Hadoop中mapreduce作业日志是如何生成的
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop中mapreduce作业日志是如何生成的相关的知识,希望对你有一定的参考价值。
摘要:本篇博客介绍了hadoop中mapreduce类型的作业日志是如何生成的。主要介绍日志生成的几个关键过程,不涉及过多细节性的内容。
本文分享自华为云社区《hadoop中mapreduce作业日志是如何生成的》,作者:mxg。
我们知道hadoop分为三大块:HDFS,Yarn,Mapreduce。其中mapreduce相关的核心代码都在hadoop-mapreduce-project子工程中。
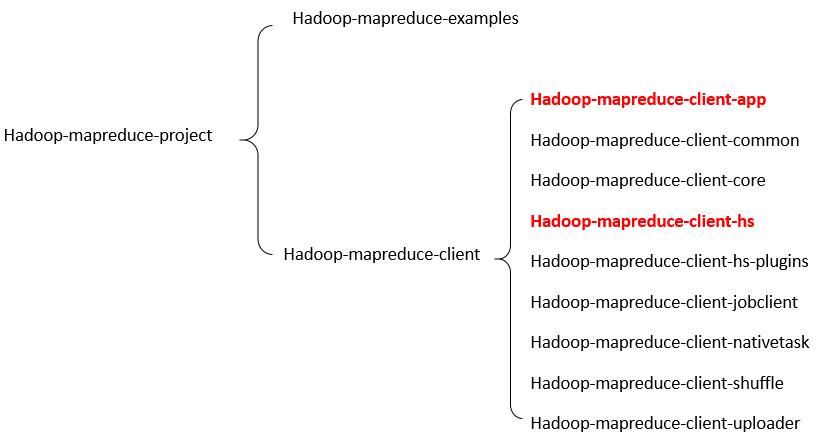
其中比较重要的功能模块有:MRAppMaster, JobHistory,以及mapreduceClient,分别对应上面的app,hs和jobclient。当然还有一些公共的工具类这里不再细表。
MRAppMaster:作为一个yarn application运行的第一个Container,用于为所属的mapreduce job申请task资源,并且监控task的运行状态。
注意这里引入了名词:yarn application和mapreduce job,其实是同一个事物两种不同层面下的叫法。Yarn里面运行的所有的应用都称之为application,而job是一个mapreduce类型的application在mapreduce框架下的叫法,在其他计算框架下可能又有别的叫法,总之一点,无论在计算框架侧怎么叫,在yarn这里都是yarn application。
记住这些开源社区既定的名词有助于我们理解代码,例如当看到job相关的接口,潜意识就要反应过来,这是jobhistory或者MRAppMaster的接口,如果是Application相关的接口,那么这肯定是ResourceManager的接口。
HistoryServer:我们知道yarn application 在AM运行的时候,默认会将这个job的运行日志上传到hdfs路径:/tmp/hadoop-yarn/staging,当然也可以使用参数:yarn.app.mapreduce.am.staging-dir配置成任何想要的路径。甚至可以跨域文件系统,例如不在hdfs上面存储。AM日志最终会组织成一个特定的格式jhist,HistoryServer会去解析,并通过web页面友好的展示出来。
jobclient:提供一些接口用于用于job的管理,例如作业的提交。
下面介绍下一个mapreduce job的AM日志生成的几个阶段。其中设计三个重要的参数:
1-运行完的mr作业的临时日志目录;
mapreduce.jobhistory.intermediate-done-dir:/mr-history/tmp
2-运行完的mr作业的最终目录
mapreduce.jobhistory.done-dir: /mr-history/done
3-AM运行过程中的日志持久化目录
yarn.app.mapreduce.am.staging-dir: /tmp/hadoop-yarn/staging
下面介绍AM日志在job运行的不同阶段在上面的三个目录中是如何转移的。
Phase1
AM的运行日志会存放到hdfs路径:/tmp/hadoop-yarn/staging,并且在job运行的过程中一直动态更新.
