声网AI降噪测评系统初探
Posted 声网Agora
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了声网AI降噪测评系统初探相关的知识,希望对你有一定的参考价值。

作者:孟赛斯
前言
音频质量的优化是一个复杂的系统工程,而降噪是这个系统工程中的一个重要环节,传统的降噪技术经过几十年的发展已经陷入了瓶颈期,尤其是对非平稳噪声的抑制越来越不能满足新场景的需求。而近几年以机器学习/深度学习为代表的AI技术的崛起,为特殊场景下的音频降噪带来了新的解决方案。声网Agora 伴随着在线音视频直播服务的发展逐渐形成了自己的积淀,本文是声网Agora 音频技术团队出品的特殊场景下的音频测评系列文章──AI降噪篇。由于业界对于音频的评价标准尚存在不同的意见,因此声网Agora 的实践更偏重从有参到无参的工程化落地,在此抛砖引玉、恳请业界同仁多加批评指正。
背景介绍
作为开发者,我们希望为用户提供高清晰度和流畅度、高保真音质的实时互动体验,但由于噪声无时无刻的存在,使得人们在通话中受到干扰。不同场合拥有的噪声也是不同的,噪声可以是平稳的也可以是非平稳或者瞬态的,平稳的噪声是不随时间的变化而变化,比如白噪声;非平稳的噪声随着时间的变化而变化,比如人说话声、马路噪声等等,瞬态噪声可以归为非平稳噪声,它是持续时间较短的、间歇性噪声,比如敲键盘声、敲桌子、关门等等。在实际互动场景中,当双方使用移动设备通话时,一方处于饭店、吵闹的街道、地铁或者机场等嘈杂的环境中,另一方就会接收到大量含有噪声的语音信号,当噪声过大时,通话双方无法听清楚对方讲话内容,容易产生烦躁的负面情绪,影响最终用户体验。因此,为了减小噪声对语音信号的干扰,提高用户通话的愉悦程度,我们往往会做Noise suppression(NS,噪声抑制)处理,目的是从带噪语音信号中滤除掉噪声信号,最大程度的保留语音信号,使得通话双方听到的语音都不受噪声的干扰,一个理想的NS技术是要在去除噪声的同时保留语音的清晰度、可懂度和舒适度。
降噪的研究最早开始于上个世纪60年代,经过了几十年的发展,已经取得了巨大的进步,我们把降噪算法大致的分为以下几类。
(1)子空间方法,其基本思想是将含噪语音信号映射到信号子空间和噪声子空间,纯净语音信号可以通过消除噪声子空间成分和保留信号子空间成分的方式进行估计;
(2)短时谱减法,该方法假设噪声信号是平稳的且变化缓慢,使用带噪信号的频谱减去估计出的噪声信号的频谱,从而得到降噪后的语音信号;(3)维纳滤波器,算法的基本原理是根据最小均方误差准则,用维纳滤波器估计语音信号,然后从带噪信号中提取出语音信号;
(4)基于听觉掩蔽效应的方法,该方法模拟人耳的感知特性,对某一时刻某一频率确定一个人耳可感受到噪声能量的最低阈值进行计算,通过将噪声能量控制在该阈值以下,从而达到最大限度的掩蔽残留噪声和防止语音失真的目的;
(5)基于噪声估计的方法,该方法一般是基于噪声和语音特性的不同,通过VAD(Voice Activity Detection,语音端点检测)或语音存在概率对噪声成分和语音成分进行区分,但当噪声与语音特性类似时,此算法往往不能准确区分含噪语音中语音和噪声的成分;
(6)AI降噪, AI降噪技术能一定程度上解决传统降噪技术存在的问题,比如在一些瞬态噪声(持续时间短、能量高的噪声,如关门声,敲击声等等)和一些非平稳噪声(随时间变化快,随机波动不可预测,如吵闹的街道)的处理上,AI降噪的优势更明显。
无论是传统NS技术还是AI NS技术,我们在产品上线时都需要考虑包体积和算力影响,以便运用于移动端和loT设备,即要在保证模型是轻量级的基础上还要最大程度地保证NS性能,这也是实际产品上线最具挑战的地方之一,其中,模型的量级在上线后已经可以得到保证,那么NS的性能是否能够达标呢?这里我们把重点放在如何评估NS的性能上,针对NS的调参、NS的重构、新NS算法的提出、不同NS性能的对比,我们如何站在用户体验角度去评估NS技术的性能呢?
