便可进一步提升Kafka客户端的并行消费能力,相对前面增加Partition数量的方式来说,该方式对客户端应用来说,是一种相对更为平滑透明、成本更低的扩展方式,且客户端的应用资源也能够得到充分利用。但缺点是,如果需要手动提交消费位移(offset),需要保证消费位移提交的一致性,实现复杂度会相对较高。
三、多线程消费方案
对于上面提到的方式2,可根据实际场景要求(至多消费一次、至少消费一次),来进一步细分为2种不同的多线程处理方案:
1.场景一:至多消费一次
如果你的实际业务场景对消息消费可靠性要求不高,只要求“至多消费一次”,则kafka的enable.auto.commit参数使用默认的true即可,即kafka客户端一拉取到消息后,就会自动提交消费位移(offset),不管消息后续是否有处理完成。
这意味着,拉取线程在拉取到消息,只需要分发给工作线程,之后的处理流程,就可以不管了,继续下次消息的拉取。至于工作线程是否有完成消息的业务处理,拉取线程不用关心,它只负责拉取和分发。因此这种处理方案的实现复杂度还是比较小的
两类线程的分工:
拉取线程:拉取对应Topic的消息,并将消息分发给工作线程
工作线程:完成消息的业务处理
如果不希望消息拉取后就自动提交消费位移(offset),而是希望在消息被工作线程处理完成后,再提交offset,又该如何处理呢?
答:可以考虑下面的方案二
2.场景二:至少消费一次
这种场景对消息的消费可靠性要求较高,消息被拉取到后,并不会自动提交offset,而是要等该消息的业务处理也全部完成之后,才会提交offset,否则会认为没有消费成功,会再次拉取重新消费,因此是“至少消费一次”。
该场景下,需将kafka的enable.auto.commit参数设为false,即禁止自动提交消费位移(offset)。
该场景与上面方案一最大的不同,是需要kafka客户端手动提交offset(类似于RabbitMQ中消费方的手动Ack),由于客户端对消息的消费是“多个拉取线程+多个工作线程”合作完成,对拉取线程一次拉取到的一批消息(假设为100个),这一批消息又是被多个线程并行消费处理,如何保证这一批消息的offset提交的一致性是关键所在,也是比较有挑战的一个设计要点。
这里简单说下目前我们用到的一种方案,该方案已在生产环境运行实践,目前无论是消费速率,还是稳定性,表现都还不错。
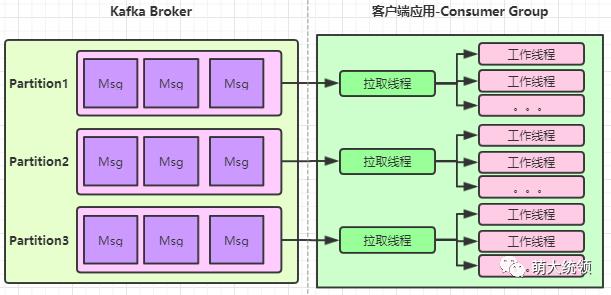
如上图所示,整体交互以及线程的分工与前面的“至多消费一次”是类似的,最主要的差异在于,工作线程和拉取线程分别多了一项工作:更新offset、提交offset。
两类线程分工:
拉取线程:拉取对应Topic的消息,并将消息分发给工作线程;同时异步提交已完成业务处理的消息的offset;
工作线程:完成消息的业务处理后,把该消息的offset同步更新到待提交的offset池子中(但不提交);
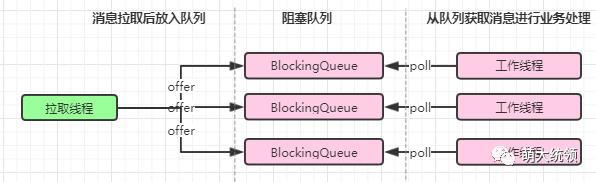
如上图所示,拉取线程与工作线程是通过阻塞队列来异步解耦,即每个工作线程都会有一个阻塞队列,拉取线程将拉取到的消息放入到该队列后就立即返回,工作线程会从该队列中获取消息,进行后续的业务处理。两者都是异步并行的。
如上图所示,通过一个公共的Map来暂存待提交的offset,该Map的key是消息所属Partition,value则是要提交的offset。能放入到该Map中的offset,说明其对应的消息已完成了业务处理。
offset的更新(工作线程)与offset的提交(拉取线程)则是通过该Map来异步解耦。工作线程完成该消息的业务处理后,就会把该消息对应的offset放入Map(更新该Partition最新完成的offset,但不提交),拉取线程则会一直检查该Map的每个Partition的offset是否有更新,若有更新,则就会提交该offset到Kafka。
引申思考:
方案二在落地实现过程中其实会涉及到不少注意点,此处只提出其中2个关键设计要点,各位可以思考下如何解决(受限于篇幅,本文不详细叙述这2个关键要点的具体设计细节):
设计要点1:消息offset提交的一致性如何保证?
