Kafka开发环境搭建及应用
Posted 我也要当昏君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka开发环境搭建及应用相关的知识,希望对你有一定的参考价值。
Kafka开发环境搭建及应用
kafka的介绍
Kafka 本质上是一个 MQ(Message Queue),使用消息队列的好处?
- 解耦:允许我们独立的扩展或修改队列两边的处理过程。
- 可恢复性:即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
- 缓冲:有助于解决生产消息和消费消息的处理速度不一致的情况。
- 灵活性&峰值处理能力:不会因为突发的超负荷的请求而完全崩溃,消息队列能够使关键组件顶
住突发的访问压力。
异步通信:消息队列允许用户把消息放入队列但不立即处理它。
典型应用: 原链接
 Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地
Elasticsearch 是一个分布式、RESTful ⻛格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。
作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
架构

注意:版面原因这里没有画上zookeeper, broker都是由zookeeper管理。
Kafka 存储的消息来自任意多被称为 Producer 生产者的进程。数据从而可以被发布到不同的Topic 主题下的不同 Partition 分区。
在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为 Consumer 消费者的进程可以从分区订阅消息。
Kafka 运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
下面给出 Kafka 一些重要概念,让大家对 Kafka 有个整体的认识和感知,后面还会详细的解析每一个概念的作用以及更深入的原理:
- Producer:消息生产者,向 Kafka Broker 发消息的客户端。
- Consumer:消息消费者,从 Kafka Broker 取消息的客户端。
- Consumer Group:消费者组(CG),消费者组内每个消费者负责消费不同分区的数据,提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 机器就是一个 Broker。一个集群( kafka cluster )由多个 Broker 组成。一个 Broker 可以容纳多个 Topic。
- Topic:可以理解为一个队列,Topic 将消息分类,生产者和消费者面向的是同一个 Topic。
- Partition:为了实现扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker(即服务器)上,一个 Topic 可以分为多个 Partition, 同一个topic在不同的分区的数据是不重复的, 每个 Partition 是一个有序的队列,其 表现形式就是一个一个的文件夹 。
- Replication : 每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Message:每一条发送的消息主体。
- Leader:每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。
- Follower:每个分区多个副本的“从”副本,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader。
- Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
- ZooKeeper:Kafka 集群能够正常工作,需要依赖于 ZooKeeper,ZooKeeper 帮助 Kafka存储和管理集群信息。
工作流程
Kafka集群将 Record 流存储在称为 Topic 的类别中,每个记录由一个键、一个值和一个时间戳组成。
 Kafka 是一个分布式流平台,这到底是什么意思?
Kafka 是一个分布式流平台,这到底是什么意思?
- 发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 以容错的持久方式存储记录流。
