RISC-V指令集架构特点及其总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RISC-V指令集架构特点及其总结相关的知识,希望对你有一定的参考价值。
参考技术A 本文章对E203开源核的Decode模块进行总结。六种基本指令格式,分别是:
RISC-V的指令有几个有点:
蜂鸟E203内核解析Chap.1 RISC-V指令集架构与硬件结构
【蜂鸟E203内核解析】Chap.1 RISC-V指令集架构与硬件结构
前言:本文均为作者原创,内容均来自本人的毕业设计。 未经授权严禁转载、使用。里面的插图和表格均为作者本人制作,如需转载请联系我并标注引用参考。分享仅供大家学习和交流。
1. 指令集架构
处理器(Central Processing Uni,简称CPU)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。其组成分为软件、指令集、硬件这三个层面,如图2-1所示。其中,软件层面包括了运行于处理器上的操作系统、各种软件应用还有可以把高级语言的代码转换成底层硬件所认识的低级语言的程序编译器等。
指令集层面作为运行于底层硬件与软件之间的桥梁和规范的出入口,指令集架构(Instruction Set Architecture,简称ISA)的指令决定了处理器的主要功能。处理器的具体底层硬件实现策略被称为处理器的微架构(Micro-Architecture),是通过底层硬件电路的设计来实现指令在处理器内部的执行过程。

处理器的实际设计VLSI(Very Large Scale Integration Circuit,超大规模集成电路)会包含数百万级别的晶体管数量,其规模与指令集层面的指令集架构息息相关,指令集架构越复杂,实际处理器的VLSI设计的功耗、主频和面积会受到限制[8]。指令集架构可分为CISC(Complex Instruction Set Computer,复杂指令集计算机)和RISC(Reduced Instruction Set Computer,精简指令集计算机)[9],如表2-1所示。
| 架构 | X86或ARM等CISC架构 | RISC-V架构 |
|---|---|---|
| 指令系统 | 指令系统规模大 | 指令系统简洁 |
| 寄存器 | 专用的寄存器 | 通用的寄存器 |
| 指令字长 | 不固定 | 固定 |
| 可扩展性 | 不支持 | 预留子码空间,支持可扩展定制指令 |
| 电路 | 面积大、功耗高 | 面积小、功耗低 |
其中RISC架构的处理器只包含了最基本的常用指令,而相对复杂的指令则通过执行多条常用指令的方式来实现。RISC-V是第五代精简指令集计算机,指令集更加精简和规整,RISC-V比x86和ARM架构具有极大的优势。
1.1 RISC-V指令集架构
RISC-V 指令集可分为基础指令集和扩展指令集,如表2.2所示,基础指令集均为整数指令,根据处理器寻址的空间大小可划分为RV32I、RV32E(是RV32I的子集,但只有16个寄存器组)、RV64I、RV128I,在RISC-V 架构中要求设计的处理器必须实现基本(整数)指令集。扩展指令集的作用是可以更加灵活地针对不同的应用场景能够自定义符合RISC-V架构规定的RISC-V指令,B、P和V需根据用户的实际需求来自定义设计。
RISC的主要核心理念是包含全部常用的指令,而对于不常用的指令操作,则通过重复执行多条常用指令的方式来达到“重复回样”的效果。本设计的内核采用RV32I指令子集的RISC-V指令集架构,共47条指令[10],见3.2.1章节详述。其它的指令集扩展可以仅通过RV32I来模拟(RV32A扩展除外,因为向量操作的原子性需要定制的硬件支持)。
| RISC-V指令集 | 指令集名称 | 指令数 | 寻址空间(位) | 寄存器组(位) |
|---|---|---|---|---|
| 基本指令集 (均为整数指令集) | RV32I | 47 | 32 | 32 |
| RV32E | 47 | 32 | 16 | |
| RV64I | 59 | 64 | 32 | |
| RV128I | 71 | 128 | 32 | |
| 扩展指令集 | 指令集名称 | 指令数 | 指令集描述 | |
| M | 8 | 乘法、除法运算 | ||
| A | 11 | 原子与加载、存储 | ||
| F | 26 | 单精度浮点运算 | ||
| D | 26 | 双精度浮点运算 | ||
| Q | 26 | 四精度浮点运算 | ||
| C | 46 | 压缩 | ||
| B | 自定义完成 | 位操作 | ||
| P | 自定义完成 | Packed-SIMD | ||
| V | 自定义完成 | 向量操作 | ||
1.2 指令类型与编码
在流水线中希望能够快速地读写与访问通用寄存器组,有助于提高处理器系统的局部性能和进一步优化系统整体时序。RISC-V之前的所有RISC指令集架构版本在迭代升级的过程中不断添加完善指令集中的指令,其指令编码格式在修改后显得更加不规整,给流水线的译码阶段索引通用寄存器造成了不小的困难。而升级后的RISC-V的指令类型和编码十分有序规整,如图2-2所示。

