为啥HikariCP被号称为性能最好的Java数据库连接池,如何配置使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为啥HikariCP被号称为性能最好的Java数据库连接池,如何配置使用相关的知识,希望对你有一定的参考价值。
HiKariCP是数据库连接池的一个后起之秀,号称性能最好,可以完美地PK掉其他连接池。为何要使用HiKariCP?这要先从BoneCP说起:
什么?不是有C3P0/DBCP这些成熟的数据库连接池吗?一直用的好好的,为什么又搞出一个BoneCP来?因为,传说中BoneCP在快速这个特点上做到了极致,官方数据是C3P0等的25倍左右。不相信?其实我也不怎么信。可是,有图有真相啊(图片来自BoneCP官网:http://jolbox.com/benchmarks.html):
而且,网上对于BoneCP是好评如潮啊,推荐的文章一搜一大堆。
然而,上Maven Repository网站(http://mvnrepository.com/artifact/com.jolbox/bonecp)查找有没有最新版本的时候,你会发现最新的是2013年10月份的(这么久没新版本出来了?)。于是,再去BoneCP的Githut(https://github.com/wwadge/bonecp)上看看最近有没有提交代码。却发现,BoneCP的作者对于这个项目貌似已经心灰意冷,说是要让步给HikariCP了(有图有真相):
……什么?又来一个CP?……什么是Hikari?
Hikari来自日文,是“光”(阳光的光,不是光秃秃的光)的意思。作者估计是为了借助这个词来暗示这个CP速度飞快。不知作者是不是日本人,不过日本也有很多优秀的码农,听说比特币据说日本人搞出来的。。。
这个产品的口号是“快速、简单、可靠”。实际情况跟这个口号真的匹配吗?又是有图有真相(Benchmarks又来了):
这个图,也间接地、再一次地证明了boneCP比c3p0强大很多,当然,跟“光”比起来,又弱了不少啊。
那么,这么好的P是怎么做到的呢?官网详细地说明了HikariCP所做的一些优化,总结如下:
字节码精简:优化代码,直到编译后的字节码最少,这样,CPU缓存可以加载更多的程序代码;
优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;
自定义数组类型(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;
自定义集合类型(ConcurrentBag):提高并发读写的效率;
其他针对BoneCP缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究(但没说具体怎么优化)。
很多优化的对比都是针对BoneCP的……哈哈。
(参考文章:https://github.com/brettwooldridge/HikariCP/wiki/Down-the-Rabbit-Hole)
几个连接池的代码量对比(代码量越少,一般意味着执行效率越高、发生bug的可能性越低):
可是,“黄婆卖瓜,自催自擂”这个俗语日本人也是懂得,于是,用户的好评如潮也是有图有真相:
还有第三方关于速度的测试:
也许你会说,速度高,如果不稳定也是硬伤啊。于是,关于稳定性的图也来了:
另外,关于可靠性方面,也是有实验和数据支持的。对于数据库连接中断的情况,通过测试getConnection(),各种CP的不相同处理方法如下:
(所有CP都配置了跟connectionTimeout类似的参数为5秒钟)
HikariCP:等待5秒钟后,如果连接还是没有恢复,则抛出一个SQLExceptions 异常;后续的getConnection()也是一样处理;
C3P0:完全没有反应,没有提示,也不会在“CheckoutTimeout”配置的时长超时后有任何通知给调用者;然后等待2分钟后终于醒来了,返回一个error;
Tomcat:返回一个connection,然后……调用者如果利用这个无效的connection执行SQL语句……结果可想而知;大约55秒之后终于醒来了,这时候的getConnection()终于可以返回一个error,但没有等待参数配置的5秒钟,而是立即返回error;
BoneCP:跟Tomcat的处理方法一样;也是大约55秒之后才醒来,有了正常的反应,并且终于会等待5秒钟之后返回error了;
可见,HikariCP的处理方式是最合理的。根据这个测试结果,对于各个CP处理数据库中断的情况,评分如下:
参考文章:https://github.com/brettwooldridge/HikariCP/wiki/Bad-Behavior:-Handling-Database-Down
说得这么好,用起来会不会很麻烦啊,会不会有很多参数要配置才能有这样的效果啊?答案是:不会。
如果之前用的是BoneCP配置的数据源,那么,就简单了,只需要把dataSource换一下,稍微调整一下参数就行了:
BoneCP的数据源配置:
<!--BoneCpDatasource-->
<beanid="dataSourceBoneCp"class="com.jolbox.bonecp.BoneCPDataSource"destroy-method="close">
<propertyname="driverClass"value="$db.driverClass"/>
<propertyname="jdbcUrl"value="$db.url"/>
<propertyname="username"value="$db.username"/>
<propertyname="password"value="$db.password"/>
<propertyname="idleConnectionTestPeriodInMinutes"value="2"/>
<propertyname="idleMaxAgeInMinutes"value="2"/>
<propertyname="maxConnectionsPerPartition"value="2"/>
