聊聊 Kafka: Consumer 源码解析之 Consumer 如何加入 Consumer Group
Posted 老周聊架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊 Kafka: Consumer 源码解析之 Consumer 如何加入 Consumer Group相关的知识,希望对你有一定的参考价值。
一、前言
今天这一篇我们来说一下 Consumer 是如何加入 Consumer Group 的,我们前面有一篇 Kafka 的架构文章有说到,Consumer 有消费组(Consumer Group)的概念,而 Producer 没有生产组的概念。所以说 Consumer 侧会比 Producer 侧复杂点,除了消费者有消费组的概念,还需要维护管理 offset 偏移量、重复消费等问题。
与消费组相关的两个组件,一个是消费者客户端的 ConsumerCoordinator,一个是 Kafka Broker 服务端的 GroupCoordinator。ConsumerCoordinator 负责与 GroupCoordinator 通信,Broker 启动的时候,都会启动一个 GroupCoordinator 实例,而一个集群中,会有多个 Broker,那么如何确定一个新的 Consumer 加入 Consumer Group 后,到底和哪个 Broker 上的 GroupCoordinator 进行交互呢?
别急,聪明的程序员肯定是有办法的,我们还是先来说一下 GroupCoordinator 吧。
二、GroupCoordinator
别问,问就是有相应的算法和策略。那我们就来看下是啥算法和策略实现 Consumer 正确找到 GroupCoordinator 的,这就和 Kafka 内部的 Topic __consumer_offsets 有关系了。
2.1 __consumer_offsets
