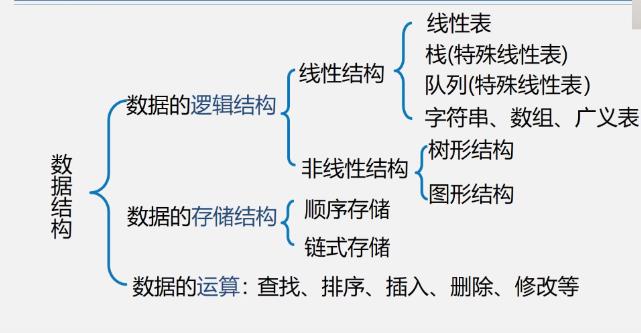
数据结构与算法学习笔记 查找
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法学习笔记 查找相关的知识,希望对你有一定的参考价值。
数据结构与算法学习笔记(9) 查找
文章目录
一.查找的基本概念
-
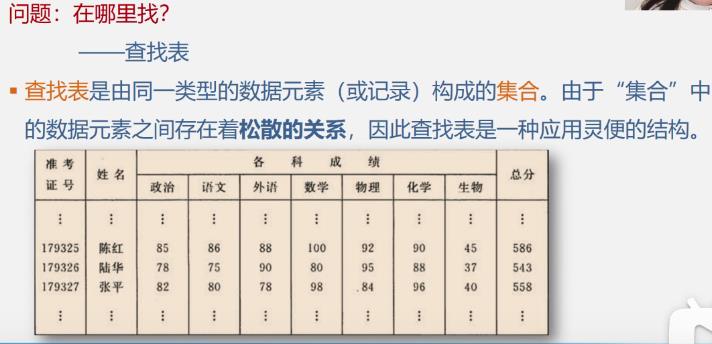
查找表
-
何为查找

-
怎样算找到

-
查找的目的

-
查找表的分类

-
查找算法的评价指标

-
查找过程的研究内容

二.线性表的查找
1.顺序查找
应用范围
-
顺序表或线性链表表示的静态查找表
-
表内元素之间无序
-
顺序表的表示
-
数据元素类型定义
typedef struct KeyType key; //关键字域 ...... //其他域 ElemType; typedef struct //顺序表结构类型定义 ElemType *R; //表基址 int length; //表长 SSTable; SSTable ST; //定义顺序表ST
-
算法

基本形式
int Search_Seq(SSTable ST,KeyType Key)
//若成功返回其位置信息,否则返回0
for(i=ST.length;i>=1;--i)
if(ST.R[i].key==key)
return i;
return 0;
该算法的其他形式:


这种形式for循环要加分号
改进算法
-
把待查关键字key存入表头,从后往前逐个比较,可免去查找过程中每一步都要检测是否查找完毕,加快速度
这样子就无需判断是否越界了

循环体是空语句,不要忘了分号

-
当ST.length较大时,此改进能使进行一次查找所需的时间几乎减少一半
-
算法效率分析

-
时间复杂度:O(n)

-
空间复杂度: 一个辅助空间——O(1)
-
-

特点
-
优点:
算法简单,逻辑次序无要求,且不同存储结构均适用
-
缺点:
ASL太长,时间效率太低

2.折半查找(二分查找)
-
折半查找:
每次将待查记录所在区间缩小一半
非递归算法
-
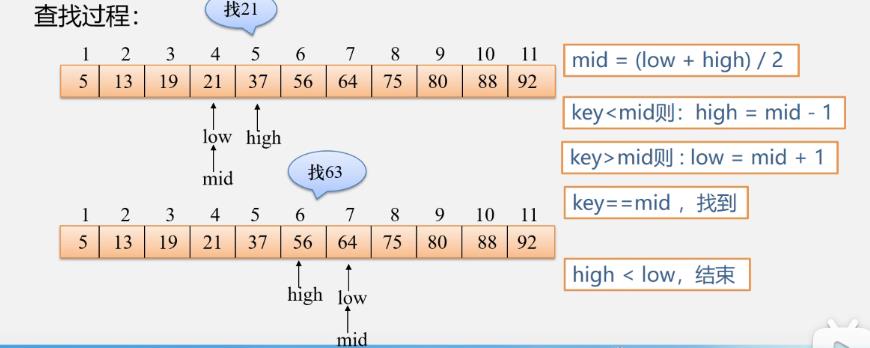
查找过程举例:
-
算法分析(非递归)

