基于机器学习的语音编解码器声网Agora Silver:支持超低码率下的高音质语音互动
Posted 声网Agora
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于机器学习的语音编解码器声网Agora Silver:支持超低码率下的高音质语音互动相关的知识,希望对你有一定的参考价值。
从 1860 年电话发明,到现如今通过网络进行语音互动,语音始终是最自然、最基础的实时互动方式。过去几年,语音实时互动成为越来越多人日常生活的一部分。但是每个人都会遇到弱网环境,这会直接影响语音通话体验。所以声网也在不断地利用最前沿的技术来改进语音通话体验。我们现在在国内率先正式推出基于机器学习的语音编解码器(语音 AI Codec)——声网Agora Silver。它可以在超低码率下,提供32KHz采样率的超宽带编码音质,并通过 AI 降噪算法来进一步优化音质与语音自然听感。
传统编码器为何要引入AI?
在语音互动的过程中,所有用户都会遇到弱网。有的是因为所在地区的网络设施问题造成的;有的可能处于网络设施较好的区域,但遇到网络使用高峰期,仍然会出现网络拥塞,从而使用户分到的有效带宽降低。任何人都无法保证网络的全时稳定,弱网环境长期存在。
面对弱网,通常会选择降低码率,从而减少对带宽的占用,以此来避免出现语音卡顿的情况。但是,这种方法虽然解决了卡顿、不可用的问题,却带来了新的问题。
传统的编解码器,在极低码率时只能保持一定的语音可懂度(即听得清对方在说什么),却很难保持音色等其他信息。例如,Opus 在 6kbps 的码率下只能做到窄带语音的编码,有效语谱带宽就只有 4KHz 了。这是什么概念呢?
Opus 是目前业界应用最广泛的音频编解码器,也是 WebRTC 默认的编解码器。为了能适应不同的网络情况,它的码率可在 6kbps - 510kbps 之间调节。那么当遇到弱网,或者说网络带宽有限的时候,可以将码率最低降至 6kbps。在这个码率下,只能进行窄带语音编码。根据业界的定义,窄带语音编码的采样率为 8KHz。而根据采样定理,也称作奈奎斯特采样定理,只有采样频率高于声音信号最高频率的两倍时,才能把数字信号表示的声音还原成为原来的声音。也就是说,采样率为 8KHz 的时候,有效语谱带宽只有 4KHz。人声会听起来很闷,因为声音中很多高频的部分丢失了。
经过这么多年的发展,已经很难再通过算法调优,来帮助传统编解码器突破这个瓶颈了。而随着 AI 语音合成技术的不断发展,尤其是基于 WaveRNN 的语音生成技术的发展,人们发现将 AI 与音频编解码器结合,能够在更低码率的编码条件下更完整地还原语音。