__consumer_offsets 这个内部 Topic,专门用来存储 Consumer Group 消费的情况,默认情况下有 50 个 partition,每个 partition 默认三个副本。如下图所示:
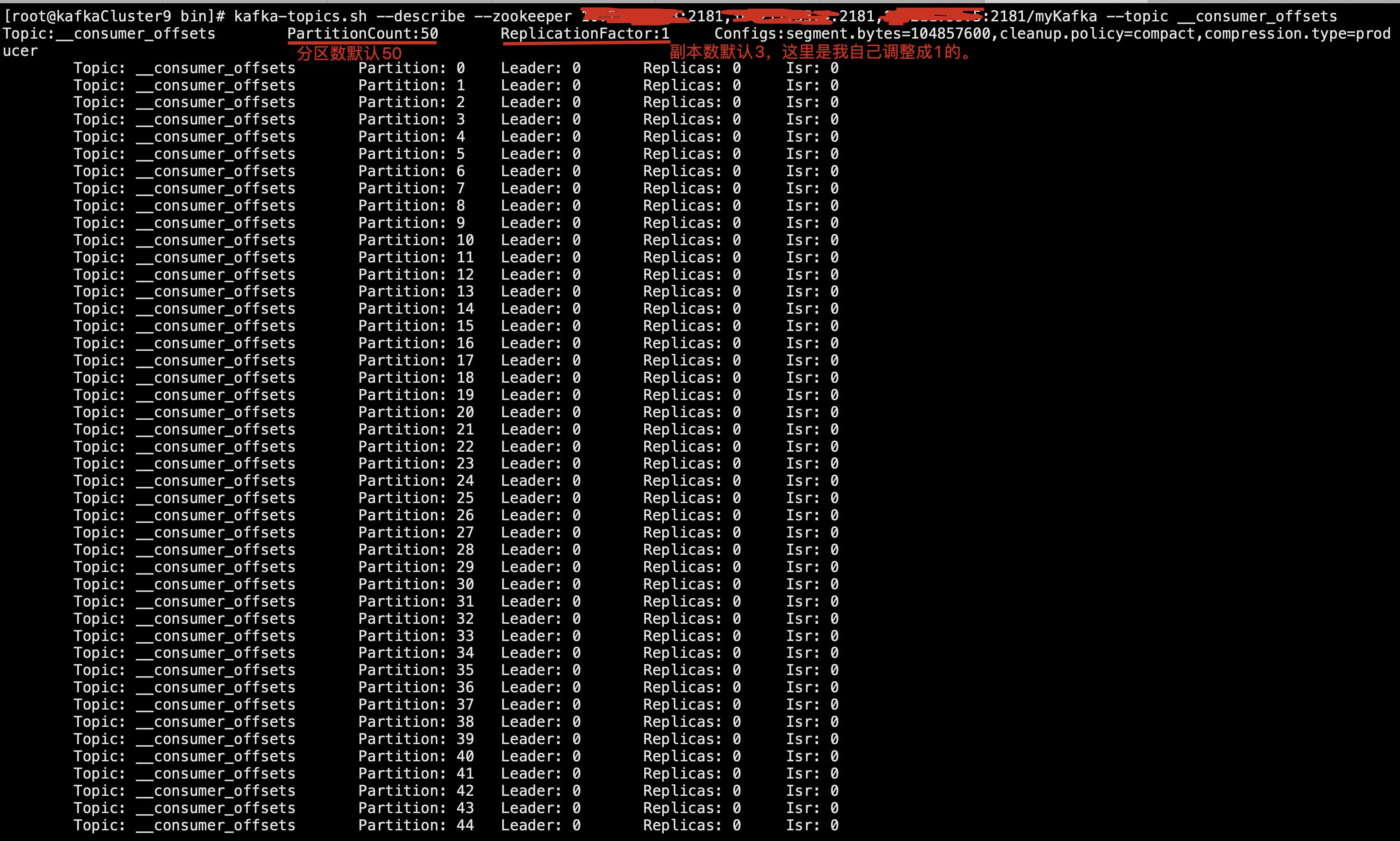
2.2 Consumer 如何找到 GroupCoordinator 的?
每个 Consumer Group 都有其对应的 GroupCoordinator,当一个新的 Consumer 要寻找和它交互的 GroupCoordinator 时,需要先对它的 GroupId 进行 hash,然后取模 __consumer_offsets 的 partition 数量,最后得到的值就是对应 partition,那么这个 partition 的 leader 所在的 broker 即为这个 Consumer Group 要交互的 GroupCoordinator 所在的节点。获取 partition 公式如下:
abs(GroupId.hashCode()) % NumPartitions
举个例子,假设一个 GroupId 计算出来的 hashCode 是 8,之后取模 50 得到 8。那么 partition-8 的 leader 所在的 broker 就是我们要找的那个节点。这个 Consumer Group 后面都会直接和该 broker 上的 GroupCoordinator 交互。
三、Group 状态变更
说 Consumer 加入 Consumer Group 流程之前,老周觉得有必要先说一下 Consumer Group 的状态变更。
3.1 消费端
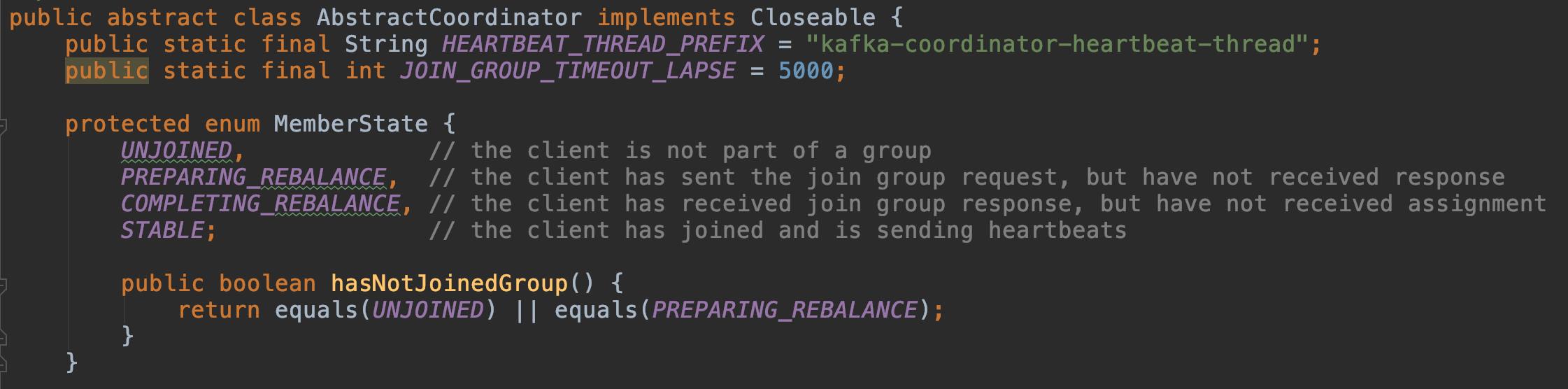
在协调器 AbstractCoordinator 中的内部类 MemberState 中我们可以看到协调器的四种状态,分别是未注册、重分配后没收到响应、重分配后收到响应但还没有收到分配、稳定状态。
