k8s实践(13)--有状态服务StatefulSet详解
Posted hguisu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s实践(13)--有状态服务StatefulSet详解相关的知识,希望对你有一定的参考价值。
k8s实战系列 https://blog.csdn.net/hguisu/category_9999400.html
https://blog.csdn.net/hguisu/category_9999400.html
已经介绍无状态服务相关 k8s实践(12)--K8s service服务详解
最近项目搭建基于StatefulSet创建常驻pod的GPU虚机平台,项目接近尾声,在此顺便做了个总结,温故而知新,而不是走马观花,浅尝辄止懂些概念。
一、k8s集群的服务分类
在K8S运行的服务,从简单到复杂可以分成三类:无状态服务、普通有状态服务和有状态集群服务。下面分别来看K8S是如何运行这三类服务的。
1、无状态服务(Stateless Service):
1)定义:是指该服务运行的实例不会在本地存储需要持久化的数据,并且多个实例对于同一个请求响应的结果是完全一致的。
2)随意扩容和缩容:这些节点可以随意扩容或者缩容,只要简单的增加或减少副本的数量就可以。K8S使用RC(或更新的Replica Set)来保证一个服务的实例数量,如果说某个Pod实例由于某种原因Crash了,RC会立刻用这个Pod的模版新启一个Pod来替代它,由于是无状态的服务,新启的Pod与原来健康状态下的Pod一模一样。在Pod被重建后它的IP地址可能发生变化,为了对外提供一个稳定的访问接口,K8S引入了Service的概念。一个Service后面可以挂多个Pod,实现服务的高可用。
3)多个实例可以共享相同的持久化数据:例如数据存储到mysql。
相关的k8s资源有:ReplicaSet、ReplicationController、Deployment等,由于是无状态服务,所以这些控制器创建的pod序号都是随机值。并且在缩容的时候并不会明确缩容某一个pod,而是随机的,因为所有实例得到的返回值都是一样,所以缩容任何一个pod都可以。
2、普通有状态服务(Stateful Service):
和无状态服务相比,它多了状态保存的需求。即有数据存储功能。这类服务包括单实例的mysql。
因为有状态的容器异常重启就会造成数据丢失,也无法多副本部署,无法实现负载均衡。
比如php/java应用服务的Session数据默认存储在磁盘上,比如 /tmp 目录,而多副本负载均衡时,多个php/java容器的目录是彼此隔离的。比如存在两个副本A和B,用户第一次请求时候,流量被转发到A,并生成了SESSION,而第二次请求时,流量可能被负载均衡器转发到B上,而B是没有SESSION数据的,所以就会造成会话超时等BUG。
如果采用主机卷的方式,多个容器挂载同一个主机目录,就可以共享SESSION数据,但是如果多主机负载均衡场景,就需要将SESSION存储于外部数据库或Redis中了。
Kubernetes提供了以Volume和Persistent Volume为基础的存储系统,可以实现服务的状态保存。
普通状态服务只能有一个实例,因此不支持“自动服务容量调节”。一般来说,数据库服务或者需要在本地文件系统存储配置文件或其它永久数据的应用程序可以创建使用有状态服务。要想创建有状态服务,必须满足几个前提:
1)待创建的服务镜像(image)的Dockerfile中必须定义了存储卷(Volume),因为只有存储卷所在目录里的数据可以被备份
2)创建服务时,必须指定给该存储卷分配的磁盘空间大小
3)如果创建服务的同时需要从之前的一个备份里恢复数据,那么还要指明该存储卷用哪个备份恢复。
无状态服务和有状态服务主要有以下几点区别:
实例数量:无状态服务可以有一个或多个实例,因此支持两种服务容量调节模式;有状态服务只能有一个实例,不允许创建多个 实例,因此也不支持服务容量调节模式。
存储卷:无状态服务可以有存储卷,也可以没有,即使有也无法备份存储卷里面的数据;有状态服务必须要有存储卷,并且在创建服务时,必须指定给该存储卷分配的磁盘空间大小。
数据存储:无状态服务运行过程中的所有数据(除日志和监控数据)都存在容器实例里的文件系统中,如果实例停止或者删除,则这些数据都将丢失,无法找回;而对于有状态服务,凡是已经挂载了存储卷的目录下的文件内容都可以随时进行备份,备份的数据可以下载,也可以用于恢复新的服务。但对于没有挂载卷的目录下的数据,仍然是无法备份和保存的,如果实例停止或者删除,这些非挂载卷里的文件内容同样会丢失。
3、有状态集群服务(Stateful cluster Service)
与普通有状态服务相比,它多了集群管理的需求,即有状态集群服务要解决的问题有两个:
一个是状态保存,
另一个是集群管理。
这类服务包括kafka、zookeeper等。
二、有状态集群服务应用StatefulSet
1 StatefulSet背景
RC、Deployment、DaemonSet都是面向无状态的服务,它们所管理的Pod的IP、名字,启停顺序等都是随机的。