int Search_Bin(SSTable ST, KeyType key) low = 1; high = ST.length; //置区间初值 while(low <= high) mid = (low + high)/2; if(ST.R[mid].key == key) return mid; //找到待查元素 else if(key < ST.R[mid].key) //缩小查找区间 high = mid -1; //继续在前半区进行查找 else low = mid + 1; //继续在后半区查找 return 0; //顺序表中不存在待查元素
递归算法
int Search_Bin(SSTable ST,keyType key, int low ,int high)
if(low>high)
return 0; //没找到返回0
mid = (low+high)/2;
if(key==ST.elem[mid].key)
return mid;
else if(key<ST.elem[mid].key)
return Search_Bin(ST,key,low,mid-1); //前半区查找
else
return Search_Bin(ST,key,mid+1,high); //后半区查找
return 0;
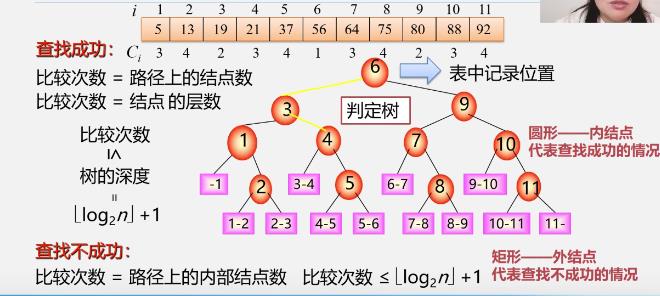
算法分析
判定树
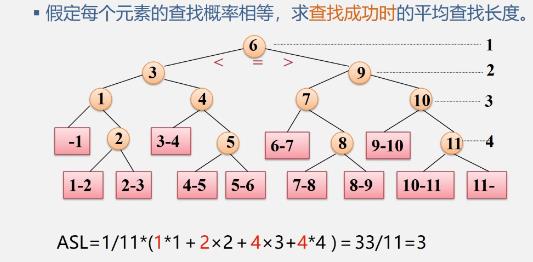

优缺点
- 优点
- 效率比顺序查找高
- 缺点
- 只适用于有序表,且限于顺序存储结构(对线性链表无效)
3.分块查找(索引查找)
- 很形象的一个例子就是
- 英文字典,分成了26个字母
条件
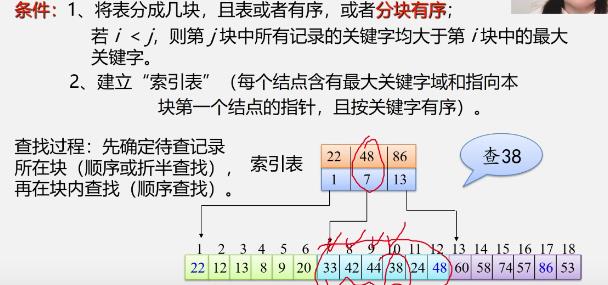
性能分析
-
查找效率

-
优缺点

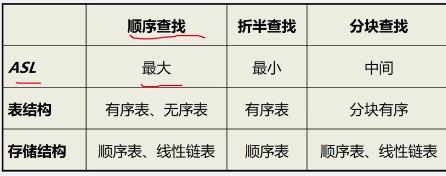
4.查找方法比较
三.树表的查找
- 顺序表的二分查找效率高,但是只适用于顺序表
1.二叉排序树
二叉排序树定义

-
二叉排序树也称为二叉搜索树、二叉查找树
-
定义

是一个递归定义
-
例

中序遍历二叉排序树的规律
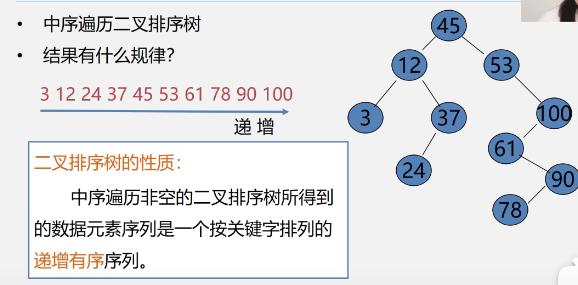
二叉排序树查找–递归算法
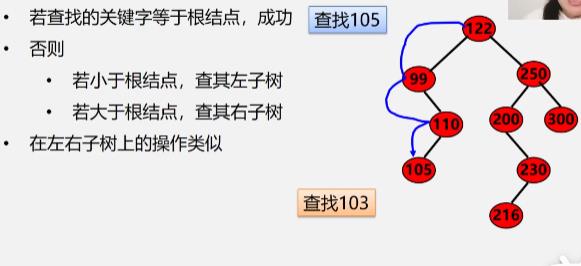
-
二叉排序树的存储结构
typedef struct KeyType key; //关键字项 InfoType otherinfo; //其他数据域 ElemType;typedef struct BSTNode ElemType data; //数据域 struct BSTNode *lchild,*rchild; //左右孩子指针 BSTNode, *BSTree; BSTree T; //定义二叉排序树T -
算法思想

