U2-net网络详解
Posted SL1029_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了U2-net网络详解相关的知识,希望对你有一定的参考价值。
学习视频:U2Net网络结构讲解_哔哩哔哩_bilibili
论文名称:U2-Net: Goging Deeper with Nested U-Structure forSalient Object Detetion
论文下载地址:https://arxiv.org/abs/2005.09007
官方源码(Pytorch实现):https://github.com/xuebinqin/U-2-Net
介绍
U2-net是阿尔伯塔大学(University of Alberta)在2020年发表在CVPR上的一篇文章。该文章中提出的U2-net是针对Salient ObjectDetetion(SOD)即显著性目标检测任务提出的。而显著性目标检测任务与语义分割任务非常相似,只不过显著性目标检测任务是二分类任务,它的任务是将图片中最吸引人的目标或区域分割出来,故只有前景和背景两类。


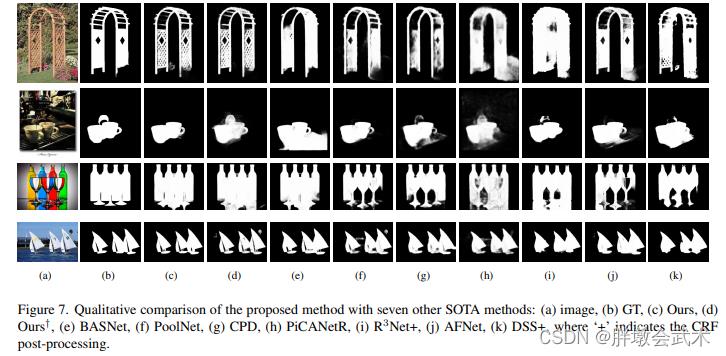
如上图,是这个任务结果比较
第一列为原始图像,第二列为GT,第三列为U2-net的结果、第四列为轻量级的U2-net结果,其他列为其他比较主流的显著性目标检测网络模型,可以看到不管是U2-net还是轻量级U2-net结果都比其他模型更出色。

一、前言

SOD任务是将图片中最吸引人的目标或者区域分割出来,这相当于语义分割中的二分类任务
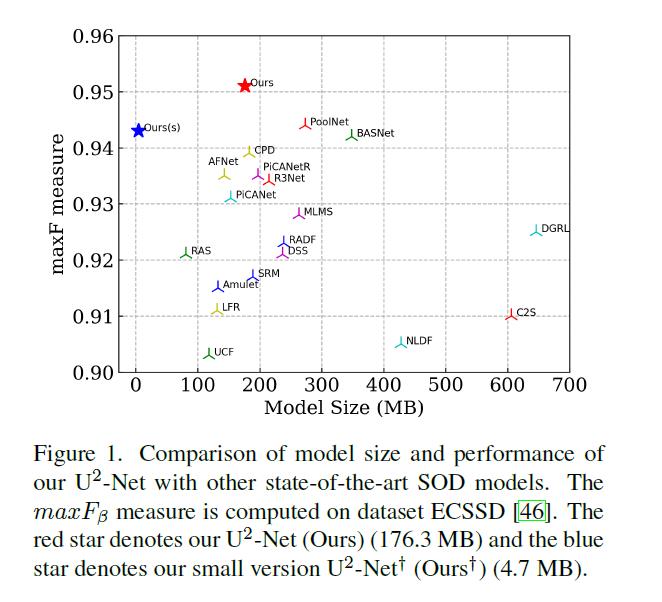
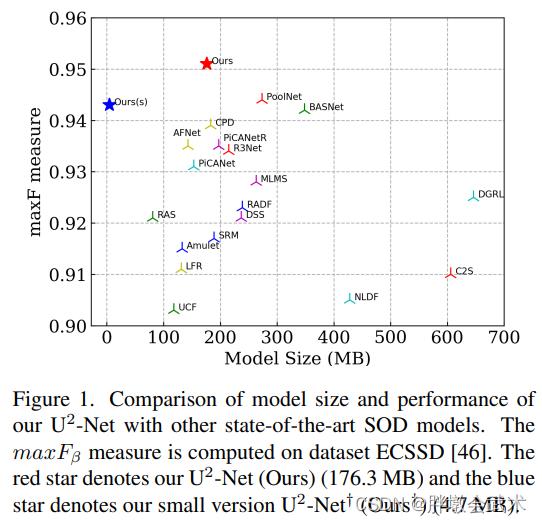
这是一张在ECSSD数据集上比较U2-net与其他主流模型的结果图,主要比较累模型的大小以及MaxF measure指标

通过对比能发现U2-net不管在模型大小还是maxF measure效果都很好,图中红色星为标准的模型,蓝色星的为轻量级的模型
