scrapy框架中setting中中间件数字大的先执行么
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy框架中setting中中间件数字大的先执行么相关的知识,希望对你有一定的参考价值。
参考技术A 下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response(也包括引擎传递给下载器的Request)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。本回答被提问者采纳 参考技术B 数字越小的中间件越先执行 参考技术C 数字小的优先级高Scrapy详解之中间件(Middleware)
编程狗在线
自由的编程学习平台
.jpg")
概述
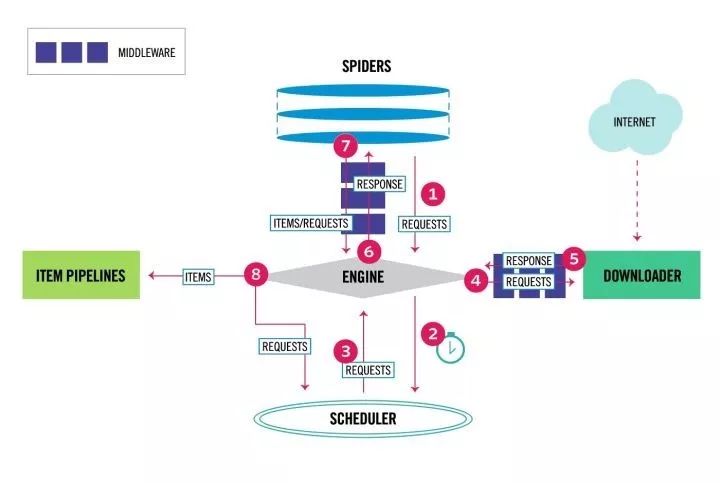
下载器中间件(Downloader Middleware)
如上图标号4、5处所示,下载器中间件用于处理scrapy的request和response的钩子框架,可以全局的修改一些参数,如代理ip,header等
使用下载器中间件时必须激活这个中间件,方法是在settings.py文件中设置DOWNLOADER_MIDDLEWARES这个字典,格式类似如下:
DOWNLOADERMIDDLEWARES = {
'myproject.middlewares.Custom_A_DownloaderMiddleware': 543,
'myproject.middlewares.Custom_B_DownloaderMiddleware': 643,
'myproject.middlewares.Custom_B_DownloaderMiddleware': None,
}
数字越小,越靠近引擎,数字越大越靠近下载器,所以数字越小的,processrequest()优先处理;数字越大的,process_response()优先处理;若需要关闭某个中间件直接设为None即可
自定义下载器中间件
有时我们需要编写自己的一些下载器中间件,如使用代理,更换user-agent等,对于请求的中间件实现process_request(request, spider);对于处理回复中间件实现process_response(request, response, spider);以及异常处理实现 process_exception(request, exception, spider)
process_request(request, spider)
每当scrapy进行一个request请求时,这个方法被调用。通常它可以返回
1.None
2.Response对象
3.Request对象
4.抛出IgnoreRequest对象
通常返回None较常见,它会继续执行爬虫下去。其他返回情况参考这里
例如下面2个例子是更换user-agent和代理ip的下载中间件
user-agent中间件
from faker import Faker
class UserAgent_Middleware():
def process_request(self, request, spider):
f = Faker()
agent = f.firefox()
request.headers['User-Agent'] = agent
代理ip中间件
class Proxy_Middleware():
def process_request(self, request, spider):
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = requests.get(xdaili_url)
proxy_ip_port = r.text
request.meta['proxy'] = 'https://' + proxy_ip_port
except requests.exceptions.RequestException:
print('获取讯代理ip失败!')
spider.logger.error('获取讯代理ip失败!')
scrapy中对接selenium
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from gp.configs import *
class ChromeDownloaderMiddleware(object):
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
if CHROME_PATH:
options.binary_location = CHROME_PATH
if CHROME_DRIVER_PATH:
self.driver = webdriver.Chrome(chrome_options=options, executable_path=CHROME_DRIVER_PATH) # 初始化Chrome驱动
else:
self.driver = webdriver.Chrome(chrome_options=options) # 初始化Chrome驱动
def __del__(self):
self.driver.close()
def process_request(self, request, spider):
try:
print('Chrome driver begin...')
self.driver.get(request.url) # 获取网页链接内容
return HtmlResponse(url=request.url, body=self.driver.page_source, request=request, encoding='utf-8',
status=200) # 返回HTML数据
except TimeoutException:
return HtmlResponse(url=request.url, request=request, encoding='utf-8', status=500)
finally:
print('Chrome driver end...')
process_response(request, response, spider)
当请求发出去返回时这个方法会被调用,它会返回
1.若返回Response对象,它会被下个中间件中的process_response()处理
2.若返回Request对象,中间链停止,然后返回的Request会被重新调度下载
3.抛出IgnoreRequest,回调函数 Request.errback将会被调用处理,若没处理,将会忽略process_exception(request, exception, spider)
当下载处理模块或process_request()抛出一个异常(包括IgnoreRequest异常)时,该方法被调用
通常返回None,它会一直处理异常from_crawler(cls, crawler)
这个类方法通常是访问settings和signals的入口函数
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_host = crawler.settings.get('MYSQL_HOST'),
mysql_db = crawler.settings.get('MYSQL_DB'),
mysql_user = crawler.settings.get('MYSQL_USER'),
mysql_pw = crawler.settings.get('MYSQL_PW')
)
scrapy自带下载器中间件
以下中间件是scrapy默认的下载器中间件
{
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
scrapy自带中间件请参考这里
Spider中间件(Spider Middleware)
如文章第一张图所示,spider中间件用于处理response及spider生成的item和Request
启动spider中间件必须先开启settings中的设置
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None,
}
数字越小越靠近引擎,process_spider_input()优先处理,数字越大越靠近spider,process_spider_output()优先处理,关闭用None
编写自定义spider中间件
process_spider_input(response, spider)
当response通过spider中间件时,这个方法被调用,返回Noneprocess_spider_output(response, result, spider)
当spider处理response后返回result时,这个方法被调用,必须返回Request或Item对象的可迭代对象,一般返回resultprocess_spider_exception(response, exception, spider)
当spider中间件抛出异常时,这个方法被调用,返回None或可迭代对象的Request、dict、Item
投稿邮箱:pythonpost@163.com
Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
▼点击下方阅读原文,进入学习Python
以上是关于scrapy框架中setting中中间件数字大的先执行么的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件