DeepLizard:Pytorch神经网络编程教学(第二部分)
Posted 10000hours
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DeepLizard:Pytorch神经网络编程教学(第二部分)相关的知识,希望对你有一定的参考价值。
视频地址(B站):适用于初学者的PyTorch神经网络编程教学
课程官方博客地址:DEEPLIZARD
个人笔记第一部分:DeepLizard:Pytorch神经网络编程教学(第一部分)
说明:
- 笔记为个人学习笔记,如有错误,欢迎指正。
- 本篇笔记整理的内容为课程的第二部分,对应视频为 P 14 ∼ P 43 P_14\\sim P_43 P14∼P43
- DeepLizard课程为全英文授课,B站视频为中文字幕,且每个视频都有配套的博客与课后测试题。
文章目录
- Section 1:数据和数据处理
- Section 2:神经网络和 PyTorch 设计
- Section 3:训练神经网络
- Section 4:神经网络实验#
- Section 5:补充学习
Section 1:数据和数据处理
对应视频: P 14 ∼ P 16 P_14\\sim P_16 P14∼P16
P14:fashion-mnist数据集
略。
P15:使用torchvision演示一种简单的提取、转换和加载流程(ETL)
ETL过程
- Extract data from a data source. 从数据源中提取数据。
- Transform data into a desirable format. 将数据转换为所需的格式。
- Load data into a suitable structure. 将数据加载到合适的结构中。
使用PyTorch准备数据
torchvision包,它可以使我们访问以下资源:Datasets;Models;Transforns;Utils
PyTorch Dataset Class
如要使用torchvision获取FashionMNIST数据集,可以通过以下代码实现:
train_set = torchvision.datasets.FashionMNIST(
root='./data'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
| 参数 | 说明 |
|---|---|
| root | 磁盘上数据所在的位置 |
| train | 数据集是否是训练集 |
| download | 是否下载数据 |
| transform | 应对数据集元素执行的转换组合 |
当第一次运行完此代码后,FashionMNIST数据集将会下载到本地。
PyTorch DataLoader Class
为训练集创建一个DataLoader包装器:
train_loader = torch.utils.data.DataLoader(train_set
,batch_size=1000
,shuffle=True
)
P16:使用DataSet和DataLoader
查看数据
# 查看训练集中有多少图像
len(train_set) # 6000
# 查看每个图像的标签
train_set.targets # tensor([9, 0, 0, ..., 3, 0, 5])
# 查看数据集中每个标签有多少个
train_set.targets.bincount() # tensor([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000])
访问训练集中的数据
sample = next(iter(train_set))
len(sample) # 2
为访问训练集中的单个元素,先将train_set传给函数iter(),该函数返回一个表示数据流的对象,之后就可以用Python的内置函数next()来获取数据流中的下一个数据元素。
由函数的输出可知,每个样本(sample)包含两项,这是数据集中包含的图像标签对。可以使用序列解包来分配图像和标签:
image, label = sample
print(type(image)) # <class 'torch.Tensor'>
print(type(label)) # <class 'int'>
查看元素:
print(image.shape) # torch.Size([1, 28, 28])
print(torch.tensor(label).shape) # torch.Size([])
# 调用squeeze(),删除维度
print(image.squeeze().shape) # torch.Size([28, 28])
绘制图像:
plt.imshow(image.squeeze(), cmap='gray')
print(torch.tensor(label)) # tensor(0)
# 说明:这里sample为train_set[2],也就是第三个元素,它的标签为0,对照上面的train_set.targets输出,可以看到第三个图像的标签就是0

PyTorch DataLoader:处理成批的数据