<propertyname="minConnectionsPerPartition"value="0"/>
<propertyname="partitionCount"value="2"/>
<propertyname="acquireIncrement"value="1"/>
<propertyname="statementsCacheSize"value="100"/>
<propertyname="lazyInit"value="true"/>
<propertyname="maxConnectionAgeInSeconds"value="20"/>
<propertyname="defaultReadOnly"value="true"/>
</bean>
HiKariCP的数据源配置:
<!--HikariDatasource-->
<beanid="dataSourceHikari"class="com.zaxxer.hikari.HikariDataSource"destroy-method="shutdown">
<!--<propertyname="driverClassName"value="$db.driverClass"/>--><!--无需指定,除非系统无法自动识别-->
<propertyname="jdbcUrl"value="jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8"/>
<propertyname="username"value="$db.username"/>
<propertyname="password"value="$db.password"/>
<!--连接只读数据库时配置为true,保证安全-->
<propertyname="readOnly"value="false"/>
<!--等待连接池分配连接的最大时长(毫秒),超过这个时长还没可用的连接则发生SQLException,缺省:30秒-->
<propertyname="connectionTimeout"value="30000"/>
<!--一个连接idle状态的最大时长(毫秒),超时则被释放(retired),缺省:10分钟-->
<propertyname="idleTimeout"value="600000"/>
<!--一个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),缺省:30分钟,建议设置比数据库超时时长少30秒,参考MySQLwait_timeout参数(showvariableslike'%timeout%';)-->
<propertyname="maxLifetime"value="1800000"/>
<!--连接池中允许的最大连接数。缺省值:10;推荐的公式:((core_count*2)+effective_spindle_count)-->
<propertyname="maximumPoolSize"value="15"/>
</bean>
其中,很多配置都使用缺省值就行了,除了maxLifetime和maximumPoolSize要注意自己计算一下。
其他的配置(sqlSessionFactory、MyBatis MapperScannerConfigurer、transactionManager等)统统不用变。
其他关于Datasource配置参数的建议:
Configure your HikariCPidleTimeoutandmaxLifeTimesettings to be one minute less than thewait_timeoutof MySQL. 参考技术A 为何要使用HiKariCP?这要先从BoneCP说起:
什么?不是有C3P0/DBCP这些成熟的数据库连接池吗?一直用的好好的,为什么又搞出一个BoneCP来?因为,传说中BoneCP在快速这个特点上做到了极致,官方数据是C3P0等的25倍左右。不相信?其实我也不怎么信。可是,有图有真相啊(图片来自BoneCP官网:
关于可靠性方面,也是有实验和数据支持的。对于数据库连接中断的情况,通过测试getConnection(),各种CP的不相同处理方法如下:
(所有CP都配置了跟connectionTimeout类似的参数为5秒钟)
HikariCP:等待5秒钟后,如果连接还是没有恢复,则抛出一个SQLExceptions 异常;后续的getConnection()也是一样处理;
C3P0:完全没有反应,没有提示,也不会在“CheckoutTimeout”配置的时长超时后有任何通知给调用者;然后等待2分钟后终于醒来了,返回一个error;
Tomcat:返回一个connection,然后……调用者如果利用这个无效的connection执行SQL语句……结果可想而知;大约55秒之后终于醒来了,这时候的getConnection()终于可以返回一个error,但没有等待参数配置的5秒钟,而是立即返回error;
BoneCP:跟Tomcat的处理方法一样;也是大约55秒之后才醒来,有了正常的反应,并且终于会等待5秒钟之后返回error了;
上述都是在网上找得到的,你直接搜关键字就可以看到的。
springboot集成druid数据源并且监控
Druid是Java语言中最好的数据库连接池,并且能够提供强大的监控和扩展功能。
业界把 Druid 和 HikariCP 做对比后,虽说 HikariCP 的性能比 Druid 高,但是因为 Druid 包括很多维度的统计和分析功能,所以这也是大家都选择使用它的原因。
首先配置 druid maven 依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.18</version>
</dependency>
配置 application.properties
#数据库
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.url=jdbc:mysql://localhost:3306/my_data?useUnicode=true&characterEncoding=utf8