RV32I包括了4种基本指令格式,分别是:R型指令、I型指令、S型指令、U型指令。R型指令用于两个寄存器间的操作;I型指令和S型指令都操作内存空间,I型指令用于加载内存提取的操作,S型指令用于访问内存后的存储操作,除此之外,I型指令还包括对短立即数的操作;U型指令用于长立即数的操作[10]。
每一种类型的指令所操作的通用寄存器的索引都被放在固定的指令段位置,操作码opcode也放置在固定的[6:0]位置有利于译码处理[6]。因此译码器可以非常便捷地译码。
2. 硬件结构
2.1基础寄存器
RV32I 基本寄存器里规定每一个基本整数寄存器都占用32位的空间,RV32I 共有32个基础寄存器[10],由32个用于保存整数值的通用寄存器x1-x31和1个固定的寄存器x0组成,如图2-3所示。

其中,x1-x31用于保存整数值的通用寄存器组成,x0用于固定连接到常数0。再加一个程序计数器的pc寄存器,它用于保存当前正在运行的指令的地址以供用户使用的模式下操作处理器程序使用。
这些寄存器的宽度由使用的RISC-V所实现功能的基变量定义。如果可以实现浮点运算指令子集(RV32F或者RV32D),则需要添加一组专用的浮点寄存器组,总共需要32个通用浮点寄存器。其中RV32F浮点指令子集的每个通用浮点寄存器的宽度为32 bit;RV32D浮点指令子集的每个通用浮点寄存器的宽度为64 bit。
2.2 流水线技术
流水线技术(pipeline)是可以实现多条指令重叠被执行的一种准并行处理实现的技术,目的是为了提高整体处理器的性能及系统时钟频率,形式上很像电子厂的厂房中的生产流水线[6]。流水线技术实现了在一个时钟周期内把对几条指令的操作可以并行重复运行,从而提高了整体系统的效率。
在处理器架构中,流水线设计本质上可以理解为是一种以面积换性能,以空间换时间的设计方法。流水线设计的层次越多越深,意味着指令运行过程部分功能的逐渐解耦,使得每一级流水线中的逻辑数量越少,进一步可以使得处理器整体性能可以运行到更高的主频,从而在流水线设计上提高数据的吞吐率。应用最广泛、最经典的是MIPS五级流水线共包含取值、译码、执行、访存、写回共五个阶段[6],如图2-4所示。

在嵌入式低功耗处理器领域,随着现代低功耗处理器需求的发展,为了微处理器的应用能够追求更高能效比,会适当将流水线的设计变浅,以追求更高的能效比。其中具有代表性的是ARM的Cortex M0+采用了两级流水线结构。无独有偶芯来科技的蜂鸟E203也采用了两级流水线[7],第一阶段包括取值和一个简单译码模块,第二阶段包括译码、执行。需要回写的时候会加上写回阶段,写回结果需要通过写回模块回到指定的通用寄存器组,故称E203内核是2级变长流水线,如图2-5所示。

2.3 片内存储器
处理器的片内存储器子系统至少需要实现两个功能:存放指令和存放数据。片内处理器内部的存储器一般有两种:Cache(高速缓冲存储器)和TCM(Tightly Coupled Memory,紧耦合式存储器)[6]。Cache将容量庞大的存储器映射到容量有限的Cache中,所以访问Cache有可能会导致Cache-Miss,很难有确定的访问使得Cache的执行时间不可预测。而TCM并不是Cache缓存机制弥补了Cache的缺点,有着低延迟的特性,主要用于存储极需要稳定性的任务程序。而且,TCM也可以暂存一小部分寄存器数据。根据存储的类型可将TCM分为ITCM(Instruction TCM,指令紧耦合指令内存存储器)和DTCM(Data TCM,数据紧耦合数据内存存储器)。
32位处理器主要应用于AIoT领域,一般要求低功耗低延迟,所以所实现的功能的软件代码规模不大,所需要处理的数据一般在几十kb左右,且追求小面积和能效比。所以不需要Cache,把指令、数据存放在TCM的存储器中。由于需要经常操作提取指令,所以存储指令需要放置在高速的数据缓冲存储器即可。存储数据最基本的需要满足处理器的基本计算需求,也就是需要数据暂存区,所以处理器最基本的存储数据的需求也是对访存速度有极高要求,所以处理器内部有独立的存储数据高速缓冲存储器。
2.4 片内总线
片内总线(Bus)是整个处理器内部和各功能模块间能够进行良好的数据交互的保障,内存与处理器之间或外围配件与内存之间采用统一的总线协议,也可以同时有多种片上总线互联方式,通过挂载功能模块到片上总线就能实现相互通信,本设计的片内总线采用ICB(Internal Chip Bus)总线协议,有32条数据线,32条地址线,32条控制线[13]。ICB总线既保留了速度快的优势和且相比于其他总线协议更加简单,总线协议主接口与从接口之间仅有两条通道:只发送请求的命令通道和反馈读取结果的返回通道,ICB总线结构如图2-6所示。