# 先创建一个批处理大小为10的数据加载程序:
display_loader = torch.utils.data.DataLoader(train_set, batch_size = 10)
# 注意:当shuffle=True时,每个batch都会不同
batch = next(iter(display_loader))
print(len(batch)) # 2
# 查看返回批次的长度
images, labels = batch
print(type(images)) # <class 'torch.Tensor'>
print(type(labels)) # <class 'torch.Tensor'>
print(images.shape) # torch.Size([10, 1, 28, 28]) # (批量大小,颜色通道数,图像高度,图像宽度)
print(labels.shape) # torch.Size([10])
绘制一批图像:
# 绘制一批图像
# 方法一:
grid = torchvision.utils.make_grid(images, nrow=10)
plt.figure(figsize=(15,15))
plt.imshow(np.transpose(grid, (1,2,0)))
# 方法二:
grid = torchvision.utils.make_grid(images, nrow=10)
plt.figure(figsize=(15,15))
plt.imshow(grid.permute(1,2,0))

Section 2:神经网络和 PyTorch 设计
P17:构建PyTorch CNN
一些包和函数
-
nn.Module
PyTorch的神经网络库中包含了构建神经网络所需的所有典型组件。深度神经网络是使用多层构建的,神经网络中每一层都有两个主要组成部分:变换(代码),权重的集合(数据)。PyTorch中的nn.Module是所有包含层的神经网络模块的基类,这意味着PyTorch中的所有层都扩展了nn.Module。
-
forward()
前向传播:当把一个张量传递给我们的网络作为输入,张量通过每个层变换向前流动,直到张量达到输出层。这个通过网络向前流动的张量的过程被称为前向传播。每一层都有它自己的变换,张量向前通过每一层的变换。所有单独的层的前向传播的组合定义了网络本身的整体向前转换。
在PyTorch中,每个nn.module都有一个前向方法来代表前向传输。因此在神经网络中构建层时,必须提供前向方法(forward method)的实现,前向方法就是实际的变换。
-
nn.functional
nn.functional包为我们提供了许多可用于构建层的神经网络操作。
构建神经网络
在 PyTorch 中构建神经网络的大纲:
- 创建一个扩展神经网络模块基类的神经网络类
- 在类构造函数中将网络的层定义为类属性
- 使用网络层属性以及nn.functional API的操作来定义网络的前向传播forward()
import torch.nn as nn
# 基础版
class Network:
def __init__(self):
self.layer = None # 层
def forward(self, t): # 前向传播函数
t = self.layer(t)
return t
# 进阶版
class Netword(nn.Module): # 定义一个扩展基类的神经网络类
def __init__(self):
super().__init__()
# 卷积层
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
# 线性层
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Lineat(in_features=60, out_features=10)
def forward(self, t):
# t = self.layer(t)
return t
P18:CNN层,理解构建CNN时使用的参数
CNN层
在P17中,我们定义了两个卷积层和三个线性层。我们的每一层都扩展了PyTorch的神经网络模块基类。
对于每一层,有两个主要项目封装其中:前向函数定义和权重张量。每层中的权重张量包含了随着我们的网络在训练过程中学习而更新的权重值。在神经网络模块类中,PyTorch可以跟踪每一层的权重张量。由于我们扩展了神经网络模块基类,我们自动继承了这个功能。
CNN层参数
parameter 和 argument
- parameter在函数定义中使用,由于这个原因,我们可以把参数看成是占位符。
- argument是当函数被调用时传递给函数的实际值。
- 或者说,parameter是形参,argument是实参
超参数和数据相关超参数 - 超参数的值是手动设置和任意选择的,主要是根据试错来选择超参数的值,并更多地使用过去已被证明有效的值。e.g. CNN层中的超参数