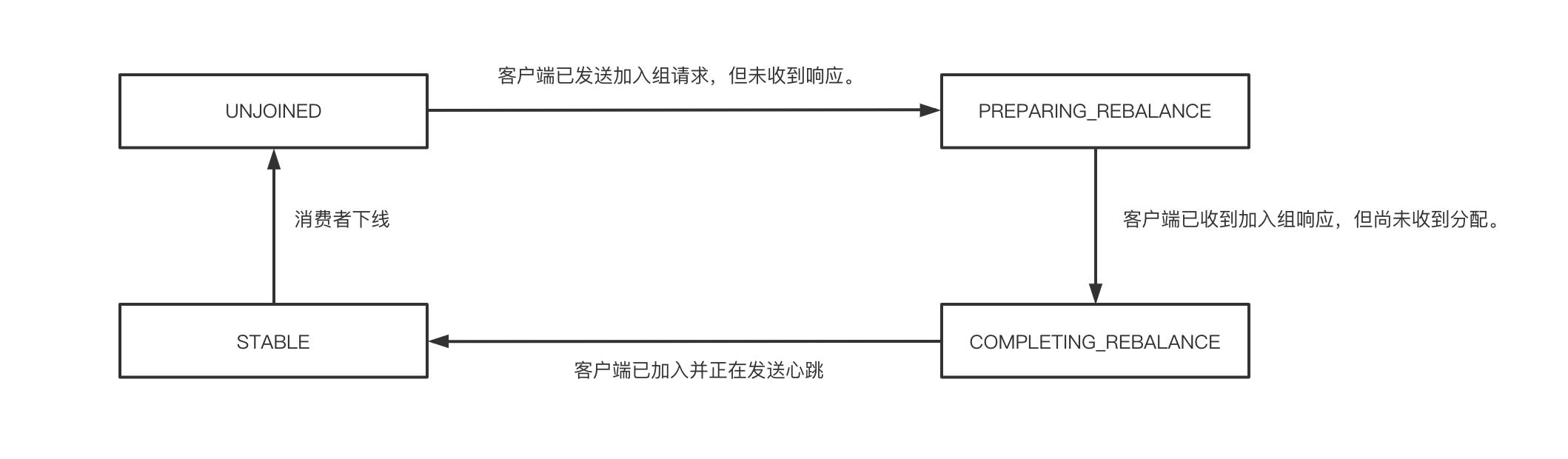
上述消费端的四种状态的转换如下图所示:
3.2 服务端
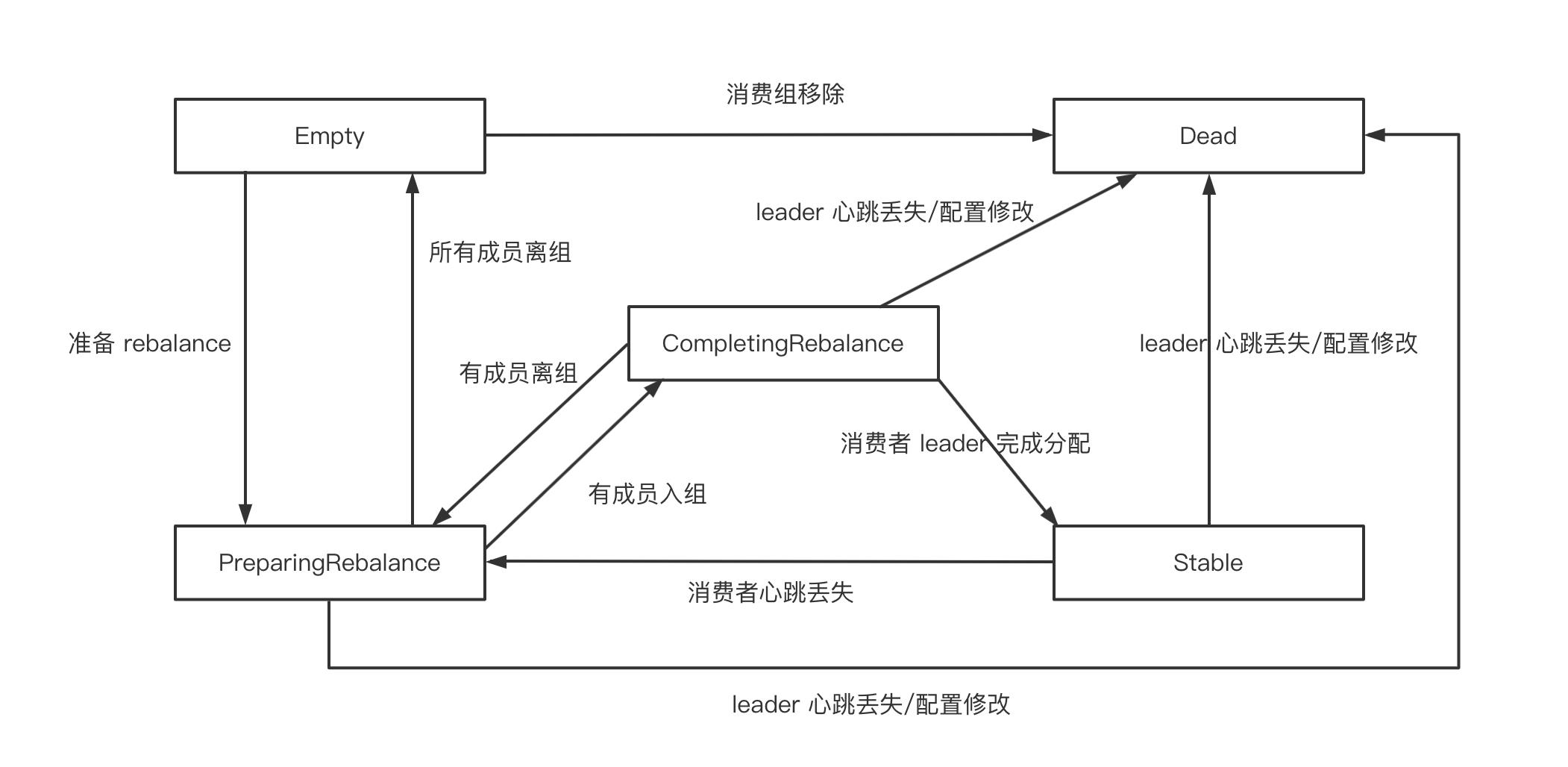
对于 Kafka 服务端的组则有五种状态 Empty、PreparingRebalance、CompletingRebalance、Stable、Dead。他们的状态转换如下图所示:

四、Consumer 加入 Consumer Group 流程
说 Consumer 如何加入 Consumer Group 之前,我们还是先来回顾下上一篇消息消费的测试案例。
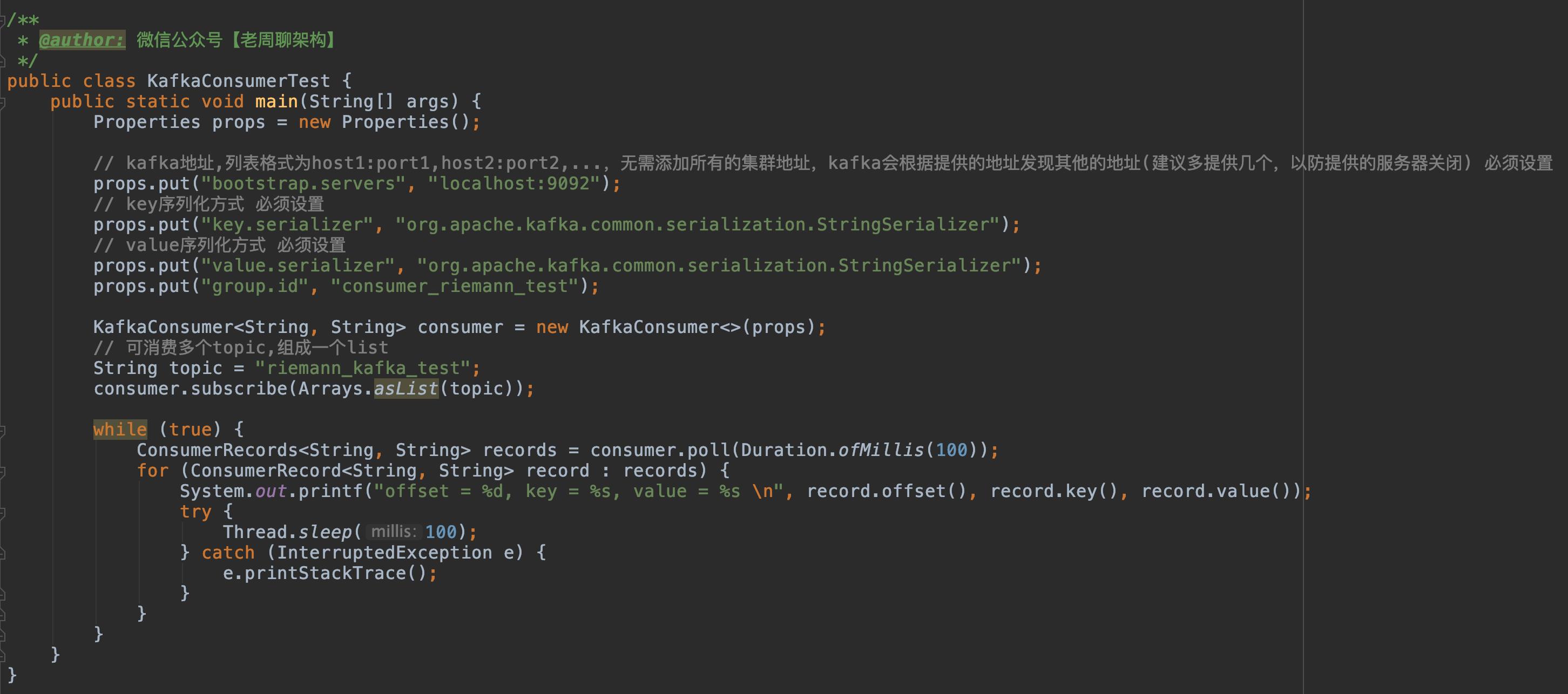
核心方法是 poll() 方法,我们这里简单提一下,后面我们会详细介绍 Consumer 关于 poll 的网络模型。
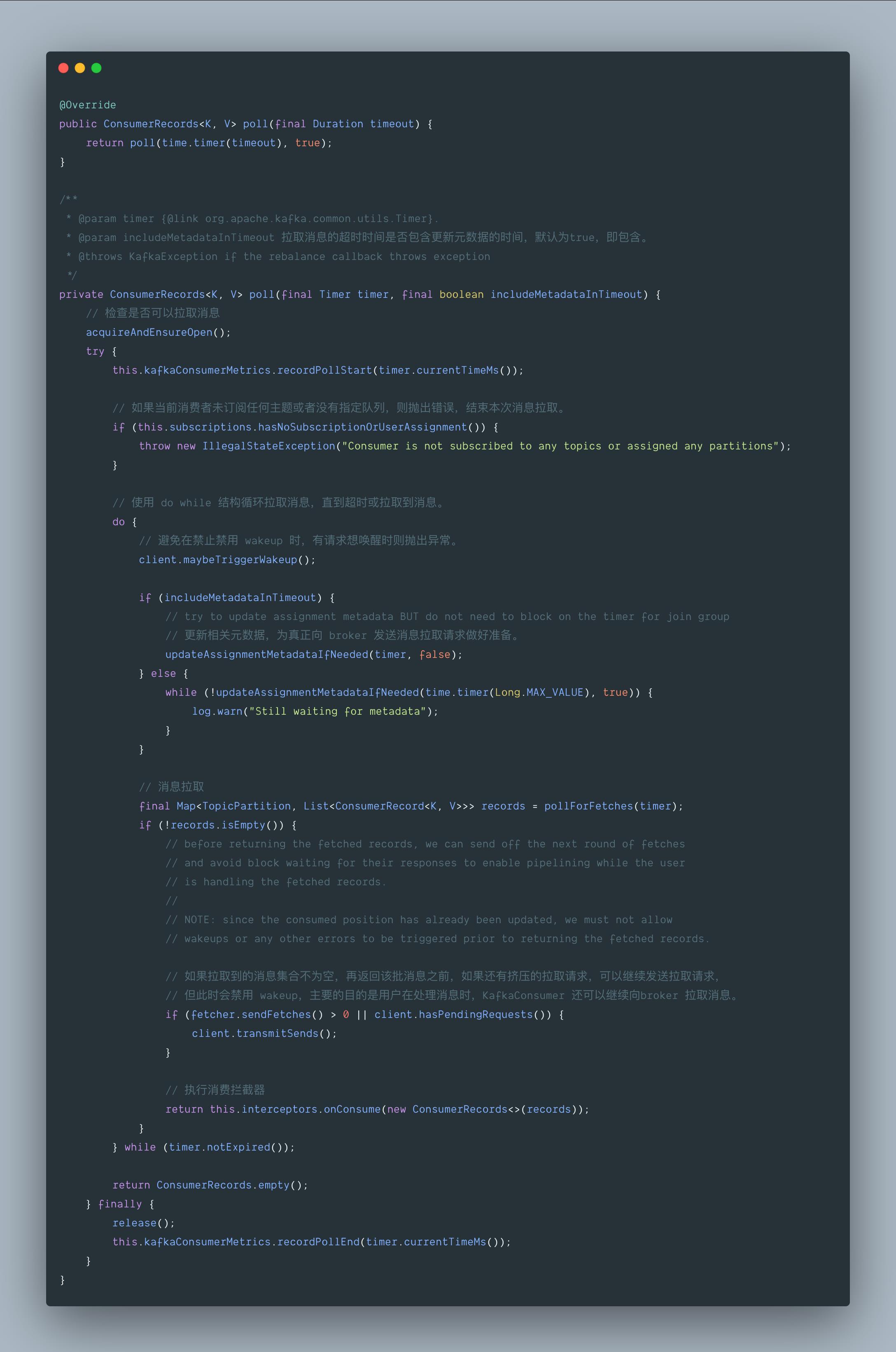
Consumer 如何加入 Consumer Group 的,我们得来看啥时候与 GroupCoordinator 交互通信的,不难发现在消息拉取请求做准备 updateAssignmentMetadataIfNeeded() 这个方法里。
然后关于对 ConsumerCoordinator 的处理都集中在 coordinator.poll() 方法中。
我们来跟一下这两个方法:
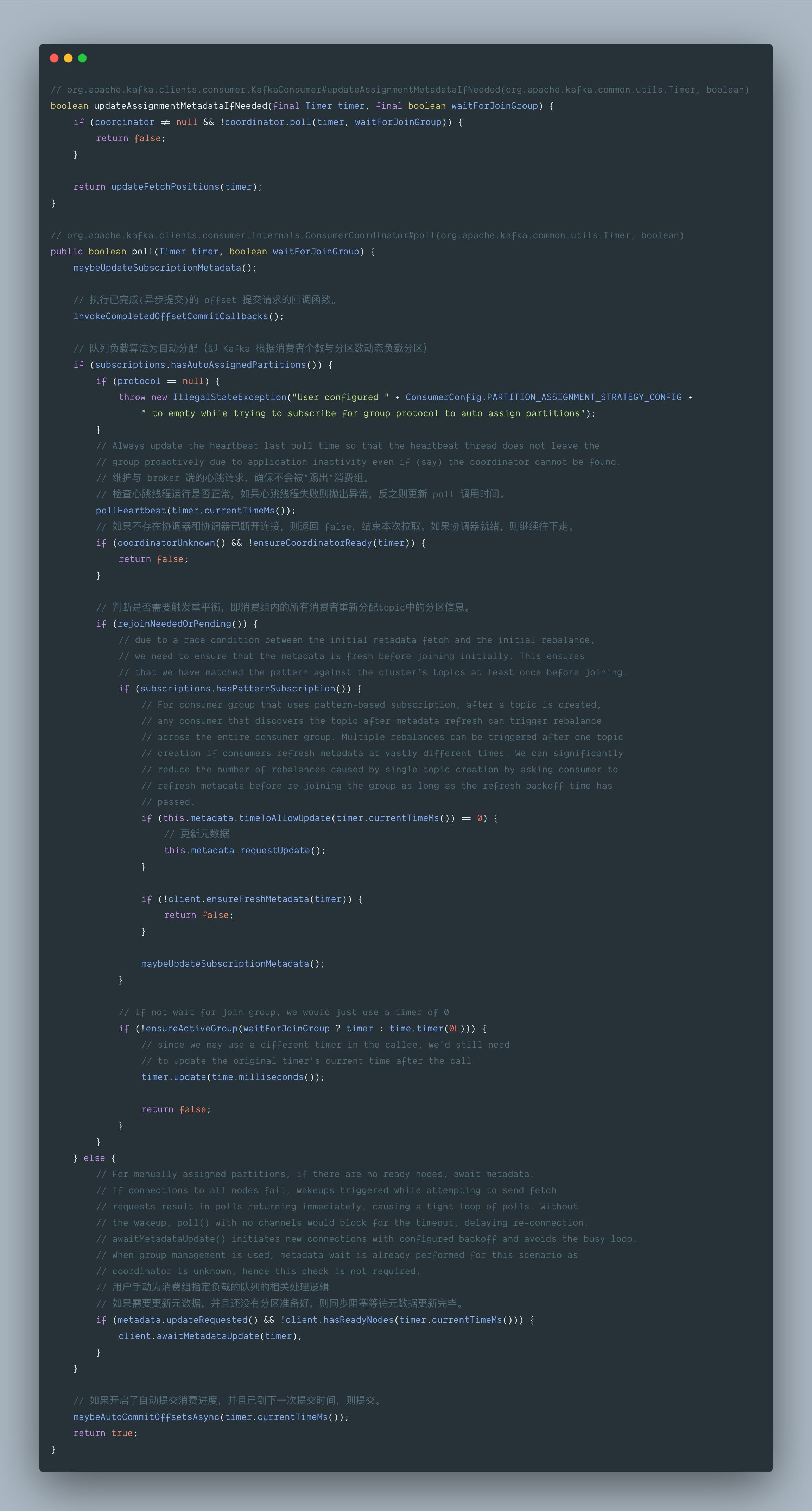
org.apache.kafka.clients.consumer.internals.ConsumerCoordinator#poll(org.apache.kafka.common.utils.Timer, boolean) 方法中,具体可以分为以下几个步骤:
- 检测心跳线程运行是否正常 (需要定时向 GroupCoordinator 发送心跳,在建立连接之后,建立连接之前不会做任何事情)