Phase2
Job运行完成之后,AM会将/tmp/hadoop-yarn/staging路径下面的job日志拷贝到/mr-history/tmp路径下(包含:jhist文件,summary文件以及conf.xml文件),刚拷贝过去的时候这些文件均已.tmp为后缀;
完全拷贝成功之后才会将tmp后缀的文件全部重命名为正常的文件名;

Phase3
JobHistoryServer进程中有一个JobHistory类型的Service(参考JHS的初始化过程以及服务介绍章节)
而JobHistory这个Service功能很简单:
1-定时将phase2生成的/mr-history/tmp目录下的完成job的日志拷贝到/mr-history/done目录下,当然拷贝完之后即删除/mr-history/tmp下面的日志文件;
2-定时扫描/mr-history/done目录下的job日志文件,将超过生存周期的全部删掉,即删掉之后的job信息将不能在JobHistoryServer 的web页面中看到了。
因此对于一个已经运行结束的mapreduce job,我们从JobHistoryServer的web页面上可以正常访问其job日志以及每一个task的日志。其实就是访问了/mr-history/done和/tmp/logs/日志。
其中/mr-history/done/里面记录了job的一些配置以及task的基本概况信息(多少map,多少reduce,多少成功,多少失败等)。
其中/tmp/logs种记录了application中所有的container(即task)的详细日志,从job页面跳转到task页面的数据就是从这里获取的。
细心的小伙伴可能已经注意到了,phase2的AM日志截图中不难看出,在作业运行完成之后,日志拷贝到intermediate-dir之前,首先设置了这个job日志的链接。这个链接其实就是jobhistoryServer web服务的地址。
一个典型的正在运行的application在yarn的原生页面中的信息如下图所示。其链接为:https://RESOURCEMANAGER_IP:PORT/Yarn/ResourceManager/45/proxy/application_1636508815320_0003/。
显然,这时候访问的还是resourceManager,也就是说在运行的过程当时还和jobhistoryServer没有什么关系。

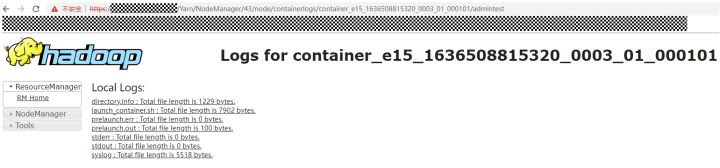
类似的,如果我们要查看一个运行过程中的job的某些已经运行结束的task的详细日志信息,那么将会访问相应的nodemanager获取,如下图所示。
从链接信息中也不难看出,这里访问的是nodemanager,该过程也和jobhistoryServer没有什么关系。
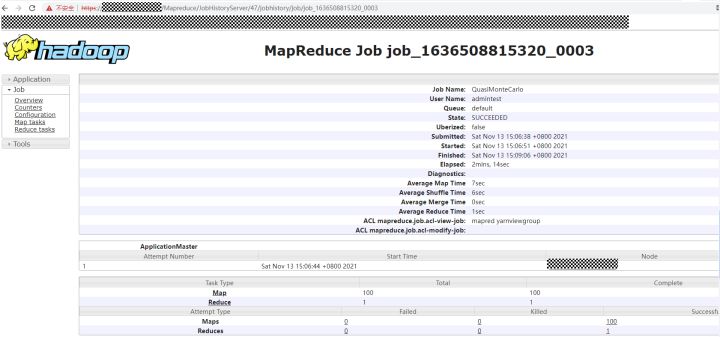
然而当一个yarn application运行结束的之后,application概览页面的History链接就不再是上面的ResourceManager链接了,转而变成了JobHistoryServer链接。
也即是说对于一个运行过程中的job,页面上的所有日志访问请求都是yarn承接的,而对于已经运行结束的job,除了yarn的application 页面概览之外,之后的所有请求都会跳转到JobHistoryServer来处理。
一个运行结束的job的连接可能是这样:https://RESOURCEMANAGER_IP:PORT/Yarn/ResourceManager/45/proxy/application_1636508815320_0003/
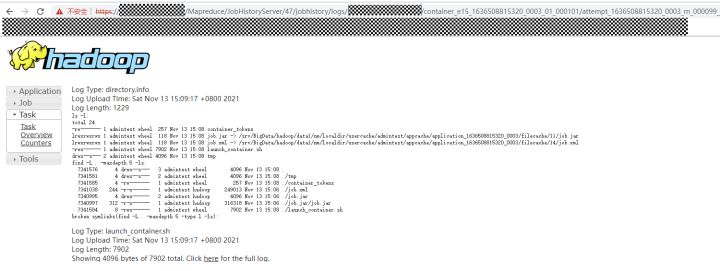
同样,对于一个已经运行完成的job,查看其某一个task/container日志的时候也是由JobHistoryServer进行处理的。
以上是关于Hadoop中mapreduce作业日志是如何生成的的主要内容,如果未能解决你的问题,请参考以下文章
使用 hadoop mapreduce 作业从日志文件分析时间范围内的总错误条目发生率
Hadoop MapReduce 作业成功完成,但未向 DB 写入任何内容