- kernel_size:内核大小设置了在该层中使用的滤波器的大小。(在DL中,内核kernel和滤波器filter是一个意思,所以卷积核和卷积滤波器是一个东西)
- out_channels:设置滤波器的深度。这是滤波器的内核数。(在一个卷积层中,输入通道与一个卷积滤波器配对来执行卷积运算。滤波器包含输入通道,这个操作的结果是一个输出通道。所以一个包含输入通道的滤波器可以给我们一个相应的输出通道。因此我们在设置输出通道数时,其实是在设置滤波器的数量。)
- out_features:设置输出张量的大小。
- 数据相关超参数是其值依赖于数据的参数。e.g. 第一个卷积层in_channels和输出层out_features。
P19:CNN内部的权重张量
可学习参数
可学习参数是在训练过程中学习的参数。对于可学习参数,通常重一组任意的值开始,当网络学习时,这些值就会以迭代的方式更新。
可学习参数是网络内部的权重,它们存在于每一层中。
获取实例网络
network = Network()
print(network)
# 输出
Network(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 12, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=192, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=60, bias=True)
(out): Linear(in_features=60, out_features=10, bias=True)
)
- kernel_size=(5, 5):当我们传递单个数字时,层构造函数假定我们想要的是一个方形滤波器。
- stride=(1, 1):告诉conc层在每次卷积操作后滤波器应该滑动多远。
访问层的权重
network.conv1.weight
其输出是一个张量,其中的值或标量分量是我们网络的可学习参数。当网络训练时,这些权重值会以一种方式更新,以使损失函数最小化。
权重张量形状
传递给层的参数值将直接影响网络的权重。
对于卷积层,权重值位于滤波器内部,在代码中,滤波器实际上是权重张量本身。层内的卷积操作是层的输入通道与层内的滤波器之间的操作。
network.conv1.weight.shape
# 输出:torch.Size([6, 1, 5, 5])
- 第一个轴的长度为6,这说明有6个滤波器。
- 第二个轴的长度为1,说明只有单个输入通道。
- 第三、四个轴的数值代表滤波器的高度和宽度。
network.conv2.weight.shape
# 输出:torch.Size([12, 6, 5, 5])
- 第二个conv层有12个滤波器,说明有来自前一层的6个输入通道。
- 可以将值6看做是赋予每个滤波器一定的深度,滤波器没有迭代的卷积所有的通道,而是具有与通道数相匹配的深度。
关于这些卷积层的两个要点:滤波器使用一个张量来表示,张量内的每个滤波器也有一个深度来说明正在卷积的输入通道数。
这里的张量是秩为4的张量,第一个轴表示滤波器的数量;第二个轴表示每个滤波器的深度,对应于被卷积的输入通道数量;最后两个轴表示每个滤波器的高和宽。
(
滤波器数量,深度,高度,宽度
)
(滤波器数量,深度,高度,宽度)
(滤波器数量,深度,高度,宽度)
权重矩阵
network.fc1.weight.shape # torch.Size([120, 192])
network.fc2.weight.shape # torch.Size([60, 120])
network.out.weight.shape # torch.Size([10, 60])
len(network.out.weight.shape) # 2
每个线性层都有一个秩为2的权重张量。以fc1的权重张量为例,由权重张量的形状可知,row120是输出特征的大小,column192是输入特征的大小,也就是说,权重张量的形状是根据输入特征和输出特征的大小得来的。通过矩阵乘法来直观感受:
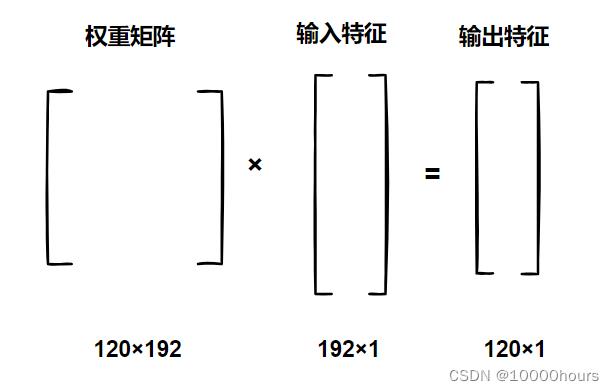
线性层使用矩阵乘法来将它们的输入特征转换为输出特征:当输入特征被线性层接收时,它们以一个扁平的一维张量的形式传递,然后乘以权重矩阵,得到的结果就是输出特征。
这就是线性层的工作原理:它们使用一个权重矩阵将一个输入特征空间映射到一个输出特征空间。
P20:PyTorch可调用的神经网络模块,以及网络和层的前向方法是如何调用的
Linear类中的权重
定义输入特征和权重矩阵:
import torch
in_features = torch.tensor([1,2,3,4], dtype=torch.float32)
weight_matrix = torch.tensor([
[1,2,3,4],
[2,3,4,5],
[3,4,5,6]
],dtype=torch.float32)
执行矩阵乘法,由P19的内容可知,得到的输出就是输出特征out_features:
weight_matrix.matmul(in_features)