- 如果不存在协调器和协调器已断开连接,则返回 false,结束本次拉取。如果 coordinator 未知,就初始化 ConsumerCoordinator (在 ensureCoordinatorReady() 中实现)
- 判断是否需要触发重平衡,即消费组内的所有消费者重新分配 topic 中的分区信息。
- 通过 ensureActiveGroup() 发送 join-group、sync-group 请求,加入 group 并获取其 assign 的 TopicPartition list。
- 如果需要更新元数据,并且还没有分区准备好,则同步阻塞等待元数据更新完毕。
- 如果开启了自动提交消费进度,并且已到下一次提交时间,则提交。
其中,有几个地方需要详细介绍,那就是 ensureCoordinatorReady() 方法、rejoinNeededOrPending() 方法和 ensureActiveGroup() 方法。
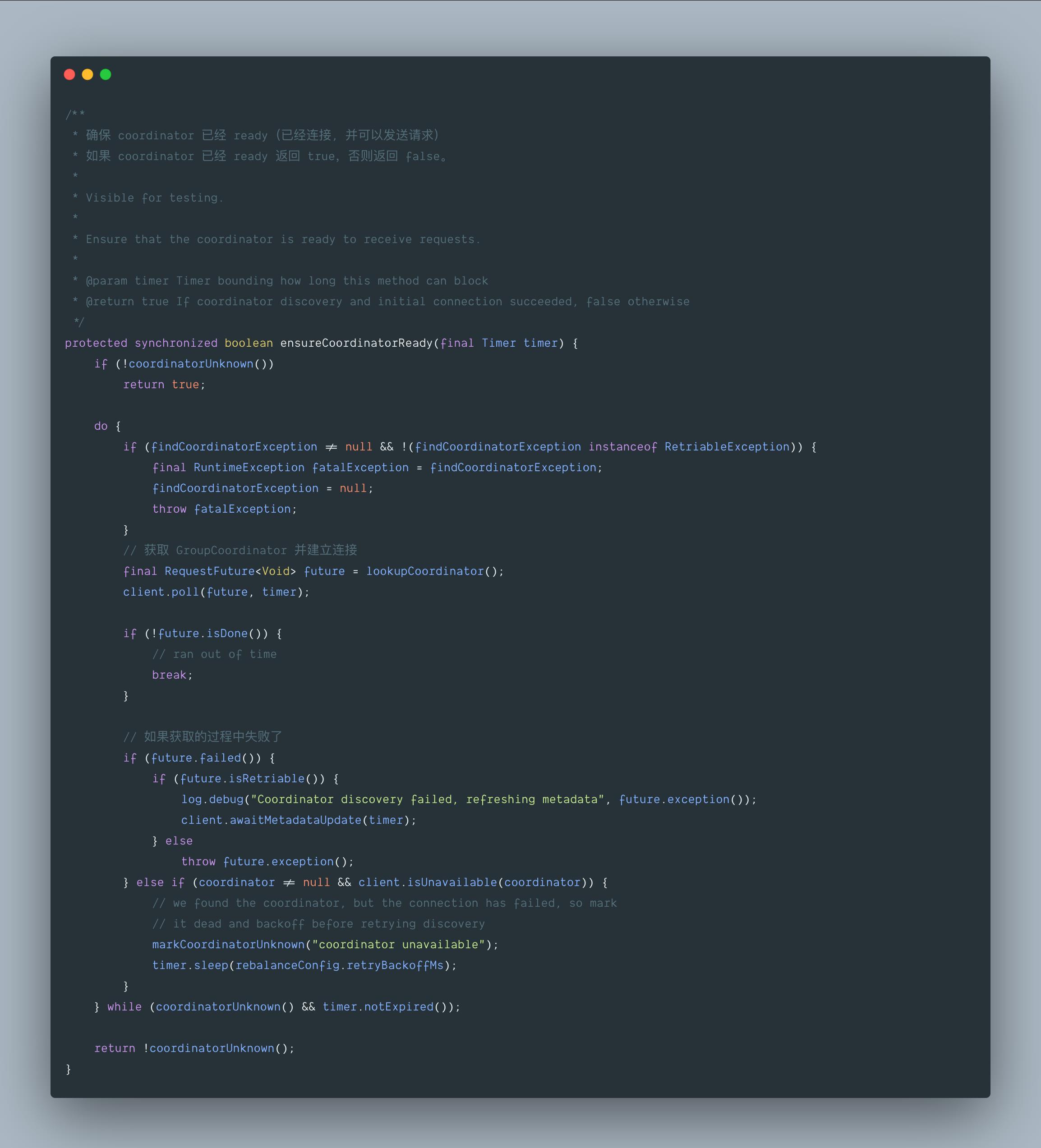
五、ensureCoordinatorReady()
这个方法的作用是:选择一个连接数最小的 broker,向其发送 GroupCoordinator 请求,并建立相应的 TCP 连接。
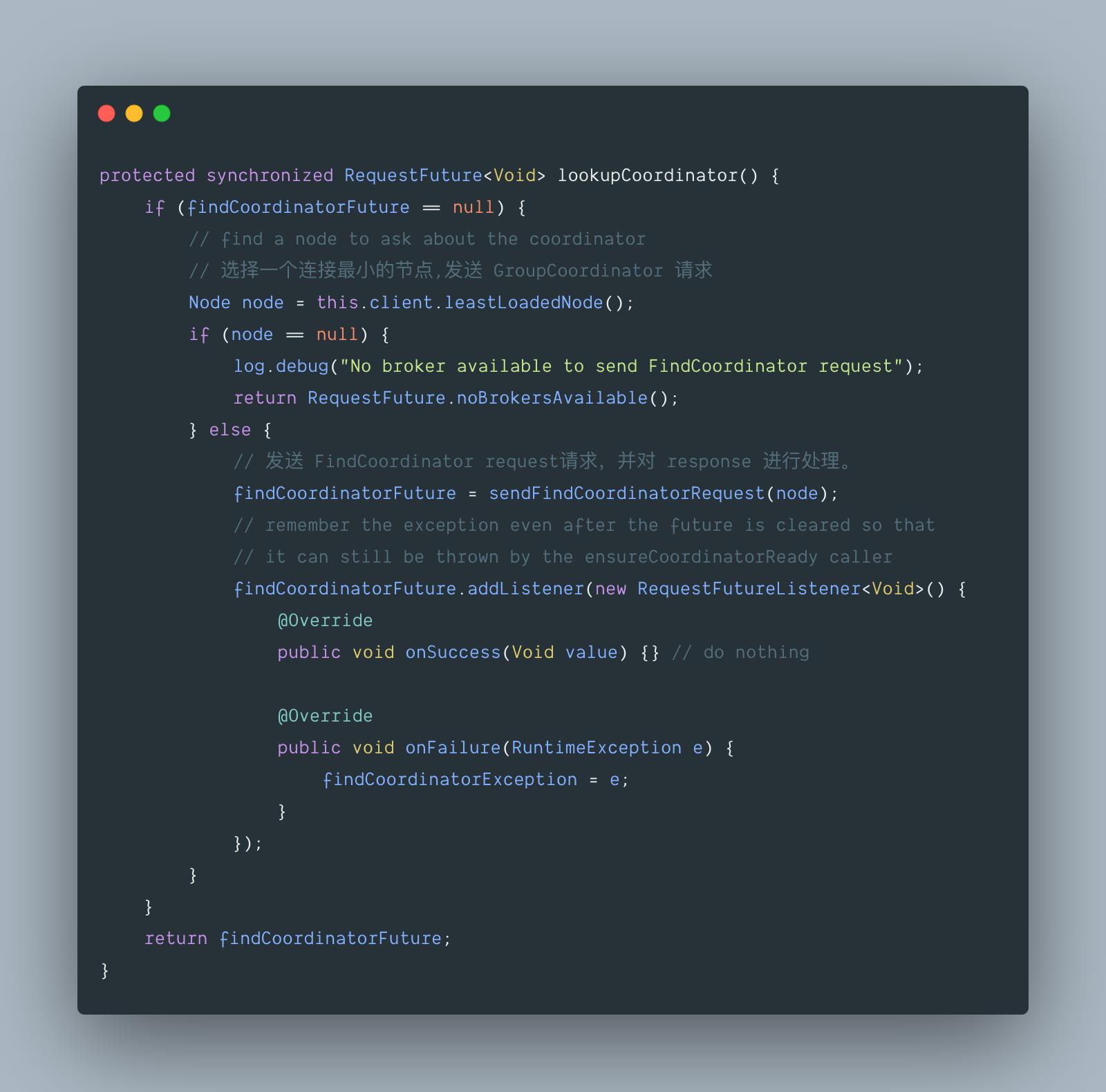
- 方法调用流程是:ensureCoordinatorReady() -> lookupCoordinator() -> sendFindCoordinatorRequest()。
- 如果 client 获取到 Server response,那么就会与 GroupCoordinator 建立连接。
5.1 org.apache.kafka.clients.consumer.internals.AbstractCoordinator#ensureCoordinatorReady