-
算法描述
BSTree SearchBST(BSTree T,KeyType key) if((!T)||key==T->data.key) //树为空或者找到了直接return指针 return T; else if(key<T->data.key) retrun SearchBST(T->lchild,key); //在左子树中继续查找 else return SearchBST(T->rchild,key); //在右子树中继续查找 -
查找分析

-
平均查找长度

-
如何提高形态不均衡的二叉排序树的查找效率

-
二叉排序树的操作-插入

- 插入的元素一定在叶结点上
二叉排序树的操作-生成


-
不同插入次序的序列生成不同形态的二叉排序树
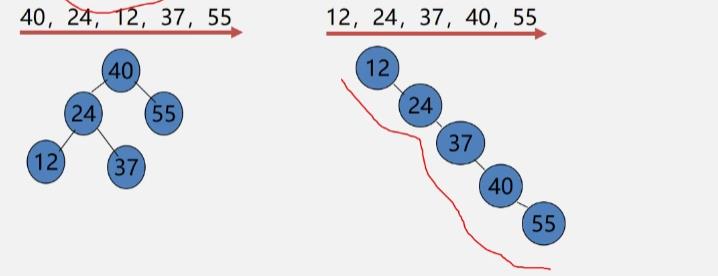
二叉排序树的操作-删除

删除叶子结点
- 直接删去
- 将其双亲结点中相应指针域的值改为”空“
被删除的结点只有左子树或者右子树
- 用其左子树或者右子树替换它
- 将其双亲结点的相应指针域的值改为”指向被删除结点的左子树或右子树“
被删除的结点既有左子树,也有右子树

-
例
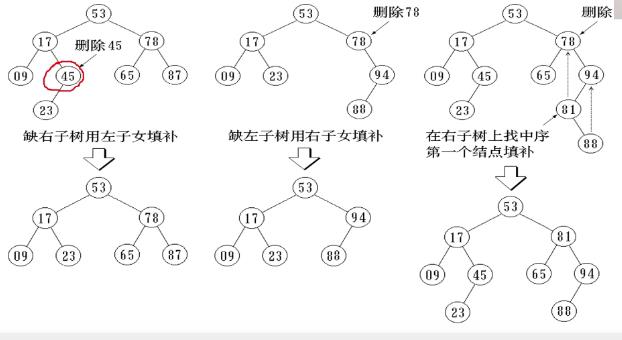
图3也可以用65来换,但是用65的话,树的高度没变
用81换可以减小树的高度
总结

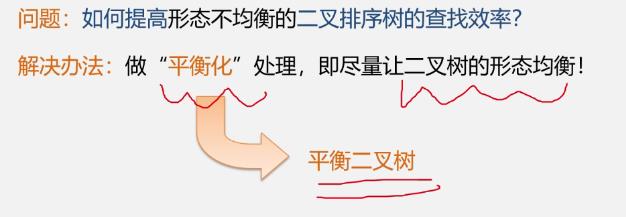
2.平衡二叉树
平衡二叉树定义
-
又称AVL树
-
平衡二叉树首先满足是二叉排序树