这里的“一致性”可以理解为“客户端对于一个Partition的多个消息,最终提交的offset之前的offset对应的消息都已完成了业务处理”。采用本方案,则在很多地方都会遇到消息offset提交一致性的问题:
比如:
多线程环境下,对于拉取的同一批消息,如果高位offset消息先于低位offset消息完成业务处理,如何避免最终低位offset提交了(被误认为是最新的offset),而高位offset却没有提交?
多线程环境下,对于拉取的同一批消息,若高位offset先于低位offset完成处理,而有一个低位offset迟迟没有完成处理,此时,该如何避免该partition的offset提交一直处于等待中?
多线程环境下,对于拉取的不同批次的消息,在并行完成业务处理后,如何避免各批次要提交的offset不会相互干扰和覆盖?
友情提示:可以参考TCP的滑动窗口的思路,来解决Kafka在多线程方式下的消息offset手动提交的一致性问题。
注:RabbitMQ在消费方多线程下的手动Ack不会存在这个一致性问题,因为RabbitMQ没有消费位移,且不需要一直存储消息,用完即删:
RabbitMQ的队列本质上是单机的,不是分布式的。虽然可以有镜像队列,但镜像队列平时并不承担读写功能,只是作为主备用,发生故障转移时,镜像队列提升为Master后,才会接受读写。
RabbitMQ收到消费方的Ack回应也只是为了删除消息。因为RabbitMQ本身并不会将消息“一直”存储(Kafka则会默认存储7天),在确认该消息已被消费完成后,就会删除该消息。
设计要点2:消息的业务处理迟迟没有完成,该如何应对?
比如:
对于拉取的同一批消息(假设属于同一个Partition),如果高位offset对应的消息先完成业务处理,低位offset对应的消息却迟迟未完成业务处理,此时该如何应对?
消息一直在拉取,但消息的业务处理比较慢,导致放消息的队列都满了,则拉取的消息迟迟无法放入,拉取线程一直被阻塞,此时该如何应对?
友情提示:最终一致性、补偿重试
3.两种方案的比较:
相同点
这两种方案都可以在不增加Partition数量的情况下,提升Kafka的并行消费能力,进一步提升消费速率。
这两种方案都是将消费线程拆分为拉取线程与工作线程,通过增加工作线程来实现Kafka并行消费能力的扩展
这两种方案都需要尽量避免对消息的拉取能力与处理能力不匹配的问题。一般来说,消息的业务处理的耗时会高于消息的拉取的耗时,因此,如果拉取线程对消息的拉取速度过快,而工作线程对消息的处理较慢时,则可能会造成拉取线程一直阻塞,因为所有工作线程的队列都已经满了,拉取线程拉取的消息迟迟无法放入到其队列中。
这两种方案由于都是多线程异步并行处理消息的消费,因此要做好对消费失败或异常的处理机制,便于后续的补偿重试。
对于消息的重复消费的幂等处理依旧是必不可少的,这是消息消费幂等性的基本要求。
不同点:
方案一:至多消费一次
优点:这种方案的落地实现较为简单,性能上也较容易保证
缺点:消息消费的可靠性相对较低,因为只能保证“至多消费一次”,可能会存在消息丢失或未处理完就提交offset的问题。
适用场景:适用于对消费速率要求极高,但允许消息丢失或未处理完就提交offset的场景
方案二:至少消费一次
优点:可以兼顾消息消费的性能与可靠性,保证“至少消费一次”
缺点:异步解耦点较多,实现链路相对较长,且需要保证offset提交的一致性,实现复杂度相对较高
适用场景:适用于对消费速率要求极高,但不允许消息丢失,且希望消息都能尽量处理完再提交offset的场景
参考资料:
https://www.cnblogs.com/huxi2b/p/6124937.html
https://www.cnblogs.com/liuwei6/p/6905016.html
http://kafka.apache.org/23/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html
以上是关于kafka浅谈Kafka的多线程消费的设计的主要内容,如果未能解决你的问题,请参考以下文章