5.2 org.apache.kafka.clients.consumer.internals.AbstractCoordinator#lookupCoordinator
5.3 org.apache.kafka.clients.consumer.internals.AbstractCoordinator#sendFindCoordinatorRequest
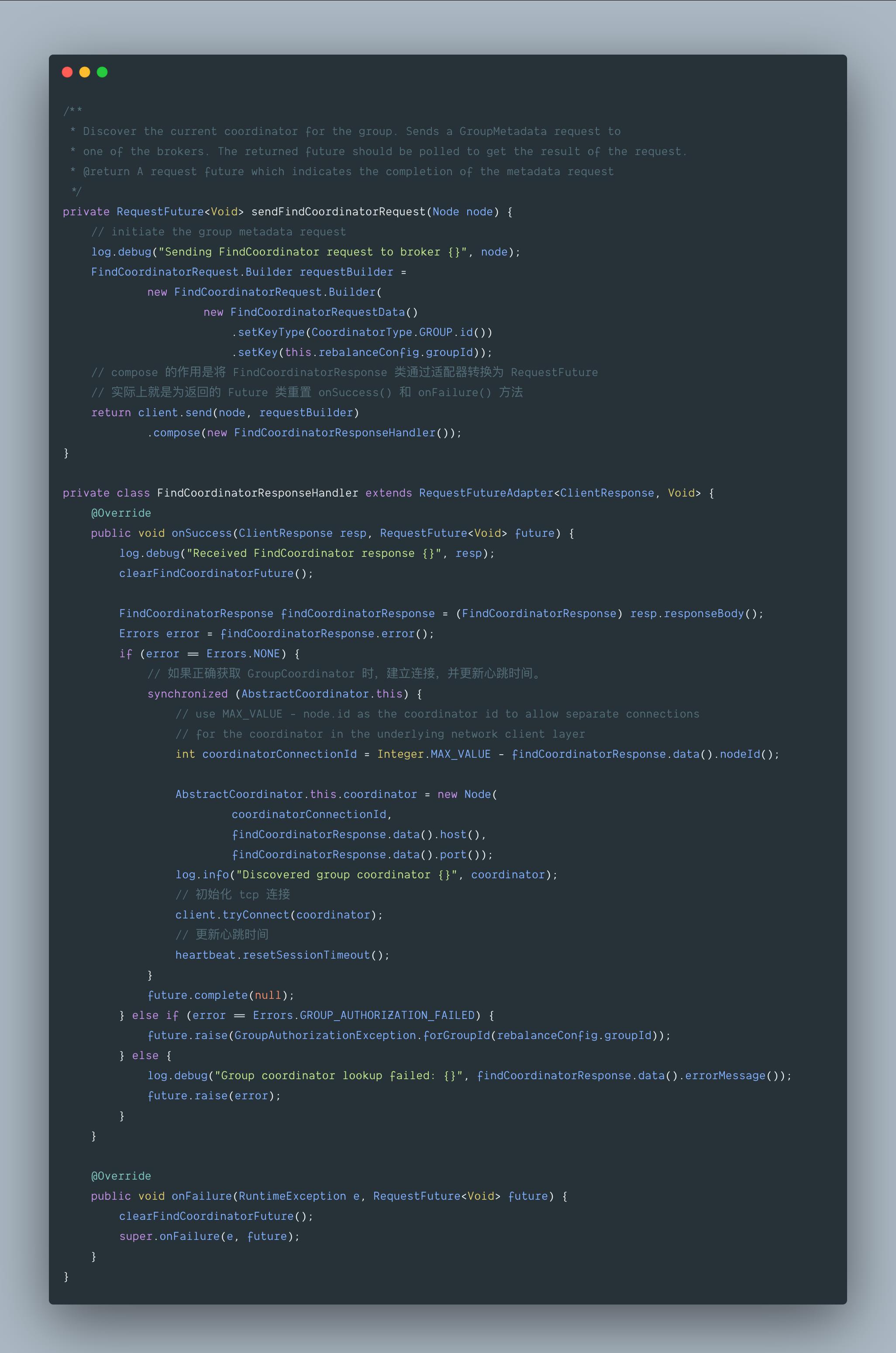
5.4 小结
- 选择一个连接最小的节点,发送 FindCoordinator request 请求,并对 response 进行处理。
- FindCoordinatorRequest 这个请求会使用 group id 通过 ConsumerNetworkClient.send() 来查找对应的 GroupCoordinator 节点。(当然 ConsumerNetworkClient.send() 也是采用的 Java NIO 的机制,我们前面的文章有说到过)
- 如果正确获取 GroupCoordinator 时(会返回其对应的 node id、host 和 port 信息),建立连接,并更新心跳时间。
六、rejoinNeededOrPending()
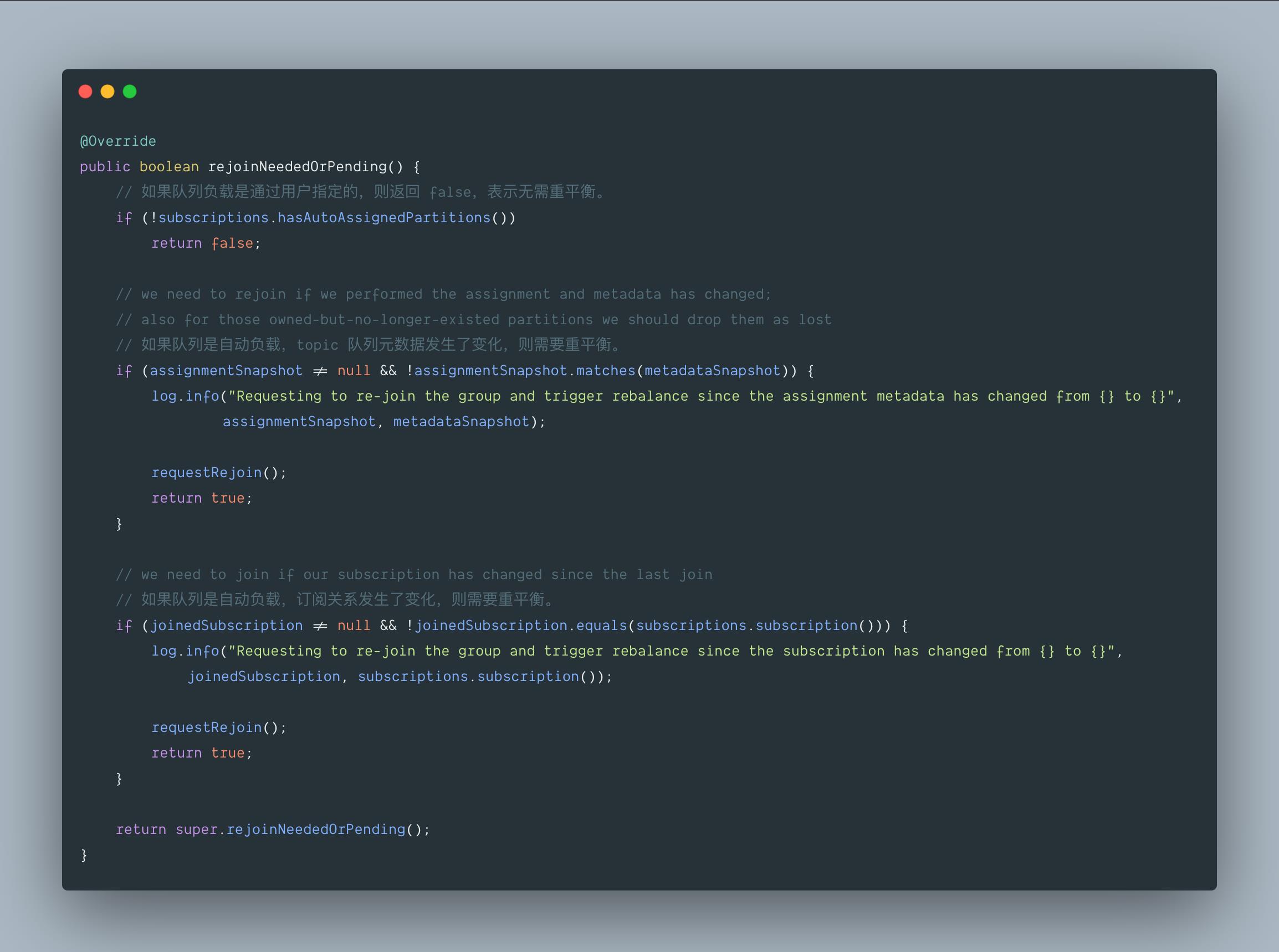
关于 rejoin, 下列几种情况会触发再均衡 reblance 操作
- 新的消费者加入消费组 (第一次进行消费也属于这种情况)
- 消费者宕机下线 (长时间未发送心跳包)
- 消费者主动退出消费组,比如调用 unsubscrible() 方法取消对主题的订阅
- 消费组对应的 GroupCoordinator 节点发生了变化
- 消费组内所订阅的任一主题或者主题的分区数量发生了变化
七、ensureActiveGroup()
现在我们已经知道了 GroupCoordinator 节点,并建立了连接。ensureActiveGroup() 这个方法的主要作用是向 GroupCoordinator 发送 join-group、sync-group 请求,获取 assign 的 TopicPartition list。
- 方法调用流程是:ensureActiveGroup() -> ensureCoordinatorReady() -> startHeartbeatThreadIfNeeded() -> joinGroupIfNeeded()
- joinGroupIfNeeded() 方法中最重要的方法是 initiateJoinGroup(),它的调用流程是 sendJoinGroupRequest() -> JoinGroupResponseHandler.handle() -> onJoinLeader()、onJoinFollower() -> sendSyncGroupRequest()
/**
* 确保 Group 是 active,并且加入该 group。
* Ensure the group is active (i.e., joined and synced)
*
* @param timer Timer bounding how long this method can block
* @throws KafkaException if the callback throws exception
* @return true iff the group is active
*/
boolean ensureActiveGroup(final Timer timer)
// always ensure that the coordinator is ready because we may have been disconnected
// when sending heartbeats and does not necessarily require us to rejoin the group.
