linux ls正则表达式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux ls正则表达式相关的知识,希望对你有一定的参考价值。
我有文件xxx,xxx1,xxx2, xxx3, 我怎么样才能 ls 出 xxx和xxx1来,ls xxx[1]? 这样不行啊。ls xxx[1]0,1也不行
ls就是默认排序的。
所以:
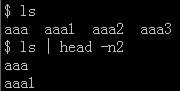
ls只支持通配符,不支持正则,所以单纯用ls是不能实现的。
一些正则过滤操作需要结合支持正则的命令如grep、sed或awk。
例如:ls | grep "[0-9]$"
得到:aaa1 aaa2 aaa3
参考技术A bash只有扩展,没正则这样操作的。摘录一点,你看看
奇特的用法
当场替换文件名的
$ mv thisisareallylongfilename,.txt
这个命令将把“thisisareallylongfilename”这个文件改名成“thisisareallylongfilename.txt”,这样就可以不用把这个长文件名打两遍了,虽然在shell中有tab按键可以自动填补文件名,这个小技巧看来不是很有用,但在shell脚本中还是非常有用的。
$ mv foo.jpeg,jpg
这个命令将把foo.jpeg改名为foo.jpg。
mv xxxyyy,wwwzzz.tt
扩展
其实,类似数组的扩展。
● echo /etc/init/avahi-daemon,lol,what.conf
/etc/init/avahi-daemon.conf /etc/init/avahi-lol.conf /etc/init/avahi-what.conf
● for i in a2,1..3,5; do echo $i; done
a2
a1
a2
a3
a5
Linux 正则表达式 grep
容易混淆的两个注意事项:
1)linux正则表达式一般是以行为单位处理的。
2)正则表达式和我们常用的通配符特殊字符是有本质区别的,例如:ls *.txt 这里的*就是通配符(表示所有),不是正则表达式。
注意字符集问题:
确保字符集:export LC_ALL=C
---------------------------------------------
基础正则表达式+扩展正则表达式含义解释:
---------------------------------------------
. 代表且只能代表任意一个字符(不包括空行)
* 重复前面任意0个或多个字符
.* 匹配所有字符。(包括空行)
sed -ri ‘s#(.*)#\1#g‘ bqh.txt
把前面正则匹配的括号内的结果,在后面用\1取出来操作。
^ 表示以什么开头,^bqh 以bqh开头
$ 是以什么结尾
^$ 表示空行。
\ 例\. 就只代表点本身,转义符号,让有着特殊身份移动的字符,脱掉马甲,还原原型\$
^.* 以任意多个字符开头。
.*$ 以任意多个字符结尾。
(.*) 从第一字符匹配,到空格停止,
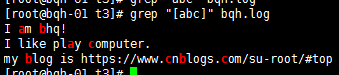
[abc] 匹配字符集合内的任意一个字符【a-zA-Z】
[^abc] 匹配不包括^后的任意字符的内容;中括号里的^为取反,注意和以...开头区别。
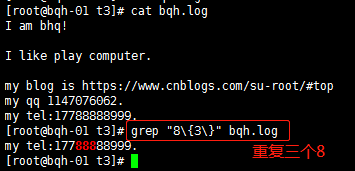
a\n,m\ 重复n到m次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\n,\ 重复至少n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\n\ 重复n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
①^word 搜索以word开头的;vi ^ 一行的开够
②word$ 搜索以word结尾的;vi $ 一行的开头
③^$ 表示空行。
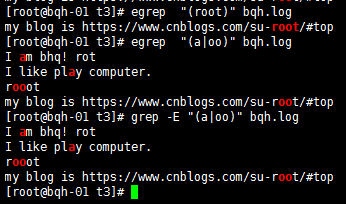
扩展的正则表达式:ERP(egrep或grep -E)
+ 重复一个或一个以上前面的字符
? 复0个或一个0前面的字符
| 用或的方式查找多个符合的字符串
() 找出“用户组”字符串
实战举例:
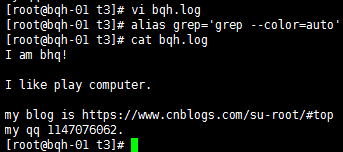
^m 搜索以m开头的

p$搜索以p结尾的

^$表示空号
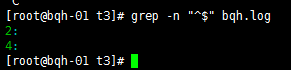
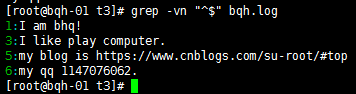
去掉空行:grep –v “^$” bqh.log
查看去掉的后的空行内容:grep -vn “^$” bqh.log
. 代表且只能代表任意一个字符(不包括空行)
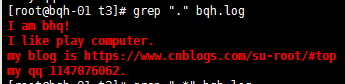
查找带0的字符:

.* 匹配所有字符。(包括空行)
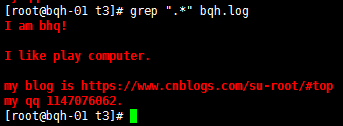
查找以.结尾的字符:
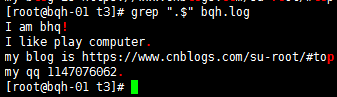
错误方法:grep ".$" bqh.log
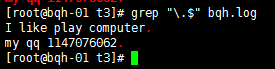
正确方法:
grep “\.$” bqh.log
注意:\. 就只代表点本身,转义符号,让有着特殊身份移动的字符,脱掉马甲,还原原型\$
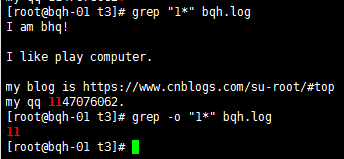
* 例1*重复1个或多个前面的一个字符。
grep –o “1*” bqh.log //-o精确匹配
^.* 以任意多个字符开头。

.*$ 以任意多个字符结尾。

[abc] 匹配字符集合内的任意一个字符【a-zA-Z】
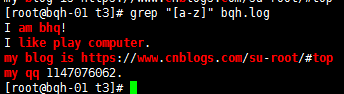
匹配字符集合内的a-z任意一个小写字符:
[^abc] 匹配不包括^后的任意字符的内容;中括号里的^为取反,注意和以...开头区别
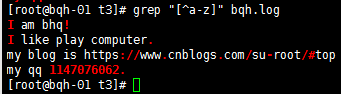
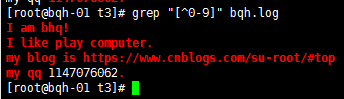
匹配非数字的任意字符:
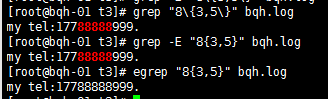
a\n,m\ 重复n到m次,前一个重复的字符。如果有用egrep/sed -r /grep -E可以去掉斜线。
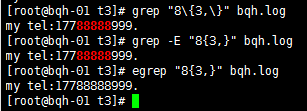
\n,\ 重复至少n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
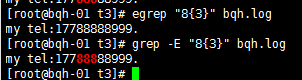
\n\ 重复n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
注意:egrep,grep -E或sed -r过滤一般特殊字符可以不转义。多使用参数。
---------------------------------------------------------------------------------
扩展的正则表达式:ERP(egrep或grep -E)
+ 重复一个或一个以上前面的字符
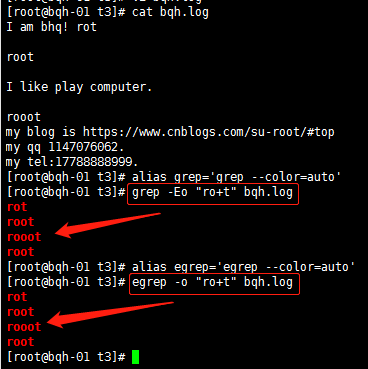
? 复0个或一个0前面的字符
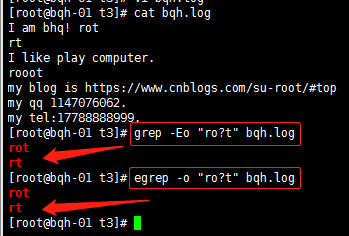
| 用或的方式查找多个符合的字符串
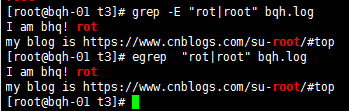
() 找出“用户组”字符串
以上是关于linux ls正则表达式的主要内容,如果未能解决你的问题,请参考以下文章