-
平衡因子

-
例
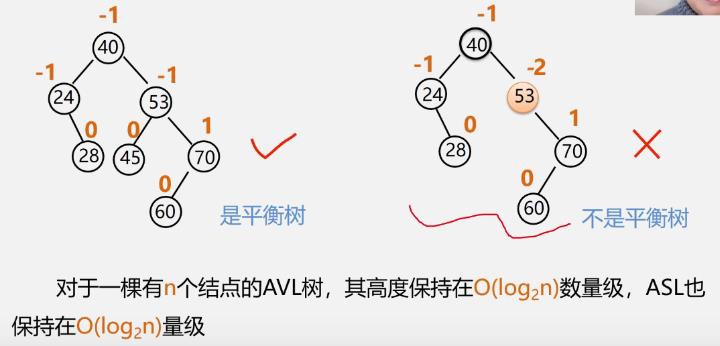
ASL:平均查找长度
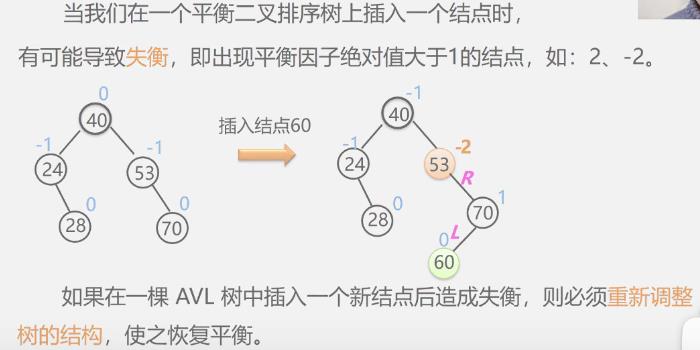
失衡二叉排序树的分析与调整
平衡调整的四种类型
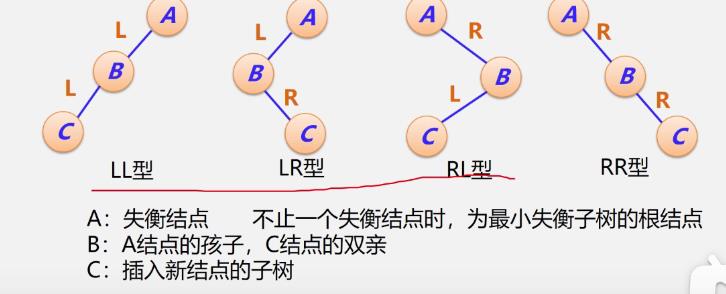
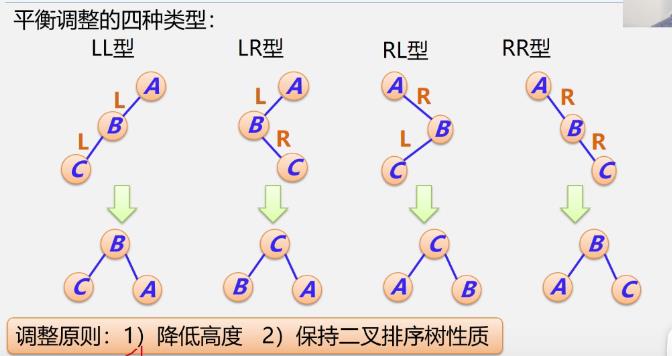
抓住调整原则
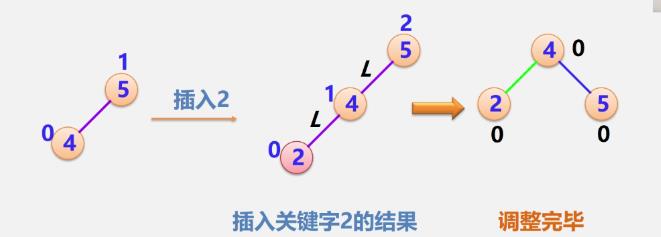
LL型