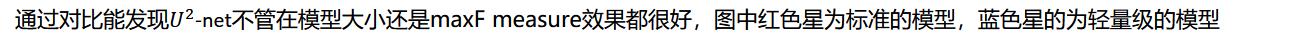
二、网络结构解析
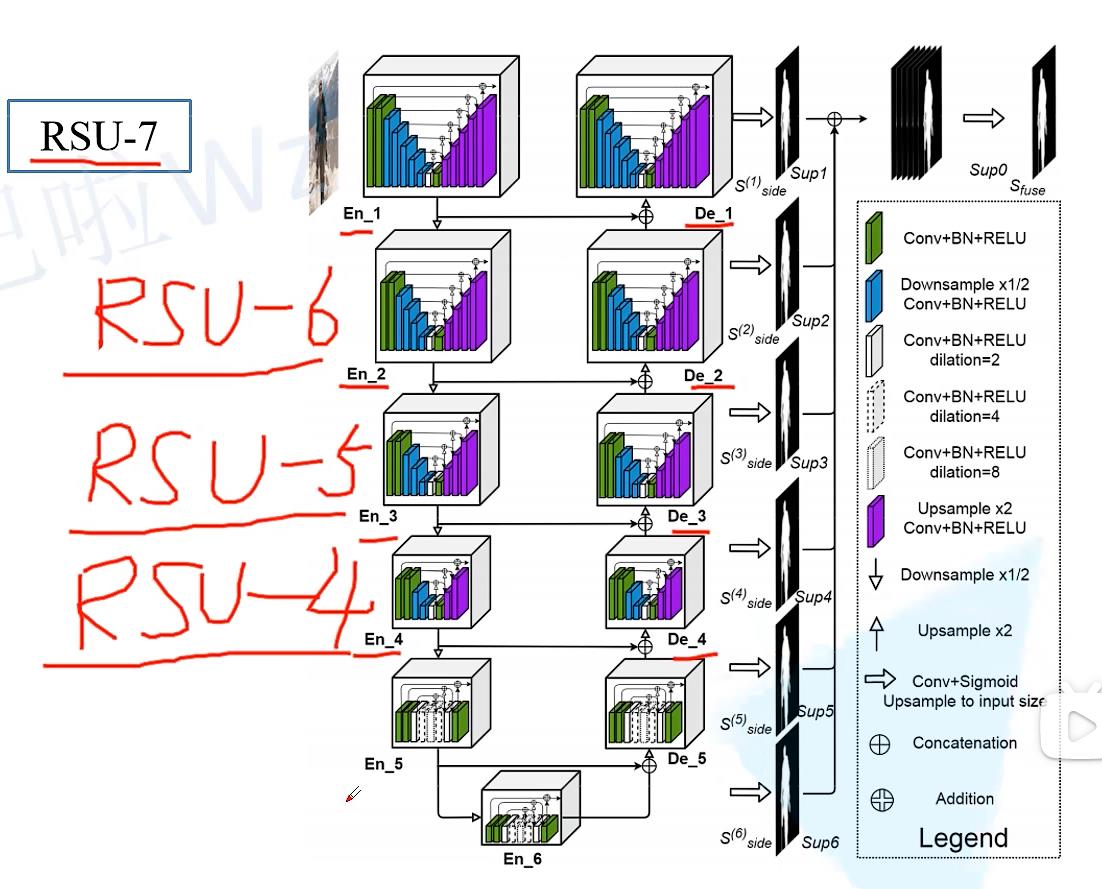
如图所示,网络结构为大型的U-net结构的每一个block里面也为U-net结构,因此称为ᵄ82-net结构

在原文中作者称每一个block为ReSidual U-block
图中block其实分为两种,一种是Encoder1到Encoder4加上Decoder1到Decoder4这八个结构相似,Encoder5与Encoder6,Decoder5又是另外一种结构。
第一种block
在Encoder阶段,每通过一个block后都会通过最大池化层下采样2倍,在Decoder阶段,通过每一个block前都会用双线性插值进行上采样
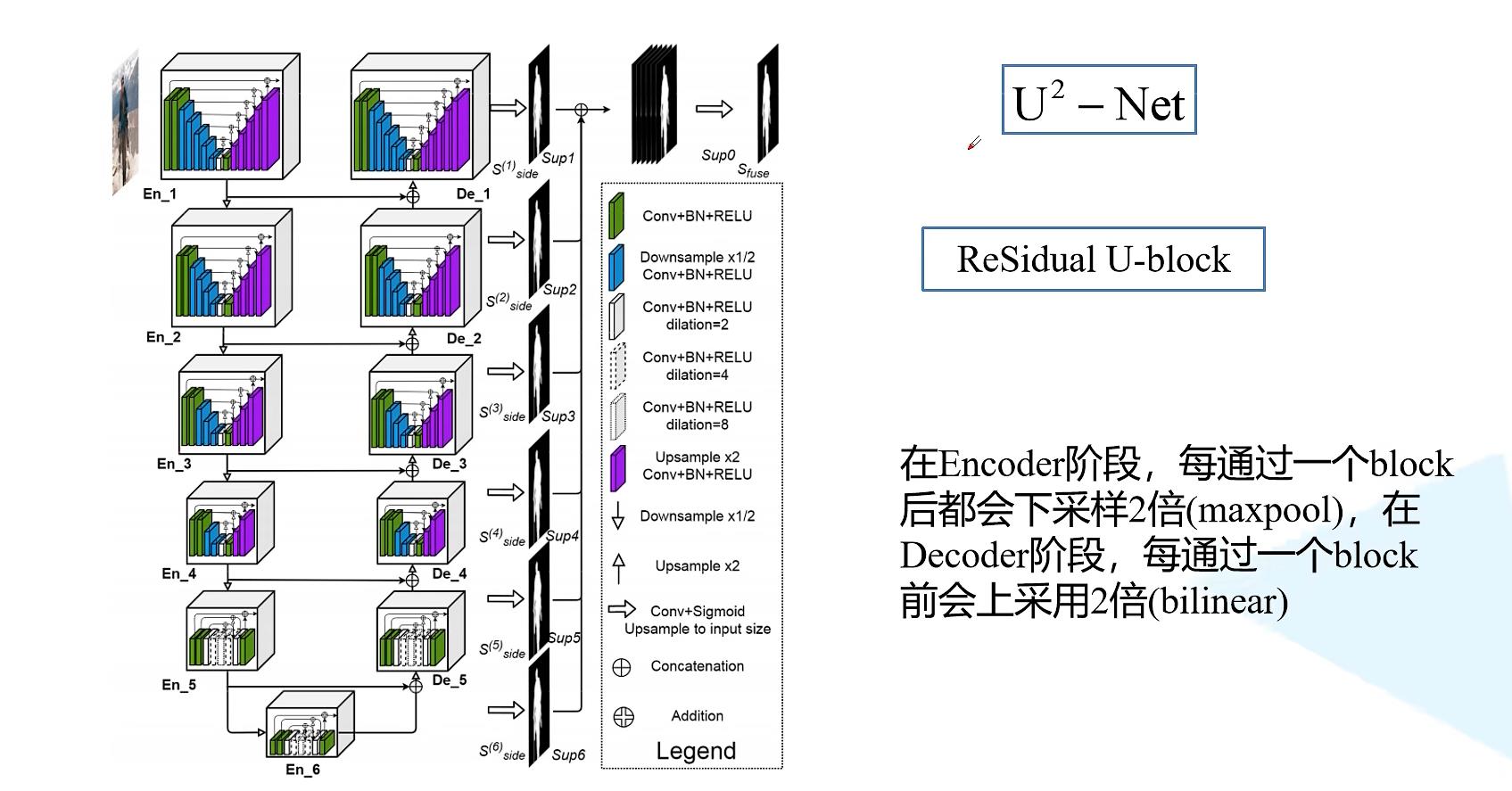
论文作者给出了block的结构,如下图
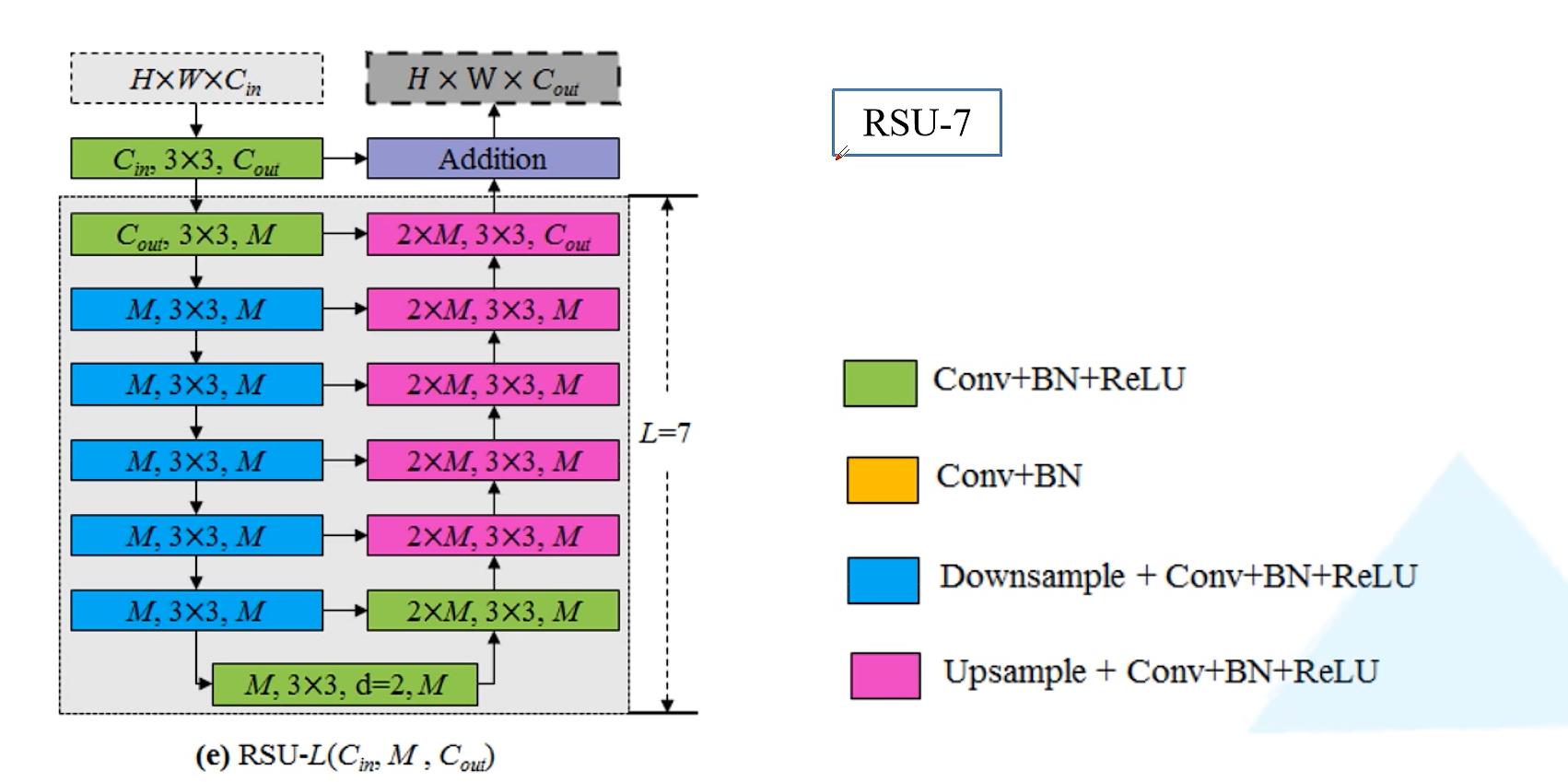
这个block称为RSU-7,7是因为有7层,绿色代表卷积+BN+ReLU,蓝色代表下采样+卷积+BN+ReLU,紫色代表上采样+卷积+BN+ReLU,在RSU-7中下采样了5次,也即把输入特征图下采样了32倍,同样在Decoder阶段上采样了32倍还原为原始图像大小。
下图为视频作者为了更清楚的解释RSU-7,重新绘制了它的结构,重新加入了shape这个特征,让结构更加清晰,具体细节可以参考U-net网络。
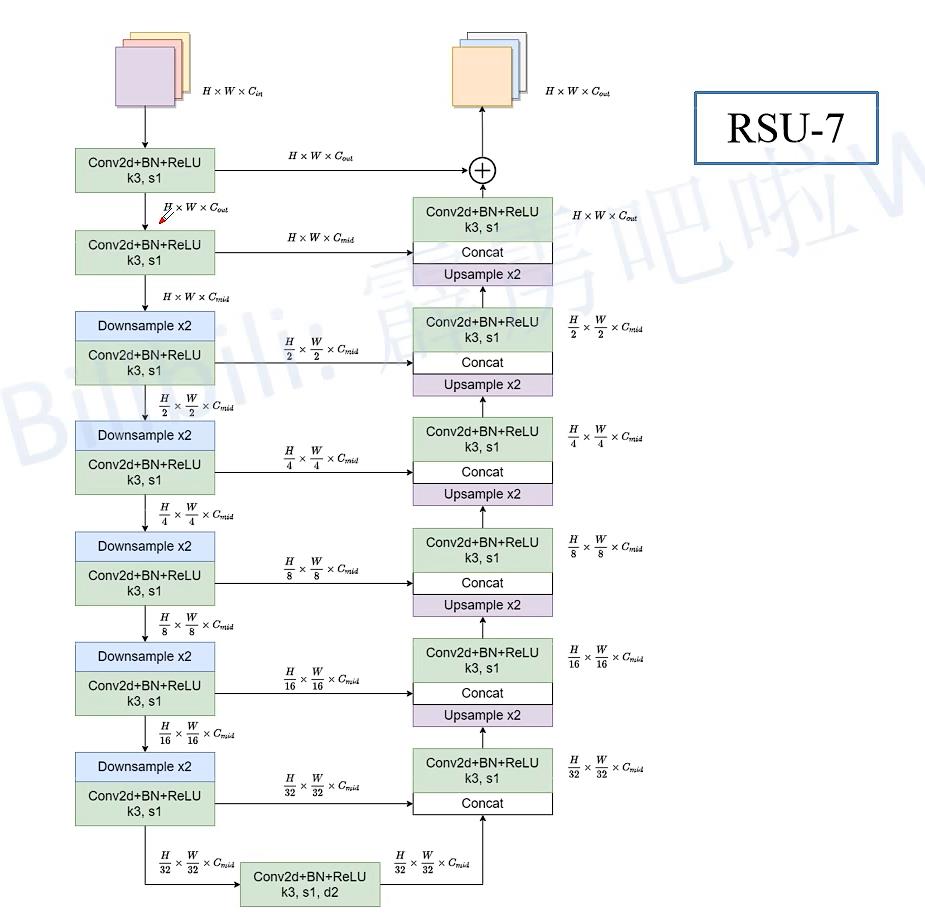
事实上RSU-7对应的是整体网络结构中的Encoder1和Decoder1,RSU-6对应的是整体网络结构中的Encoder2和Decoder2,RSU-5对应的是整体网络结构中的Encoder3和Decoder3,RSU-4对应的是整体网络结构中的Encoder4和Decoder4(如下图所示),相邻block差的是一次下采样和上采样,例如RSU-7里面是下采样32倍和上采样32倍,RSU-6是上采样16倍和下采样16倍。
第二种block
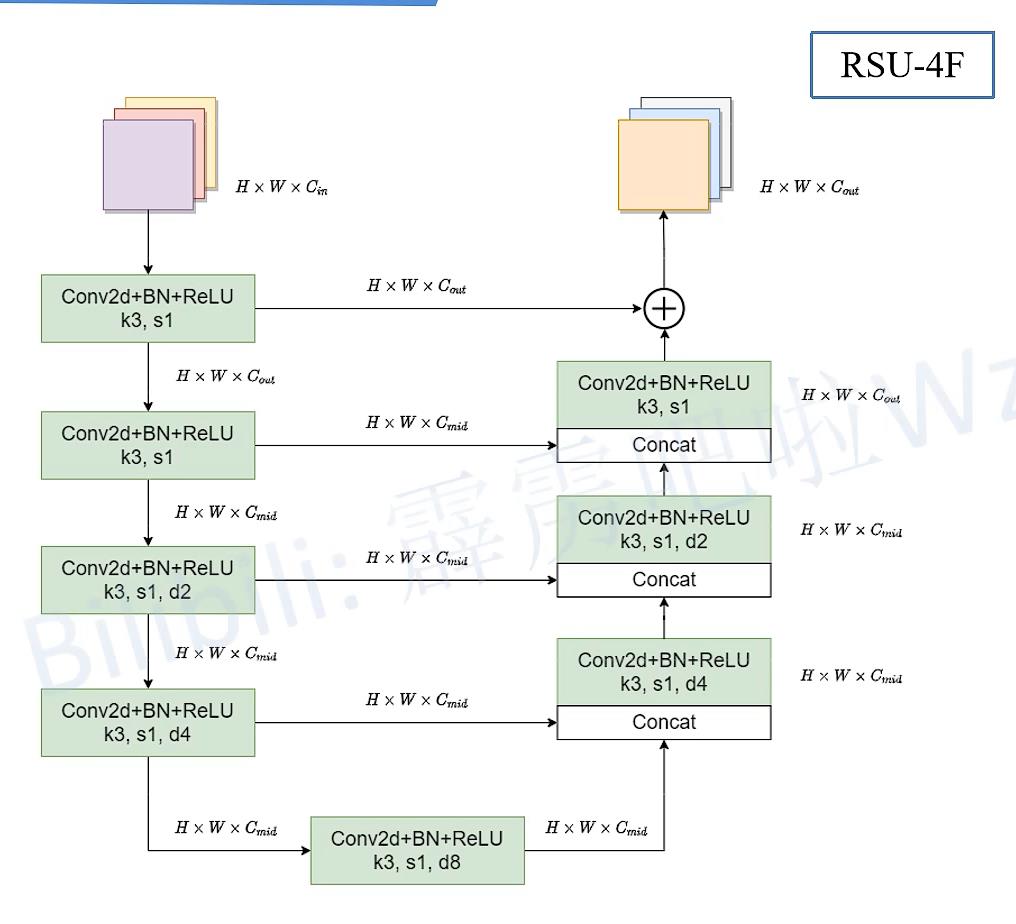
