大型有状态服务基于 K8s 的落地实践——按部门租户隔离
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大型有状态服务基于 K8s 的落地实践——按部门租户隔离相关的知识,希望对你有一定的参考价值。
作为一个容器化平台,在容器隔离的基础上,为什么还要租户隔离?
一方面,目前容器隔离还有一定的局限性,准确的说,是无法做到宿主机资源 100% 隔离;另一方面,是平台层面对业务线占用资源的限制和隔离,譬如说不让 A 部门强占 B 部门申请的机器资源等。
有时候能用代码解决的问题都是小问题,人与人之间的协同合作才是真正关系到效率的问题。
实际案例
我们都说容器使用 cgroup 保证了宿主机资源的隔离,但实际上目前 docker 的隔离功能还没有涉及到磁盘、网卡等资源上,甚至对 CPU 和 Memory 也还没做到 100% 隔离(比如说 CPU node)。
在没有任何资源的超卖的前提下,我举几个实际场景中发生的案例。
案例一:同宿主机 CPU/Memory 竞争造成性能下降
A 组、B 组的应用调度到不同机器上,性能正常;但处于同台机器上,会造成性能下降,初步怀疑是同时竞争 CPU 造成的。
有人说是因为没有对 CPU 绑核,导致 Pod 运行时频繁切换 CPU 导致,这也是一种思考的角度。
案例二:磁盘 iops 竞争
缓存和数据库应用调度到同台机器(两者都依赖本地 SSD),当数据库归档时占用大量 iops,会影响缓存应用对 SSD 的读写性能。
随后,数据库实例成了 “众矢之的”,因为这类应用需要配备大规格 SSD,高峰时会占用大量磁盘读写。其他部门组的实例都不愿意和他们一起混布在同宿主机上。
案例三:高性能机型被竞争
A 组因为准备活动,申请了一批高性能机器扩容。同时,B 组扩容,我们会对 B 组的扩容配额做限制,但是无法防止 B 组的实例占用 A 组申请的机器。同时 A 组的实例也有可能扩容到普通机器池中去。
此时,A 组的需求是:申请的高配机器只希望运行本组的应用实例。
案例总结
通过案例一,二的例子,我们发现容器的隔离性还无法 100% 保证,具体原因有很多,也比较复杂,需要专业人士分析解答。
而案例三的例子,我们认为像 A 组这样的诉求,即本组的应用实例只运行在本组申请的机器上,是合理的。
方案设计
整体上,一个 namespace 对应一个部门或小组,通过对 namespace reource quota,限制该部门或小组的资源使用额度。
具体的,如果纯粹使用亲和性(Affinity)来控制,那么需要配置的规则很多,管理起来很复杂,甚至会对调度造成压力。下面举几个例子说明:
1、各业务线应用不愿意和存储组的应用混布,那平台对所有应用施加一个和存储组的排斥关系(antiAffinity)。
2、实际上,存储组也不愿意和其他组混布,因为存储组申请的机器往往有高性能的 SSD,他们也不愿意这批机器被其他组占用 CPU 和内存,那就要对这批机器节点配置相关的 Taints 和 Tolerations。