// 确保 GroupCoordinator 已经连接
if (!ensureCoordinatorReady(timer))
return false;
// 启动心跳发送线程(并不一定发送心跳,满足条件后才会发送心跳)
startHeartbeatThreadIfNeeded();
// 发送 JoinGroup 请求,并对返回的信息进行处理。
return joinGroupIfNeeded(timer);
7.1 joinGroupIfNeeded()
join-group 的请求是在 joinGroupIfNeeded() 中实现的。
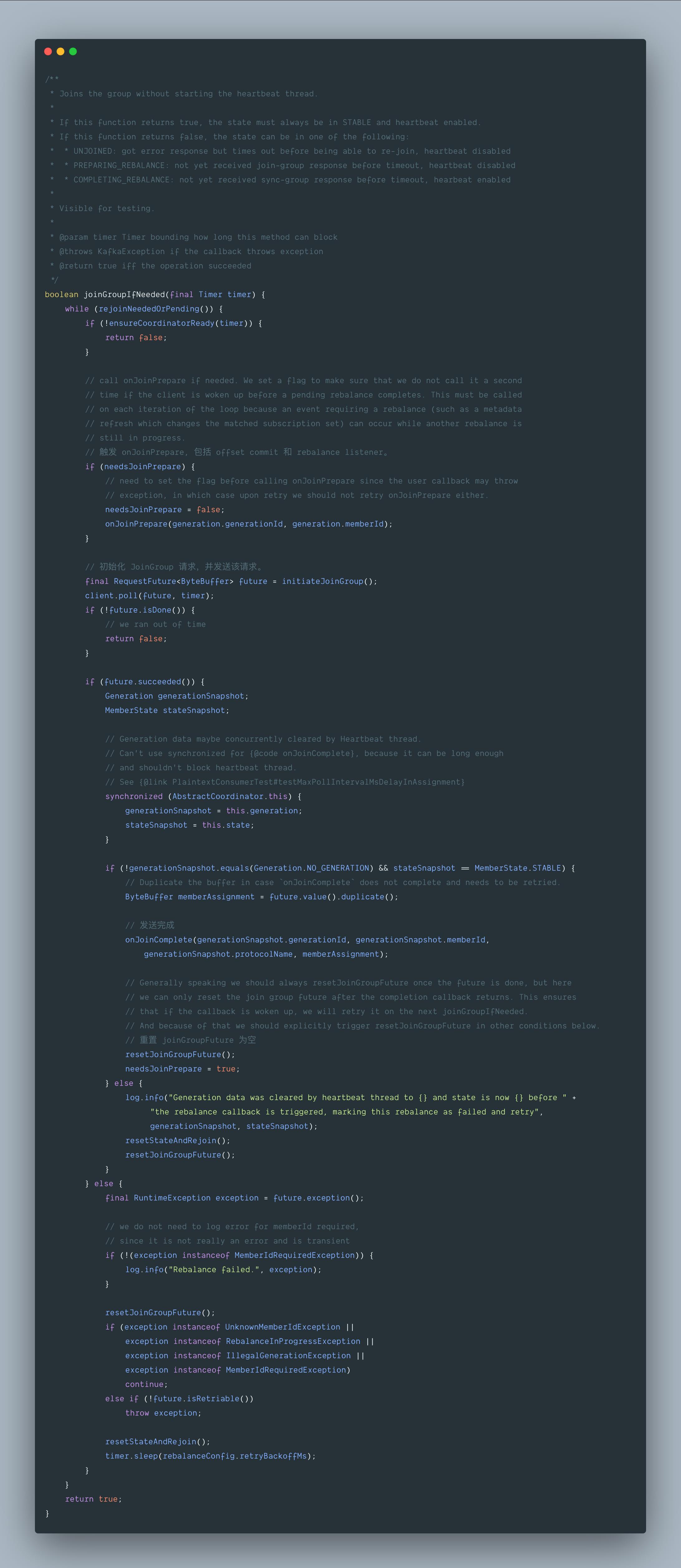
7.2 initiateJoinGroup()
joinGroupIfNeeded() 方法中最重要的方法是 initiateJoinGroup(),我们来看下:
private synchronized RequestFuture<ByteBuffer> initiateJoinGroup()
// we store the join future in case we are woken up by the user after beginning the
// rebalance in the call to poll below. This ensures that we do not mistakenly attempt
// to rejoin before the pending rebalance has completed.
if (joinFuture == null)
// 状态标记为 rebalance
state = MemberState.PREPARING_REBALANCE;
// a rebalance can be triggered consecutively if the previous one failed,
// in this case we would not update the start time.
if (lastRebalanceStartMs == -1L)
lastRebalanceStartMs = time.milliseconds();
// 发送 JoinGroup 请求
joinFuture = sendJoinGroupRequest();
joinFuture.addListener(new RequestFutureListener<ByteBuffer>()
@Override
public void onSuccess(ByteBuffer value)
// do nothing since all the handler logic are in SyncGroupResponseHandler already
@Override
public void onFailure(RuntimeException e)
// we handle failures below after the request finishes. if the join completes
// after having been woken up, the exception is ignored and we will rejoin;
// this can be triggered when either join or sync request failed
synchronized (AbstractCoordinator.this)
sensors.failedRebalanceSensor.record();
);
return joinFuture;
7.3 sendJoinGroupRequest() :join-group 请求
继续跟 sendJoinGroupRequest() 方法
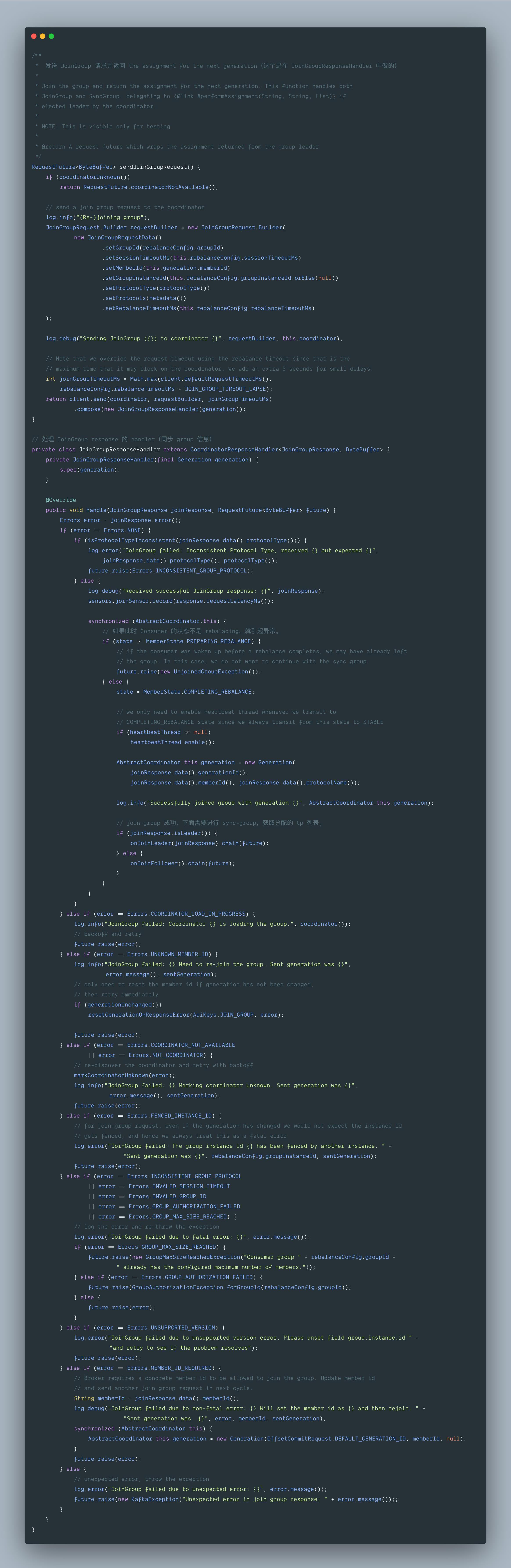
sendJoinGroupRequest():向 GroupCoordinator 发送 join-group 请求
