如何在STM32上部署卷积神经网络(纯C语言搭建)
Posted 断水客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在STM32上部署卷积神经网络(纯C语言搭建)相关的知识,希望对你有一定的参考价值。
0、前言
本文是什么
假如你已经使用PyTorch或者TensorFlow训练了一个卷积神经网络,得到了各层参数,却希望用C语言把这个部署到STM32等单片机上,那么就可以看看这篇文章啦。
本文虽然主要介绍怎么搭建lenet-5这个网络,但卷积神经网络的卷积、池化、拉直、全连接、激活等基本操作是独立给出的,没有高耦合,完全可以用这些操作自行搭建其他网络。
本文不是什么
加入你尚没有训练得到网络的参数,甚至还不知道什么是卷积神经网络,那么本文可能对你没有太多帮助。不过,这些兄弟也可以从文中的简介中对神经网络有个初步的了解。
1、研究对象
顾名思义,可以把卷积神经网络理解为加了“卷积”操作的深度学习网络。
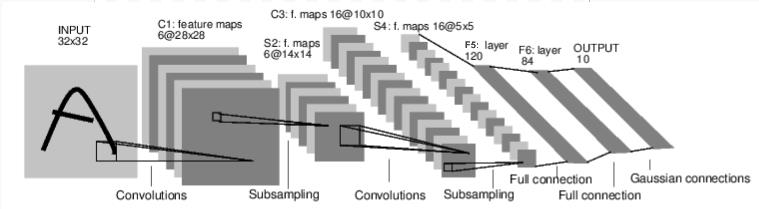
上面这张图是论文
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
中的网络的结构图。这个网络名为lenet-5,是卷积神经网络的经典之作。虽然比起现在的深度学习网络来说过于简陋,但它几乎包含了现代卷积神经网络中的所有要素。这篇文章将拆解这个网络,一步步用C语言实现一个类似的网络。
2、卷积神经网络的组成
再复杂的对象都有组成元素,论文里的那张图就至少可以分成两部分——数据和操作。下图中我用黑色箭头标出来灰色方块就是数据,而连接灰色方块的那些线则代表某种操作。
这样,lenet-5等卷积神经网络就可以看作对输入数据的一些列处理的组合。
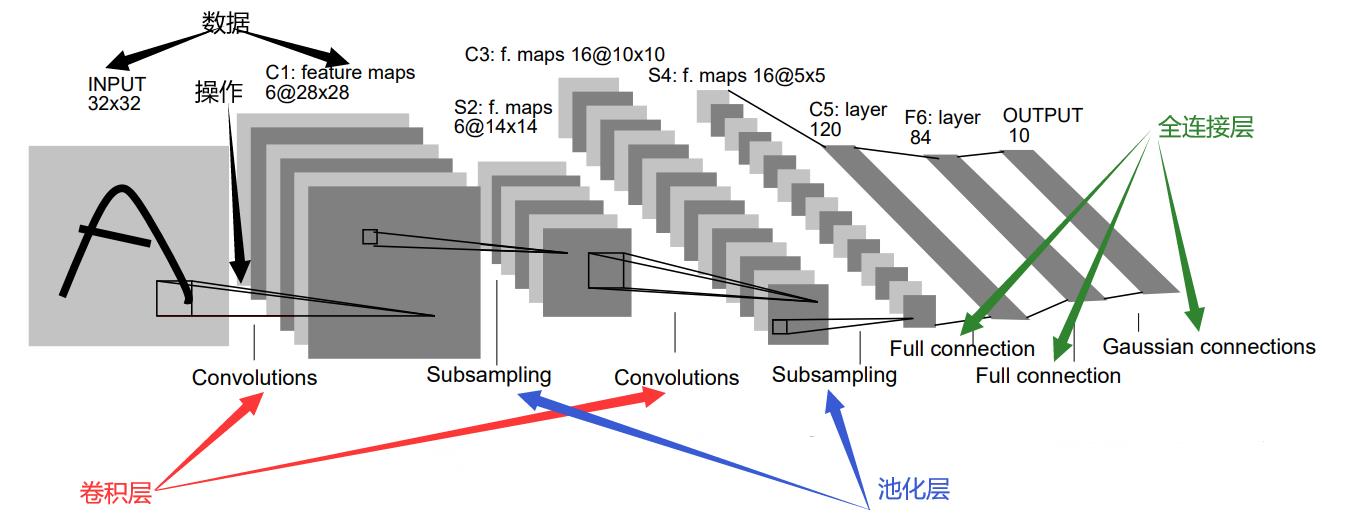
那么具体有那些处理方法呢?还是看这张图,红色箭头标注的是卷积处理,蓝色箭头标注的是池化处理,绿色箭头标注的是全连接处理。习惯上,我们把每次处理都看作一层,所以又可以说这个网络是由两个卷积层、两个池化层和三个全连接层组成的。
注意哈,原文的输出是高斯连接(Gaussian connections),本文则把它视作普通的全连接层,这个没啥影响的。
3、确定任务
我们已经知道,神经网络里面有卷积、池化、全连接等处理方法。但并不是只有这些操作的。
拉直
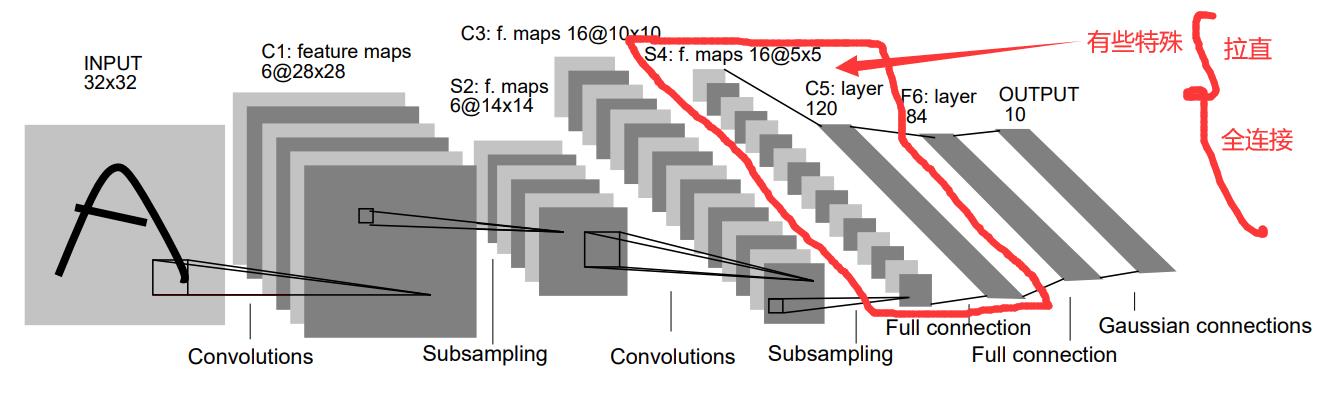
看上面这张图,红线圈中的部分有些特殊。16个矩阵形的数据经过这一层处理以后变成了长度为120的向量,这显然是和后面的两个全连接层不同的。
事实上,这一层在做全连接之前,是把输入的矩阵“拉直”成向量了的。
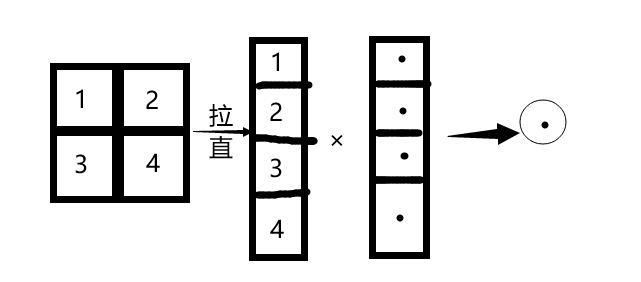
“拉直”处理如上图所示。全连接处理则是将拉直结果与一个等长的向量叉乘,得到一个数,就全连接层输出向量的一个元素。这样,每个输入都拉直、做叉乘得到一个数,组成了一个向量,就是这个特殊的全连接层的输出。
那么,后面的那两个全连接层怎么办呢?答案当然是不用再做拉直处理了呀,直接跟向量叉乘,跟有多少个向量叉乘,输出的那个向量的长度就有多长。
而那些向量的值,就是通过训练得到的参数。