首先,我们把测评NS的方法分类为主观测试方法和客观测试方法,其中客观测试又分为侵入式(Intrusive)和非侵入式(Non-intrusive),或者叫做有参的和无参的,下面解释一下其含义和优缺点。
| 方式 | 含义 | 优缺点 |
|---|---|---|
| 主观测试 | 主观评价方法以人为主体在某种预设原则的基础上对语音的质量作出主观的等级意见或者作出某种比较结果,它反映听评者对语音质量好坏的主观印象。一般的,采用绝对等级评价(Absolute Category Rating, ACR),主要是通过平均意见分(MOS)对音质进行主观评价。这种情况下没有参考语音,听音人只听失真语音,然后对该语音作出1~5分的评价。 | 优点:直接反映用户体验;缺点:人力成本高,测试周期长,可重复性差,受个体主观差异影响。 |
| 客观测试 | Intrusive:依靠参考语音和测试语音之间某种形式的距离特征来预测主观平均得分(MOS)分。如大部分文献及Paper中测评自身NS算法都是利用PESQ、信噪比、分段信噪比、板仓距离等等。 | 优点:可批量自动化测试,节约人力成本和时间成本;缺点:(1)不能完全等同于用户主观体验;(2)大部分客观指标只支持16k采样率;(3)要求参考信号与测试信号之间必须按帧对齐,而实时RTC音频难免受到网络的影响而导致数据无法按帧对齐,直接影响客观指标的准确性。 |
| Non-intrusive:仅依据测试语音本身来预测语音的质量。 | 优点:无需原始参考信号直接预测语音质量,可实时测评RTC音频质量缺点:技术要求高,模型建立有一定的难度 |
我们认为主观测试可以直接反映用户体验,而主观测试结果和客观测试结果一致,则可以证明客观测试的正确性,此时,客观测试也可反映用户体验。下面我们看看声网是如何评估NS的性能的。
声网NS测评
我们正在搭建一套全方位的、可靠的、可长期依赖的NS测评系统,我们相信它可以应对未来任何带噪场景(目前可覆盖超过70种噪声类型)和任何NS技术,并且我们不指定特定的测试语料、采样率和有效频谱,任何人的说话内容都可以作为被测对象。以这个目的作为出发点,我们对现有的NS测评技术进行了验证,发现它们并不能够覆盖我们的所有通话场景、也不能完全覆盖我们测试的噪声类型、更不能代表主观感受。因此,我们拟合了新的全参考NS指标,同时用深度学习的算法去做无参考的模型,两种方案同时进行。下面简单阐述一下现有的NS测评指标、我们的验证方法、以及我们如何去做全参考和无参考的NS测评模型。