- 如果 group 是新的 group.id,那么此时 group 初始化的状态为
Empty。 - 当 GroupCoordinator 接收到 consumer 的 join-group 请求后,由于此时这个 group 的 member 列表还是空(group 是新建的,每个 consumer 实例被称为这个 group 的一个 member),第一个加入的 member 将被选为 leader,也就是说,对于一个新的 consumer group 而言,当第一个 consumer 实例加入后将会被选为 leader。
- 如果 GroupCoordinator 接收到 leader 发送 join-group 请求,将会触发 rebalance,group 的状态变为
PreparingRebalance。 - 此时,GroupCoordinator 将会等待一定的时间,如果在一定时间内,接收到 join-group 请求的 consumer 将被认为是依然存活的,此时 group 会变为
AwaitSync状态,并且 GroupCoordinator 会向这个 group 的所有 member 返回其 response。 - consumer 在接收到 GroupCoordinator 的 response 后,如果这个 consumer 是 group 的 leader,那么这个 consumer 将会负责为整个 group assign partition 订阅安排(默认是按 range 的策略,目前也可选 RoundRobin),然后 leader 将分配后的信息以 sendSyncGroupRequest() 请求的方式发给 GroupCoordinator,而作为 follower 的 consumer 实例会发送一个空列表。
- GroupCoordinator 在接收到 leader 发来的请求后,会将 assign 的结果返回给所有已经发送 sync-group 请求的 consumer 实例,并且 group 的状态将会转变为
Stable,如果后续再收到 sync-group 请求,由于 group 的状态已经是 Stable,将会直接返回其分配结果。
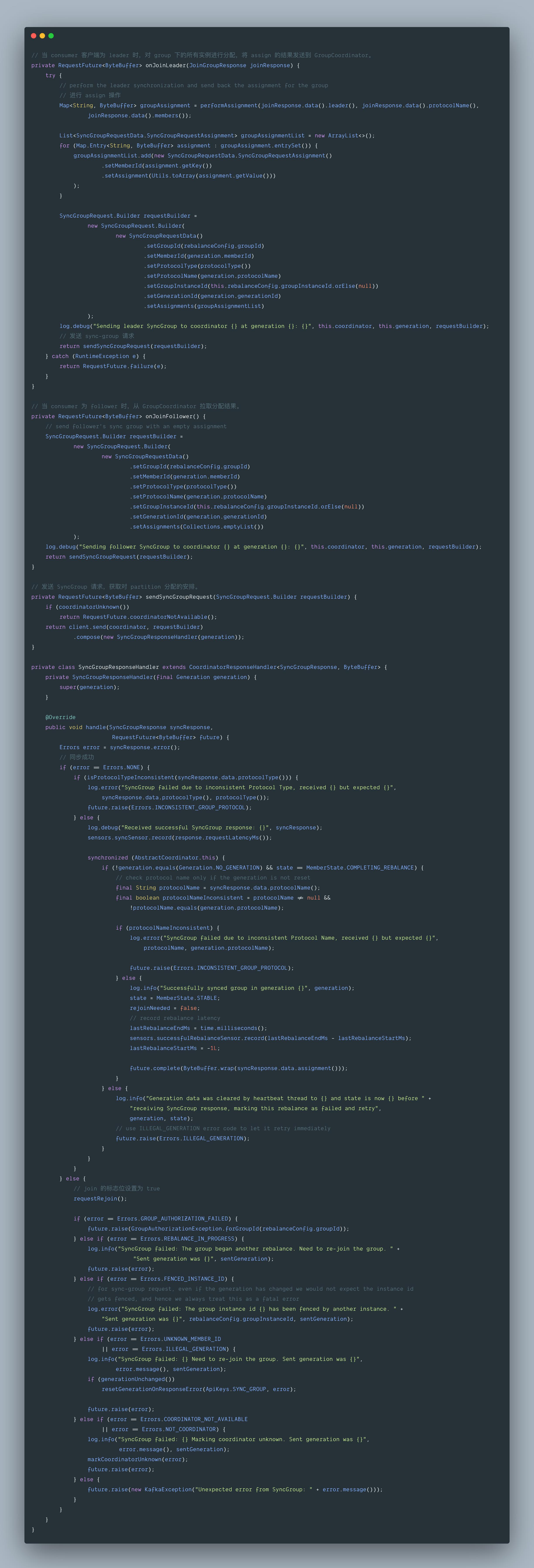
7.4 sendSyncGroupRequest() :sync-group 请求
sync-group 发送请求核心代码如下:
7.5 onJoinComplete()
经过上面的步骤,一个 consumer 实例就已经加入 group 成功了,加入 group 成功后,将会触发ConsumerCoordinator 的 onJoinComplete() 方法,其作用就是:更新订阅的 tp 列表以及更新其对应的 metadata。
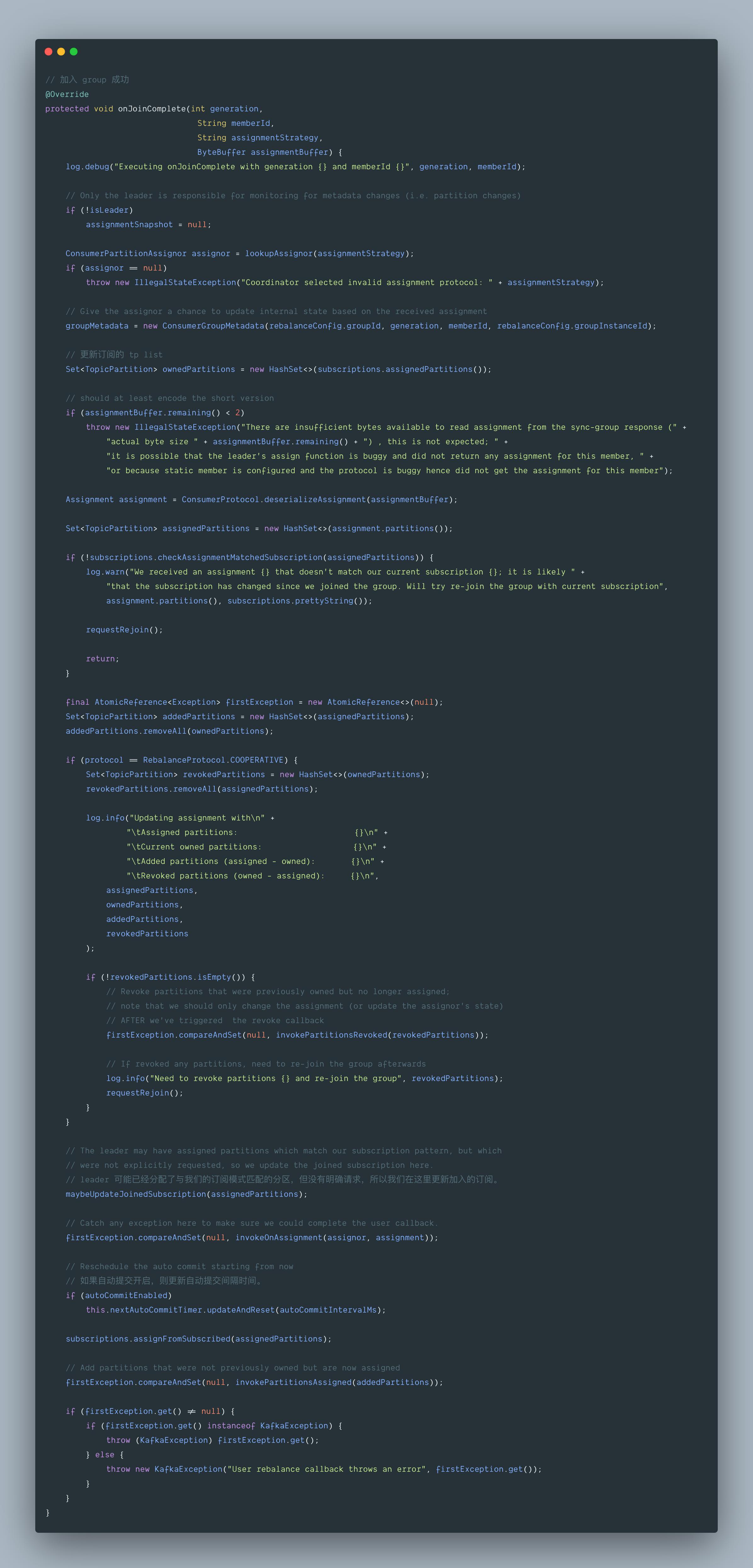
至此,一个 consumer 实例算是真正上意义上加入 group 成功。然后消费者就进入正常工作状态,同时消费者也通过向 GroupCoordinator 发送心跳来维持它们与消费者的从属关系以及它们对分区的所有权关系。只要以正常的间隔发送心跳,就被认为是活跃的,但是如果 GroupCoordinator 没有响应,那么就会发送 LeaveGroup 请求退出消费组。
以上是关于聊聊 Kafka: Consumer 源码解析之 Consumer 如何加入 Consumer Group的主要内容,如果未能解决你的问题,请参考以下文章
聊聊 Kafka: Consumer 源码解析之 Consumer 如何加入 Consumer Group
聊聊 Kafka: Consumer 源码解析之 Consumer 如何加入 Consumer Group
聊聊 Kafka: Consumer 源码解析之 Consumer 如何加入 Consumer Group
聊聊 Kafka: Consumer 源码解析之 Rebalance 机制