Hive之cluster by , distribute by,order by,sort by
Posted 健哥说编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive之cluster by , distribute by,order by,sort by相关的知识,希望对你有一定的参考价值。
order by,sort by ,distrubute by , cluster by
首先,可以通过以下语句,来修改reduce的个数,默认为-1由hive自行决定。
hive (db01)> set mapred.reduce.tasks=2;
先将reduce个数设置为2:
hive (db01)> set mapred.reduce.tasks;
mapred.reduce.tasks=2
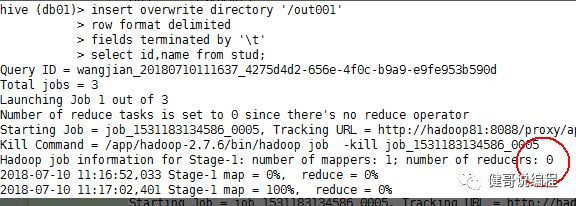
将数据导出,可见,直接将数据导出时,默认的reduce个数为0:
数据:
hive (db01)> select * from stud;
OK
ID NAME
1Jack
2Mary
3Alex
4Mark
5Rose
1、order by
Hive中的order by跟传统的sql语言中的order by作用是一样的,会对查询的结果做一次全局排序,所以说,只有hive的sql中制定了order by所有的数据都会到同一个reducer进行处理(不管有多少map,也不管文件有多少的block只会启动一个reducer)。但是对于大量数据这将会消耗很长的时间去执行。
这里跟传统的sql还有一点区别:如果指定了hive.mapred.mode=strict(默认值是nonstrict),这时就必须指定limit来限制输出条数,原因是:所有的数据都会在同一个reducer端进行,数据量大的情况下可能不能出结果,那么在这样的严格模式下,必须指定输出的条数。
设置为reduce个数为:2
hive (db01)> set mapred.reduce.tasks=2;
SQL语句,并指定order by关键字:
insert overwrite directory '/out001'
row format delimited
fields terminated by '\t'
select id,name from stud order by id;
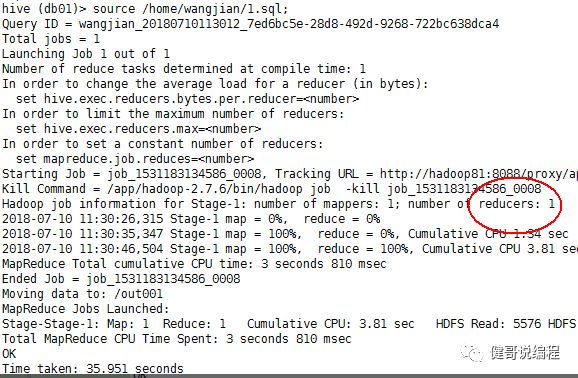
以下执行显示,虽然设置了mapred.reduce.tasks=2,但还是只有一个reduce。
2、sort by
Hive中指定了sort by,那么在每个reducer端都会做排序,也就是说保证了局部有序(每个reducer出来的数据是有序的,但是不能保证所有的数据是有序的,除非只有一个reducer),好处是:执行了局部排序之后可以为接下去的全局排序提高不少的效率(其实就是做一次归并排序就可以做到全局排序了)。
设置为reduce个数为:2
hive (db01)> set mapred.reduce.tasks=2;
现在将上面的order by 修改成sort by :
insert overwrite directory '/out001'
row format delimited
fields terminated by '\t'
select id,name from stud sort by id;
修改以后,再执行,现在有两个reduer,如下所示:
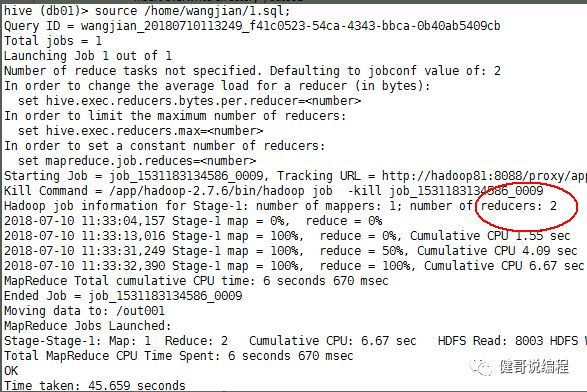
查看输出的文件,也确实有两个:
[wangjian@hadoop81 ~]$ hdfs dfs -ls /out001;
Found 2 items