3、就算在同一组里,也会有被 “嫌弃” 的应用。比如说搜索组也会有缓存或者存储类应用对磁盘读写敏感,也有 AI 数据模型应用对 CPU 敏感(甚至是 GPU),这些服务应用也希望和本组内的其他服务应用隔离开。
我们的方针--分治:先分大组,将原本复杂的问题限制到各个业务线内部;组内定档,将现有的资源按性能定档,组内应用主动适配。
先分大组
1、一个 namespace 对应一个部门组;
1、将机器按照所属部门组进行划分,为节点 Node 打上指定 label;
2、一个 namespace 下的所有 Pod 都标记 nodeSelector(也可以通过父级对象的中 podTemplate.nodeSelector),通过 nodeSelector 调度到部门组机器上。
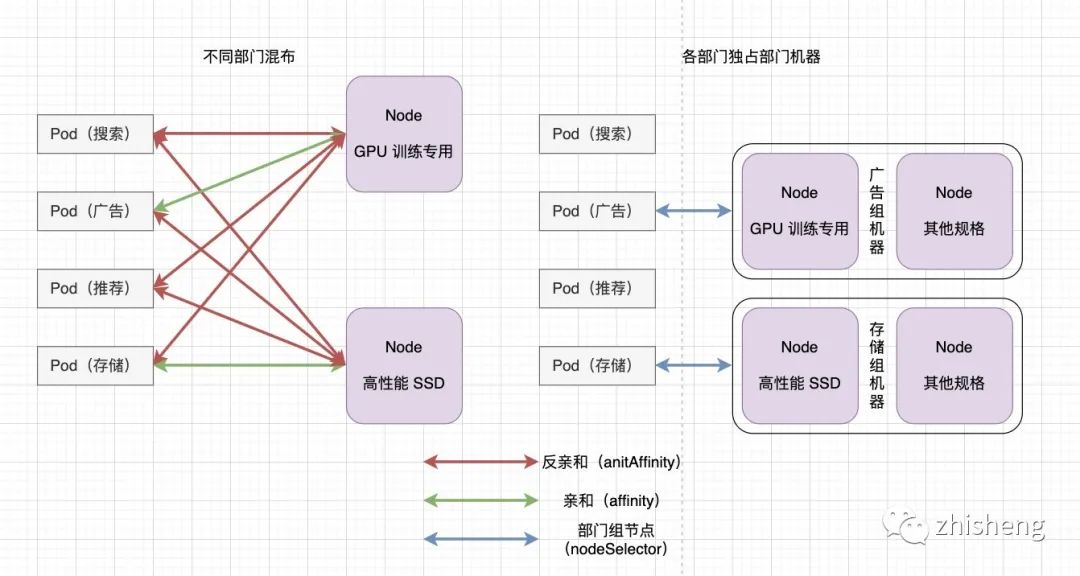
通过上图,我们期望:
广告部门的应用调度到 GPU 机型上;
存储部门的应用调度到高性能 SSD 机型上;
为了达到目的,左边采用的间接的方式(Pod 和 Node的亲和性 Affinity),右边采用的是直接的方式(Pod 和 Node 的选择性 nodeSelector)。明显,右边的方式更简单,更方便管理。
补充一下,Affinity 的逻辑计算会对调度器造成很大的负担,特别集群规模比较大的情况下,我们尽可能减少使用 Affinity。
总结
当 Pod 与 Pod 相互影响的时候,如果是同部门组的应用,那就可以直接交给该部门组的研发去调整;但是如果是跨部门的应用,那要请两边的研发同学去调查,这个事情就复杂了。当前按部门做租户隔离还有避免部门间相互推诿的好处。
本篇通过部门隔离的方式,将整个复杂问题分割成业务部门各自管理资源分配的小问题。至于如何在业务部门的范畴内,进一步解决问题,会在后面文章讲到。
原文:https://blog.ppistechnology.top/2021/08/10/%E5%A4%A7%E5%9E%8B%E6%9C%89%E7%8A%B6%E6%80%81%E6%9C%8D%E5%8A%A1%E5%9F%BA%E4%BA%8E-k8s-%E7%9A%84%E8%90%BD%E5%9C%B0%E5%AE%9E%E8%B7%B5%EF%BC%88%E5%8D%81%E5%85%AB%EF%BC%89%EF%BC%9A%E6%8C%89%E9%83%A8/
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统
关于数据中台的深度思考与总结(干干货)
日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。点个赞+在看,少个 bug 👇以上是关于大型有状态服务基于 K8s 的落地实践——按部门租户隔离的主要内容,如果未能解决你的问题,请参考以下文章