-
例
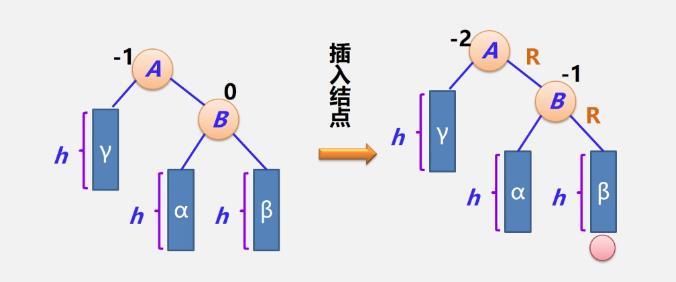
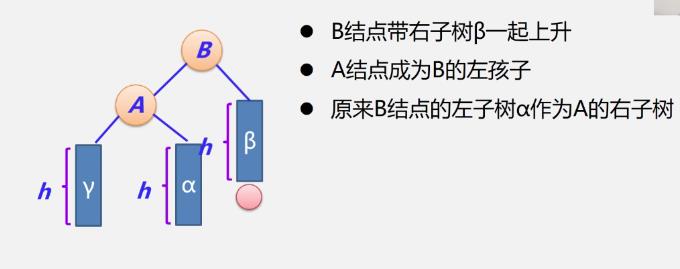
RR型
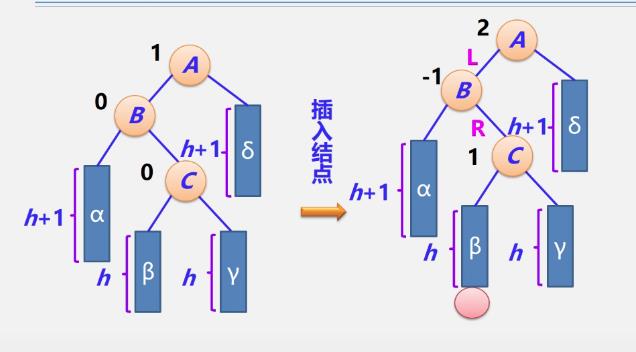
LR型
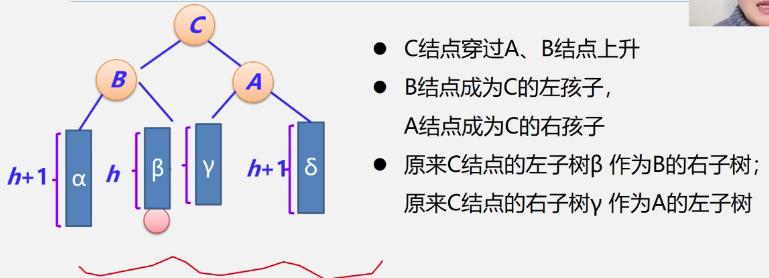
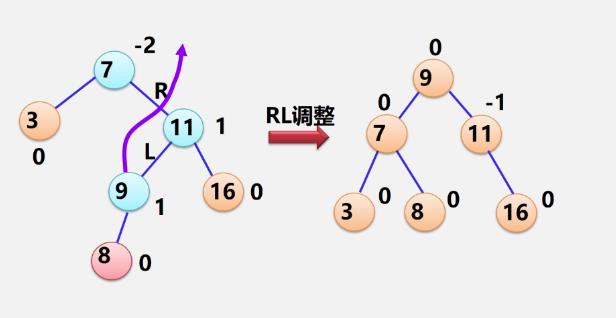
RL型
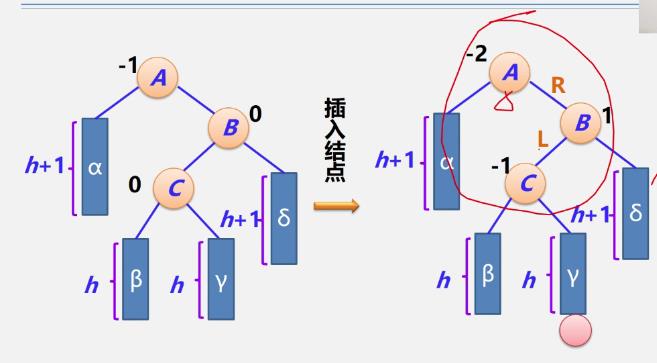
-
例
四.散列表的查找
1.基本概念
-
基本思想
记录的存储位置与关键字之间存在对应关系–hash(哈希)函数
Loc(i)=H(keyi) -
例

-
如何查找

-
2.一些术语
-
散列方法(杂凑法)

-
散列函数(杂凑函数)
散列方法中使用的转换函数
-
散列表

-
冲突

-
例

-
-
同义词
具有相同函数值的多个关键字
3.散列函数的构造方法

-
构造散列函数考虑的因素

-
根据元素集合的特性构造
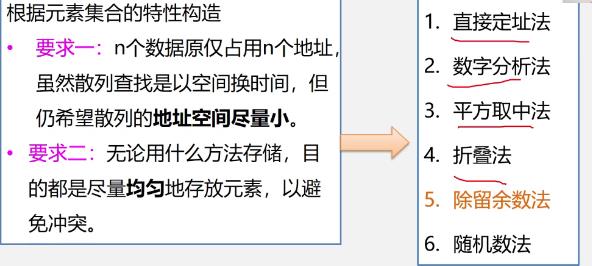
-
直接定址法

-
除留余数法
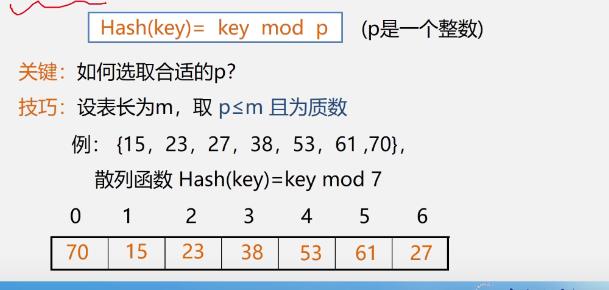
-
4.处理冲突的方法
开放地址法(开地址法)
-
基本思想
有冲突就去找下一个空的散列地址,只要散列表足够大
空的散列地址总能找到,并将数据元素存入
-
常用方法