有状态集群服务的部署,意味着节点需要形成群组关系,每个节点需要一个唯一的ID(例如Kafka BrokerId, Zookeeper myid, MySQL、MongoDB的数据存储)来作为集群内部每个成员的标识,集群内节点之间进行内部通信时需要用到这些标识。
传统的做法是管理员会把这些程序部署到稳定的,长期存活的节点上去,这些节点有持久化的存储和静态的IP地址。这样某个应用的实例就跟底层物理基础设施比如某台机器,某个IP地址耦合在一起了。
K8S为此开发了一套以StatefulSet(1.5版本之前叫做PetSet)为核心的全新特性,方便了有状态集群服务在K8S上的部署和管理。Kubernets中StatefulSet的目标是通过把标识分配给应用程序的某个不依赖于底层物理基础设施的特定实例来解耦这种依赖关系。(消费方不使用静态的IP,而是通过DNS域名去找到某台特定机器)
StatefulSet本质上是Deployment的一种变体,在v1.9版本中已成为GA版本,它为了解决有状态服务的问题,它所管理的Pod拥有固定的Pod名称,启停顺序,在StatefulSet中,Pod名字称为网络标识(hostname),还必须要用到共享存储。
StatefulSet顾名思义就是有状态的集合,管理所有有状态的服务,比如MySQL、MongoDB集群等。从kubernetes 1.5 开始, PetSet 功能升级到了 Beta 版本,并重新命名为StatefulSet。除了依照社区民意改了名字之外,这一 API 对象并没有太大变化,kubernetes集群部署 Pod 增加了每索引最多一个”的语义,有了顺序部署、顺序终结、唯一网络名称以及持久稳定的存储。
在Deployment中,与之对应的服务是service,而在StatefulSet中与之对应的headless service。
headless service,即无头服务,与service的区别就是它没有Cluster IP,解析它的名称时将返回该Headless Service对应的全部Pod的Endpoint列表。
除此之外,StatefulSet在Headless Service的基础上又为StatefulSet控制的每个Pod副本创建了一个DNS域名,这个域名的格式为:
$(podname).(headless server name)
FQDN:$(podname).(headless server name).namespace.svc.cluster.local
2、StatefulSet特点
StatefulSet为什么适合有状态的程序,因为它相比于Deployment有以下特点:
Pod一致性:包含次序(启动、停止次序)、网络一致性。此一致性与Pod相关,与被调度到哪个node节点无关;
稳定的次序(启动或关闭时保证有序):对于N个副本的StatefulSet,每个Pod都在[0,N)的范围内分配一个数字序号,且是唯一的;优雅的部署和伸缩性: 操作第n个pod时,前n-1个pod已经是运行且准备好的状态。 有序的,优雅的删除和终止操作:从 n, n-1, ... 1, 0 这样的顺序删除。
在部署或者扩展的时候要依据定义的顺序依次依序进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
稳定的、唯一网络标识:Pod的hostname模式为( statefulSet名 称 ) − (statefulset名称)-(statefulset名称)−(序号);因此可以用来发现集群内部的其他成员,比如StatefulSet的名字叫kafka,那么第一个起来的Pet叫kafka-0,第二个叫kafk-1,依次类推,基于Headless Service(即没有Cluster IP的Service)来实现。
稳定的持久化存储:通过Kubernetes的PV/PVC或者外部存储(预先提供的)来实现,即通过VolumeClaimTemplate为每个Pod创建一个PV/PVC。删除、减少副本,不会删除相关的卷。
上述提到的“稳定”指的是Pod在多次重新调度时保持稳定,即存储,DNS名称,hostname都是跟Pod绑定到一起的,跟Pod被调度到哪个节点没关系。
所以Zookeeper,Etcd或 Elasticsearch这类需要稳定的集群成员的应用时,就可以用StatefulSet。通过查询无头服务域名的A记录,就可以得到集群内成员的域名信息。
3、StatefulSet也有一些限制:
1)、在Kubernetes 1.9版本之前是beta版本,在Kubernetes 1.5版本之前是不提供的。
2)、Pod的存储必须是通过 PersistentVolume Provisioner基于 storeage类来提供,或者是管理员预先提供的外部存储。
3)、删除或者缩容不会删除跟StatefulSet相关的卷,这是为了保证数据的安全
4)、StatefulSet现在需要一个无头服务(Headless Service)来负责生成Pods的唯一网络标示,此Headless服务需要通过手工创建。
4、什么时候使用StatefulSet
StatefulSet 的目的就是给为数众多的有状态负载提供正确的控制器支持。然而需要注意的是,不一定所有的有存储应用都是适合移植到 Kubernetes 上的,在移植存储层和编排框架之前,需要回答以下几个问题。
应用是否可以使用远程存储?