Encoder5和Decoder5,Encoder6使用是这个第二种block,由于经过了几次下采样,原图已经很小了,所以不再进行下采样,若再进行下采样,恐怕会丢失很多信息,这个block称为RSU-4F,主要是再RSU-4的基础上,将下采样和上采样换成了膨胀卷积,整个过程中特征图大小不变。
最后
将每个阶段的特征图进行融合,主要是收集Decoder1、Decoder2、Decoder3、Decoder4、Decoder5、Encoder6的输出结果,对他们做3*3的卷积,卷积核个数为1,再用线性插值进行上采样恢复到原图大小,进行concat拼接,使用sigmoid函数输出最终分割结果。
三、损失计算

如图,为计算的损失公式,在这里M=6,表示Decoder1、Decoder2、Decoder3、Decoder4、Decoder5、Encoder6有六个输出,Wfuse代表的是最终的预测概率图的损失
四、评价准则

如图为显著性目标检测的评价指标
Precision(精准度)
Recall(召回率)
Precision和Recall往往是一对矛盾的性能度量指标;
提高Precision == 提高二分类器预测正例门槛 == 使得二分类器预测的正例尽可能是真实正例;
提高Recall == 降低二分类器预测正例门槛 == 使得二分类器尽可能将真实的正例挑选出来;
precision代表准,recall代表全
五、DUTs数据集
DUTs数据集简介:

Pytorch项目实战之语义分割:U-NetUNet++U2Net
文章目录
博主精品专栏导航
- 🍕 【Pytorch项目实战目录】算法详解 + 项目详解 + 数据集 + 完整源码
- 🍔 【sklearn】线性回归、最小二乘法、岭回归、Lasso回归
- 🥘 三万字硬核详解:yolov1、yolov2、yolov3、yolov4、yolov5、yolov7
- 🍰 卷积神经网络CNN的发展史
- 🍟 卷积神经网络CNN的实战知识
- 🍝 Pytorch基础(全)
- 🌭 Opencv图像处理(全)
- 🥙 Python常用内置函数(全)
一、前言
1.1、什么是图像分割?