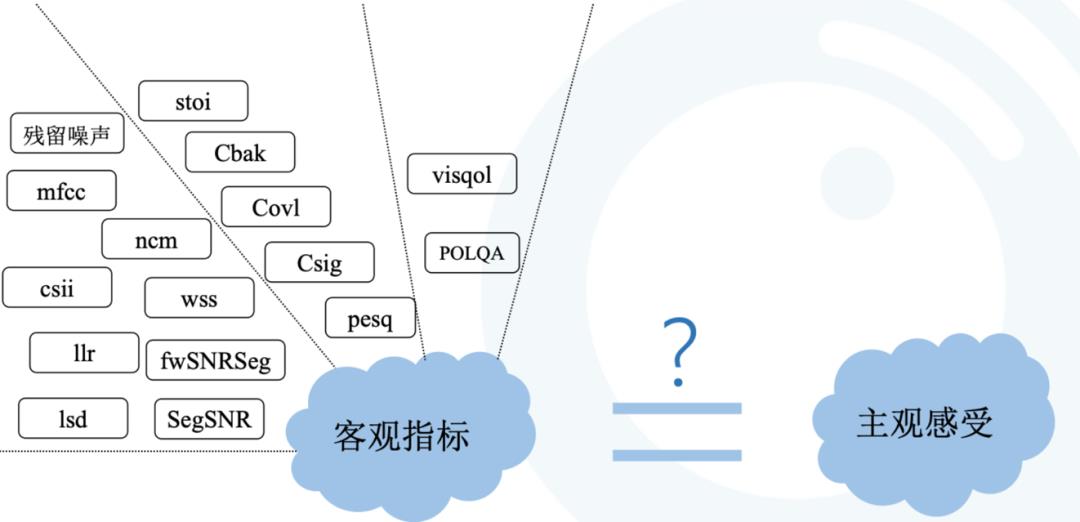
1.现有的NS测评指标:通过调研大量文献、权威性Paper和一些开源网站如https://github.com/schmiph2/pysepm,并根据我们实际的场景需求,我们开发了一个用于测评NS的客观指标库,其中包含像常见的PESQ、语音分段信噪比SegSNR、短时可懂度STOI等,以及参考语音和测试语音之间某种形式的距离特征,如倒谱距离(Cepstrum Distance, CD)能反映非线形失真对音质的影响、对数谱距离(Log Spectral Distance,LSD)用于刻画两个频谱之间的距离度量、NCM (Normalized Covariance Measure)评价方法是计算纯净语音信号与含噪语音在频域内的包络信号之间的协方差。综合测度Csig、Cbak、Covl分别表示predicted rating [1-5] of speech distortion、predicted rating [1-5] of noise distortion、predicted rating [1-5] of overall quality,是通过结合多个客观测度值形成综合测度,使用综合测度的原因是,不同的客观测度捕捉失真信号的不同特征,因此采用线性或者非线形的方式组合这些测度值可能显著改善相关性。
每个指标对应着NS前后音频的某些特征的变化,每个指标从不同的角度去衡量NS的性能。我们不禁有个疑问?这些指标是不是能与主观感受画上等号?除了算法上有合理性,我们怎么确保它跟主观的一致?是不是这些客观指标没问题了,主观测出来就不会有问题?我们怎么确保这些指标的覆盖性?
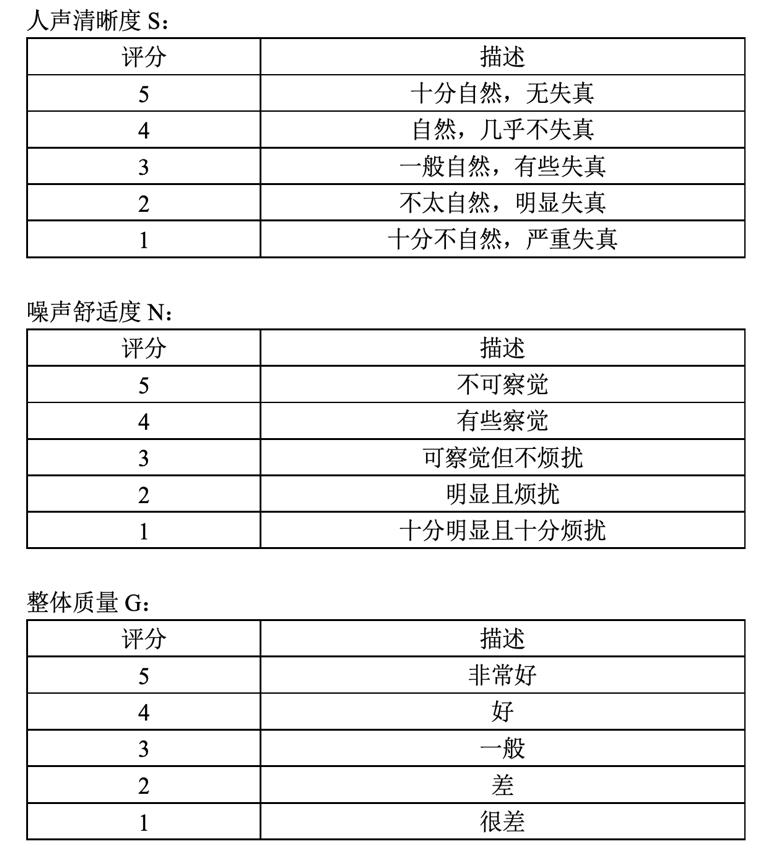
