字符串匹配算法KMP详细解释——深入理解
Posted 无鞋童鞋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符串匹配算法KMP详细解释——深入理解相关的知识,希望对你有一定的参考价值。
1. 前言
字符串匹配是一个经典算法问题,展开来讲各类问题多达几十种,有名称的算法也不下三十种,所以需要深入学习的东西有很多。这次我们来探讨一个最简单的问题,假设现在随机输入一个长度为m的主串T,另外输入一个长度为n(n≤m)的字符串P,我们来判断字符串P是否是主串T的一个子串(即能否从T中随机取出与P同长的一段字符串,与P完全匹配)。
2. 蛮力匹配法
问题很简单,当然也有最直接、最直观也是最好想到的方法,蛮力串匹配。即两个字符串像物流传送带一般,主串固定,子串一步步像前移动,一位位匹配比较,直到完全匹配找到想要的结果的位置。效果即如下图所示,将T长度为m的m - n+1个子串逐一和P进行比对,发现完全每一位匹配的位置即我们需要的结果。图中P字符串上黑色表示该位已成功匹配,而绿色表示当前匹配未成功的位置,白色表示未匹配字符位置。

蛮力解法的代码如下:
#include<stdio.h>
#include<string.h>
int stringMatch(char* T,char* P,int nLenT, int nLenP)
int i = 0, j = 0;
while(i<(nLenT- nLenP+1)) //i最大位置仅能取到nLenT- nLenP
if(T[i+j] == P[j]) //当子字符串开头匹配就一直判断下去
if(j == nLenP -1)//当整个字符都匹配返回i的位置
return i;
j++; //未匹配完成,则匹配下一位
else //如果不匹配则i位置+1,j从头开始
i++;
j=0;
return -1;
int main()
char T[100] , P[100];
int nLenT , nLenP;
int nRel;
while(scanf("%s%s",&T,&P))
nLenT = strlen(T);
nLenP = strlen(P);
nRel = stringMatch(T,P,nLenT,nLenP);
printf("%d\\n",nRel);
return 0;
上面程序很好理解,就是从位置0开始,先固定当前主串的位置i,然后一一比较主串下面m个字符是否和P完全匹配,匹配则输出主串中位置i。一旦这个m位比较过程中,如果发生当前字符不匹配的情况,则主串i的位置相比较这次匹配开始位置增加1,准备进行下一次比较,而j自然复位到字符串P的首字符地方。一般情况下,我们知道m远小于n的,这样蛮力匹配算法的总体时间复杂度为O(n×m)。当然,蛮力匹配算法的写法有很多,也不一定就是上面的形式,但是只要不发生质的改变,所有的蛮力匹配算法写法时间复杂度是不会发生改观的。
但是,蛮力算法明显时间复杂度过高,不适合规模稍微大一些的应用环境,因此就需要改进。这里我们观察不难发现,蛮力算法之所以需要大量的时间,是因为存在大量的局部匹配,而且每次匹配一旦失配,主串和模式串的字符指针都需要回退,并从头开始下一轮的尝试。实际上,我们在整个过程中重复了很多操作,因为在完全成功匹配之前,我们曾经很大可能匹配成功过很多次部分字符。只要充分利用这些信息,就可以不需要让主串完全回退到上次开始比较的下一个字符,模式串一样的道理,这样就可以大大提高匹配算法的效率。下面我们就来看看关于这个问题改进的算法KMP的原理。
2. KMP算法
KMP算法是根据三位发明者 Knuth、Morris 和 Pratt 名字的首字母命名的。在介绍之前,我们详细看看下面这张图:
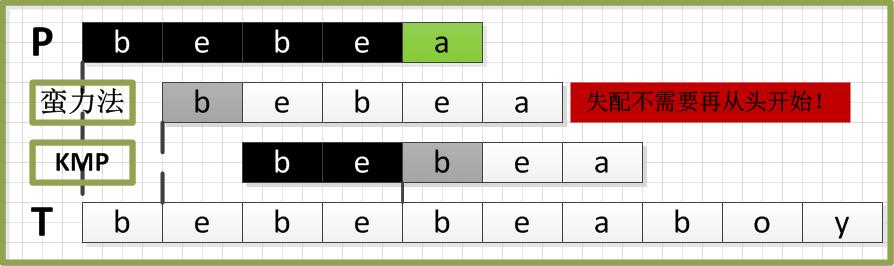
当第一轮对比进行到最后一对字符的时候,由于’a’和’b’发生失配,如果是蛮力算法将会让这两个字符指针回退(即主串i = i-j+1,和模式串j=0),然后又从头一一对比。然而事实上,指针i完全不必要回退,通过第一轮比对我们清楚的知道,主串T的子串substr(T,i-j,j)的第三位和第四位其实和模式串P前两位是完全匹配的,并且模式串P第一位也并不等于主串T第二位,所以可以直接将模式串P直接移到主串第三位对齐,并且前两位不需要比较,直接从第三位开始继续比较即可。
那么一般性的问题就来了,模式串P在任何上次失配情况下,应该右移几个单元,并且从第几位开始比较呢?这就是KMP中next表应该完成的工作了。
2.1 next表理解
一开始我就要强调一下,next表都是基于模式串,即子串来建立的。next表决定了当两个字符串一个个字符匹配的时候出现失配,应该回退到哪,即失配回退是根据失配那一位的next值所决定。回退的规则简单来说也就是一句话:返回失配位之前最长公共前后缀对应的前缀后一位的地方。怎么理解这句话呢?先看下图:
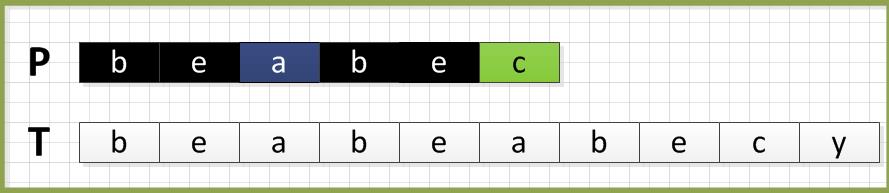
上面的话需要分为“最长公共前后缀”和“前缀后一位”两部分来理解。当P和T匹配遇到”c”发生失配,那么现在P应该从“c”回退到第几个字符,完全由“c”前面子字符串“beabe”所决定。我们看到这个字符串是关于“a”前后对称,也就是说最长的公共前后缀就是“be”,那么下一次比较的开端就是前缀“be”后一位“a”。下一次匹配移动如下:

公共前后缀的理解如下图所示:

红色部分就是公共的前后缀了!
2.2 next表如何建立
next表的每一位反映该位失配后回退的地方,它是由前一位字符在整个前子字符串中最长公共前后缀的长度值所决定(说的有些绕口。。),我们还是直接看下面的总结:
①、第一位字符的next值设置为-1,因为当第一位就开始失配,直接将模式串下移一位即可,无需多说。同样道理,第二位也一样,其前子字符串仅一个字符,所以next值即为0。
②、后面的,当某位前一位字符的前一个字符对称程度为0的时候,只要将该位前一位字符与子串第一个字符进行比较即可。例如abcdae,因为“d”字符与前面无对称项,所以只需要比较a和开头字符比较即可。
③、以此推理,如果某位前一位字符的next值是1,即该位前一位字符的前一个字符与开头字符相等,那么我们就把该位前一位字符与子串第二个字符进行比较,如果也相等,说明对称程度就是2了,即该位的next值为2。
④、当然如果一直相等,就一直一位位累加继承。但是绝大多数不可能会如此顺利对称下去,如果遇到下一个不相等了,那么说明不能继承前面的对称性了。这种情况只能说明没有那么多对称了,但是不能说明一点对称性都没有,所以遇到这种情况就要重新来考虑,这个也是难点所在。
④、一旦发生不能累加继承,则需要在对称的前后缀字符串中继续寻找子对称。如下图所示:
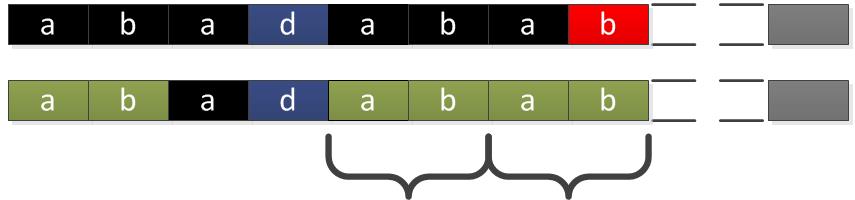
“abadabab… …”中“b”不能继续继承前面的对称序“aba”,所以下一步做的在对称序中继续找次对称序,最后发现子对称“ab”。如果未能成功寻找到则b后一位的next值为0。
2.3 KMP程序
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define N 100
void cal_next( char * str, int * next, int len )
int i, j;
next[0] = -1;
for( i = 1; i < len; i++ )
j = next[ i - 1 ];
while( str[ j + 1 ] != str[ i ] && ( j >= 0 ) )
j = next[ j ];
if( str[ i ] == str[ j + 1 ] )
next[ i ] = j + 1;
else
next[ i ] = -1;
int KMP( char * str, int slen, char * ptr, int plen, int * next )
int s_i = 0, p_i = 0;
while( s_i < slen && p_i < plen )
if( str[ s_i ] == ptr[ p_i ] )
s_i++;
p_i++;
else
if( p_i == 0 )
s_i++;
else
p_i = next[ p_i - 1 ] + 1;
return ( p_i == plen ) ? ( s_i - plen ) : -1;
int main()
char str[ N ] = 0;
char ptr[ N ] = 0;
int slen, plen;
int next[ N ];
while( scanf( "%s%s", str, ptr ) )
slen = strlen( str );
plen = strlen( ptr );
cal_next( ptr, next, plen );
printf( "%d\\n", KMP( str, slen, ptr, plen, next ) );
return 0;
上面KMP程序摘自下面篇博文:
http://blog.csdn.net/u011564456/article/details/20862555utm_source=tuicool&utm_medium=referral
本文内容主要参考自:
博文:
http://blog.csdn.net/u011564456/article/details/20862555utm_source=tuicool&utm_medium=referral
邓俊辉 《数据结构(C++)》
个人学习记录,由于能力和时间有限,如果有错误望读者纠正,谢谢!
转载请注明出处:CSDN 无鞋童鞋
以上是关于字符串匹配算法KMP详细解释——深入理解的主要内容,如果未能解决你的问题,请参考以下文章