对图像中属于特定类别的像素进行分类的过程,即逐像素分类。
- 图像分类:识别图像中存在的内容。
- 目标检测:识别图像中的内容和位置(通过边界框)。
- 语义分割:识别图像中存在的内容以及位置(通过查找属于它的所有像素)。
(1)传统的图像分割算法:灰度分割,条件随机场等。
(2)深度学习的图像分割算法:利用卷积神经网络,来理解图像中的每个像素所代表的真实世界物体。

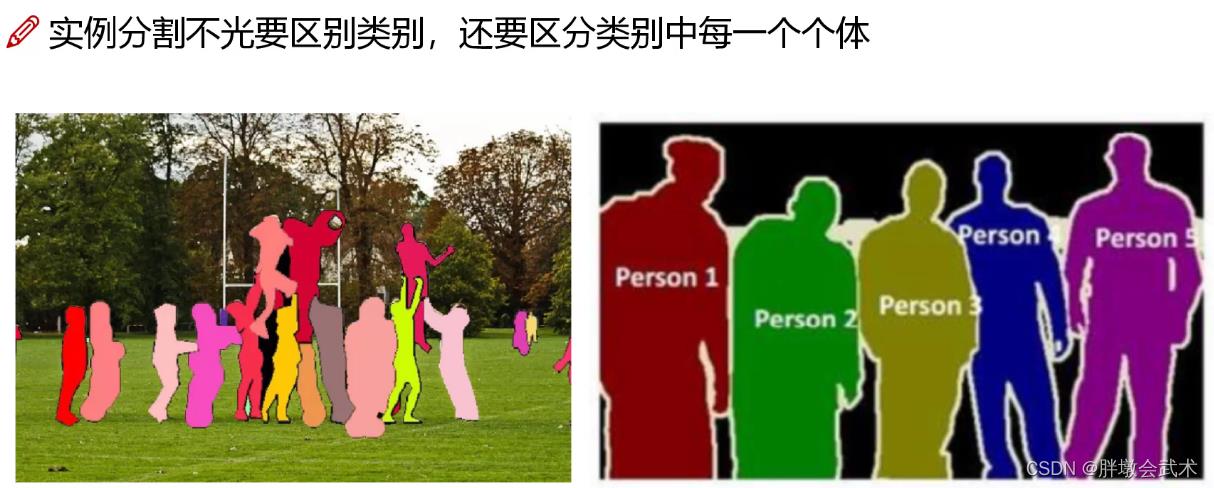
1.2、语义分割与实例分割的区别
基于深度学习的图像分割技术主要分为两类:语义分割及实例分割。
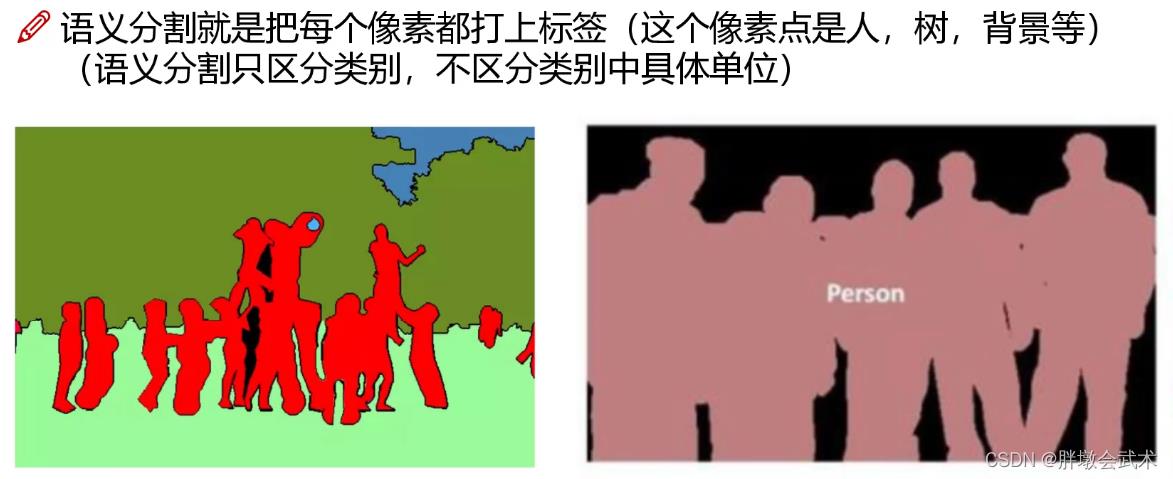
语义分割(Semantic Segmentation):对图像中的每个像素点都进行分类预测,得到像素化的密集分类。然后提取具有感兴趣区域Mask。
- 特点:语义分割只能判断类别,无法区分个体。(只能将属于人的像素位置分割出来,但是无法分辨出图中有多少个人)
实例分割(Instance Segmentation):不需要对每个像素点进行标记,只需要找到感兴趣物体的边缘轮廓即可。
- 详细过程:即同时利用目标检测和语义分割的结果,通过目标检测提供的目标最高置信度类别的索引,将语义分割中目标对应的Mask抽取出来。
- 区别:目标检测输出目标的边界框和类别,实例分割输出的是目标的Mask和类别。
- 特点:可以区分个体。 (可以区分图像中有多少个人,不同人的轮廓都是不同颜色)
1.3、语义分割的上下文信息
- 上下文:指的是图像中的每一个像素点不可能是孤立的,一个像素一定和周围像素是有一定的关系的,大量像素的互相联系才产生了图像中的各种物体。
- 上下文特征:指像素以及周边像素的某种联系。 即在判断某一个位置上的像素属于哪种类别的时候,不仅考察到该像素的灰度值,还充分考虑和它临近的像素。
1.4、语义分割的网络架构
一个通用的语义分割网络结构可以被广泛认为是一个:编码器 - 解码器(Encoder-Decoder)。
- (1)编码器:负责特征提取,通常是一个预训练的分类网络(如:VGG、ResNet)。
- (2)解码器:将编码器学习到的可判别特征(低分辨率)从语义上投影到像素空间(高分辨率),以获得密集分类。
二、网络 + 数据集
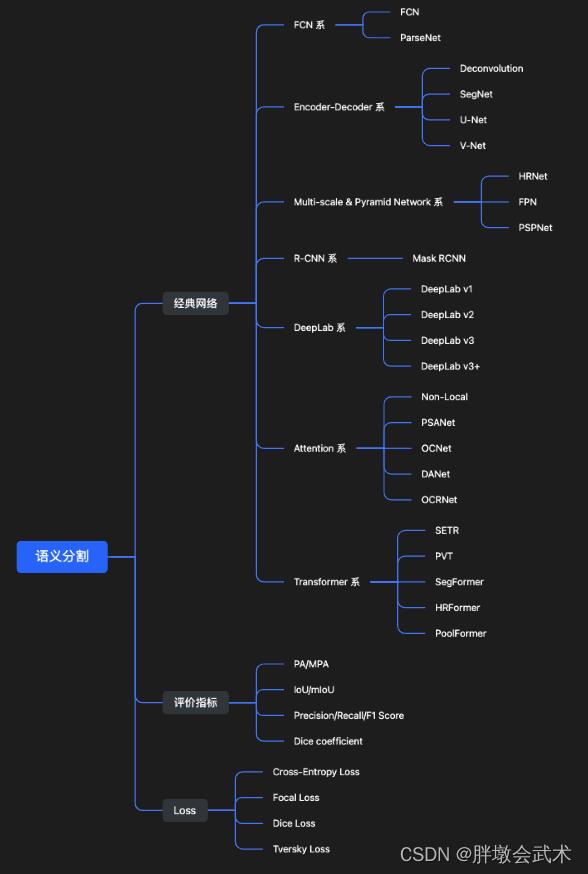
2.1、经典网络的发展史(模型详解)
论文下载:史上最全语义分割综述(FCN、UNet、SegNet、Deeplab、ASPP…)
参考链接:经典网络 + 评价指标 + Loss损失(超详细介绍)
2.2、分割数据集下载
下载链接:【语义分割】FCN、UNet、SegNet、DeepLab
| 数据集 | 简介 |
|---|---|
| CamVid | 32个类别:367张训练图,101张验证图,233张测试图。 |
| PascalVOC 2012 | (1)支持 5 类任务:分类、分割、检测、姿势识别、人体。(2)对于分割任务,共支持 21 个类别,训练和验证各 1464 和 1449 张图 |
| NYUDv2 | 40个类别:795张训练图,645张测试图。 |
| Cityscapes | (1)50个不同城市的街景数据集,train/val/test的城市都不同。(2)包含:5k 精细标注数据,20k 粗糙标注数据。标注了 30 个类别。(3)5000张精细标注:2975张训练图,500张验证图,1525张测试图。(4)图像大小:1024x2048 |
| Sun-RGBD | 37个类别:10355张训练图,2860张测试图。 |
