半监督学习——混合模型
Posted pjqooo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了半监督学习——混合模型相关的知识,希望对你有一定的参考价值。
Semi-Supervised Learning
半监督学习(三)
方法介绍
Mixture Models & EM
无标签数据告诉我们所有类的实例混和在一起是如何分布的,如果我们知道每个类中的样本是如何分布的,我们就能把混合模型分解成独立的类,这就是mixture models背后的机制。今天,小编就带你学习半监督学习的混合模型方法。
混合模型 监督学习
首先,我们来学习概率模型的概念,先来看一个例子:
-
Example 1. Gaussian Mixture Model with Two Components
训练数据来自两个一维的高斯分布,如下图展示了真实的分布以及一些训练样本,其中只有两个有标签数据,分别标记为正负。
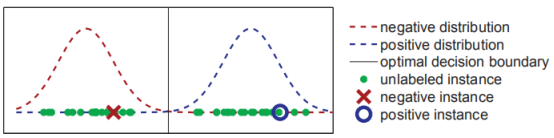
假如我们知道数据来自两个高斯分布,但是不知道参数(均值,方差,先验概率等),我们可以利用数据(有标签和无标签)对两个分布的参数进行估计。注意这个例子中,带标签的两个样本实际上带有误导性,因为它们都位于真实分布均值的右侧,而无标签数据可以帮助我们定义两个高斯分布的均值。参数估计就是选择能 最大限度提高模型生成此类训练数据概率 的参数。
更规范化地解释:要预测样本x的标签y,我们希望预测值能最大化条件概率p(y|x),由条件概率的定义,可知对于所有可能的标签y,
 ,且
,且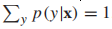 ,如果我们想要最小化分类错误率,那么我们的目标函数就是
,如果我们想要最小化分类错误率,那么我们的目标函数就是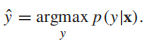 ,当然了,如果不同类型的误分类导致的损失不同(如,将良性肿瘤错误分类为恶性),那么上述的最小化期望误差可能不是最佳策略,我们将在下文中讨论最小化损失函数的内容。那么如何计算p(y|x)呢?一种方法就是使用生成模型(采用Bayes规则):
,当然了,如果不同类型的误分类导致的损失不同(如,将良性肿瘤错误分类为恶性),那么上述的最小化期望误差可能不是最佳策略,我们将在下文中讨论最小化损失函数的内容。那么如何计算p(y|x)呢?一种方法就是使用生成模型(采用Bayes规则):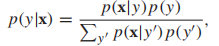 其中,P(x|y):类条件概率;p(y):先验概率;P(x,y) = p(y)p(x|y) :联合分布。多元高斯分布常作为连续型随机变量的生成模型,它的类条件概率的形式如下:
其中,P(x|y):类条件概率;p(y):先验概率;P(x,y) = p(y)p(x|y) :联合分布。多元高斯分布常作为连续型随机变量的生成模型,它的类条件概率的形式如下: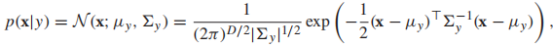
 和
和 分别表示均值向量和协方差矩阵。以一个图像分类任务为例,x是一张图片的像素向量,每一种类别的图像都用高斯分布建模,那么整体的生成模型就叫做高斯混合模型(GMM)。
分别表示均值向量和协方差矩阵。以一个图像分类任务为例,x是一张图片的像素向量,每一种类别的图像都用高斯分布建模,那么整体的生成模型就叫做高斯混合模型(GMM)。 -
多项式分布也常作为生成模型,他的形式如下:
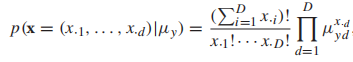
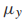 是一个概率向量。以一个文本分类的任务为例,x是一个文档的词向量,每一种类型的文档都用多项式分布来建模,那么整体的生成模型就叫做多项式混合模型。