语音AI Codec是什么?
目前业界对于 AI 与音频编解码的结合有很多中探索。例如,有通过 WaveRNN 在解码端来优化低码率的音质,也有利用 AI 在编码端优化压缩效率的方法。所以广义上讲,只要是用到机器学习、深度学习来进行语音的压缩或解码的,都算是语音 AI Codec。
语音AI Codec现在面对的难点
尽管在很多编解码标准的设计研发中,已开始探索将 AI 应用其中。语音 AI Codec 从学术、标准,落地到实际业务场景中,还比如 Google 最近发布的 Lyra 可以做到 3kpbs 的码率还原 16KHz 采样的宽带语音。它的做法是通过机器学习模型在解码端,根据收到的低码率的语音数据,重建还原出高质量信号,从而让声音还原度听上去更高。类似的语音 AI Codec 还有微软发布的 Satin ,它可以在 6kpbs 的码率还原 32KHz 采样率的超宽带语音。
但相对传统声码器,语音 AI Codec 的应用落地仍需解决一些难点:
噪音鲁棒性
根据香农定理,低码率对信号的信噪比要求更高。由于语音 AI Codec 解码多使用语音生成模型来生成音频信号,在噪声情况下,一个比较直观的感受就是噪声都变成了一些类似语音的不自然噪音,非常影响听感。加上低码率压缩,噪声情况很可能会导致语音可懂度快速下降,听上去你会感觉对端的人仿佛有“大舌头”,说话含糊不清。所以在实际使用中,往往先需要一个优秀的降噪模块来作为前处理,再进行编码。
针对移动端的算法模型优化
解码时 AI 模型往往需要庞大算力。解码时采用的语音生成模型的计算都比较耗时,而实时互动场景又要求模型可在大部分移动设备上进行实时计算。因为大多数实时互动都发生在移动终端上。例如 Google 开源的 Lyra 在麒麟 960 芯片上实测包含 40ms 信息的一个音频package,解码需要 40ms-80ms,如果你的手机搭载了这个芯片,例如华为荣耀 9,就无法在实时互动场景中采用 Lyra。这还只是单路解码,如果需要多路解码(多人的实时通话)那要求的算力就需要成倍上升,一般的设备可能就无法支持了。因此如果想要让语音 AI Codec 能应用于实时互动场景,那还必须针对移动终端做算力优化,以满足实时性的性能与延时要求。
语言自然度与算力的权衡
要想得到一个自然的语音听感,往往需要更高算力的模型。这与我们刚提到的第二个“挑战”刚好形成互相制约的关系。
