Scrapy框架的下载器中间件讲解&并用下载器中间件设置随机请求头python爬虫入门进阶(24)
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy框架的下载器中间件讲解&并用下载器中间件设置随机请求头python爬虫入门进阶(24)相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 3. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当,持续更新中 。python爬虫入门进阶
❤️ 4. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 5. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
关注下方公众号,众多福利免费嫖;加我VX进群学习,学习的路上不孤单

前言
上一篇文章我们介绍了Scrapy框架架构详解【python爬虫入门进阶】(23),介绍了Scrapy框架中的各个组件以及数据的流转图。这篇文章主要讲解Scrapy框架的下载器中间件以及如何设置随机请求头。
Downloader Middlewares(下载器中间件)
下载器中间件是引擎和下载器之间通信的中间件,在这个中间件中我们可以设置代理、更换请求头等达到反反爬虫的目的。要写下载器中间件,可以在下载器中实现两个方法。一个是process_request(self, request, spider),这个方法是在请求发送之前会执行,一个是process_response(self, request, response, spider),这个方法是在数据下载到引擎之前执行。
process_request(self, request, spider)
这个方法是下载器在发送请求之前会执行的。一般可以在这个里面设置随机代理ip等。
- 参数:
- request:发送请求的request对象。
- spider: 发送请求的spider对象
- 返回值:
- 返回None:如果返回None,Scrapy将继续处理该request,执行其他中间件中的相应方法,直到适合的下载器处理函数被调用。
- 返回Response对象:Scrapy将不会调用任何其他的
process_request方法,将直接返回这个response对象,已经激活的中间件的process_response()方法则会在每个response返回时被调用。 - 返回Request对象:不再使用之前的request对象去下载数据,而是根据现在返回的request对象返回数据。
- 如果这个方法抛出了异常,则会调用
process_exception方法。
process_response(self, request, response, spider)
这个是下载器下载的数据到引擎中间会执行的方法。
-
参数:
- request: request对象。
- response: 被处理的response对象。
- spider: spider对象。
-
返回值:
- 返回Response对象:会将这个新的response对象传给其他中间件,最终传给爬虫。
- 返回Request对象:下载器链被切断,返回的request会重新被下载器调度下载。
- 如果抛出一个异常,那么调用request的errback方法,如果没有指定这个方法,那么会抛出一个异常。
下图展示了下载器中间件的执行过程,如下图所示有1,2,3 三个下载器中间件,引擎在该下载器发送请求之前首先会调用process_request方法,如果一个中间件的process_request方法返回的是一个None的话,那么它会将请求给到下一个中间件继续处理。
如果一个中间件的process_request方法返回的是一个request对象,会将新的request对象返回给下一个中间件处理。
如果一个中间件的process_request方法返回的是一个response对象,则不在调用任何其他的process_request方法,将直接返回response对象。
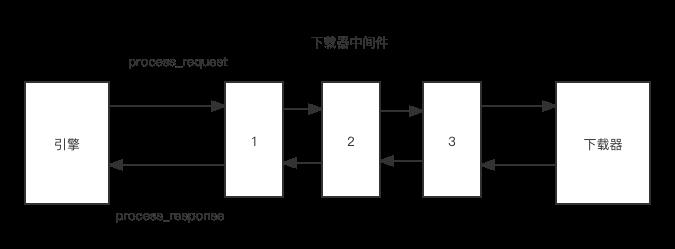
随机请求头中间件
前面这是介绍了Scrapy框架下载器中间件的理论知识,下面就以设置随机请求头来说明下中间件的作用。爬虫在频繁访问一个页面的时候,这个请求头如果一直保持一致,那么很容易被服务器发现,从而禁掉这个请求头的访问,因此我们要在访问这个页面之前随机的更改请求头,这就才可以避免爬虫被抓,随机更改请求头,可以在下载中间件中实现,在请求发送给服务器之前,随机的选择一个请求头,这样就可以避免总有一个请求头了。示例代码如下:
- 在middlewares.py 中添加如下示例代码
自定义下载器中间件类UserAgentDownloadMiddleware,并重写process_request方法,在该方法中从USER_ARGENTS列表中随机选择一个请求头设置到request中。
import random
class UserAgentDownloadMiddleware(object):
USER_ARGENTS = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.7.12) Gecko/20051215 Epiphany/1.8.4.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2866.71'
'Mozilla/5.0 (X11; U; Linux x86_64; en; rv:1.9.0.8) Gecko/20080528 Epiphany/2.22 Firefox/3.0'
]
def process_request(self, request, spider):
user_agent = random.choice(self.USER_ARGENTS)
request.headers['user-agent'] = user_agent
- 在settings.py 中放开下载器中间件的设置
指定我们自定义的下载器中间件,如果不设置的话则下载器中间件不会被执行。
DOWNLOADER_MIDDLEWARES =
'useragent_demo.middlewares.UserAgentDownloadMiddleware': 543,
设置完成之后运行scrapy项目可以看到如下结果
总结
本文以设置随机请求头为例说明了下载器中间件的作用,下载器中间件可以让我们你在下载之前做一些自定义设置。
粉丝专属福利
软考资料:实用软考资料
面试题:5G 的Java面试题
学习资料:50G的各类学习资料
脱单秘籍:回复【脱单】
并发编程:回复【并发编程】
👇🏻 验证码 可通过搜索下方 公众号 获取👇🏻
以上是关于Scrapy框架的下载器中间件讲解&并用下载器中间件设置随机请求头python爬虫入门进阶(24)的主要内容,如果未能解决你的问题,请参考以下文章
Scrapy框架设置UA池与代理池 -- 2019-08-08 17:20:36