-rwxr-xr-x 1 wangjian supergroup 28 2018-07-10 11:33 /out001/000000_0
-rwxr-xr-x 1 wangjian supergroup 7 2018-07-10 11:33 /out001/000001_0
查看里面的内容:
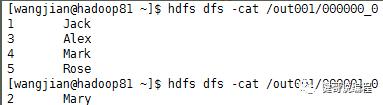
3、distribute by和sort by一起使用
hive中的distribute by是控制在map端如何拆分数据给reduce端的。
hive会根据distribute by后面列,根据reduce的个数进行数据分发,默认是采用hash算法。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
先来看一个只有distribute的示例:
设置为reduce个数为:2
hive (db01)> set mapred.reduce.tasks=2;
SQL语句,注意最后使用distribute by:
insert overwrite directory '/out001'
row format delimited
fields terminated by '\t'
select id,name from stud distribute by id;
执行:
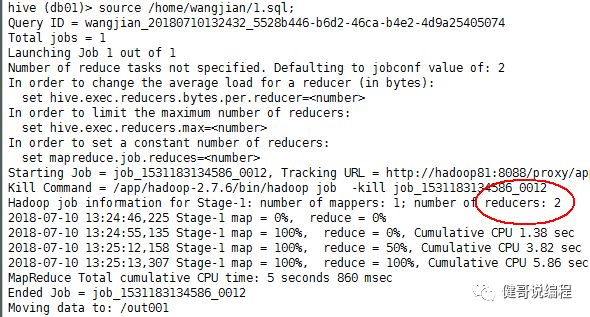
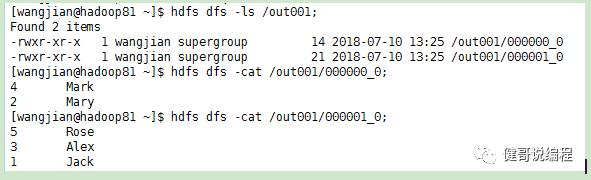
查看hdfs上的数据:
Distribute by 和 sort by共同使用
Distribute by 决定根据哪一个列将数据放到不同的reduce中,而sort by 用于指定每一个reduce的排序规则。
设置为reduce个数为:2
hive (db01)> set mapred.reduce.tasks=2;
SQL语句:
insert overwrite directory '/out001'
row format delimited
fields terminated by '\t'
select id,name from stud distribute by id
sort by id asc;
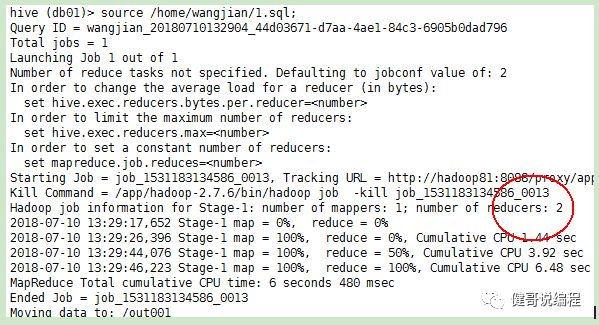
查看数据:
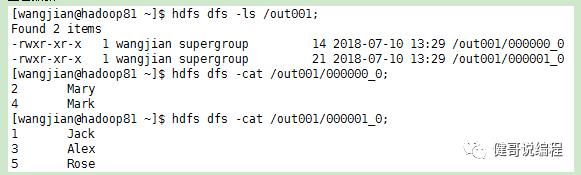
通过上面的数据可以看出,每一个reduce的输出已经根据id排序。
4、cluster by
Cluster by 的功能,就是distribute by 加 sort by的结合 。注意cluster by 指定的列只能是降序。
设置为reduce个数为:2
hive (db01)> set mapred.reduce.tasks=2;
SQL语句,注意cluster by后面只能是0或是1,然后根据hash值放到不同的文件中:
insert overwrite directory '/out001'
row format delimited
fields terminated by '\t'
select id,name from stud
cluster by pmod(id,2);
执行,由于设置为两个reduce所以,可以看到输出的结果为两个:
查看结果:
小结:
Order by : 全排序。
Sort by : Reduce排序。
Distribute by : 对distribute by后面值进行hash以后放到不同的reduce中。
Cluster by : distribute by 加sort by的结合。
以上是关于Hive之cluster by , distribute by,order by,sort by的主要内容,如果未能解决你的问题,请参考以下文章