大数据浅谈Kafka的分区(Partition)
Posted 达摩院首座
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据浅谈Kafka的分区(Partition)相关的知识,希望对你有一定的参考价值。
上节课我们讲了反应数据流(Reactive Stream)--。今天我们来讲基于这一数据流类型的消息总线系统Kafka。
单纯地将Kafka理解为消息总线(Message Bus)并不全面,它除了能提供快速、可扩展、高可用(Kafka的高可用不一定需要分布式的多节点来实现)且持续的基于发布/订阅模式的总线服务外,你还可以把它看作可分布式的冗余的日志提交服务。
在Kafka消息总线中,消息的生产者和消费者是严格分隔开的,而任何客户端可以在Kafka消息缓存释放前(默认是7天,不管消息有没有被消费过)重播任何总线消息。
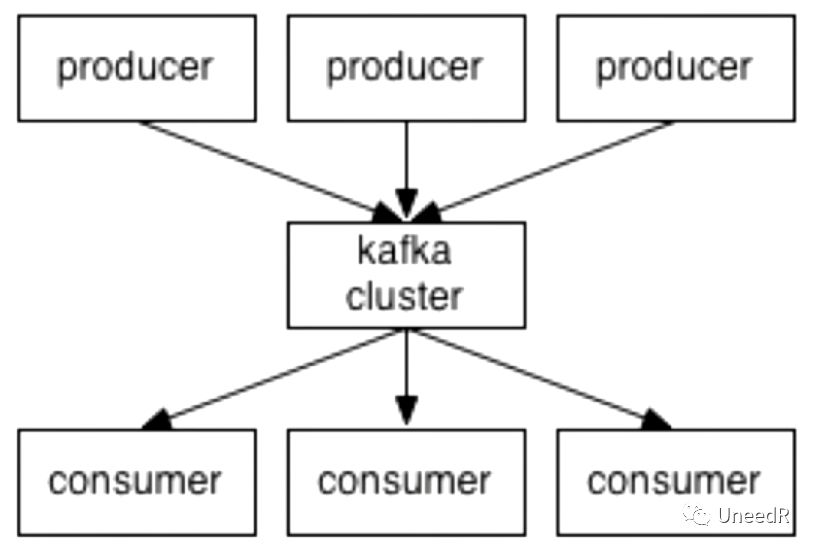
将Kafka视为日志提交服务的话,每一个数据流对应一个Topic,每一个Topic可以有多个Partition,Partition是每个Topic的全量副本,存放在任意一台Broker服务器上,服务器与Partition是一对多的关系,而每个Partition只能被一个消费者(跨Group情况除外)消费。
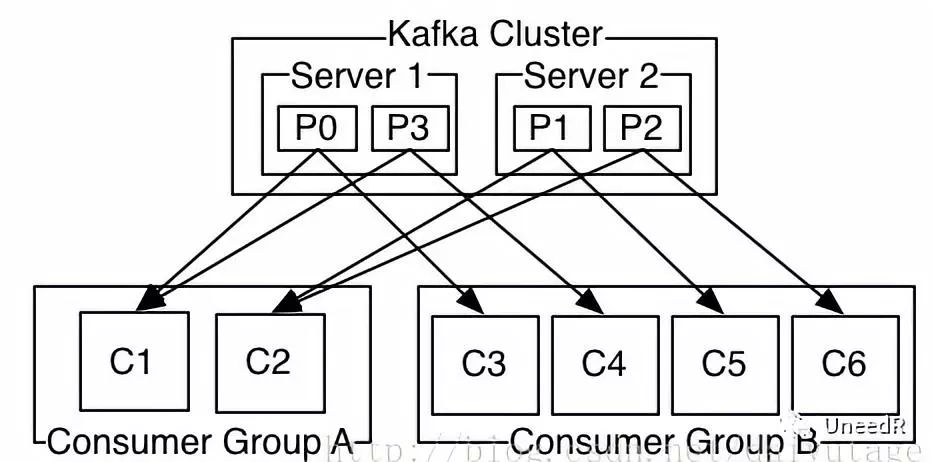