2.我们的验证方法:为了验证我们建立的客观指标库的准确性及与主观体验的相关性,我们做了基于众包的主观音频测试,并开发了一款专门用于众包主观标注的APP,整个流程我们遵循了P808,P835以及借鉴NS挑战赛,对测试数据、时长、环境、设备、测试人员等等都做出了要求。我们主要关注三个维度,人声清晰度SMOS,噪声舒适度NMOS,整体质量GMOS,范围都是1~5分,下面给出对应的MOS评分相关描述和APP页面设计。

那么主观标注的结果与之前我们提到的客观指标库中的指标之间有多大的相关性呢?我们对客观指标库中所有客观指标进行了统计,这里我们只给出PESQ与主观标注的PLCC(Pearson linear correlation coefficient):
| PLCC | PESQ |
|---|---|
| 主观SMOS | 0.68 |
| 主观NMOS | 0.81 |
| 主观GMOS | 0.79 |
这里的主观SMOS、NMOS、GMOS是由200条数据/每条数据32人标注的均值计算得出。
3.如何去做全参考和无参考的NS测评模型:随着主观标注数据量的累积,我们发现现有的指标精度不足以覆盖我们的所有场景、噪声类型、更不能代表主观感受。因此我们拟合了新的综合测度MOS分,用于测评NS的性能。
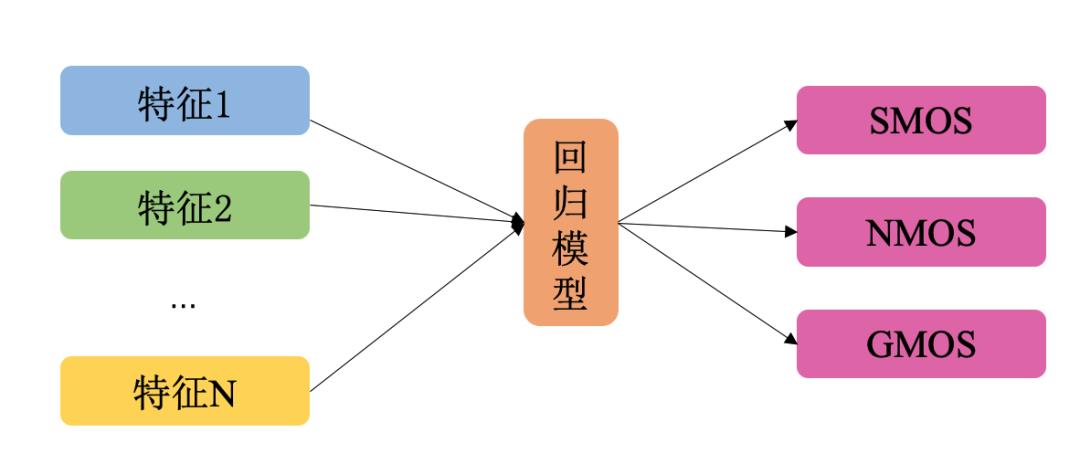
我们的方案一是全参考模型,即以客观指标库中的指标作为特征输入,众包标注的结果当作标签训练三个模型,三个模型的输出分别是衡量语音、噪声、整体的分值。
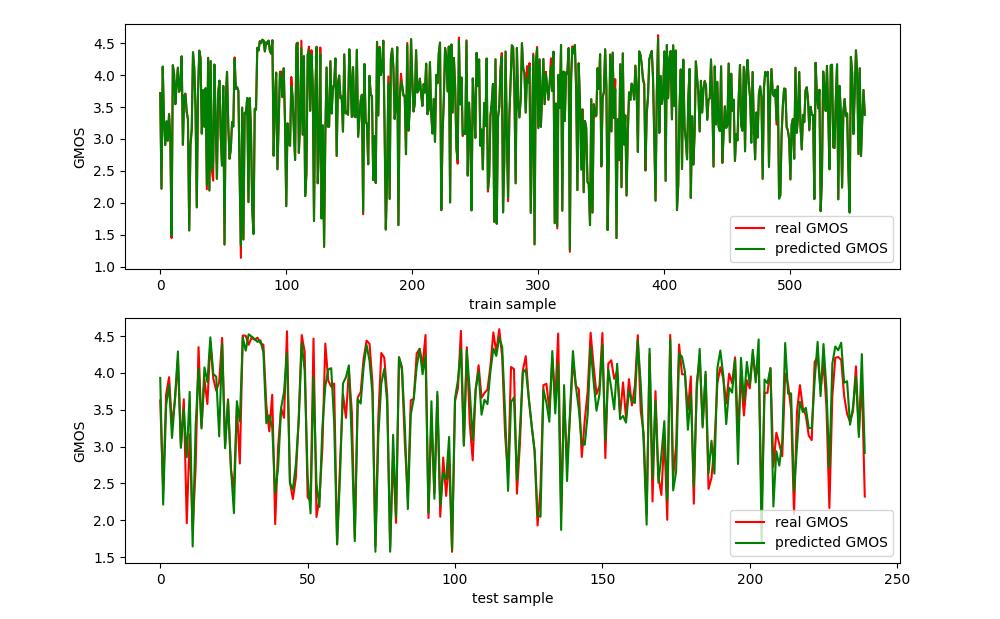
以下是由800条数据组成的数据集,随机抽取70%的数据作为训练集,30%的数据作为测试集;模型选取GBDT(Gradient Boosting Decision Tree)对GMOS的训练和测试情况,下图上半部分是训练集的real GMOS和训练好模型后模型预测训练集的predicted GMOS,下半部分是测试集的real GMOS和训练好模型后模型预测测试集的predicted GMOS,其中测试集的real GMOS和predicted GMOS之间的PLCC可达0.945,SROCC(Spearman rank-order correlation coefficient)可达0.936,RMSE(Root Mean Square Error)为0.26.
