递归神经网络RNN怎样加速?看PyTorch如何进行动态批处理
Posted 雷克世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了递归神经网络RNN怎样加速?看PyTorch如何进行动态批处理相关的知识,希望对你有一定的参考价值。
原文来源:medium
「机器人圈」编译:多啦A亮
 如果你读过我的博客,你可能已经了解到我是一个TensorFlow的贡献者,并在那里建立了很多高级API。
如果你读过我的博客,你可能已经了解到我是一个TensorFlow的贡献者,并在那里建立了很多高级API。
而在2017年2月,我已经离开谷歌并创立了自己的公司——。我们教机器用自然语言编写代码。
作为这项工作的一部分,我们正在构建以树格式读取或编写代码的深度学习模型。在试图用TensorFlow管理这种复杂性之后,我已经决定尝试用一下PyTorch。
PyTorch是由Facebook AI研究人员构建的框架,并且在自然语言和强化学习研究领域越来越受欢迎。它的主要优点是动态图形构建原理——与Tensorflow相比,其中图形一旦被构建,然后就会被“执行”多次,PyTorch可以使用简单的Python逻辑动态重建图形,就像你正在使用numpy数组进行计算一样。

来源: http://pytorch.org/about
这种灵活性吸引了一些人,他们使用复杂输入/输出数据(例如语言、树、图形)或需要在计算中运行一些自定义逻辑(深度强化学习)。
在这里我想谈谈批处理的事情。即使PyTorch利用GPU加速器快速运行,并且通常推进C模块的计算,如果你没有对计算进行批处理——你仍然需要付出代价。
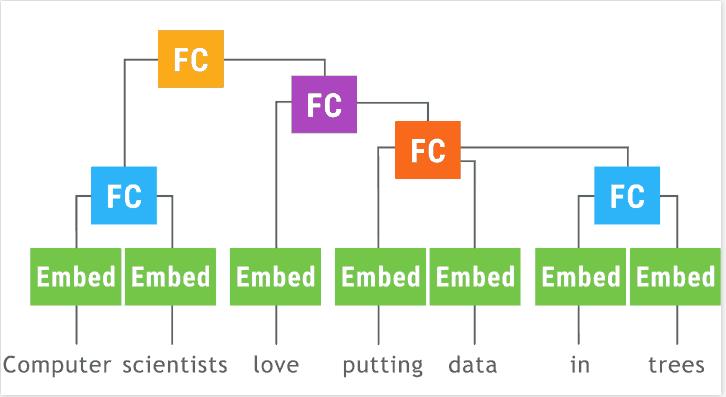
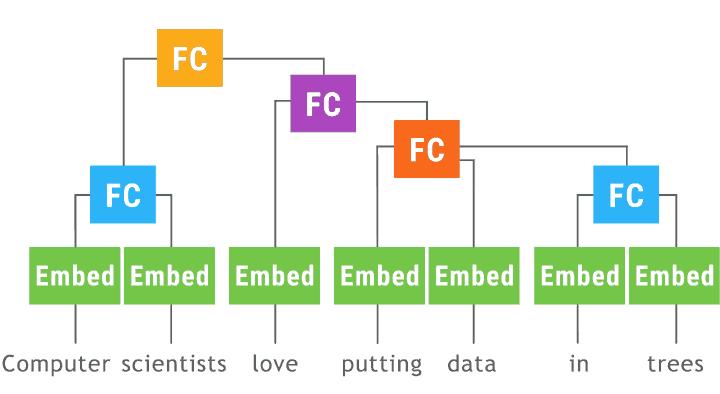
递归神经网络(以树形LSTM为例)特别难以批处理,因为每个示例都是不同的树。
单纯的实现将如下所示:
class TreeLSTM(nn.Module):
def __init__(self, num_units):
super(TreeLSTM, self).__init__()
self.num_units = num_units
self.left = nn.Linear(num_units, 5 * num_units)
self.right = nn.Linear(num_units, 5 * num_units)
def forward(self, left_in, right_in):
lstm_in = self.left(left_in[0])
lstm_in += self.right(right_in[0])
a, i, f1, f2, o = lstm_in.chunk(5, 1)
c = (a.tanh() * i.sigmoid() + f1.sigmoid() * left_in[1] +
f2.sigmoid() * right_in[1])
h = o.sigmoid() * c.tanh()
return h, c
class SPINN(nn.Module):
def __init__(self, n_classes, size, n_words):
super(SPINN, self).__init__()
self.size = size
self.tree_lstm = TreeLSTM(size)
self.embeddings = nn.Embedding(n_words, size)
self.out = nn.Linear(size, n_classes)
def leaf(self, word_id):
return self.embeddings(word_id), Variable(torch.FloatTensor(word_id.size()[0], self.size))
def children(self, left_h, left_c, right_h, right_c):
return self.tree_lstm((left_h, left_c), (right_h, right_c))
def logits(self, encoding):
return self.out(encoding)
def encode_tree_regular(model, tree):
def encode_node(node):
if node.is_leaf():
return model.leaf(Variable(torch.LongTensor([node.id])))
else:
left_h, left_c = encode_node(node.left)
right_h, right_c = encode_node(node.right)
return model.children(left_h, left_c, right_h, right_c)
encoding, _ = encode_node(tree.root)
return model.logits(encoding)
...