目前,我们推荐用远程存储来使用 StatefulSets,就要对因为网络造成的存储性能损失有一个准备:即使是专门优化的实例,也无法同本地加载的 SSD 相提并论。你的云中的网络存储,能够满足 SLA 要求么?如果答案是肯定的,那么利用 StatefulSet 运行这些应用,就能够获得自动化的优势。如果应用所在的 Node 发生故障,包含应用的 Pod 会调度到其他 Node 上,在这之后会重新加载他的网络存储以及其中的数据。
这些应用是否有伸缩需求?
用 StatefulSet 运行应用会带来什么好处呢?你的整个组织是否只需要一个应用实例?对该应用的伸缩是否会引起问题?如果你只需要较少的应用实例数量,这些实例能够满足组织现有的需要,而且可以预见的是,应用的负载不会很快增长,那么你的本地应用可能无需移植。
然而,如果你的系统是微服务所构成的生态系统,就会比较频繁的交付新服务,如果更近一步,服务是有状态的,那么 Kubernetes 的自动化和健壮性特性会对你的系统有很大帮助。如果你已经在使用 Kubernetes 来管理你的无状态服务,你可能会想要在同一个体系中管理你的有状态应用。
预期性能增长的重要性?
Kubernetes 还不支持网络或存储在 Pod 之间的隔离。如果你的应用不巧和嘈杂的邻居共享同一个节点,会导致你的 QPS 下降。解决方式是把 Pod 调度为该 Node 的唯一租户(独占服务器),或者使用互斥规则来隔离会争用网络和磁盘的 Pod,但是这就意味着用户必须鉴别和处置(竞争)热点。
如果榨干有状态应用的最大 QPS 不是你的首要目标,而且你愿意也有能力处理竞争问题,似的有状态应用能够达到 SLA 需要,又如果对服务的移植、伸缩和重新调度是你的主要需求,Kubernetes 和 StatefulSet 可能就是解决问题的好方案了。
你的应用是否需要特定的硬件或者实例类型
如果你的有状态应用在高端硬件或高规格实例上运行,而其他应用在通用硬件或者低规格实例上运行,你可能不想部署一个异构的集群。如果可以把所有应用都部署到统一实例规格的实例上,那么你就能够从 Kubernetes 获得动态资源调度和健壮性的好处。
三、StatefulSet工作原理机制
1、StatefulSet组成部分
Headless Service:用来定义Pod网络标识( DNS domain);
volumeClaimTemplates :存储卷申请模板,创建PVC,指定pvc名称大小,将自动创建pvc,且pvc必须由存储类供应;
StatefulSet :定义具体应用,如名为nginx,有三个Pod副本,并为每个Pod定义了一个域名部署statefulset。
2、具体工作原理
- 是通过Init Container来做集群的初始化工作
- 用 Headless Service 来维持集群成员的稳定关系,
- 用动态存储供给来方便集群扩容
- 最后用StatefulSet来综合管理整个集群。
要运行有状态集群服务要解决的问题有两个:状态保存问题和集群管理问题:
一个是状态保存问题解决:Kubernetes 有一套以Volume插件为基础的存储系统,通过这套存储系统可以实现应用和服务的状态保存。K8S的存储系统从基础到高级又大致分为三个层次:普通Volume,Persistent Volume 和动态存储供应。
3、Init Container初始化集群服务
什么是Init Container?