- 处理记录流。
Kafka 中消息是以 Topic 进行分类的,生产者生产消息,消费者消费消息,面向的都是同一个Topic。
Topic 是逻辑上的概念,而 Partition 是物理上的概念,每个 Partition 对应于一个 log 文件,该log 文件中存储的就是 Producer 生产的数据。
Producer 生产的数据会不断追加到该 log 文件末端,且每条数据都有自己的 Offset。
消费者组中的每个消费者,都会实时记录自己消费到了哪个 Offset,以便出错恢复时,从上次的位置继续消费。
日志默认在: /tmp/kafka-logs
存储机制
 由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制。
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制。
它将每个 Partition 分为多个 Segment,每个 Segment 对应两个文件:“.index” 索引文件和“.log” 数据文件。
这些文件位于同一文件下,该文件夹的命名规则为:topic 名-分区号。例如,test这个 topic 有三分分区,则其对应的文件夹为 test-0,test-1,test-2。
ls /tmp/kafka-logs/test-1
00000000000000009014.index
00000000000000009014.log
00000000000000009014.timeindex
leader-epoch-checkpoint
index 和 log 文件以当前 Segment 的第一条消息的 Offset 命名。下图为 index 文件和 log 文件
的结构示意图:
 “.index” 文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数据文件中 Message 的物理偏移量。
“.index” 文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数据文件中 Message 的物理偏移量。
查看索引:./kafka-dump-log.sh --files /tmp/kafka-logs/test-1/00000000000000000000.index
生产者
producer就是生产者,是数据的入口。Producer在写入数据的时候永远的找leader,不会直接将数据写入follower。

分区策略
分区原因:
- 方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个 Topic 又可以有多个 Partition 组成,因此可以以 Partition 为单位读写了。
- 可以提高并发,因此可以以 Partition 为单位读写了。
分区原则:我们需要将 Producer 发送的数据封装成一个 ProducerRecord 对象。
该对象需要指定一些参数:
- topic:string 类型,NotNull。
- partition:int 类型,可选。
- timestamp:long 类型,可选。
- key:string 类型,可选。
- value:string 类型,可选。
- headers:array 类型,Nullable。
指明 Partition 的情况下,直接将给定的 Value 作为 Partition 的值。
没有指明 Partition 但有 Key 的情况下,将 Key 的 Hash 值与分区数取余得到 Partition 值。
既没有 Partition 有没有 Key 的情况下,第一次调用时随机生成一个整数(后面每次调用都在这个整数上自增),将这个值与可用的分区数取余,得到 Partition 值,也就是常说的 Round-Robin轮询算法。
数据可靠性保证
为保证 Producer 发送的数据,能可靠地发送到指定的 Topic,Topic 的每个 Partition 收到Producer 发送的数据后,都需要向 Producer 发送 ACK(ACKnowledge 确认收到)。如果 Producer 收到 ACK,就会进行下一轮的发送,否则重新发送数据。
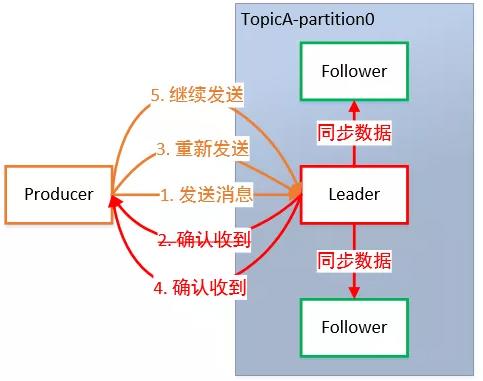
副本数据同步策略
何时发送 ACK?确保有 Follower 与 Leader 同步完成,Leader 再发送 ACK,这样才能保证Leader 挂掉之后,能在 Follower 中选举出新的 Leader 而不丢数据。