# 输出:tensor([30., 40., 50.])
定义一个线性层,输入特征大小为4,输出特征大小为3:
fc = nn.Linear(in_features=4, out_features=3)
这一步要注意的是:通过使用权重矩阵将4维空间映射到3维空间。权重矩阵位于PyTorch线性层类中,由PyTorch创造,PyTorch线性层类通过将4和3传递给构造函数,以创建一个3x4的权重矩阵
调用对象实例
fc(in_features)
# 输出:tensor([ 0.2730, -0.4860, -1.7627], grad_fn=<AddBackward0>)
这里的值[ 0.2730, -0.4860, -1.7627]与[30., 40., 50.]相差甚远,这是因为PyTorch创建了一个权重矩阵,并用随机值来初始化。
权重矩阵中的值定义了一个线性函数( y = A x + b y=Ax+b y=Ax+b)。这表明了在训练过程中,当权重被更新时,网络的映射是如何变化的,当更新权重时,我们在改变函数(更改了 A A A和 b b b)。
再使用新的输入进行测试:
fc.weight = nn.Parameter(weight_matrix)
fc(in_features)
# 输出:tensor([30.4673, 40.0535, 50.3319], grad_fn=<AddBackward0>)
输出结果更接近[30,40,50]但又不完全相等,这是因为有偏置值的存在。
特殊的调用方法:__call()__函数
如果一个类实现了特殊的__call()__方法,每当调用对象实例时,都会调用__call()__方法。
我们不直接调用前向方法forward(),而是调用对象实例,在调用对象实例之后,__call()__方法会被调用,而__call()__方法又反过来调用forward()方法。
PyTorch在__call()__方法中运行的额外代码是我们从未直接调用forward()方法的原因: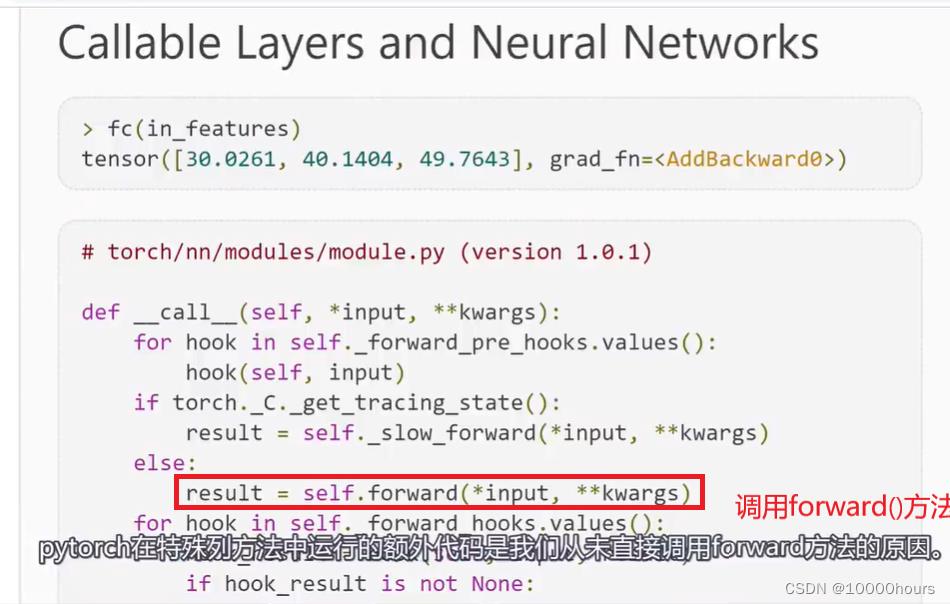
P21:调试PyTorch源代码
略
P22:实现一个卷积神经网络的前向方法
我们的forward()方法接收一个张量作为输入,然后返回一个张量作为输出。
forward()方法的实现将使用我们在构造函数中定义的所有层。forward()方法是输入张量到一个预测的输出张量的映射。
关于input layer:
- 任何神经网络的输入层都是由输入数据决定的。
- 比如,若输入张量中包含三个元素,那网络将有三个节点包含在它的输入层中,因此可将输入层看做恒等转换( f ( x ) = x f(x)=x f(x)=x)
- 输入层通常隐藏。但在以下代码中,将输入层用代码显示表示出来:
t = t
import torch
import torch.nn as nn
import torch.nn.functional as F
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
# (1)输入层input layer(输入层在代码中通常隐藏)
t = t
# (2)卷积层 hidden conv layer t = self.conv1(t) # 其中封装了权重
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
# (3)卷积层 hidden conv layer t = self.conv2(t) # 其中封装了权重
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
# 注:每层都由一组权重和一组操作组成。
# 权重被封装在神经网络模块层类实例中:e.g. self.conv1(t)
# relu()和max_pool2d()都是操作
# 在把输入传递给第一个线性层之前,必须重塑张量。每当把卷积层的输出输入到一个线性层时,就会出现这种情况
# (4)线性层 hidden liner layer # 12是由之前的卷积层产生的输出通道数决定的
# 4 * 4是12个输出通道的高和宽
t = t.reshape(-1, 12 * 4 * 4)
t = self.fc1(t)
t = F.relu(t)
# (5)线性层 hidden liner layer t = self.fc2(t)
t = F.relu(t)
# (6)输出层 output layer t = self.out(t)
t = F.softmax(t, dim=1)
return t
P23:使用卷积神经网络由数据集的样本输入生成输出预测答案
再来理解一下前向传播:
- 前向传播是将输入张量转换为输出张量的过程。
- 神经网络是将输入张量映射到输出张量的函数,而前向传播只是将输入张量传递给网络并从网络接收输出的过程的一个特殊名称。
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
torch.set_printoptions(linewidth=120)