| MS COCO | 91个类别,328k 图像,2.5 million 带 label 的实例。 |
| ADE20K | 150个类别,20k张训练图,2k张验证图。 |
三、算法详解
3.1、U-Net
论文地址:U-Net:Convolutional Networks for Biomedical Image Segmentation
论文源码:论文源码已开源,可惜是基于MATLAB的Caffe版本。 U-Net的实验是一个比较简单的ISBI cell tracking数据集,由于本身的任务比较简单,U-Net紧紧通过30张图片并辅以数据扩充策略便达到非常低的错误率,拿了当届比赛的冠军。
Unet 发表于 2015 年,属于 FCN 的一种变体,是一个经典的全卷积神经网络(即没有全连接层)。采用编码器 - 解码器(下采样 - 上采样)的对称U形结构和跳跃连接结构。
- 全卷积神经网络(FCN)是图像分割的开天辟地之作。
- 为什么引入FCN:CNN浅层网络得到图像的纹理特征,深层得到轮廓特征等,但无法做到更精细的分割(像素级)。为了弥补这一缺陷,引入FCN。
- FCN与CNN的不同点:FCN将CNN最后的全连接层替换为卷积层,故FCN可以输入任意尺寸的图像。
- 而U-Net的初衷是为了解决生物医学图像问题。由于效果好,也被广泛的应用在卫星图像分割,工业瑕疵检测等。目前已有许多新的卷积神经网络设计方法,但仍延续了U-Net的核心思想。
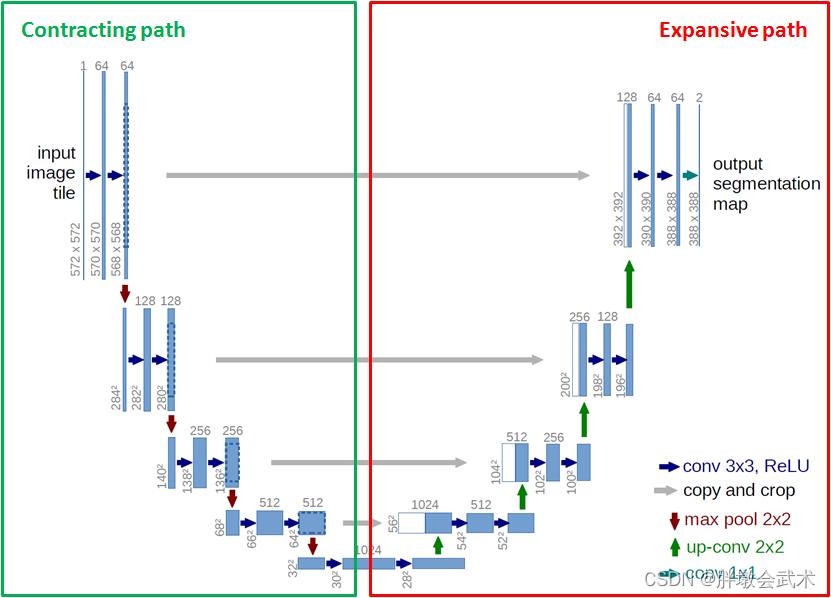
3.1.1、网络框架(U形结构+跳跃连接结构)
具体过程:
- 输入图像大小为572 x 572。FCN可以输入任意尺寸的图像,且输出也是图像。
- (1)压缩路径(Contracting path):由4个block组成,每个block使用2个(conv 3x3,ReLU)和1个MaxPooling 2x2。
- 每次降采样之后的Feature Map的尺寸减半、数量翻倍。经过四次后,最终得到32x32的Feature Map。
- (2)扩展路径(Expansive path):由4个block组成,每个block使用2个(conv 3x3,ReLU)和1个反卷积(up-conv 2x2)。
- 11、每次上采样之后的Feature Map的尺寸翻倍、数量减半。
- 22、跳跃连接结构(skip connections):将左侧对称的压缩路径的Feature Map进行拼接(copy and crop)。由于左右两侧的Feature Map尺寸不同,将压缩路径的Feature Map裁剪到和扩展路径的Feature Map相同尺寸(左:虚线裁剪。右:白色块拼接)。
- 33、逐层上采样 :经过四次后,得到392X392的Feature Map。
- 44、卷积分类:再经过两次(conv 3x3,ReLU),一次(conv 1x1)。由于该任务是一个二分类任务,最后得到两张Feature Map(388x388x2)。
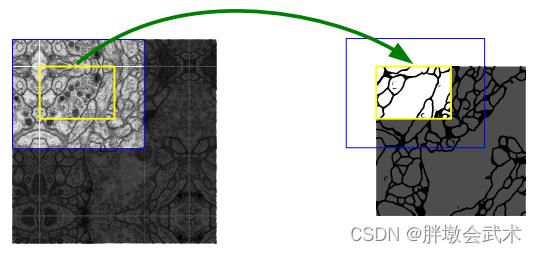
3.1.2、镜像扩大(保留边缘信息)
在不断的卷积过程中,图像会越来越小。为了避免数据丢失,在模型训练前,每一小块的四个边需要进行镜像扩大(不是直接补0扩大),以保留更多边缘信息。
由于当时计算机的内存较小,无法直接对整张图片进行处理(医学图像通常都很大),会采取把大图进行分块输入的训练方式,最后将结果一块块拼起来。
3.1.3、数据增强(变形)
医学影像数据普遍特点,就是样本量较少。当只有很少的训练样本可用时,数据增强对于教会网络所需的不变性和鲁棒性财产至关重要。