多少个 Follower 同步完成后发送 ACK?全部 Follower 同步完成,再发送 ACK。
| 方案 | 优点 | 缺点 |
|---|---|---|
| 半数以上完成同步,就发送ack | 延迟低 | 选举新的leader时,容忍n台节点故障,需要2n+1个副本。 |
| 全部完成同步,才发送ack | 选举新的leader时,容忍n台节点故障,需要n+1个副本。 | 延迟高。 |
ISR
采用第二种方案,所有 Follower 完成同步,Producer 才能继续发送数据,设想有一个 Follower因为某种原因出现故障,那 Leader 就要一直等到它完成同步。
这个问题怎么解决?Leader维护了一个动态的 in-sync replica set(ISR):和 Leader 保持同步的 Follower 集合。
当 ISR 集合中的 Follower 完成数据的同步之后,Leader 就会给 Follower 发送 ACK。
如果 Follower ⻓时间未向 Leader 同步数据,则该 Follower 将被踢出 ISR 集合,该时间阈值由replica.lag.time.max.ms 参数设定。Leader 发生故障后,就会从 ISR 中选举出新的 Leader。
ACK 应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 Follower 全部接受成功。
所以 Kafka 为用户提供了三种可靠性级别,用户根据可靠性和延迟的要求进行权衡,选择以下的配置。
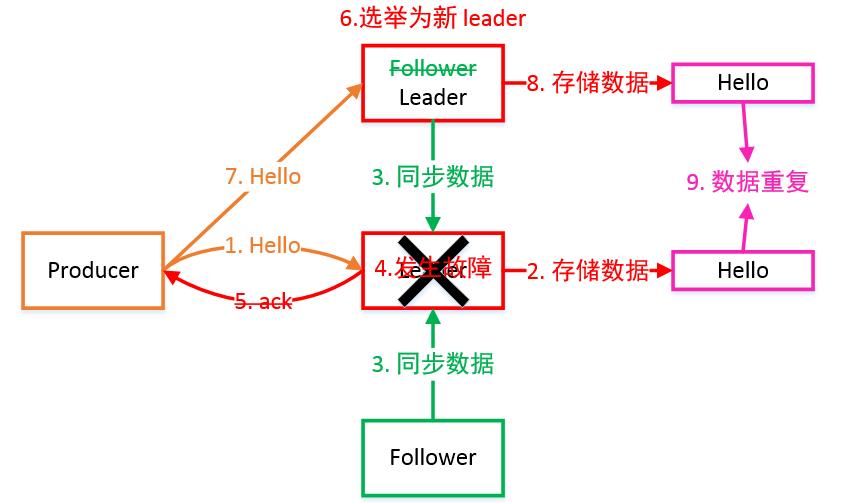
ACK 参数配置:
- 0:Producer 不等待 Broker 的 ACK,这提供了最低延迟,Broker 一收到数据还没有写入磁盘就已经返回,当 Broker 故障时有可能丢失数据。
- 1:Producer 等待 Broker 的 ACK,Partition 的 Leader 落盘成功后返回 ACK,如果在Follower 同步成功之前 Leader 故障,那么将会丢失数据。
- -1(all):Producer 等待 Broker 的 ACK,Partition 的 Leader 和 Follower 全部落盘成功后才返回 ACK。但是在 Broker 发送 ACK 时,Leader 发生故障,则会造成数据重复。
可靠性指标
没有一个中间件能够做到百分之百的完全可靠,可靠性更多的还是基于几个9的衡量指标,比如4个9、5个9。软件系统的可靠性只能够无限去接近100%,但不可能达到100%。所以kafka如何是实现最大可能的可靠性呢?
- 分区副本,你可以创建更多的分区来提升可靠性,但是分区数过多也会带来性能上的开销,一般来说,3个副本就能满足对大部分场景的可靠性要求
- acks,生产者发送消息的可靠性,也就是我要保证我这个消息一定是到了broker并且完成了多副本的持久化,但这种要求也同样会带来性能上的开销。它有几个可选项
- 1,生产者把消息发送到leader副本,leader副本在成功写入到本地日志之后就告诉生产者消息提交成功,但是如果isr集合中的follower副本还没来得及同步leader副本的消息,leader挂了,就会造成消息丢失
- -1,消息不仅仅写入到leader副本,并且被ISR集合中所有副本同步完成之后才告诉生产者已经提交成功,这个时候即使leader副本挂了也不会造成数据丢失。
- 0:表示producer不需要等待broker的消息确认。这个选项时延最小但同时⻛险最大(因为当server宕机时,数据将会丢失)。 - 保障消息到了broker之后,消费者也需要有一定的保证,因为消费者也可能出现某些问题导致消息没有消费到。
- enable.auto.commit默认为true,也就是自动提交offset,自动提交是批量执行的,有一个时间窗口,这种方式会带来重复提交或者消息丢失的问题,所以对于高可靠性要求的程序,要使用手动提交。 对于高可靠要求的应用来说,宁愿重复消费也不应该因为消费异常而导致消息丢失。
消费者
消费方式
Consumer 采用 Pull(拉取)模式从 Broker 中读取数据。
Pull 模式则可以根据 Consumer 的消费能力以适当的速率消费消息。Pull 模式不足之处是,如果Kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。