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
#为实体对象所在的包,跟数据库表一一对应
mybatis.typeAliasesPackage=com.exer.demo.entity
#mapper文件的位置
mybatis.mapperLocations=classpath:mapper/*.xml
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
spring.datasource.initialSize=5
spring.datasource.minIdle=5
spring.datasource.maxActive=20
# 配置获取连接等待超时的时间
spring.datasource.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.timeBetweenEvictionRunsMillis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.minEvictableIdleTimeMillis=300000
# 校验SQL,Oracle配置 spring.datasource.validationQuery=SELECT 1 FROM DUAL,如果不配validationQuery项,则下面三项配置无用
spring.datasource.validationQuery=SELECT \'x\'
spring.datasource.testWhileIdle=true
spring.datasource.testOnBorrow=false
spring.datasource.testOnReturn=false
# 打开PSCache,并且指定每个连接上PSCache的大小
spring.datasource.poolPreparedStatements=true
spring.datasource.maxPoolPreparedStatementPerConnectionSize=20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,\'wall\'用于防火墙
spring.datasource.filters=stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
spring.datasource.useGlobalDataSourceStat=true
@Configuration
public class DruidConfiguration {
@Bean
public ServletRegistrationBean DruidStatViewServle2() {
//org.springframework.boot.context.embedded.ServletRegistrationBean提供类的进行注册.
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid2/*");
//添加初始化参数:initParams
//白名单:
servletRegistrationBean.addInitParameter("allow","192.168.1.106");
//IP黑名单 (存在共同时,deny优先于allow) : 如果满足deny的话提示:Sorry, you are not permitted to view this page.
// servletRegistrationBean.addInitParameter("deny", "192.168.1.73");
//登录查看信息的账号密码.
servletRegistrationBean.addInitParameter("loginUsername","admin");
servletRegistrationBean.addInitParameter("loginPassword","123456");
//是否能够重置数据.
servletRegistrationBean.addInitParameter("resetEnable","false");
return servletRegistrationBean;
}
/**
* 注册一个:filterRegistrationBean
* @return
*/
@Bean
public FilterRegistrationBean druidStatFilter2(){
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter());
//添加过滤规则.
filterRegistrationBean.addUrlPatterns("/*");
//添加不需要忽略的格式信息.
filterRegistrationBean.addInitParameter("exclusions","*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid2/*");
return filterRegistrationBean;
}
}
重启启动项目 http://192.168.1.106:8081/druid2/login.html 账号和密码: admin 123456
如果不使用代码手动初始化DataSource的话,监控界面的SQL监控会没有数据
这种情况下手动初始化 druid DataSource
@Value("${spring.datasource.url}")
private String dbUrl;
@Value("${spring.datasource.username}")
private String username;
@Value("${spring.datasource.password}")
private String password;