从名字来看就是做初始化工作的容器。可以有一个或多个,如果有多个,这些 Init Container 按照定义的顺序依次执行,只有所有的Init Container 执行完后,主容器才启动。由于一个Pod里的存储卷是共享的,所以 Init Container 里产生的数据可以被主容器使用到。
Init Container可以在多种 K8S 资源里被使用到如 Deployment、Daemon Set, Pet Set, Job等,但归根结底都是在Pod启动时,在主容器启动前执行,做初始化工作。
我们在什么地方会用到 Init Container呢?
第一种场景是等待其它模块Ready,比如我们有一个应用里面有两个容器化的服务,一个是Web Server,另一个是数据库。其中Web Server需要访问数据库。但是当我们启动这个应用的时候,并不能保证数据库服务先启动起来,所以可能出现在一段时间内Web Server有数据库连接错误。为了解决这个问题,我们可以在运行Web Server服务的Pod里使用一个Init Container,去检查数据库是否准备好,直到数据库可以连接,Init Container才结束退出,然后Web Server容器被启动,发起正式的数据库连接请求。
第二种场景是做初始化配置,比如集群里检测所有已经存在的成员节点,为主容器准备好集群的配置信息,这样主容器起来后就能用这个配置信息加入集群。
还有其它使用场景,如将pod注册到一个中央数据库、下载应用依赖等。
这些东西能够放到主容器里吗?从技术上来说能,但从设计上来说,可能不是一个好的设计。首先不符合单一职责原则,其次这些操作是只执行一次的,如果放到主容器里,还需要特殊的检查来避免被执行多次。
这是Init Container的一个使用样例
这个例子创建一个Pod,这个Pod里跑的是一个nginx容器,Pod里有一个叫workdir的存储卷,访问nginx容器服务的时候,就会显示这个存储卷里的index.html 文件。
而这个index.html 文件是如何获得的呢?是由一个Init Container从网络上下载的。这个Init Container 使用一个busybox镜像,起来后,执行一条wget命令,获取index.html文件,然后结束退出。
由于Init Container和nginx容器共享一个存储卷(这里这个存储卷的名字叫workdir),所以在Init container里下载的index.html文件可以在nginx容器里被访问到。
可以看到 Init Container 是在 annotation里定义的。Annotation 是K8S新特性的实验场,通常一个新的Feature出来一般会先在Annotation 里指定,等成熟稳定了,再给它一个正式的属性名或资源对象名。
4、用 Headless Service 来维持集群成员的稳定关系
1)、Headless Service 定义:
有时不需要或不想要负载均衡,以及单独的Service IP。遇到这种情况,可以通过指定Cluster IP(spec.clusterIP)的值为“None”来创建Headless Service。
2)、Headless Service和普通Service相比:
k8s对Headless Service并不会分配Cluster IP,kube-proxy不会处理它们,而且平台也不会为它们进行负载均衡和路由。k8s会给一个集群内部的每个成员提供一个唯一的DNS域名来作为每个成员的网络标识,集群内部成员之间使用域名通信。
普通Service的Cluster IP 是对外的,用于外部访问多个Pod实例。而Headless Service的作用是对内的,用于为一个集群内部的每个成员提供一个唯一的DNS名字,这样集群成员之间就能相互通信了。所以Headless Service没有Cluster IP,这是它和普通Service的区别。
3)、无头服务管理Headless Service域名格式
无头服务管理的域名是如下的格式:$(service_name).$(k8s_namespace).svc.cluster.local。其中的"cluster.local"是集群的域名,除非做了配置,否则集群域名默认就是cluster.local。
4)、StatefulSet基于Headless Service来实现创建的每个Pod的序号是唯一的。
为了解决名字不稳定的问题,StatefulSet下创建的每个Pod的名字不再使用随机字符串,而是为每个pod分配一个唯一不变的序号,比如StatefulSet的名字叫 mysql,那么第一个启起来的pod就叫 mysql-0,第二个叫 mysql-1,如此下去。
当一个某个pod掉后,新创建的pod会被赋予跟原来pod一样的名字。由于pod名字不变所以DNS名字也跟以前一样,同时通过名字还能匹配到原来pod用到的存储,实现状态保存。