# 建立训练集
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
# 建立模型
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 =递归神经网络RNN怎样加速?看PyTorch如何进行动态批处理
原文来源:medium
「机器人圈」编译:多啦A亮
 如果你读过我的博客,你可能已经了解到我是一个TensorFlow的贡献者,并在那里建立了很多高级API。
如果你读过我的博客,你可能已经了解到我是一个TensorFlow的贡献者,并在那里建立了很多高级API。
而在2017年2月,我已经离开谷歌并创立了自己的公司——。我们教机器用自然语言编写代码。
作为这项工作的一部分,我们正在构建以树格式读取或编写代码的深度学习模型。在试图用TensorFlow管理这种复杂性之后,我已经决定尝试用一下PyTorch。
PyTorch是由Facebook AI研究人员构建的框架,并且在自然语言和强化学习研究领域越来越受欢迎。它的主要优点是动态图形构建原理——与Tensorflow相比,其中图形一旦被构建,然后就会被“执行”多次,PyTorch可以使用简单的Python逻辑动态重建图形,就像你正在使用numpy数组进行计算一样。

来源: http://pytorch.org/about
这种灵活性吸引了一些人,他们使用复杂输入/输出数据(例如语言、树、图形)或需要在计算中运行一些自定义逻辑(深度强化学习)。
在这里我想谈谈批处理的事情。即使PyTorch利用GPU加速器快速运行,并且通常推进C模块的计算,如果你没有对计算进行批处理——你仍然需要付出代价。
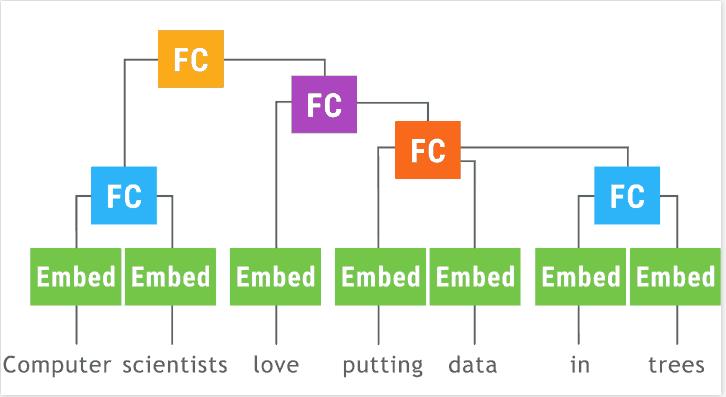
递归神经网络(以树形LSTM为例)特别难以批处理,因为每个示例都是不同的树。
单纯的实现将如下所示:
class TreeLSTM(nn.Module):
def __init__(self, num_units):
super(TreeLSTM, self).__init__()
self.num_units = num_units
self.left = nn.Linear(num_units, 5 * num_units)
self.right = nn.Linear(num_units, 5 * num_units)
def forward(self, left_in, right_in):
lstm_in = self.left(left_in[0])
lstm_in += self.right(right_in[0])
a, i, f1, f2, o = lstm_in.chunk(5, 1)
c = (a.tanh() * i.sigmoid() + f1.sigmoid() * left_in[1] +
f2.sigmoid() * right_in[1])
h = o.sigmoid() * c.tanh()
return h, c
class SPINN(nn.Module):
def __init__(self, n_classes, size, n_words):
super(SPINN, self).__init__()
self.size = size
self.tree_lstm = TreeLSTM(size)
self.embeddings = nn.Embedding(n_words, size)
self.out = nn.Linear(size, n_classes)
def leaf(self, word_id):
return self.embeddings(word_id), Variable(torch.FloatTensor(word_id.size()[0], self.size))
def children(self, left_h, left_c, right_h, right_c):
return self.tree_lstm((left_h, left_c), (right_h, right_c))
def logits(self, encoding):
return self.out(encoding)
def encode_tree_regular(model, tree):
def encode_node(node):
if node.is_leaf():
return model.leaf(Variable(torch.LongTensor([node.id])))
else:
left_h, left_c = encode_node(node.left)
right_h, right_c = encode_node(node.right)
return model.children(left_h, left_c, right_h, right_c)
encoding, _ = encode_node(tree.root)
return model.logits(encoding)
...