all_logits, all_labels = [], []
for tree in batch:
all_logits.append(encode_tree_regular(model, tree))
all_labels.append(tree.label)
loss = criterion(torch.cat(all_logits, 0), Variable(torch.LongTensor(all_labels)))
有一种手动批处理的方法:在每次处理输入不同的操作之后,找出如何批处理输入,然后解除输出批处理。这是。
另一种选择是,根据我们要计算的确切输入/输出,找到一个系统决定为我们的批处理对象。灵感来自中描述的方法。 “动态计算图深度学习”(在中实现但似乎并不被支持),在这个动画中有很好的描绘:
来源:http://github.com/tensorflow/fold
我已经在一个简单的TorchFold中实现了这个原理:
class TorchFold(object):
def __init__(self, versatible=False, cuda=False):
...
def add(self, op, *args):
...
def apply(self, nn, return_values):
...
现在,如果我们想用以前的gist对树形LSTM / 模型进行编码,那么我们需要这样更改代码:
from pytorch_tools import torchfold
def encode_tree_fold(fold, tree):
def encode_node(node):
if node.is_leaf():
return fold.add('leaf', node.id).split(2)
else:
left_h, left_c = encode_node(node.left)
right_h, right_c = encode_node(node.right)
return fold.add('children', left_h, left_c, right_h, right_c).split(2)
encoding, _ = encode_node(tree.root)
return fold.add('logits', encoding)
...
fold = torchfold.Fold(cuda=args.cuda)
all_logits, all_labels = [], []
for tree in batch:
all_logits.append(encode_tree_folded(fold, tree))
all_labels.append(tree.label)
res = fold.apply(model, [all_logits, all_labels])
loss = criterion(res[0], res[1])
这里,在每次调用encode_tree_folded时,通过fold.add添加节点来动态构建“折叠”图,其中op是要调用的模型中的函数的名称。它会自动显示哪些op可以组合在一起,哪些应该遵循。
然后在fold.apply,调用传递的模型的操作,传递它们的批处理的输入张量(可能在不同的步骤有不同的批处理大小),并自动输出到接下来的步骤。
比较未折叠和折叠版本之间的速度(在这里的简单模型):
常规:0.18秒/步(100 dim),2.19秒/步(500 dim)
折叠:0.05秒/步(100 dim),0.22秒/步(500 dim)
由于降低了计算非有效效率,提升了3-10倍的速度。
该工具通常对于任何复杂的架构(包括RNN)都是有用的,因为它至少在第一个实验中不需要考虑批处理。
你可以在这里找到实现和示例:
另外,在撰写本文时,我发现最近有关于这个主题的文章 - , DyNet的实现。
还有就是,自从升级到PyTorch 0.2.0后,我发现TorchFold的性能略有下降,所以为了最佳速度,尝试运行0.1.12直到稳定即可。
点击下图加入联盟
关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人圈官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条……
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册
以上是关于递归神经网络RNN怎样加速?看PyTorch如何进行动态批处理的主要内容,如果未能解决你的问题,请参考以下文章