@Value("${spring.datasource.driver-class-name}")
private String driverClassName;
@Value("${spring.datasource.initialSize}")
private int initialSize;
@Value("${spring.datasource.minIdle}")
private int minIdle;
@Value("${spring.datasource.maxActive}")
private int maxActive;
@Value("${spring.datasource.maxWait}")
private int maxWait;
@Value("${spring.datasource.timeBetweenEvictionRunsMillis}")
private int timeBetweenEvictionRunsMillis;
@Value("${spring.datasource.minEvictableIdleTimeMillis}")
private int minEvictableIdleTimeMillis;
@Value("${spring.datasource.validationQuery}")
private String validationQuery;
@Value("${spring.datasource.testWhileIdle}")
private boolean testWhileIdle;
@Value("${spring.datasource.testOnBorrow}")
private boolean testOnBorrow;
@Value("${spring.datasource.testOnReturn}")
private boolean testOnReturn;
@Value("${spring.datasource.poolPreparedStatements}")
private boolean poolPreparedStatements;
@Value("${spring.datasource.maxPoolPreparedStatementPerConnectionSize}")
private int maxPoolPreparedStatementPerConnectionSize;
@Value("${spring.datasource.filters}")
private String filters;
@Value("${spring.datasource.connectionProperties}")
private String connectionProperties;
@Value("${spring.datasource.useGlobalDataSourceStat}")
private boolean useGlobalDataSourceStat;
@Bean //声明其为Bean实例
@Primary //在同样的DataSource中,首先使用被标注的DataSource
public DataSource dataSource(){
DruidDataSource datasource = new DruidDataSource();
datasource.setUrl(this.dbUrl);
datasource.setUsername(username);
datasource.setPassword(password);
datasource.setDriverClassName(driverClassName);
//configuration
datasource.setInitialSize(initialSize);
datasource.setMinIdle(minIdle);
datasource.setMaxActive(maxActive);
datasource.setMaxWait(maxWait);
datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
datasource.setValidationQuery(validationQuery);
datasource.setTestWhileIdle(testWhileIdle);
datasource.setTestOnBorrow(testOnBorrow);
datasource.setTestOnReturn(testOnReturn);
datasource.setPoolPreparedStatements(poolPreparedStatements);
datasource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize);
datasource.setUseGlobalDataSourceStat(useGlobalDataSourceStat);
try {
datasource.setFilters(filters);
} catch (SQLException e) {
System.err.println("druid configuration initialization filter: "+ e);
}
datasource.setConnectionProperties(connectionProperties);
return datasource;
}
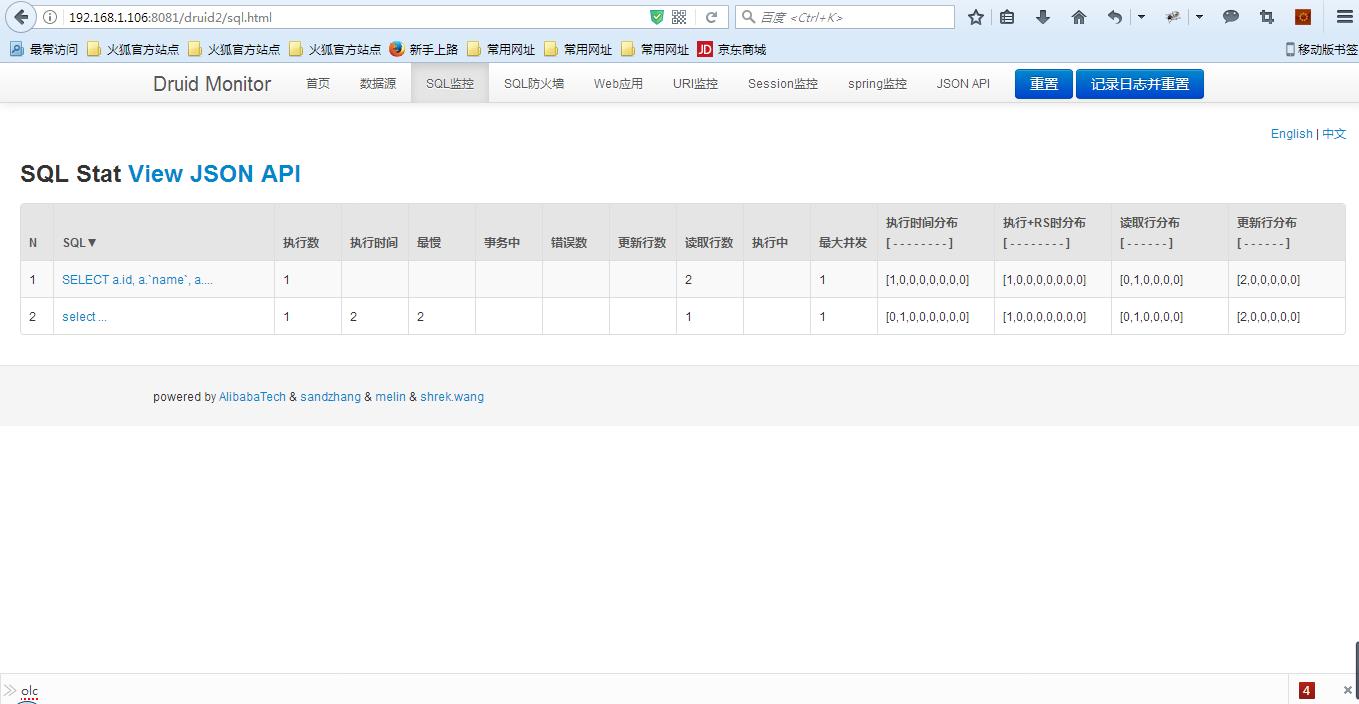
SQL监控就可以看到执行信息了。
以上是关于为啥HikariCP被号称为性能最好的Java数据库连接池,如何配置使用的主要内容,如果未能解决你的问题,请参考以下文章
[转帖]为什么HikariCP被号称为性能最好的Java数据库连接池,如何配置使用
Day860.高性能数据库连接池HiKariCP -Java 并发编程实战
Day860.高性能数据库连接池HiKariCP -Java 并发编程实战