-
线性探测法

-
二次探测法
增量序列是二次序列

-
伪随机探测法

-
链地址法(拉链法)
-
基本思想:
相同散列地址的记录链成一单链表
m个散列地址就设m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态结构
-
如:
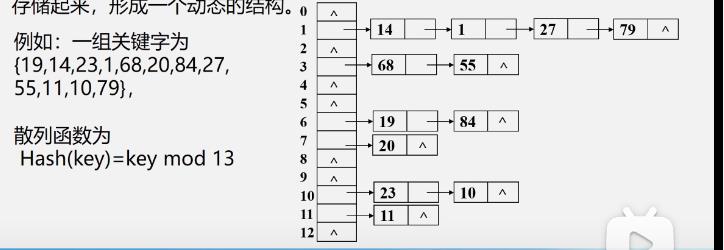
-
链地址法建立散列表步骤

-
链地址法的优点

5.散列表的查找及性能分析
-
查找过程
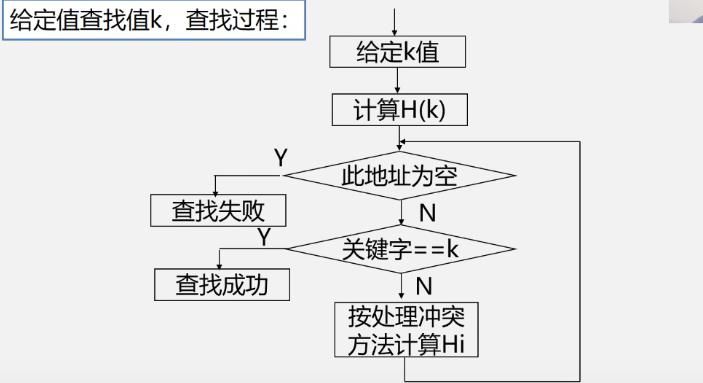
-
例
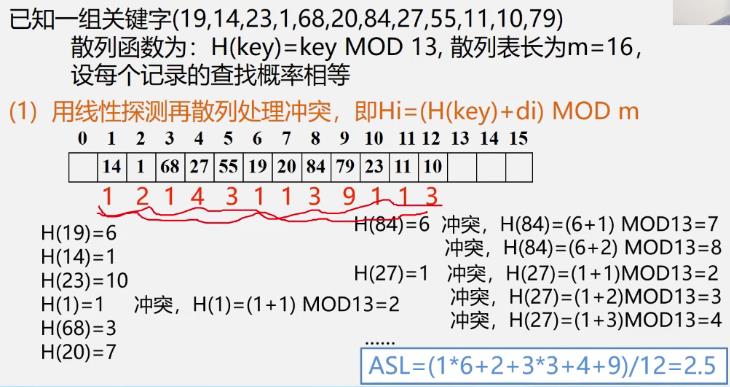
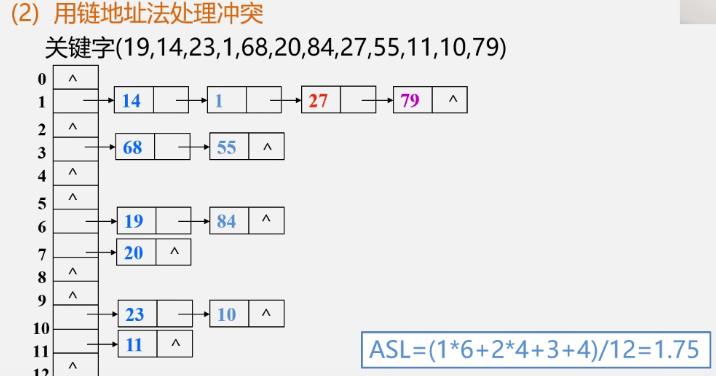
散列表查找效率分析


6.总结

以上是关于数据结构与算法学习笔记 查找的主要内容,如果未能解决你的问题,请参考以下文章