all_logits, all_labels = [], []
for tree in batch:
all_logits.append(encode_tree_regular(model, tree))
all_labels.append(tree.label)
loss = criterion(torch.cat(all_logits, 0), Variable(torch.LongTensor(all_labels)))
有一种手动批处理的方法:在每次处理输入不同的操作之后,找出如何批处理输入,然后解除输出批处理。这是。
另一种选择是,根据我们要计算的确切输入/输出,找到一个系统决定为我们的批处理对象。灵感来自中描述的方法。 “动态计算图深度学习”(在中实现但似乎并不被支持),在这个动画中有很好的描绘:
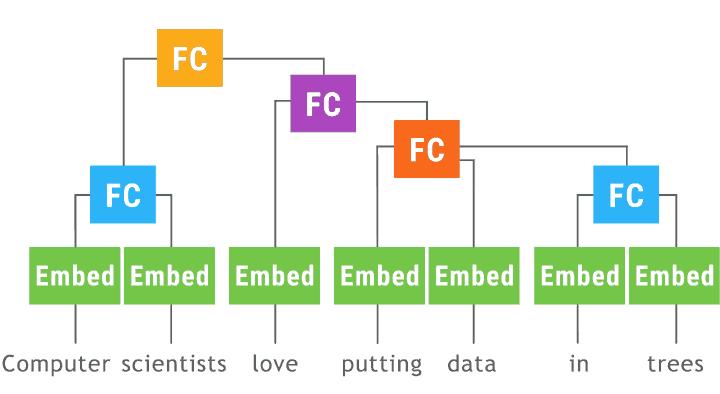
来源:http://github.com/tensorflow/fold
我已经在一个简单的TorchFold中实现了这个原理:
class TorchFold(object):
def __init__(self, versatible=False, cuda=False):
...
def add(self, op, *args):
...
def apply(self, nn, return_values):
...
现在,如果我们想用以前的gist对树形LSTM / 模型进行编码,那么我们需要这样更改代码:
from pytorch_tools import torchfold
def encode_tree_fold(fold, tree):
def encode_node(node):
if node.is_leaf():
return fold.add('leaf', node.id).split(2)
else:
left_h, left_c = encode_node(node.left)
right_h, right_c = encode_node(node.right)
return fold.add('children', left_h, left_c, right_h, right_c).split(2)
encoding, _ = encode_node(tree.root)
return fold.add('logits', encoding)
...
fold = torchfold.Fold(cuda=args.cuda)
all_logits, all_labels = [], []
for tree in batch:
all_logits.append(encode_tree_folded(fold, tree))
all_labels.append(tree.label)
res = fold.apply(model, [all_logits, all_labels])
loss = criterion(res[0], res[1])
这里,在每次调用encode_tree_folded时,通过fold.add添加节点来动态构建“折叠”图,其中op是要调用的模型中的函数的名称。它会自动显示哪些op可以组合在一起,哪些应该遵循。
然后在fold.apply,调用传递的模型的操作,传递它们的批处理的输入张量(可能在不同的步骤有不同的批处理大小),并自动输出到接下来的步骤。
比较未折叠和折叠版本之间的速度(在这里的简单模型):
常规:0.18秒/步(100 dim),2.19秒/步(500 dim)
折叠:0.05秒/步(100 dim),0.22秒/步(500 dim)
由于降低了计算非有效效率,提升了3-10倍的速度。
该工具通常对于任何复杂的架构(包括RNN)都是有用的,因为它至少在第一个实验中不需要考虑批处理。
你可以在这里找到实现和示例:
另外,在撰写本文时,我发现最近有关于这个主题的文章 - , DyNet的实现。
还有就是,自从升级到PyTorch 0.2.0后,我发现TorchFold的性能略有下降,所以为了最佳速度,尝试运行0.1.12直到稳定即可。
点击下图加入联盟
关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人圈官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条……
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册
以上是关于DeepLizard:Pytorch神经网络编程教学(第二部分)的主要内容,如果未能解决你的问题,请参考以下文章
零基础构建神经网络:使用PyTorch从零编写前馈神经网络代码
递归神经网络RNN怎样加速?看PyTorch如何进行动态批处理