恒源云_AIphaCode是否能取代程序员?
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云_AIphaCode是否能取代程序员?相关的知识,希望对你有一定的参考价值。
文章来源 | AI科技大本营
原文地址 | AIphaCode 并不能取代程序员,而是开发者的工具
编译 | 禾木木
首先,开篇我就得先夸一家自己家的大佬们,文章写的那是一绝!
我们恒源云社区的深度学习文章,一篇比一篇优秀,譬如下方的任意一篇,每一篇都是知识点满满!
当然了,如果看完社区的内容后你们还觉得不过瘾,不要着急,我又从别的地方搬运了一篇超棒的文章给大家学习。
来来来,快跟随我的脚步👣,瞅一瞅有没有你感兴趣的点吧~
正文开始
DeepMind 是 AI 研究实验室,它引入了一种深度学习模型,可以生成具有显著效果的软件源代码。该模型名为 AIphaCode,是基于 Transformers,OpenAI 在其代码生成模型中使用的架构相同。
编程是深度学习和大型语言模型的有前景的应用之一。对编程人才日益增长的需求刺激了创造工具的竞赛,这些工具可以提高开发人员的工作效率,并为非开发人员提供工具来创建软件。
而在这方面,AIphaCode 确实给人留下了深刻的印象。它成功地解决了复杂的编程挑战,这些挑战通常需要数小时的规划、编码和测试。它可能会成为将问题描述转化为工作代码的好工具。
但它不等同于任何级别的人类程序员。这是一种完全不同的软件创建方法,如果没有人类的思考和直觉,这种方法是不完整的。

编
码
竞
赛
编码竞赛
编码竞赛

AIphaCode 并不是唯一的,但它完成了一项非常复杂的任务。其他类似的系统专注于生成简短的代码片段,例如执行小任务的函数或代码块(例如,设置 Web 服务器,从 API 系统中提取信息)。虽然令人印象深刻,但当语言模型暴露于足够大的源代码语料库时,这些任务就变得微不足道。
另一方面,AIphaCode 旨在解决竞争性编程问题。编码挑战的参与者必须阅读挑战描述,理解问题,将其转化为算法解决方案,以通用语言实现,并针对一组有限的测试用例进行评估。最后,他们的结果是根据在实施过程中不可用的隐藏测试的性能进行评估的。编码挑战也可以有其他条件,例如时间和内存限制。
基本上,参与编码挑战的机器学习模型必须生成一个完整的程序,用来解决它前所未有的问题。


T
r
a
n
s
f
o
r
m
e
r
和
大
型
语
言
模
型
的
力
量
Transformer 和大型语言模型的力量
Transformer和大型语言模型的力量
AlphaCode 是大型语言模型在解决复杂问题方面取得进展的又一个例子。AlphaCode 是大型语言模型在解决复杂问题方面取得进展的又一个例子。这种深度学习系统通常被称为序列到序列模型 (Seq2seq)。
Seq2seq 算法将一系列值(字母、像素、数字等)作为输入,并生成另一个值序列。这是机器翻译、文本生成和语音识别等许多自然语言任务中使用的方法。
根据 DeepMind 的论文,AlphaCode 使用了一种编码器-解码器 Transformer 架构。近年来,Transformer 变得特别流行,因为它们可以处理大量数据序列,并且比其前身循环神经网络 (RNN) 和长短期记忆网络 (LSTM) 所需的内存和计算需求少得多。
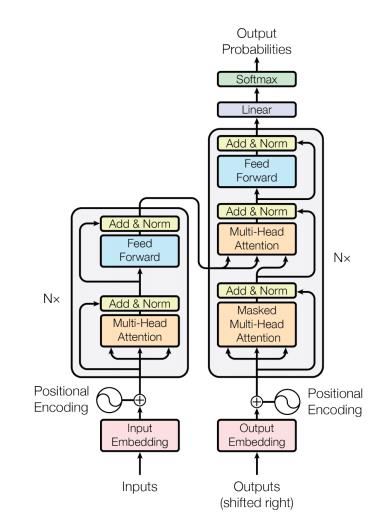
AlphaCode 的编码器部分为问题的自然语言描述创建了一个数字表示。解码器部分获取编码器产生的嵌入向量,并尝试生成解决方案的源代码。
事实证明,Transformer 模型擅长此类任务,尤其是在为它们提供足够的训练数据和计算能力的情况下。但在研究者看来,AlphaCode 的真正出色之处不仅仅是将原始数据投入到超大型神经网络中的强大功能,更多地在于 DeepMind 的科学家们在设计训练过程以及生成和过滤它的算法方面的独创性有关。