激活函数
除了拉直,咱还不能忘了激活函数,对本文将要搭建的网络来说,每一层处理之后都要加上一个激活函数。激活函数有好几种可供选择,我们选用的是relu函数,它的函数图像如下,实现起来也很简单。
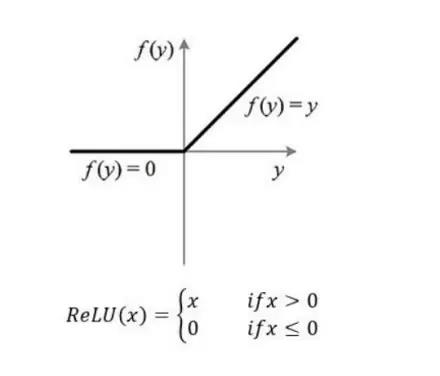
这样,我们就明确任务了,至少要编写这么几个处理函数:
- 卷积处理
输入可能是多个多维矩阵的形式 - 池化处理
与卷积层类似 - 全连接
第一层全连接之前先做平化处理 - 平化处理(拉直处理)
把矩阵变为向量 - 激活函数
对输入矩阵/向量中的每一个元素做映射
4、组件介绍
要用C语言实现上述的那些处理方法,需要做哪些准备呢?我们直接看看头文件吧。
4.1 矩阵操作(matoperation)
首先是输入的尺寸结构体imageSize,考虑到通用性,咱把给它设置了数量、维度、行数、列数四个参数,可以支持对四维数据的描述。
然后是两个二维矩阵相关的操作,矩阵最大值坐标matOperationMaxIt()和矩阵扩大matOperationEdgeExpand()
//矩阵尺寸
typedef struct IS
int numsc;//数量
int dimsc;//维度
int rowsc;//行数
int colsc;//列数
imageSize;
void matOperationMaxIt(float** mat,imageSize matSize,int* it);
float** matOperationEdgeExpand(float** mat, int r,int c, int addc, int addr);
4.2 CNN算子(cnnoperation)
这部分是卷积神经网络的基本处理方法,包括卷积处理cnnOperationConvolution()、池化处理cnnOperationPooling()、扁平化操作cnnOperationLinear()和激活函数cnnOperationActivation()。
//卷积处理
void cnnOperationConvolution(float*** inputmat,imageSize inputSize,
float*** outputmat,imageSize outputSize,float**** kernel,imageSize kernelSize,
int paddding,int step);
//池化处理
void cnnOperationPooling(float*** inputmat, imageSize inputSize,
float*** outputmat, imageSize outputSize,
imageSize kernelSize, int padding,int step);
//全连接处理 一维化然后进行全连接运算
void cnnOperationLinear(float*** inputmat, imageSize inputSize,
float*** outputmat, imageSize outputSize,float** weight,float* bias);
//扁平化
void cnnOperationFlatten(float*** input,imageSize inputsize, float*** output,