因为消费者从 Broker 主动拉取数据,需要维护一个⻓轮询,针对这一点, Kafka 的消费者在消费数据时会传入一个时⻓参数 timeout。
如果当前没有数据可供消费,Consumer 会等待一段时间之后再返回,这段时⻓即为 timeout。
分区分配策略
一个 Consumer Group 中有多个 Consumer,一个 Topic 有多个 Partition,所以必然会涉及到Partition 的分配问题,即确定哪个 Partition 由哪个 Consumer 来消费。
Kafka 有三种分配策略:
- RoundRobin
- Range,默认为Range
- Sticky
当消费者组内消费者发生变化时,会触发分区分配策略(方法重新分配)。
这里主要讲Range、RoundRobin。
Range(默认策略)
 Range 方式是按照主题来分的,不会产生轮询方式的消费混乱问题。
Range 方式是按照主题来分的,不会产生轮询方式的消费混乱问题。
假设我们有10个分区,3个消费者,排完序的分区将会是0,1,2,3,4,5,6,7,8,9;消费者线程排完序将会是C1-0,C2-0,C3-0。然后将partitions的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。在我们的例子里面,我们有10个分 区,3个消费者线程, 10/3 = 3,而且除不尽,那么消费者线程 C1-0将会多消费一个分区
结果看起来是这样的:
C1-0 将消费 0, 1, 2, 3 分区
C2-0将消费 4,5,6分区
C3-0将消费 7,8,9分区
假如我们有11个分区,那么最后分区分配的结果看起来是这样的:
C1-0将消费 0,1,2,3分区
C2-0将消费 4,5,6,7分区
C3-0 将消费 8, 9, 10 分区
假如我们有2个主题(T1和T2),分别有10个分区,那么最后分区分配的结果看起来是这样的:
C1-0 将消费 T1主题的 0, 1, 2, 3 分区以及 T2主题的 0, 1, 2, 3分区
C2-0将消费 T1主题的 4,5,6分区以及 T2主题的 4,5,6分区
C3-0将消费 T1主题的 7,8,9分区以及 T2主题的 7,8,9分区
可以看出,C1-0 消费者线程比其他消费者线程多消费了2个分区,这就是Range strategy的一个很明显的弊端
即是,如下图所示,Consumer0、Consumer1 同时订阅了主题 A 和 B,可能造成消息分配不对等问题,当消费者组内订阅的主题越多,分区分配可能越不均衡。
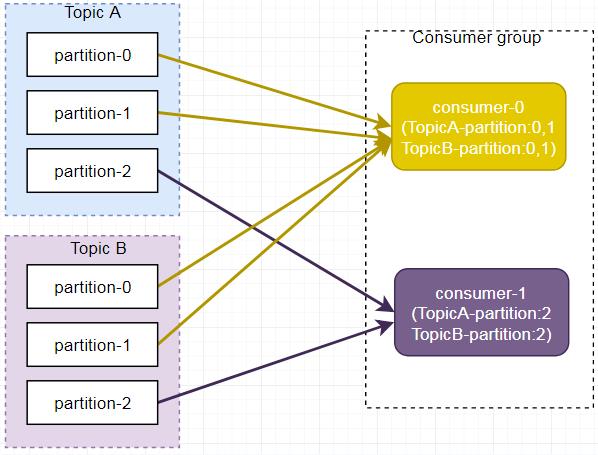 RoundRobin
RoundRobin
 RoundRobin 轮询方式将分区所有作为一个整体进行 Hash 排序,消费者组内分配分区个数最大差别为 1,是按照组来分的,可以解决多个消费者消费数据不均衡的问题。
RoundRobin 轮询方式将分区所有作为一个整体进行 Hash 排序,消费者组内分配分区个数最大差别为 1,是按照组来分的,可以解决多个消费者消费数据不均衡的问题。
轮询分区策略是把所有partition和所有consumer线程都列出来,然后按照hashcode进行排序。最后通过轮询算法分配partition给消费线程。如果所有consumer实例的订阅是相同的,那么partition会均匀 分布。
在我们的例子里面,假如按照 hashCode排序完的topic-partitions组依次为T1-5,T1-3,T1-0,T1-8,T1-2,T1-1,T1-4,T1-7,T1-6,T1-9,我们的消费者线程排序为C1-0,C1-1,C2-0,C2-1,最后分区分配的结果为:
C1-0将消费 T1-5,T1-2,T1-6分区;
C1-1将消费 T1-3,T1-1,T1-9分区;
C2-0将消费 T1-0,T1-4分区;
C2-1将消费 T1-8,T1-7分区;
但是,当消费者组内订阅不同主题时,可能造成消费混乱,如下图所示,Consumer0 订阅主题A,Consumer1 订阅主题 B。
 将 A、B 主题的分区排序后分配给消费者组,TopicB 分区中的数据可能分配到 Consumer0 中。
将 A、B 主题的分区排序后分配给消费者组,TopicB 分区中的数据可能分配到 Consumer0 中。
使用轮询分区策略必须满足两个条件
- 每个主题的消费者实例具有相同数量的流
- 每个消费者订阅的主题必须是相同的
kafka开发环境
安装Java环境
下载linux下的安装包
登陆网址: link.