消息的生产者并不关心消息被分到几个Partition,但生产者会给消息配上私钥(Key),在传输时Kafka通过计算私钥的哈希值决定它属于哪个Partition,同时消息有先后顺序,且不能调整。没有私钥的消息会以轮询机制(Round Robin)投递。
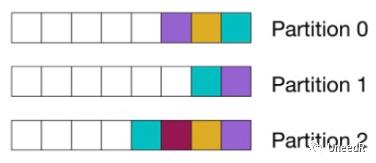
当然,我们上面也说到不同的Partition是给到不同的消费者的,所以我们也可以定制查询让特定的消息进入特定的Partition。
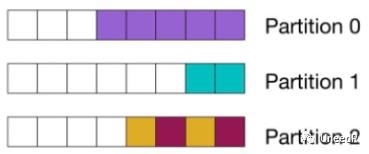
这样看起来,在partition这里就能完成目标消费者的精准投递,那面对多个消费者(组)的情况,我只要多建几个partition就可以了么?
情况并非如此简单。
首先,越多的Partition意味着越多的吞吐量。不管在生产端还是消费端,消息到所有Partition的写入都是同步进行的,一些复杂的运算(比如数据压缩)就会占用更多的硬件资源。
其次,越多的Partition需要越多的文件句柄(Open File Handles)。每个Partition都将一个目录映射给Kafka Broker,在这个日志目录中,每个日志分段(Segment)会有两类文件--索引和实际数据。目前的版本而言,Kafka Baoker会打开这两类文件的举兵。因此越多的Partition就以为着在Broker的系统层有越多的OpenFiles。当然,这只是个配置问题,实际环境中Kafka集群中每个Broker可以同时运行超过三万个文件句柄。