较小算力的模型可能导致生成的语音有很多失真和不自然的听感。例如目前语音最自然的逐点生成模型(Sample by sample) 模型往往需要 3-20GFLOPS 的计算量。我们一般可以用 MUSHRA(用于流媒体与通信的相关编码的主观评价测试方法,满分 100 分)来评价语音生成模型的语音可懂度和自然度,20GFLOPS 的模型,例如 WaveRNN 就可以达到 MOS 分达到 85 分左右,而算力比较小的模型,例如 3GFLOPS 的 LPCNET 就只能达到 75 分。
Silver特性与横向实测效果
在 Silver 编解码器中,我们通过自研算法解决了上述三个难题。如下图所示,Silver 首先利用 实时全频带 AI 降噪算法提供噪声鲁棒性。在解码端,Silver 基于深度优化的 WaveRNN 模型,以极小的算力实现语音解码。
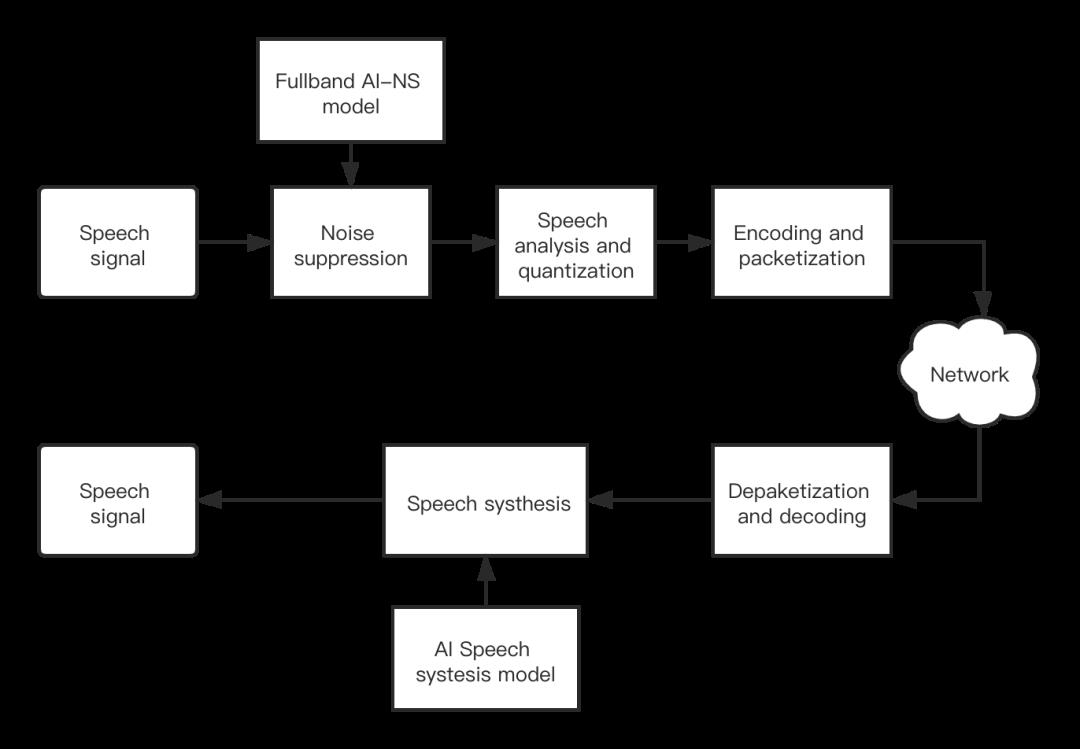
Silver 的特性包括:
1、解决噪声鲁棒性问题:结合自主研发的实时全频带 AI 降噪算法。
2、机器学习模型可运行于移动终端:基于深度优化的 WaveRNN 模型以极小的算力实现语音解码,实测在高通 855 单核上,解码 40ms 的语音信号只需要 5ms 的计算时间,流畅支持各种实时互动场景。
3、超低码率:码率最低可达 2.7kpbs,更省带宽。
4、高音质:支持 32KHz 采样率,超宽带编码音质,音色饱满自然。
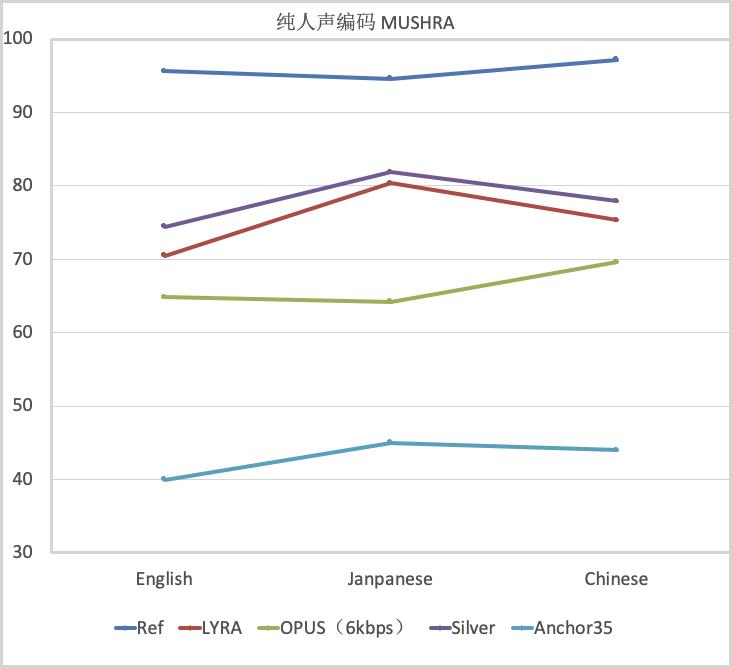
我们基于 MUSHRA 标准来对比了 Silver、Opus(6kbps)、Lyra 的语音可懂度和自然度。如下图所示。其中 REF 为满分锚点,Anchor35 为低分锚点,就是把原始的语音(满分锚点)和很差的合成数据(低分锚点)混到测试语料里去接受测试打分。我们测试了三种语言,Silver 的打分均高于其它编解码器。
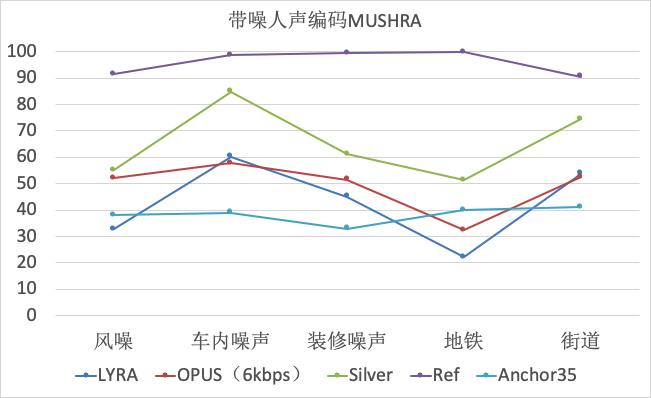
同时,我们还在不同的噪声环境下,对比测试了以上三种编解码器,测试打分结果如下。在 AI 降噪算法的支持下,Silver 可以为用户提供更自然的语音互动效果。
在有噪声和无噪声环境下,原声与经过不同编解码器传输后的效果可以通过我们准备的音频对比感受,由于平台无法上传音频,因此,感兴趣的开发者可以点击这里收听。
由于篇幅限制,能分享的音频数量有限。如果你还希望进一步了解 Silver ,欢迎访问声网开发者社区,在论坛留言与我们交流。
以上是关于基于机器学习的语音编解码器声网Agora Silver:支持超低码率下的高音质语音互动的主要内容,如果未能解决你的问题,请参考以下文章
声网Agora Lipsync技术剖析:通过实时语音驱动人像模拟真人说话
RTC月度小报5月 |教育aPaaS灵动课堂升级抢先体验VUE版 Agora Web SDK声网Agora与HTC达成合作