 下载完成后,Linux默认下载位置在当前目录下的Download或下载文件夹下,通过命令cd ~/Downloads或cd ~/下载即可查看到对应的文件。
下载完成后,Linux默认下载位置在当前目录下的Download或下载文件夹下,通过命令cd ~/Downloads或cd ~/下载即可查看到对应的文件。
解压安装包jdk-8u202-linux-x64.tar.gz
tar -zxvf jdk-8u291-linux-x64.tar.gz
解压后的文件夹为jdk1.8.0_291
进入文件夹和查看文件
cd jdk1.8.0_291
ls
可以看到bin目录

将解压后的文件移到/usr/lib目录下
在/usr/bin目录下新建jdk目录
sudo mkdir /usr/lib/jdk
将解压的jdk文件移动到新建的/usr/lib/jdk目录下来
sudo mv jdk1.8.0_291 /usr/lib/jdk/
执行命令后可到 usr/lib/jdk 目录下查看是否移动成功。
配置java环境变量
这里是将环境变量配置在etc/profile,即为所有用户配置JDK环境。
使用命令打开/etc/profile文件
sudo vim /etc/profile
在末尾添加以下几行文字:
#set java env
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_291
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH

执行命令使修改立即生效
在终端输入,出现版本号说明安装成功。
java -version
Kafka的安装部署
下载kafka
wget https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
安装kafka
我们下载的kafka是已经编译好的程序,只需要解压即可得到执行程序。
tar -zxvf kafka_2.11-2.0.0.tgz
进入kafka目录,以及查看对应的文件和目录
cd kafka_2.11-2.0.0
ls
 bin:为执行程序
bin:为执行程序
config:为配置文件
libs:为库文件
配置和启动zookeeper
下载的kafka程序里自带了zookeeper,kafka自带的Zookeeper程序脚本与配置文件名与原生Zookeeper稍有不同。
kafka自带的Zookeeper程序使用bin/zookeeper-server-start.sh,以及bin/zookeeper-server-stop.sh来启动和停止Zookeeper。
kafka依赖于zookeeper来做master选举一起其他数据的维护。
- 启动zookeeper:zookeeper-server-start.sh
- 停止zookeeper:zookeeper-server-stop.sh
在config目录下,存在一些配置文件
zookeeper.properties
server.properties
所以我们可以通过下面的脚本来启动zk服务,当然,也可以自己独立搭建zk的集群来实现。这里我们直接使用kafka自带的zookeeper。
启动zookeeper
sh zookeeper-server-start.sh -daemon ../config/zookeeper.properties
默认端口为:2181,可以通过命令lsof -i:2181 查看zookeeper是否启动成功。
启动和停止kafka
- 修改server.properties(在config目录), 增加zookeeper的配置
zookeeper.connect=localhost:2181
- 启动kafka
sh kafka-server-start.sh -daemon ../config/server.properties
默认启动端口9092
- 停止kafka
sh kafka-server-stop.sh -daemon ../config/server.properties
kafka的基本操作
创建topic
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Replication-factor 表示该topic需要在不同的broker中保存几份,这里设置成1,表示在两个broker中保存两份Partitions分区数
查看topic
sh kafka-topics.sh --list --zookeeper localhost:2181
查看topic属性
sh kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
消费消息
sh kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test --from-beginning
发送消息
sh kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test
kafka-topics.sh 使用方式
围绕创建、修改、删除以及查看等功能。
查看帮助–help
/bin目录下的每一个脚本工具,都有着众多的参数选项,不可能所有命令都记得住,这些脚本都可以使
用 --help 参数来打印列出其所需的参数信息。
$ sh kafka-topics.sh --help
下面我们挑选其中使用最为频繁且重要的参数进行说明,以及其中一些坑进行标明。
副本数量不能大于broker的数量
kafka 创建主题的时候其副本数量不能大于broker的数量,否则创建主题 topic 失败.