是一个概率向量。以一个文本分类的任务为例,x是一个文档的词向量,每一种类型的文档都用多项式分布来建模,那么整体的生成模型就叫做多项式混合模型。作为另一种生成模型的例子,隐马尔可夫模型(HMM)通常用来建模序列,序列中的每个实例都是从隐藏状态生成的,隐藏状态可以是高斯分布,也可以是多项式分布,而且HMMs 指定状态之间的转移概率来生成序列,学习HMMs模型包括估计条件概率分布的参数和转移概率。
现在,我们知道如何根据p(x|y)和p(y)来做分类,问题仍然是如何从训练集中学习到这些分布。类条件概率p(x|y)由模型参数决定,比如高斯分布的均值和协方差矩阵,对于p(y),如果由C个类,那么需要估计C-1个参数:p(y=1),...,p(y=C-1),因为p(y=C)=1- (p(y=1)+...+p(y=C-1))。用θ表示我们要估计的参数集合,一个最常用的准则是最大似然估计
(MLE),给定训练集D,
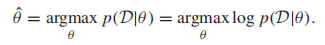
(我们常常使用对数似然,因为log函数是单调的,它与使用原函数有相同的最优解,但是更容易处理)。
在监督学习中,训练集为
,我们重写一些对数似然函数
现在我们来定义在监督学习中如何使用MLE(参数估计)建模高斯混合模型(以2分类高斯混合模型为例):
首先定义我们的约束优化问题:
接着我们引入拉格朗日乘子:
其中,
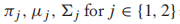 分别是类先验,高斯分布的均值和协方差矩阵。我们计算所有参数的偏导,然后设每个偏导函数为0,得到MLE的闭式解:
分别是类先验,高斯分布的均值和协方差矩阵。我们计算所有参数的偏导,然后设每个偏导函数为0,得到MLE的闭式解: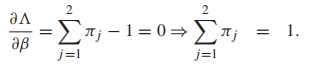
(显然,β拉格朗日乘数的作用是对类先验概率执行规范化约束) 以及
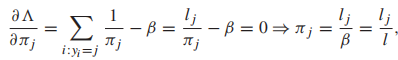
从上面的式子中可以发现β=l,最后我们发现,类先验概率就是每个类样本占总样本的比例。我们接下来解决类均值的问题,我们仍对均值向量求偏导,通常让v代表一个向量,A是一个合适大小的方阵,有
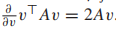 所以我们可以得到
所以我们可以得到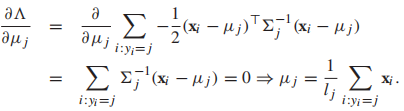 我们发现每个类的均值就是类中样本的均值。最后,用MLE求协方差矩阵
我们发现每个类的均值就是类中样本的均值。最后,用MLE求协方差矩阵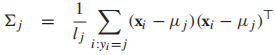 ,也是一个类中样本的协方差。
,也是一个类中样本的协方差。
Mixture models for semi-supervised classification
阅读完第一节,相信你们已经对混合模型及其参数估计有了理解,现在我们进入正题,如何将混合模型运用到半监督学习上去。
因为训练集中包含有标签和无标签数据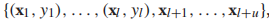
那么可以将似然函数定义为如下形式:
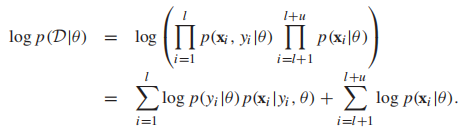
P(x|θ)叫做边缘概率,
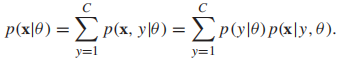
它代表的是我们知道这些未标记样本的存在,但是不知道它们属于哪个类。半监督的![]() 需要同时适用标签数据和无标签数据。我们把未观察到的标签叫做隐变量,不 幸的是,这些隐变量会导致log似然函数非凸而难以优化。但是,很多优化方法可以找到局部最优的θ,最有名的就是EM(expectation maximization)算法。