越多的Partition会降低可用性,尽管Kafka支持集群内复制,一个partition可以在跨broker的节点上存放多副本(Leader & Follower,见下图)
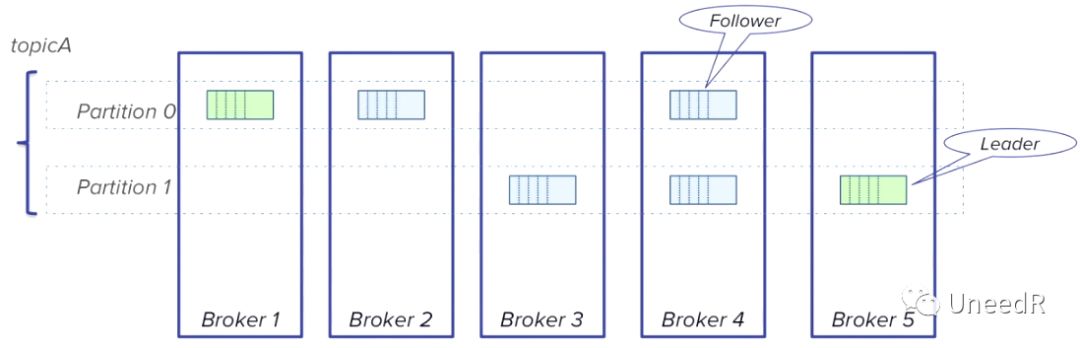
我们知道一般情况下,一个Broker发生了问题或正常关闭,zookeeper会及时发现并将Leader移至其他Broker节点。
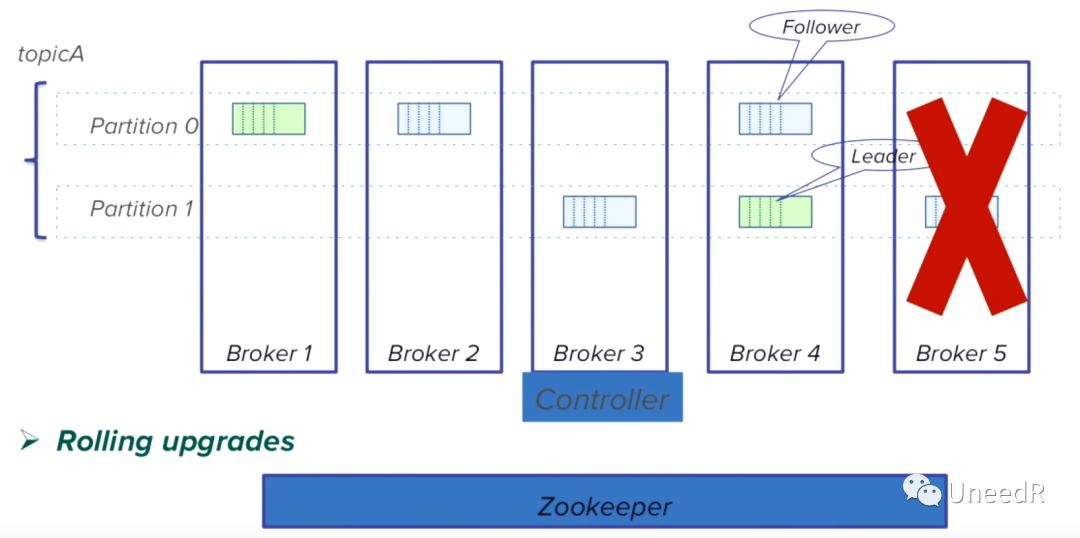
那么问题来了,如果broker进程非正常关闭(比如使用“kill -9 进程号”方式关闭)对于zookeeper来说就没那么容易恢复了。而如果此时我还有2000个partition队列,受影响的broker承担了其中400个partition的leader角色,那可用性就会大受影响了。
越多的Partition会增加端到端的延时。端到端的延迟指的是从生产者发布消息到消费者读取消息所花的时间,这其中涉及到提交偏移量(committed offset)的问题。实验数据显示,从一个broker复制1000个partition可以增加20毫秒的延时,这对一些实时性要求极高的消费者而言是几乎不可接受的。
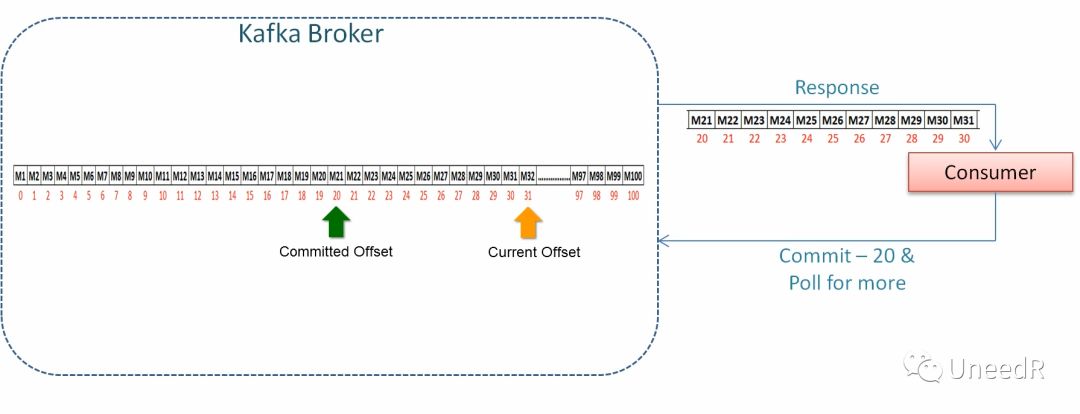
以上是关于大数据浅谈Kafka的分区(Partition)的主要内容,如果未能解决你的问题,请参考以下文章
大牛总结分享:大数据技术Storm和Kafka 哪些场景更适合