正则表达式
Posted burnovblog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式相关的知识,希望对你有一定的参考价值。
在Linux shell脚本中,使用sed gawk命令的关键就是自如的使用正则表达式;我们需要准确的匹配数据流量;
1、正则表达式是什么
1.1、正则表达式的定义
正则表达式,是我们在Linux系统下,过滤数据的模式模板。只有先匹配到流量或者数据,我们才能采用对应的操作;
在之前我们又通过文件统配符来列出问价的例子:ls -al da*
这则表达式和通配符工作方式相似,但是要比通配符复杂的多;
1.2、正则表达式的类型
不同的语言使用不同的正则表达式类型;不同类型我叫做不同模式的正则表达式,它是通过正则表达式引擎实现的。
正则表达式引擎分类:1、POSIX基本正则表达式(BRE)引擎;2、POSIX扩展正则表达式(BRE)引擎;
我们这里只讨论sed和gawk所能够支持的正则表达式;
2、定义BRE模式
基本的BRE模式是匹配数据流中文本字符。
2.1、纯文本
打印匹配上的文本
$ echo "This is a test" | sed -n ‘/test/p‘ This is a test $ echo "This is a test" | sed -n ‘/trial/p‘ $ $ echo "This is a test" | gawk ‘/test/{print $0}‘ This is a test $ echo "This is a test" | gawk ‘/trial/{print $0}‘ # $0表示整行内容 $
sed和gawk都区分大小写
$ echo "This is a test" | sed -n ‘/this/p‘ $ $ echo "This is a test" | sed -n ‘/This/p‘ This is a test $
不必局限于单词是否写全
$ echo "The books are expensive" | sed -n ‘/book/p‘ This books are expensive
空格字符也能识别
$ echo "This is line number 1" | sed -n ‘/ber 1/p‘ This is line number 1
2.2、特殊字符
有几个特殊的字符,用来匹配文本: . * [] ^ $ {} \\ + ? | ()
转义字符: \\ : 恢复原有字符的意思
sed -n ‘/\\$/p‘ data2 #恢复 $ 符号原有的意思
反斜杠对于反斜杠自己也要进行转意
echo "\\ is a special character" | sed -n ‘\\//\\p‘
虽让在正斜杠不是特殊字符,但是在sed和gawk中依然需要反斜杠转意
echo "3 / 2" | sed -n ‘/\\//p‘
2.3、定位符
1、从头开始
托字符 ^ 定义文本开头内容
echo "This book store" | sed -n ‘/^book/p‘
echo "Books are great" | sed -n ‘/^Books/p
托字符由换行符决定,且区分大小写的;
如果托字符,不放在文本开始位置,那就是普通字符,不再充当特殊字符;
echo "This ^ is a test" | sed -n ‘/s ^/p‘
2、查找结尾
$ 符定义结尾
echo "This is a good book" | sed -n ‘/book$/p‘
3、联合定位
以this is a test开头,同时以this is a tes结尾
$ sed -n ‘/^this is a test$/p‘ data4 this is a test
第二种情况 ^$ 可以表示空白行;
2.4、点字符
点字符(.) 用于匹配除了换行符之外的任意单个字符;
$ sed -n ‘/.at/p‘ data6 The cat is sleeping.
2.5、字符类
[] 中括号指定一类字符,例如 [abc] 配置abc中任意一个字符;
$ sed -n ‘/[ch]at/p‘ data6 The cat is sleeping. That is a very nice hat.
只有 at 前面没有 c或者h 上面的字符串也是无法匹配到的;
常用方式:
$ echo "Yes" | sed -n ‘/[Yy][Ee][Ss]/p‘
$ echo "yEs" | sed -n ‘/[Yy][Ee][Ss]/p
匹配邮政编码数字
$ sed -n ‘ > /^[0123456789][0123456789][0123456789][0123456789][0123456789]$/p > ‘ data8 #匹配了只有五位的任意数字串
接收常见的错误单词拼写
$ sed -n ‘ > /maint[ea]n[ae]nce/p > /sep[ea]r[ea]te/p > ‘ data9
2.6、否定字符类
在范围内使用托字符,表示否定,例如: [^ch] 出去ch外的所有字符
$ sed -n ‘/[^ch]at/p‘ data6
2.7、使用范围
短划线符号可以表示在字符中使用一些列字符范围。[0-9]:表示 0123456789中的任意数字;
$ sed -n ‘/^[0-9][0-9][0-9][0-9][0-9]$/p‘ data8
同样的方式也适用于字母
$ sed -n ‘/[a-ch-m]at/p‘ data6 #从a到c,从h到m,之间的匹配字符串 abc higklm 这两组字符串的组合;
2.8、特殊字符类
BRE包含一些特殊字符:

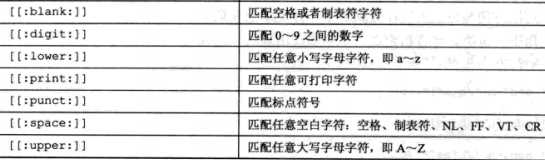
这些特殊字符,直接使用即可;
2.9、星号
星号(*),表示星号前一个字符出现多次 i*:表示iiiii...出现零次多次;

也可以指定任意组合出现多吃

3、扩展的正则表达式
gawk比sed更加灵活,它能够识别ERE模式的正则表达式,也就是扩展的正则表达式;
3.1、问号
? 表示前面的字符出现零次或一次。但是 * 号表示零次或多次;
$ echo "bt" | gawk ‘/be?t/{print $0}‘ bt $ echo "beet" | gawk ‘/be?t/{print $0}‘ $
? 也可以和字符串连用
$ echo "bt" | gwak ‘/b[ae]?t/{print $0}‘
"bot" "bat" "bet" "beat" "beet" "baet"
3.2、加号
+ 与 ? 正好相反,表示前面的字符出现一次和多次;
$ echo "beeet" | gawk ‘/be+t/{print $0}‘
"beet" "bet" "bt"
也可以与字符串连用
$ echo "bt" | gawk ‘/b[ea]+t/{print $0}‘
"bat" "bet" "beat" "beeeat"
3.3、使用大括号
指定可重复的次数{m}:正好出现m次;{m,n}:最少出现m此,最多出现n次;
$ echo "bet" | gawk --re-interval ‘/be{1}t/{print $0}‘
"bt" "beet"
字符出现的范围
$ echo "bt" | gawk --re-interval ‘/be{1,2}t/{print $0}‘
"bet" "beet" "beeet"
也可以结合字符串来实现匹配
$ echo "bt" | gawk --re-interval ‘/b[ea]{1,2}t/{print $0}‘ #e和a出现的总次数不能多于两次
"bt" "bat" "bet" "beat" "beet" "beeat" "baeet" "beaaet"
3.4、管道符号
这里的管道符表示或者OR
$ echo "This cat is asleep" | gawk ‘/cat|dog/{print $0}‘
$ echo "He has a hat." | gawk ‘/[ch]at|dog/{print $0}‘
3.5、将表达式分组
圆括号,可以将正则表示是进行分组;一个括号内的字符串,作为一个字符进行处理;
$ echo "Saturday" | gawk ‘/Sat(urday)?/{print $0}‘ Saturday
分组可以结合管道符使用
$ echo "cat" | gawk ‘/(a|b)a(b|t)/{print $0}‘
4、正则表达式实战
4.1、计算目录文件
统计PATH环境变量中的可执行文件数量。
#!/bin/bash # count number of files in your PATH mypath=`echo $PATH | sed ‘s/:/ /g‘` count=0 for directory in $mypath do check=`ls $directory` for item in $check do count=$[ $count + 1 ] done echo "$directory - $count" count=0 done
4.2、验证电话号码
常见电话号码类型:(123)456-7890 (123) 456-7890 123-456-7890 123.456.7890
^\\(? 括号可能有,也可能没有
[2-9][0-9]{2} 美国点好以2开头,只要指定后面的电话就可以了
\\)? 反括号,有可能有,也可能没有
(| |-|\\.) 指定这个位置,可能是没有字符,也可能是空格,也可能是 - ,也可能是 .
[0-9]{3} 3为0-9任意字符
( |-|\\.) 指定空格,-,. 中的任意一个字符
[0-9]{4}$ 以四组任意数字结尾;
记住:在gawk程序中使用正则表达式间隔时,必须使用--re-interval命令行选项。
#!/bin/bash # script to filter out bad phone numbers gawk --re-interval ‘/^\\(?[2-9][0-9]{2}\\)?(| |-|\\.)[0-9]{3}( |-|\\.)[0-9]{4}/{print $0}‘
cat phonelist | ./isphone #过滤掉phonelist文件中的非电话号码
4.3、解析电子邮件地址
username:包括圆点,短划线,加好,下划线
hostname:包括圆点,下划线
^([a-zA-Z0-9_\\-\\.\\+]+)@ #用户名
([a-zA-Z0-9_\\-\\.]+) #这个模式可以匹配的文本,server或者server.subdomain或者server.subdomain.subdomain
\\.([a-zA-Z]{2,5})$ #顶级域名的表达方式
组合起来
^([a-zA-Z0-9_\\-\\.\\+]+)@([a-zA-Z0-9_\\-\\.]+)\\.([a-zA-Z]{2,5})$
$ echo "rich$here.now" | ./isemail
以上是关于正则表达式的主要内容,如果未能解决你的问题,请参考以下文章