imageSize outputsize);
//激活函数
void cnnOperationActivation(float*** inputmat, imageSize inputSize, float bias);
4.3 网络搭建
为了方便兄弟们理解怎么用这些组件,我用前面那些组件搭了一个类似于lenet5的分类网络,暂且称之为lenet5Improved,可以使用lenet5Improved()这个函数调用。
int lenet5Improved(float*** input,imageSize inputSize);
这个网络使用PyTorch训练,它的结构如下。
Conv2d是卷积层,参数按顺序分别是卷积核的维度、卷积核的数量、卷积核的边长、padding数。比如,第一层卷积层有6个卷积核,每个卷积核都是三维的,卷积核大小是5×5。
/*
各层参数说明
net=torch.nn.Sequential
nn.Conv2d(3,6,kernel_size=5,padding=2),nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),nn.Flatten(),
nn.Linear(576,120),nn.ReLU(),
nn.Linear(120,84),nn.ReLU(),
nn.Linear(84,2)
*/
下图为lenet5Improved()的实现,红色箭头标出卷积层的位置,蓝色箭头标出池化层的位置,绿色箭头标出全连接层的位置,黑色箭头标出扁平化处理的位置。每一层处理后面都跟上激活函数。

不要看着图片这么长就觉得很复杂,其实主要是做了动态分配的代码比较占位置,咱们可以拿第一层卷积层来看看。
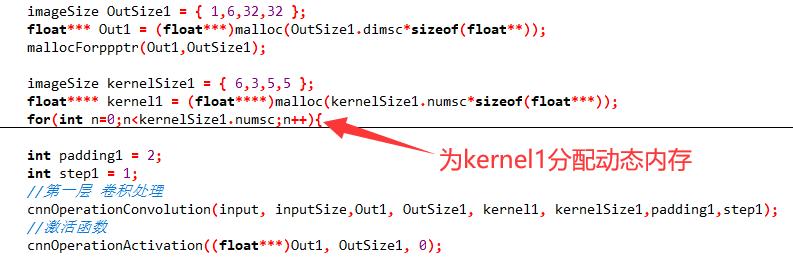
就这几行
OutSize是第一层输出的大小,初始化为1个、6维、32×32的矩阵。Out1用来存储第一层的输出,mallocForppptr()给它分配动态内存。kernelSize是这层卷积核的大小,初始化为6个、3维、5×5的矩阵。- 卷积处理以后,卷积层的输出存在
Out1中,用激活函数对每个数据做激活处理
其他层的处理都是类似的。
5、训练参数的使用
搭建网络是为了部署训练好的网络,那么怎么把训练得到的参数导入这个C语言搭起来的网络里呢?
前面不是为kernel等变量分配了动态内存嘛,就是用来存这些参数的。
训练得到的参数也就两种,一种是卷积层的卷积核里面的值,另一种是全连接层的那些和拉直处理后的输入做叉乘的向量的值(权重),以及偏差(bias)。把这些参数写成常量数组,就可以烧进单片机里面,运行的时候放到动态内存里面用传进处理函数就行啦。就像下面这样。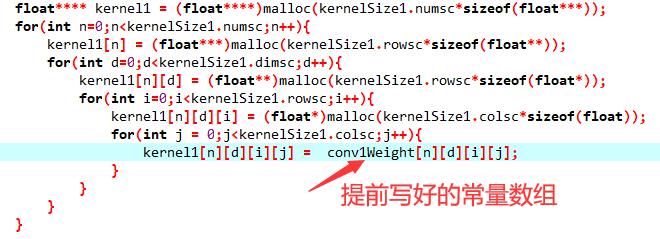
6、源代码
为了方便大伙参考,我把源代码放到Gitee上啦,需要的点这个就行。
以上是关于如何在STM32上部署卷积神经网络(纯C语言搭建)的主要内容,如果未能解决你的问题,请参考以下文章
在 STM32CubeIDE 上打印(用 C 语言)到 IDE 控制台
JSON数据格式C语言解析库(cJSON)的使用&在STM32上移植和使用