需要同时适用标签数据和无标签数据。我们把未观察到的标签叫做隐变量,不 幸的是,这些隐变量会导致log似然函数非凸而难以优化。但是,很多优化方法可以找到局部最优的θ,最有名的就是EM(expectation maximization)算法。
OPTIMIZATION WITH THE EM ALGORITHM

![]() 是隐藏标签的分布,可以认为是根据当前的模型参数为无标签数据预测的“软标签”。可以证明的是,EM每一轮迭代提高了log似然函数,但是EM只能求局部最优解(θ可能不是全局最优)。EM收敛的局部最优解依赖于θ的初始值,常用的初始值是有标签样本的MLE。注意,EM算法需要针对特定的生成模型,以GMM为例。
是隐藏标签的分布,可以认为是根据当前的模型参数为无标签数据预测的“软标签”。可以证明的是,EM每一轮迭代提高了log似然函数,但是EM只能求局部最优解(θ可能不是全局最优)。EM收敛的局部最优解依赖于θ的初始值,常用的初始值是有标签样本的MLE。注意,EM算法需要针对特定的生成模型,以GMM为例。
-
EM for GMM

其中,E-step相当于给每个样例计算一个标签概率向量,M-step更新模型参数,算法会在log似然函数收敛的时候停止,混合高斯模型的log似然函数是:
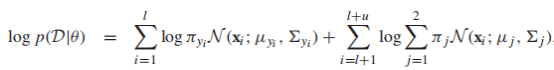
有的同学会发现,EM算法和我们之前提到过的self-training相似,EM算法可以看作self-training的特殊形式,其中当前的分类器θ将利用所有有标签数据给无标签数据打上标签,但是每个分类器的权重是
 ,然后这些增强的无标签数据被用来更新分类器。
,然后这些增强的无标签数据被用来更新分类器。
-
The Assumptions of Mixture Models
混合模型提供了半监督学习的框架,事实上,如果使用正确的生成模型,这种框架的效果是很好的,所以我们有必要在这里提以下模型假设:
Mixture Model Assumption:数据来自混合模型且模型个数,先验概率p(y)和条件概率p(x|y)是正确的。
然而,这一假设很难成立,因为有标签数据很少,很多时候我们都是根据领域知识去选择生成模型,但是模型一旦选错了,半监督学习会使模型表现变差,在这种场景下,最好只使用在有标签数据上进行监督学习。
-
Cluster-than-Label Method
我们已经用EM算法来给无标签数据打标签,其实无监督聚类算法同样可以从无标签数据中定义出类:

第一步,聚类算法A是无监督的,第二步,我们利用每个聚类中的有标签数据学习一个分类器,然后使用这个预测器对这个聚类中的无标签数据进行预测。
举一个使用层次聚类的Cluster-than-Label实例:
我们首先用层次聚类(距离方程用欧式距离,聚类之间的距离用single linkage决定)
下图展示了数据的原始分布(两个类),以及最终的标签预测结果,在这个例子中,由于两个有标签实例恰好是正确的,我们正确分类了所有的数据。
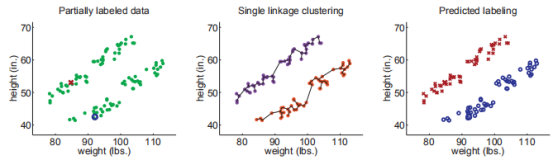
其实使用single linkage方法在这里非常重要(真实的聚类又细又长),如果使用complete linkage 聚类,聚类结果会偏向球形,结果会像这样:
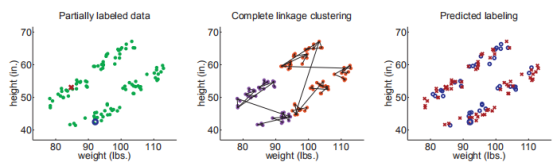
上面的实验并不是想说明complete linkage 不如 single linkage,而是为了强调假设对半监督学习的重要性。
总结:
这篇文章混合模型和EM算法在半监督学习上的应用,随后也介绍了一种非概率的,先聚类后标记的方法,它们背后都隐含这相同的思想:无标签数据可以帮助定义输入空间的聚类,下一篇文章中,我们会介绍另一种半监督学习方法 co-training,敬请期待~
希望大家多多支持我的公众号,扫码关注,我们一起学习,一起进步~

以上是关于半监督学习——混合模型的主要内容,如果未能解决你的问题,请参考以下文章