无
监
督
和
监
督
学
习
无监督和监督学习
无监督和监督学习
为了创建 AlphaCode,DeepMind 的科学家结合了无监督预训练和监督微调。通常被称为自我监督学习,这种方法在没有足够标记数据或数据注释昂贵且耗时的应用程序中变得流行。
在预训练阶段,AlphaCode 对从 GitHub 提取的 715GB 数据进行了无监督学习。通过尝试预测语言或代码片段的缺失部分来训练模型。这种方法的优点是它不需要任何类型的注释,并且通过接触越来越多的样本,ML 模型在为文本和源代码的结构创建数字表示方面变得更好。
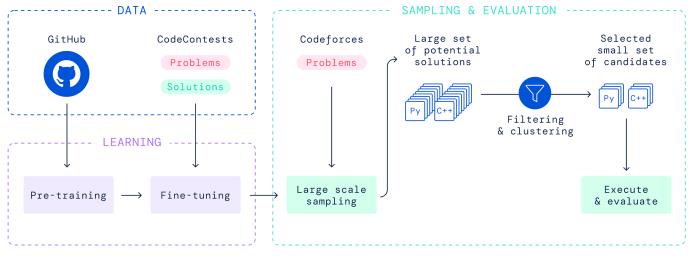
然后在 CodeContests(DeepMind 团队创建的带注释数据集)上对预训练模型进行微调。该数据集包含问题陈述、正确和错误的提交以及从各种来源收集的测试用例,包括 Codeforces、Description2Code 和 IBM 的 CodeNet。该模型经过训练,可以将挑战的文本描述转换为生成的源代码。它的结果通过测试用例进行评估,并与正确的提交进行比较。
在创建数据集时,研究人员特别注意避免训练、验证和测试集之间的历史重叠。这确保了 ML 模型在面临编码挑战时不会产生记忆结果。

代
码
生
成
和
过
滤
代码生成和过滤
代码生成和过滤
一旦 AlphaCode 接受了训练,它就会针对以前从未遇到过的问题进行测试。当 AlphaCode 处理一个新问题时,它会产生很多解决方案。然后,它使用过滤算法选择最佳 10 名候选人并将其提交给比赛。如果其中至少有一个是正确的,则认为该问题已解决。
根据 DeepMind 的论文,AlphaCode 可以为每个问题生成数百万个样本,尽管它通常会生成数以千个解决方案。然后对样本进行过滤,只包括那些通过问题陈述中包含的测试的样本。据该论文称,这会删除大约 99% 的生成样本,但仍然留下了数千个有效样本。
为了优化样本选择过程,使用聚类算法将解决方案分组。据研究人员称,聚类过程倾向于将工作解决方案组合在一起。这使得找到一小部分可能通过竞争隐藏测试的候选人变得更加容易。
根据 DeepMind 的说法,在流行的 Codeforces 平台上的实际编程比赛中进行测试时,AlphaCode 平均排名前 54%,考虑到编码挑战的难度,这非常令人印象深刻。

A
I
V
S
人
类
AI VS 人类
AIVS人类
DeepMind 的博客正确地指出,AlphaCode 是第一个“在编程竞赛中达到具有竞争力的性能水平”的 AI 代码生成系统。
然而,却有人将这种说法误认为人工智能编码“和人类程序员一样好”这是谬误的将狭义的人工智能与人类解决问题的一般能力进行比较。
例如,DeepBlue 和 AlphaGo,它们是击败国际象棋和围棋世界冠军的人工智能系统。虽然这两个系统都是计算机科学和人工智能的了不起的成就,但它们只擅长一项任务。他们无法在任何其他需要仔细计划和制定战略的任务上与人类对手竞争,这些都是人类在成为国际象棋和围棋大师之前获得的技能。
关于竞争性编程也可以这样说。一位在编码挑战中达到竞争水平的程序员已经花费了数年的时间学习。他们可以抽象地思考问题,解决更简单的挑战,编写简单的程序,并表现出许多其他在编程比赛中被视为理所当然且未评估的技能。
简而言之,这些比赛是为人类设计的。你可以肯定,一般来说,在竞争性编程中排名靠前的人就是一个优秀的程序员。这就是为什么许多公司利用这些挑战来做出招聘决定的原因。
另一方面,AlphaCode 是竞争性编程的捷径——尽管它非常出色。它创建了新颖的代码,不会从其训练数据中复制粘贴。但它并不等同于普通程序员。
因此,与其让 AlphaCode 与程序员竞争,我们更应该对 AlphaCode 和其他类似的 AI 系统在与人类程序员合作时能做什么更感兴趣。这些工具可以对程序员的生产力产生巨大影响。它们甚至可能改变编程文化,将人类转向制定问题(仍然是人类智能领域的学科)并让人工智能系统生成代码。
但程序员仍将处于控制之中,他们必须学会利用人工智能生成代码的力量和局限性。
以上是关于恒源云_AIphaCode是否能取代程序员?的主要内容,如果未能解决你的问题,请参考以下文章
恒源云_CIFAR-10数据集实战:构建ResNet18神经网络