我们的方案二是无参考模型,由于全参考的客观指标要求参考信号与测试信号之间必须按帧对齐,而实时RTC音频难免受到网络的影响而导致数据不按帧对齐,直接影响客观指标的准确性。为了避免这一因素的影响,我们也在做无参的SQA(Speech Quality Assessment)模型,目前的技术核心是将音频转换为Mel频谱图,然后对Mel频谱图进行切割,利用CNN去提取每个切割后segment的质量特征,接着利用self-attention对特征序列在时间上建模,实现特征序列在时间上的交互,最后通过attention模型计算每个segment对整个MOS分的贡献度,从而映射到最终的MOS。
这里我们给出无参SQA模型目前的训练精度,训练集共1200条带噪声数据,70%做训练集,30%做测试集,横坐标表示epoch,蓝色的线表示训练loss随着epoch的变化,红色的线表示训练集随着epoch的增大,和训练集标签的PLCC,绿色的线表示测试集随着epoch的增大,和测试集标签的PLCC,我们可以看出目前离线的效果是很理想的,后续我们将增加更多场景的数据进行模型训练。

未来
未来,我们会直接进行端到端的音频质量评估(Audio Quality Assessment,AQA),而噪声只是音频中影响主观体验的一个因子。我们会在线上搭建一套完整的实时音频评价系统,这个评价系统将是长期可靠的、高精度的,用于评价用户在实时音频互动中产生的厌恶或愉悦情绪的程度。整个流程包括建立方案、数据集的构建、众包标注(标注标准的建立、标注后数据的清洗与筛选、数据分布验证)、模型训练与优化和上线反馈等等。虽然现在我们面临着一些挑战,但只要制定出smart目标,那么这个目标就一定能实现。
Dev for Dev专栏介绍
Dev for Dev(Developer for Developer)是声网Agora 与 RTC 开发者社区共同发起的开发者互动创新实践活动。透过工程师视角的技术分享、交流碰撞、项目共建等多种形式,汇聚开发者的力量,挖掘和传递最具价值的技术内容和项目,全面释放技术的创造力。
以上是关于声网AI降噪测评系统初探的主要内容,如果未能解决你的问题,请参考以下文章
通过 TensorFlow 实现 AI 语音降噪提升 QQ 音视频通话质量