ScratchDet by hs
Posted bupt213
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ScratchDet by hs相关的知识,希望对你有一定的参考价值。
一、简介
1、目前的检测网络都是基于现成的分类网络来进行fine-tune的,这样会存在几个问题:
1)检测和分类任务对变化(translation)的敏感度不同,这样导致对学习目标的偏差
2)分类网络的结构会有很多限制,改动起来非常不方便
所以有了从零开始的训练方法(即没有预训练模型from scratch),但是从零开始训练的性能往往不如在预训练模型上接着finetune,且不容易收敛,作者发现导致这个问题的关键在于之前的训练没有加上BN层,BN层对从零开始的训练非常有帮助。
作者提出了一个ScratchDet,加上了BN层,利用从零训练也得到了很不错的效果。
2、BN层可以提供给网络稳定且可预测的梯度,这样可以使从零开始的训练变得更加稳定,同时可以使训练网络变得更加容易收敛,这样也更利于改变网络的结构。
作者从而提出了一个Root-ResNet,可以更加充分地利用训练图像的信息。
二、参考文献
CVPR2019: ScratchDet: Training Single-Shot Object Detectors from Scratch
三、BN
BN层就是对一批数据进行处理,使其分布更适合于网络下一步训练,解决的问题包括:
1、梯度消失问题,对于一些激活函数,如果输入的分布趋于两侧的话,会导致梯度变为0,从而最后梯度消失。
2、内部迁移问题,神经网络的中间层的输入的分布往往会跟原先的输入分布差别越来越大,这样对后面网络的学习会带来困难,收敛速度也会变慢,简单的归一化可以解决输入分布变化的为题,但是也会丢失前面网络学习到的特征,所以需要一些技巧。

对数据的处理方式如上图所示,分为几个步骤:
1、对输入求均值和方差进行标准化
2、对输入进行变换重构,即包含γ和β两个参数,这两个参数都是通过学习得到的,即在反向传播的时候也进行学习。

训练的时候:
1、先将每一层的输入xk经过变换变为yk,然后在反向传播梯度的时候将γ和β也当做网络的参数进行学习,最后得到一个固定参数的训练好的模型
2、在进行预测时,先对每一层所有mini_batch的输入取平均值和方差,然后再对输入进行11中的公式运算来得到BN层的输出。
四、ScratchDet
作者分别分三部分测试了BN层对从零开始训练SSD的影响:在backbone中引入BN,在检测网络中引入BN和在backbone和检测网络中都引入BN

五、Root-ResNet
作者发现相比于VGG,ResNet在加入BN层之后的性能提升并不明显,并指出是因为:第一次卷积层的下采样操作对小物体的检测很不友好,于是提出了一个新的结构Root-ResNet,这也得益于加了BN层之后可以对传统的分类网络进行更大地改动。
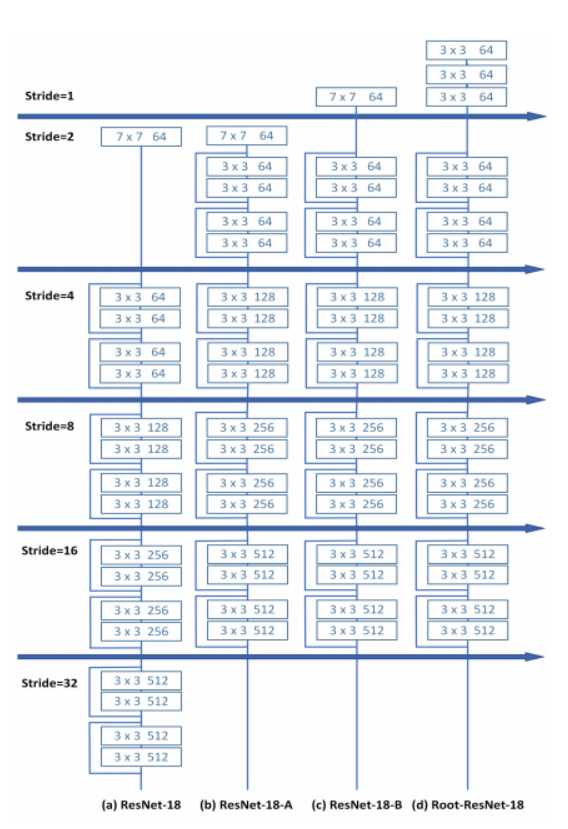
改动有:
1、将原ResNet第一层的下采样操作给去掉了
2、对三个3*3的卷积核代替了原先的7*7的卷积核,作者指出这样可以利用输入图像的更多信息来提取特征
3、用四个残差块取代了SSD中加在检测网络之前的四个卷积块,每个残差块包括两个部分,一部分是一个步长为2的1*1卷积层,另一部分由一个步长为2的3*3卷积层和一个步长为1的3*3的卷积层组成。作者指出这样可以在不损失性能的同时提升参数利用和计算的效率。
以上是关于ScratchDet by hs的主要内容,如果未能解决你的问题,请参考以下文章
hive order by sort by distribute by和sort by一起使用 cluster by
Hive之cluster by , distribute by,order by,sort by
Hive中order by,sort by,distribute by,cluster by的区别
Hive SORT BY vs ORDER BY vs DISTRIBUTE BY vs CLUSTER BY