- 对于显微图像,主要需要平移和旋转不变性,以及对变形和灰度值变化的鲁棒性。特别是训练样本的随机弹性变形,是训练具有很少注释图像的关键。
- 在生物医学分割中,变形是组织中最常见的变化,并且可以有效地模拟真实的变形。
论文中的具体操作:使用粗糙的3乘3网格上的随机位移向量生成平滑变形。位移从具有10像素标准偏差的高斯分布中采样。然后使用双三次插值计算每个像素的位移。收缩路径末端的丢弃层执行进一步的隐式数据扩充。

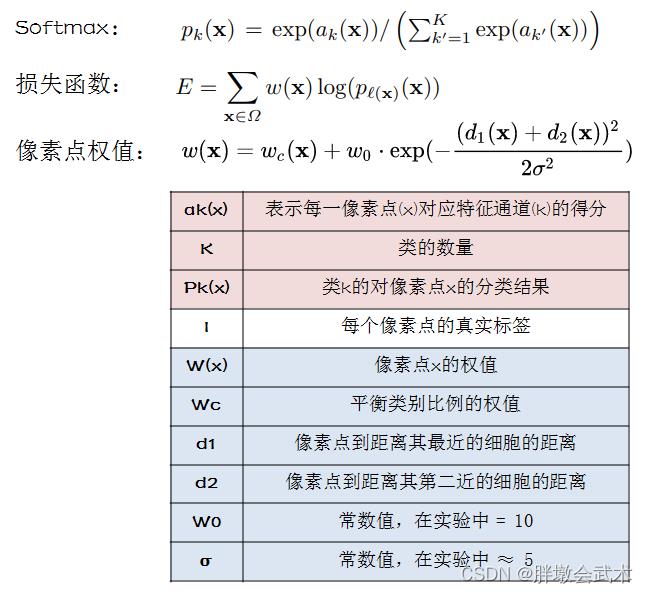
3.1.4、损失函数(交叉熵)
论文的相关配置:Caffe框架,SGD优化器,每个batch一张图片,动量=0.99,交叉熵损失函数。
3.1.5、性能表现
用DIC(微分干涉对比)显微镜记录玻璃上的HeLa细胞。
(a) 原始图像。
(b) 覆盖地面真实分割。不同的颜色表示HeLa细胞的不同实例。
(c) 生成的分割掩码(白色:前景,黑色:背景)。
(d) 使用像素级损失权重映射,以迫使网络学习边界像素。

3.2、UNet++
论文地址:UNet++:A Nested U-Net Architecture for Medical Image Segmentation
UNet++ 发表于 2018 年,基于U-Net,采用一系列嵌套的密集的跳跃连接结构,并通过深度监督进行剪枝。
- UNet++的初衷是为了解决 " U-Net对病变或异常的医学图像缺乏更高的精确性 " 问题。
3.2.1、网络框架(U型结构+密集跳跃连接结构)
黑、红、绿、蓝色的组件将UNet++与U-Net区分开来。【语义分割】UNet++
- 黑色:U-Net网络
- 红色:深度监督(deep supervision)。可以进行模型剪枝 (model pruning)
- 绿色:在跳跃连接(skip connections)设置卷积层,在 Encoder 和 Decoder 网络之间架起语义鸿沟。
- 蓝色:一系列嵌套的密集的跳跃连接,改善了梯度流动。
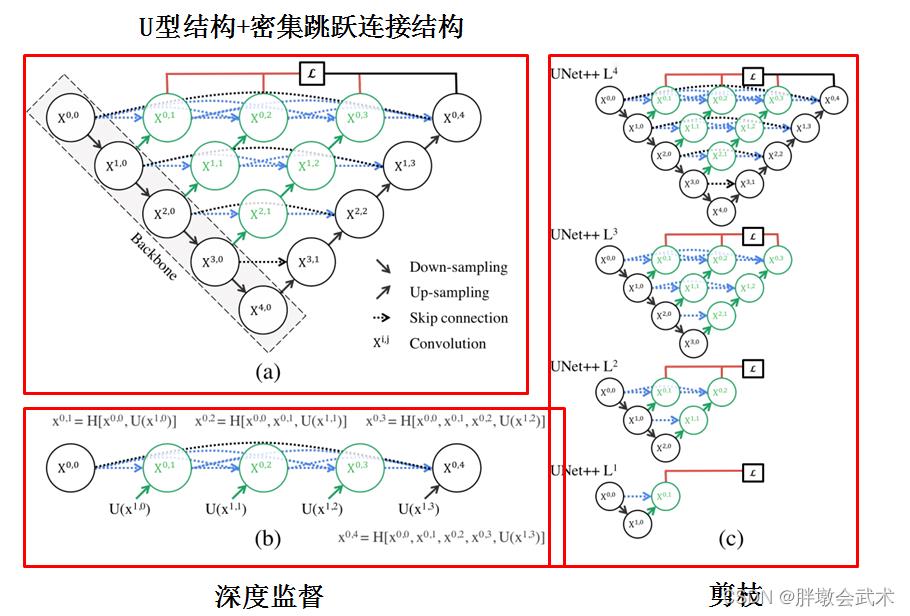
3.2.2、改进的跳跃连接结构(融合+拼接)
Encoder 网络通过下采样提取低级特征;Decoder 网络通过上采样提取高级特征。
- U-Net 网络:(作者认为会产生语义鸿沟)
- 特点:跳跃连接,又叫长连接或直接跳跃连接。将左右两边对称的特征图通过裁剪的方式进行拼接,有助于还原降采样所带来的信息损失(与残差块非常类似)。
- 缺点:裁剪将导致图像的深层细节丢失(如:人的毛发、小瘤附近的微刺等),影响细胞的微小特征(如:小瘤附近的微刺,可能预示着恶性瘤)。
- UNet++网络:
- 特点:一系列嵌套的,密集的跳跃连接。包括L1、L2、L3、L4四个U-Net网络,分别抓取浅层到深层特征。将左右两边对称的特征图先融合,再拼接,进而可以获取不同层次的特征。
【备注】不同大小的感受野,对不同大小的目标,其敏感度也不同,获取图像的特征也不同。浅层(小感受野)对小目标更敏感;深层(大感受野)对大目标更敏感。
3.2.3、深度监督Deep supervision(剪枝)
此概念在对 U-Net 改进的多篇论文中都有使用,并不是该论文首先提出。
在结构
后加上1x1卷积,相当于去监督每个分支的 U-Net 输出。在深度监督中,因为每个子网络的输出都是图像分割结果,所以通过剪枝使得网络有两种模式。
- (1)精确模式:对所有分割分支的输出求平均值
- (2)快速模式:从所有分割分支中选择一个分割图。剪枝越多参数越少,在不影响准确率的前提下,剪枝可以降低计算时间。
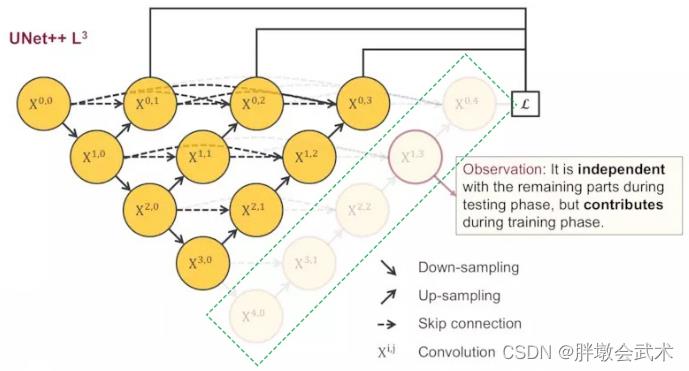
(1)为什么可以剪枝?