StatefulSet下创建的每个Pod,得到一个对应的DNS子域名,格式如下:
$(podname).$(governing_service_domain),这里 governing_service_domain是由StatefulSet中定义的serviceName来决定。
举例子,无头服务管理的kafka的域名是:kafka.test.svc.cluster.local,
创建的Pod得到的子域名是 kafka-1.kafka.test.svc.cluster.local。注意这里提到的域名,都是由kuber-dns组件管理的集群内部使用的域名,可以通过命令来查询:
$ nslookup my-nginx
Server: 192.168.16.53
Address 1: 192.168.16.53
Name: my-nginx
Address 1: 192.168.16.132
而普通Service情况下,Pod名字后面是随机数,需要通过Service来做负载均衡。
当一个StatefulSet挂掉,新创建的StatefulSet会被赋予跟原来的Pod一样的名字,通过这个名字来匹配到原来的存储,实现了状态保存。因为上文提到了,每个Pod的标识附着在Pod上,无论pod被重新调度到了哪里。
5、StatefulSet集群服务的存储:K8S的存储系统
K8S的存储系统从基础到高级又大致分为三个层次:普通Volume,Persistent Volume 和动态存储供应。
具体看:k8s(5)-kubernetes存储系统
1.普通Volume
最简单的普通Volume是单节点Volume。它和Docker的存储卷类似,使用的是Pod所在K8S节点的本地目录。
第二种类型是跨节点存储卷,这种存储卷不和某个具体的K8S节点绑定,而是独立于K8S节点存在的,整个存储集群和K8S集群是两个集群,相互独立。
跨节点的存储卷在Kubernetes上用的比较多,如果已有的存储不能满足要求,还可以开发自己的Volume插件,只需要实现Volume.go 里定义的接口。如果你是一个存储厂商,想要自己的存储支持Kubernetes 上运行的容器,就可以去开发一个自己的Volume插件。
2.pv:persistent volume
PersistentVolume(PV)是集群之中的一块网络存储。跟 Node 一样,也是集群的资源,并且不属于特定的namespace。PV 跟 Volume (卷) 类似,不过会有独立于 Pod 的生命周期。
它和普通Volume的区别是什么呢?
普通Volume和使用它的Pod之间是一种静态绑定关系,在定义Pod的文件里,同时定义了它使用的Volume。Volume 是Pod的附属品,我们无法单独创建一个Volume,因为它不是一个独立的K8S资源对象。
而Persistent Volume 简称PV是一个K8S资源对象,所以我们可以单独创建一个PV。它不和Pod直接发生关系,而是通过Persistent Volume Claim,简称PVC来实现动态绑定。Pod定义里指定的是PVC,然后PVC会根据Pod的要求去自动绑定合适的PV给Pod使用。
PV的访问模式有三种:
第一种,ReadWriteOnce:是最基本的方式,可读可写,但只支持被单个Pod挂载。
第二种,ReadOnlyMany:可以以只读的方式被多个Pod挂载。
第三种,ReadWriteMany:这种存储可以以读写的方式被多个Pod共享。不是每一种存储都支持这三种方式,像共享方式,目前支持的还比较少,比较常用的是NFS。在PVC绑定PV时通常根据两个条件来绑定,一个是存储的大小,另一个就是访问模式。
刚才提到说PV与普通Volume的区别是动态绑定,我们来看一下这个过程是怎样的。
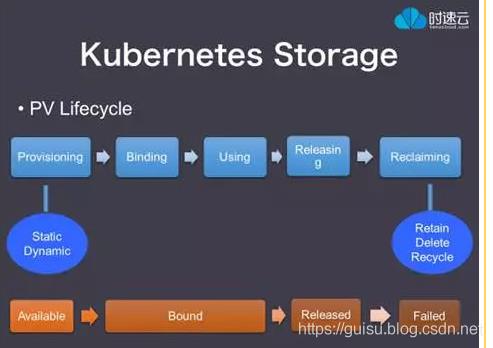
这是PV的生命周期:
首先是Provision,即创建PV,这里创建PV有两种方式,静态和动态。所谓静态,是管理员手动创建一堆PV,组成一个PV池,供PVC来绑定。动态方式是通过一个叫 Storage Class的对象由存储系统根据PVC的要求自动创建。
一个PV创建完后状态会变成Available,等待被PVC绑定。
一旦被PVC邦定,PV的状态会变成Bound,就可以被定义了相应PVC的Pod使用。
Pod使用完后会释放PV,PV的状态变成Released。
变成Released的PV会根据定义的回收策略做相应的回收工作。有三种回收策略,Retain、Delete 和 Recycle。Retain就是保留现场,K8S什么也不做,等待用户手动去处理PV里的数据,处理完后,再手动删除PV。Delete 策略,K8S会自动删除该PV及里面的数据。Recycle方式,K8S会将PV里的数据删除,然后把PV的状态变成Available,又可以被新的PVC绑定使用。