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 1 --topic test1
创建主题–create
创建主题时候,有3个参数是必填的,分别是 --partitions(分区数量)、 --topic(主题名) 、 --replication-factor(复制系数), 同时还需使用 --create 参数表明本次操作是想要创建一个主题操作。
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test1
返回:
Created topic “test1”.
此时主题 test1 就已经创建了。另外在创建主题的时候,还可以附加以下两个选项:–if-not-exists 和–if-exists . 第一个参数表明仅当该主题不存在时候,创建; 第二个参数表明当修改或删除这个主题时候,仅在该主题存在的时候去执行操作。
查看broker上所有的主题 --list
sh kafka-topics.sh --list --zookeeper localhost:2181
返回:test1
其中test1便为我们创建的主题。
查看指定主题 topic 的详细信息 --describe
该参数会将该主题的所有信息一一列出打印出来,比如分区数量、副本系数、领导者等待。
sh kafka-topics.sh --describe --zookeeper localhost:2181 --topic test1
返回:
Topic:test1 PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test1
Partition: 0
Leader: 0 Replicas: 0
Isr: 0
修改主题信息 --alter(增加主题分区数量)
sh kafka-topics.sh --zookeeper localhost:2181 --topic test1 --alter -- partitions 2
WARNING: If partitions are increased for a topic that has a key, the
partition logic or ordering of the messages will be affected
Adding partitions succeeded!
可以看到已经成功的将主题的分区数量从1修改为了2。
**如果去修改一个不存在的topic信息会怎么样?**比如修改主题 test2,当前这主题是不存在的。
sh kafka-topics.sh --zookeeper localhost:2181 --topic test2 --alter --
partitions 2
Error while executing topic command : Topic test2 does not exist on ZK path
localhost:2181
[2021-07-12 17:28:59,253] ERROR java.lang.IllegalArgumentException: Topic
test2 does not exist on ZK path localhost:2181
at kafka.admin.TopicCommand$.alterTopic(TopicCommand.scala:123)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:65)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
(kafka.admin.TopicCommand$)
注意:不要使用 --alter 去尝试减少分区的数量,如果非要减少分区的数量,只能删除整个主题topic, 然后重新创建
删除主题 topic --delete
sh kafka-topics.sh --zookeeper localhost:2181 --delete --topic test1
Topic test1 is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
日志信息提示,主题 test1已经被标记删除状态,但是若delete.topic.enable 没有设置为 true , 则将
不会有任何作用。
启动生产者:sh kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test1
启动消费者:sh kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test1 --from-beginning
发现此时还是可以发送消息和接收消息。
如果要支持能够删除主题的操作,则需要在 /bin 的同级目录 /config目录下的文件server.properties
中,修改配置delete.topic.enable=true(如果置为false,则kafka broker 是不允许删除主题的)。

需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
重启kafka
停止:sh kafka-server-stop.sh -daemon …/config/server.properties
启动:sh kafka-server-start.sh -daemon …/config/server.properties
再次删除
sh kafka-topics.sh --zookeeper localhost:2181 --delete --topic test1
参考
2万字⻓文深入详解 Kafka,从源码到架构全部讲透
https://mp.weixin.qq.com/s/dOiNT0a_dRytwatzdrJNCg
Kafka 日志存储
https://zhuanlan.zhihu.com/p/65415304
本文部分技术点出处,C/C++Linux服务器开发/后台架构师:https://ke.qq.com/course/417774?flowToken=1041622
以上是关于Kafka开发环境搭建及应用的主要内容,如果未能解决你的问题,请参考以下文章
Docker环境下使用docker-compose一键式搭建kafka集群及kafka管理工具EFAK
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数