- 测试阶段:输入图像只有前向传播,剪掉部分对前面的输出完全没有影响;
- 训练阶段:输入图像既有前向,又有反向传播,剪掉部分对剩余部分有影响 (绿色方框为剪掉部分) ,会帮助其他部分做权重更新。
(2)为什么要在测试时剪枝,而不是直接拿剪完的L1、L2、L3训练?
- 剪掉的那部分对训练时的反向传播时时有贡献的,如果直接拿L1、L2、L3训练,就相当于只训练不同深度的U-NET,最后的结果会很差。
(3)如何进行剪枝?
- 将数据分为训练集、验证集和测试集。
训练集是需要训练的,测试集是不能碰的,所以根据选择的子网络在验证集的结果来决定剪多少。
3.2.4、损失函数

3.2.5、性能表现
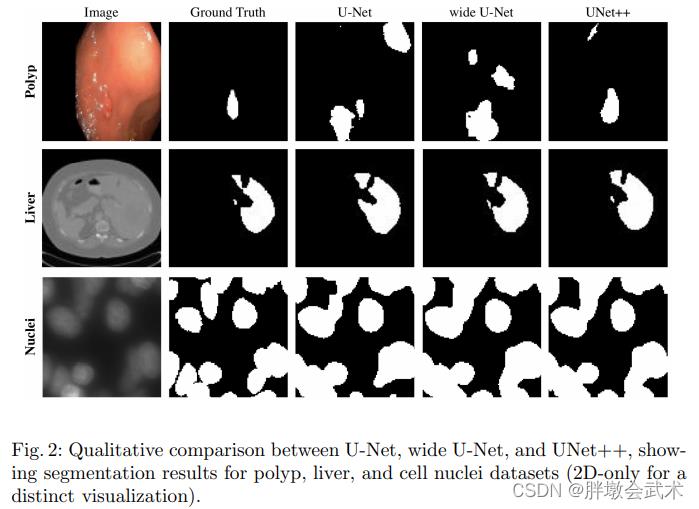
如图显示:U-Net、宽U-Net和UNet++结果之间的定性比较。
如图显示:U-Net、宽U-Net和UNet++(在肺结节分割、结肠息肉分割、肝脏分割和细胞核分割任务中)的数量参数和分割精度。
- 结论:
(1)宽U-Net始终优于U-Net,除了两种架构表现相当的肝脏分割。这一改进归因于宽U-Net中的参数数量更大。
(2)在没有深度监督的情况下,UNet++比UNet和宽U-Net都取得了显著的性能提升,IoU平均提高了2.8和3.3个点。
(3)与没有深度监督的UNet++相比,具有深度监督的UNet++平均提高0.6分。
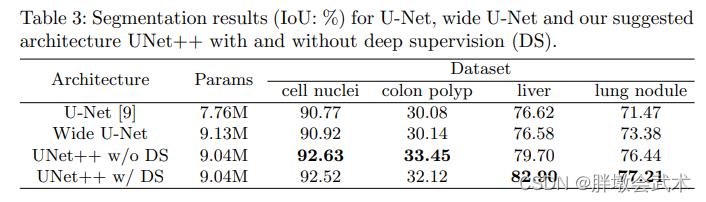
如图显示:在不同级别处修剪的UNet++分割性能。使用 UNet++ Li 表示在级别 i 处修剪的UNet++。
- 结论:UNet++ L3平均减少了32.2%的推断时间,同时仅将IoU降低了0.6个点。更积极的修剪进一步减少了推断时间,但代价是显著的精度降低。
3.3、U2-Net
论文地址:U2-Net:Going Deeper with Nested U-Structure for Salient Object Detection
代码下载:U2-Net-master
U2-Net 于 2020 年在CVPR上发表 ,主要针对显著性目标检测任务提出(Salient Object Detetion,SOD)。
显著性目标检测任务与语义分割任务非常相似,其是二分类任务,将图像中最吸引人的目标或区域分割出来,故只有前景和背景两类。
第一列为原始图像,第二列为GT,第三列为U2-net结果、第四列为轻量级U2-net结果,其他列为其他比较主流的显著性目标检测网络模型。
- 结论:无论是U2-net,还是轻量级U2-net,结果都比其他模型更出色。
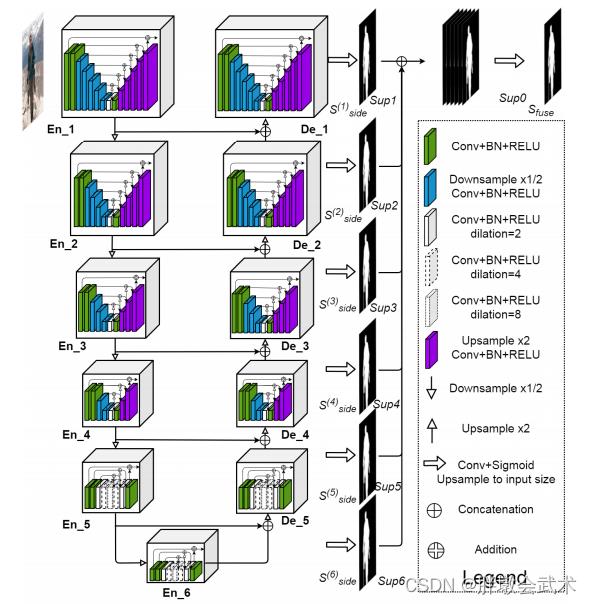
U2-Net 基于 U-Net 提出了一种残余U形块(ReSidual U-blocks,RSU)结构。每个RSU就是一个缩版的 U-net,最后通过FPN的跳跃连接构建完整模型。
- U2-Net 中的每一个block里面也是 U-Net,故称为 U2-Net 结构
- 经过测试,对于分割物体前背景取得了惊人的效果。同样具有较好的实时性,经过测试在P100上前向时间仅为18ms(56fps)。
3.3.1、网络框架(RSU结构+U型结构+跳跃连接结构)
U2-Net包括6个编码器+5个解码器。除编码器En-6,其余的模型都是对称结构。通过跳跃连接结构进行特征拼接,并得到7个基于深度监督的损失值(Sup6-Sup0)。(6个block输出结果、1个特征融合后的结果)
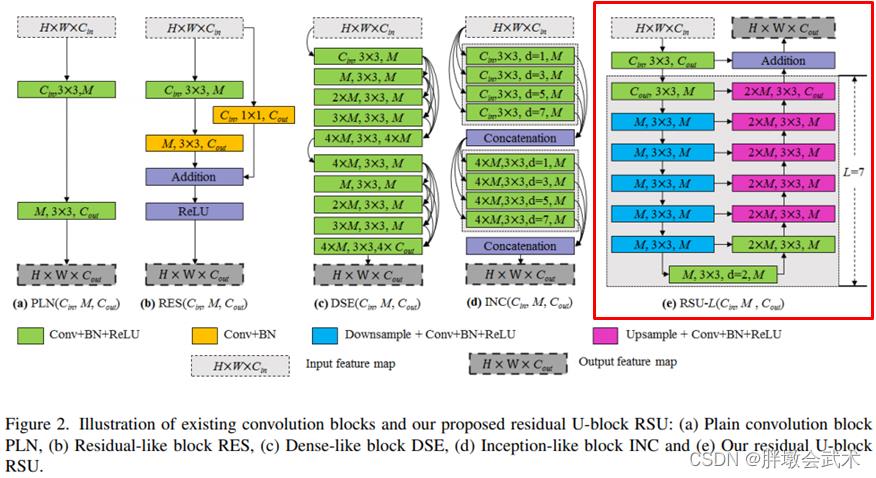
3.3.2、残余U形块RSU
残余U形块RSU与现有卷积块的对比图:
(a)普通卷积块:PLN
(b)残余块:RES
(c)密集块:DSE
(d)初始块:INC
(e)残余U形块:RSU
- RSU:每通过一个block后,Eecoder都会通过最大池化层下采样2倍,Decoder都会采用双线性插值进行上采样。
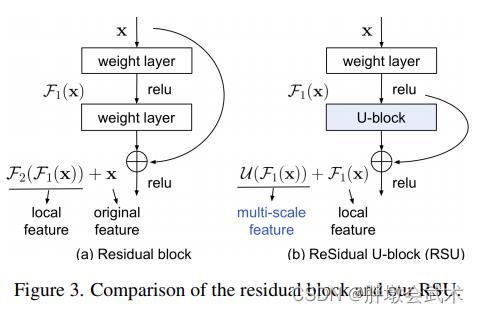
残余U形块RSU与残差模块的对比图:
(1)残差模块的权重层替换为U形模块;
(2)原始特征替换为本地特征;
3.3.3、损失函数(交叉熵)
由于U2net分成了多个block,故每个block都将输出一个loss值。7个loss相加(6个block输出结果、1个特征融合后的结果)
- 公式(1):叠加损失值loss。l表示二值交叉熵损失函数,w表示每个损失的权重。
- 公式(2):采用二值交叉熵损失函数。
在训练过程中,使用类似于HED的深度监督[45]。其有效性已在HED和DSS中得到验证。U2-net网络详解

3.3.4、性能表现
U2-Net与其他最先进SOD模型的模型大小和性能比较。
- maxFβ测量值在数据集ECSSD[46]上计算。红星表示U2-Net(176.3 MB),蓝星表示轻量级U2-Net(4.7 MB)。CVPR2020 U2-Net:嵌套U-结构的更深层次的显著目标检测
四、项目实战
实战一:U-Net(不训练版)
由于模型未训练,故每次运行得到的结果都不同。原因:每次运行的初始化卷积核不同。代码剖析
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from PIL import Image
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"
class Encoder(nn.Module):
def __init__(self, in_channels, out_channels):
super(Encoder, self).__init__()
self.block1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=0), nn.ReLU(inplace=True))
self.block2 = nn.Sequential(nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=0), nn.ReLU(inplace=True))
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x_pooled = self.pool(x)
return x, x_pooled
class Decoder(nn.Module):
def __init__(self, in_channels, out_channels):
super(Decoder, self).__init__()
self.up_sample = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)
self.block1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=0), nn.ReLU(inplace=True))
self.block2 = nn.Sequential(nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=0), nn.ReLU(inplace=True))
def forward(self, x_prev, x):
x = self.up_sample(x) # 上采样
x_shape = x.shape[2:]
x_prev_shape = x.shape[2:]
h_diff = x_prev_shape[0] - x_shape[0]