在实际使用场景里,PV的创建和使用通常不是同一个人。这里有一个典型的应用场景:管理员创建一个PV池,开发人员创建Pod和PVC,PVC里定义了Pod所需存储的大小和访问模式,然后PVC会到PV池里自动匹配最合适的PV给Pod使用。
前面在介绍PV的生命周期时,提到PV的供给有两种方式,静态和动态。其中动态方式是通过StorageClass来完成的,这是一种新的存储供应方式。
使用StorageClass有什么好处呢?除了由存储系统动态创建,节省了管理员的时间,还有一个好处是可以封装不同类型的存储供PVC选用。在StorageClass出现以前,PVC绑定一个PV只能根据两个条件,一个是存储的大小,另一个是访问模式。在StorageClass出现后,等于增加了一个绑定维度。
比如这里就有两个StorageClass,它们都是用谷歌的存储系统,但是一个使用的是普通磁盘,我们把这个StorageClass命名为slow。另一个使用的是SSD,我们把它命名为fast。
在PVC里除了常规的大小、访问模式的要求外,还通过annotation指定了Storage Class的名字为fast,这样这个PVC就会绑定一个SSD,而不会绑定一个普通的磁盘。
到这里Kubernetes的整个存储系统就都介绍完了。总结一下,两种存储卷:普通Volume 和Persistent Volume。普通Volume在定义Pod的时候直接定义,Persistent Volume通过Persistent Volume Claim来动态绑定。PV可以手动创建,也可以通过StorageClass来动态创建。
四、StatefuleSet示例
Kafka和zookeeper是在两种典型的有状态的集群服务。首先kafka和zookeeper都需要存储盘来保存有状态信息,其次kafka和zookeeper每一个实例都需要有对应的实例Id(Kafka需要broker.id,zookeeper需要my.id)来作为集群内部每个成员的标识,集群内节点之间进行内部通信时需要用到这些标识。
有两个原因让 [ZooKeeper] 成为 StatefulSet 的好例子。
首先,StatefulSet 在其中演示了运行分布式、强一致性存储的应用的能力;
其次,ZooKeeper 也是 Apache Hadoop 和 Apache Kafka 在 Kubernetes 上运行的前置条件。在 Kubernetes 文档中有一个 深度教程 说明了在 Kubernetes 集群上部署 ZooKeeper Ensemble 的过程,这里会简要描述一下其中的关键特性。
具体的部署过程包括以下几个部署:
(1) Persistent Volume 存储的创建
(2) StatefulSet(Petset)资源的创建
(3) headless服务的创建
。。。。。
k8s之StatefulSet详解_最美dee时光的博客-CSDN博客_k8s statefulset:
mysql-sc.yaml:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: mysql-nfs-storage
provisioner: storage-fsp
parameters:
archiveOnDelete: "false"部署mysql的statefulset:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
namespace: mysql-sts
spec:
selector:
matchLabels:
app: mysql
serviceName: "mysql"
replicas: 1 1
template:
metadata:
labels:
app: mysql
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: www.my.com/sys/mysql:5.7
ports:
- containerPort: 3306
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
volumeMounts:
- name: mysql-pvc
mountPath: /var/lib/mysql
volumeClaimTemplates: #可看作pvc的模板
- metadata:
name: mysql-pvc
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "mysql-nfs-storage" #存储类名,改为集群中已存在的
resources:
requests:
storage: 1Gi
以上是关于k8s实践(13)--有状态服务StatefulSet详解的主要内容,如果未能解决你的问题,请参考以下文章