ICB总线具备以下特点:
- 地址由命令通道单独传输,所写数据由命令通道跟着写请求一齐传输到从设备,所读数据由返回通道传输。
- 为了实现多个主从设备都可以挂载到ICB总线上,使用地址自定义区间寻址。
- 命令通道传输字节掩码来防止符号扩展,用于实现自定义控制的写操作。
- 不但支持自然对齐地址的访问,也支持地址非对齐的访问。
- 不支持乱序的形式,只支持顺序从返回通道返回结果。
ICB总线上两个通道的信号如表2-3所示:
| RISC-V指令集 | 指令集名称 | 指令数 | 寻址空间(位) | 寄存器组(位) |
|---|---|---|---|---|
| 基本指令集 (均为整数指令集) | RV32I | 47 | 32 | 32 |
| RV32E | 47 | 32 | 16 | |
| RV64I | 59 | 64 | 32 | |
| RV128I | 71 | 128 | 32 | |
| 扩展指令集 | 指令集名称 | 指令数 | 指令集描述 | |
| M | 8 | 乘法、除法运算 | ||
| A | 11 | 原子与加载、存储 | ||
| F | 26 | 单精度浮点运算 | ||
| D | 26 | 双精度浮点运算 | ||
| Q | 26 | 四精度浮点运算 | ||
| C | 46 | 压缩 | ||
| B | 自定义完成 | 位操作 | ||
| P | 自定义完成 | Packed-SIMD | ||
| V | 自定义完成 | 向量操作 | ||
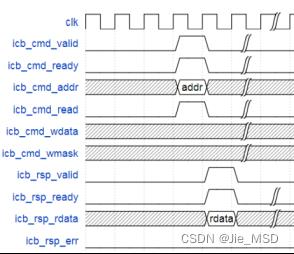
ICB的读写控制遵循valid-ready握手原则,准备好再进行下一步传输,没准备好就停下来等待,可以有效地实现读写时序控制,ICB总线上的读写时序如图2-7所示。
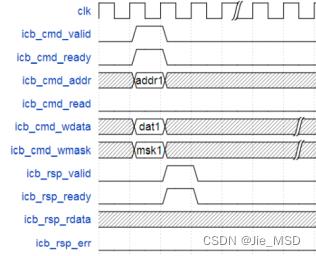
通过ICB总线写数据时,主设备将数据准备好后,将读写请求信号icb_cmd_valid拉高,同时,如果从设备不忙,则标志信号icb_cmd_ready一直拉高。在时钟沿同时出现valid和ready拉高,则从设备发送写地址、写数据、写的字节掩码。
通过ICB总线读数据时,主设备将读写请求信号icb_cmd_valid拉高,同时,如果从设备不忙,则将标志信号icb_cmd_ready一直拉高,此时读标志icb_cmd_read拉高。在时钟沿同时出现valid和ready拉高,则通过反馈通道实现读取数据。
2.5 总线接口
总线接口由BIU实现,其连接如图2-8所示。用于实现流水线中各个单元模块的存储器访问请求,遵循ICB总线协议。取指令单元IFU需要提取ITCM内存中的指令,内存访问单元LSU需要访问内存,这两个单元模块需要遵循ICB总线协议分别输入到BIU进行优先级仲裁选择,规定了LSU单元有更高的优先权。
因为IFU是流水线的第一级,往往代表着下一个周期,为了保证流水线按序工作,需要先执行上一个周期还没执行完的操作,故LSU单元相比于IFU单元拥有更高的优先权。LSU还有可能会接收到协处理器的访存请求,所以需要与主处理器的访存请求做进行一步的选择。之后LSU提取到指令后需要进行数据对齐,需要返回的指令数据会通过WB单元写回到通用寄存器组。

BIU内部采取了乒乓缓存(Ping-Pong Buffer,简称PPB)用于替换掉一般的一层流水,可以使得此级流水线向上一级流水线的握手接收信号仅关注乒乓缓存中是否有一个以上有空的表项即可,而无需将下级的握手接收信号串扰至上一级。在判断其访问的地址区间后,通过不同的接口访问外部的模块单元,包括私有外设、CLINT、快速IO、系统存储、PLIC。
后记
本文均为作者原创,内容均来自本人的毕业设计。未经授权严禁转载、使用。里面的插图和表格均为作者本人制作,如需转载请联系我并标注引用参考。分享仅供大家学习和交流。
- markdown语法转成表格,很好用
https://www.tablesgenerator.com/html_tables
https://blog.csdn.net/qq_30797051/article/details/119642901
以上是关于RISC-V指令集架构特点及其总结的主要内容,如果未能解决你的问题,请参考以下文章