w_diff = x_prev_shape[1] - x_shape[1]
x_tmp = torch.zeros(x_prev.shape).to(x.device)
x_tmp[:, :, h_diff//2: h_diff+x_shape[0], w_diff//2: x_shape[1]] = x
x = torch.cat([x_prev, x_tmp], dim=1) # 拼接
x = self.block1(x) # 卷积+ReLU
x = self.block2(x) # 卷积+ReLU
return x
class UNet(nn.Module):
def __init__(self, num_classes=2):
super(UNet, self).__init__()
"""
padding=1。 输出图像大小=((572-3 + 2*1) / 1) + 1 = 572 # 卷积前后图像大小不变
padding=0。 输出图像大小=((572-3) / 1) + 1 = 570 # 原论文每次卷积后,图像长宽各减2
"""
"""编码器(4) —— 通道变化[3, 64, 128, 256, 512]"""
self.down_sample1 = Encoder(in_channels=3, out_channels=64)
self.down_sample2 = Encoder(in_channels=64, out_channels=128)
self.down_sample3 = Encoder(in_channels=128, out_channels=256)
self.down_sample4 = Encoder(in_channels=256, out_channels=512)
"""中间过渡层 —— 通道变化512, 1024]"""
self.mid1 = nn.Sequential(nn.Conv2d(512, 1024, 3, bias=False), nn.ReLU(inplace=True))
self.mid2 = nn.Sequential(nn.Conv2d(1024, 1024, 3, bias=False), nn.ReLU(inplace=True))
"""解码器(4) —— 通道变化[1024, 512, 256, 128, 64]"""
self.up_sample1 = Decoder(in_channels=1024, out_channels=512)
self.up_sample2 = Decoder(in_channels=512, out_channels=256)
self.up_sample3 = Decoder(in_channels=256, out_channels=128)
self.up_sample4 = Decoder(in_channels=128, out_channels=64)
"""分类器 —— 通道变化[64, 类别数]"""
self.classifier = nn.Conv2d(64, num_classes, 1)
def forward(self, x):
x1, x = self.down_sample1(x)
x2, x = self.down_sample2(x)
x3, x = self.down_sample3(x)
x4, x = self.down_sample4(x)
x = self.mid1(x)
x = self.mid2(x)
x = self.up_sample1(x4, x)
x = self.up_sample2(x3, x)
x = self.up_sample3(x2, x)
x = self.up_sample4(x1, x)
x = self.classifier(x)
return x
def image_loader(image_path):
"""模型训练前的格式转换:[3, 384, 384] -> [1, 3, 384, 384]"""
image = Image.open(image_path) # 打开图像(numpy格式)
loader = transforms.ToTensor() # 数据预处理(Tensor格式)
image = loader(image).unsqueeze(0) # tensor.unsqueeze():增加一个维度,其值为1。
return image.to(device, torch.float)
def image_trans(tensor):
"""绘制图像前的格式转换:[1, 3, 384, 384] -> [3, 384, 384]"""
image = tensor.clone() # clone():复制
image = torch.squeeze(image, 0) # tensor.squeeze():减少一个维度,其值为1。
unloader = transforms.ToPILImage() # 数据预处理(PILImage格式)
image = unloader(image) # 图像转换
return image
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 可用设备
raw_image = image_loader(r"大黄蜂.jpg") # 导入图像
model = UNet(4) # 模型实例化
new_image = model(raw_image) # 前向传播
print("输入图像维度: ", raw_image.shape)
print("输出图像维度: ", new_image.shape)
raw_image = image_trans(raw_image)
new_image = image_trans(new_image)
# 由于模型未训练,故每次运行得到的结果都不同。原因:每次运行的初始化卷积核不同。
plt.subplot(121), plt.imshow(raw_image, 'gray'), plt.title('raw_image')
plt.subplot(122), plt.imshow(new_image, 'gray'), plt.title('new_image')
plt.show()
实战二:U2-Net(不训练版)
由于模型未训练,故每次运行得到的结果都不同。原因:每次运行的初始化卷积核不同。图像分割之U-Net、U2-Net及其Pytorch代码构建
import torch.nn.functional as F
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from PIL import Image
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"
class ConvolutionLayer(nn.Module):
以上是关于U2-net网络详解的主要内容,如果未能解决你的问题,请参考以下文章
[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解
[人工智能-深度学习-33]:卷积神经网络CNN - 常见分类网络- LeNet网络结构分析与详解
[人工智能-深度学习-35]:卷积神经网络CNN - 常见分类网络- GoogLeNet Incepetion网络架构分析与详解
[人工智能-深度学习-34]:卷积神经网络CNN - 常见分类网络- VGG16/VGG19网络结构分析与详解