[人工智能-深度学习-35]:卷积神经网络CNN - 常见分类网络- GoogLeNet Incepetion网络架构分析与详解
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-35]:卷积神经网络CNN - 常见分类网络- GoogLeNet Incepetion网络架构分析与详解相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120896296
目录
2.2 Christian Szegedy(克里斯蒂安·塞格迪)其人
3.1 GoogLeNet基本、核心组成单元Inception的结构介绍 - 原始版本
3.2 GoogLeNet基本、核心组成单元Inception的结构介绍 - 改进版本
第1章 卷积神经网络基础
1.1 卷积神经发展与进化史
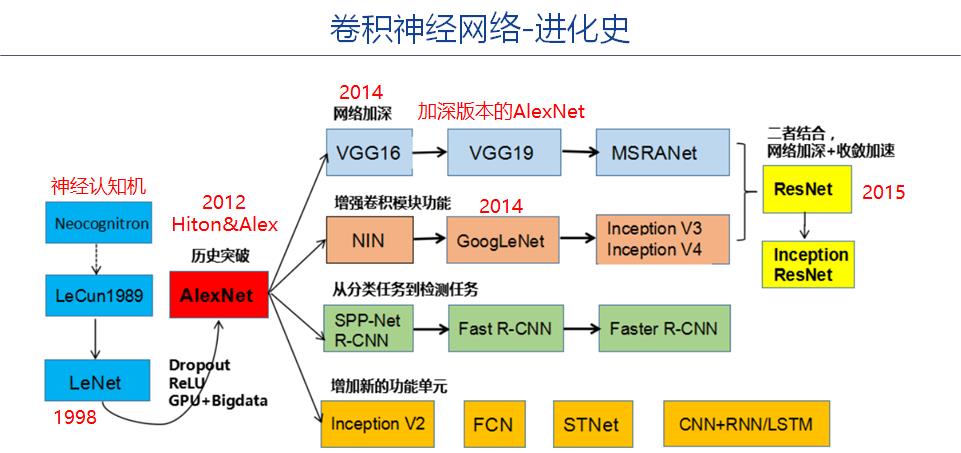
AlexNet是深度学习的起点,后续各种深度学习的网络或算法,都是源于AlexNet网络。
 https://blog.csdn.net/HiWangWenBing/article/details/120835303
https://blog.csdn.net/HiWangWenBing/article/details/1208353031.2 卷积神经网络的核心要素
1.3 卷积神经网络的描述方法
1.4 人工智能三巨头 + 华人圈名人

Yoshua Bengio、Yann LeCun、Geoffrey Hinton共同获得了2018年的图灵奖。
杰弗里·埃弗里斯特·辛顿(Geoffrey Everest Hinton),计算机学家、心理学家,被称为“神经网络之父”、“深度学习鼻祖”。Hinton是机器学习领域的加拿大首席学者,是加拿大高等研究院赞助的“神经计算和自适应感知”项目的领导者,是盖茨比计算神经科学中心的创始人,目前担任多伦多大学计算机科学系教授。2013年3月,谷歌收购 Hinton 的公司 DNNResearch 后,他便随即加入谷歌,直至目前一直在 Google Brain 中担任要职。
Yoshua Bengio是蒙特利尔大学(Université de Montréal)的终身教授,任教超过22年,是蒙特利尔大学机器学习研究所(MILA)的负责人,是CIFAR项目的负责人之一,负责神经计算和自适应感知器等方面,又是加拿大统计学习算法学会的主席,是ApSTAT技术的发起人与研发大牛。Bengio在蒙特利尔大学任教之前,是AT&T贝尔实验室 & MIT的机器学习博士后。
Yann LeCun,担任Facebook首席人工智能科学家和纽约大学教授,1987年至1988年,Yann LeCun是多伦多大学Geoffrey Hinton实验室的博士后研究员。
第2章 GoogleNet网络概述
2.1 概述
VGG模型是2014年ILSVRC竞赛的第二名,而第一名是GoogLeNet。
GoogLeNet, 由称为inception,之所以能够战胜VGG, 这是因为它引入了一种全新的深度学习结构。该网络结构是由Google的Christian Szegedy于2014年提出的,因此称为GoogLeNet。
据说之所以取名GoogLeNet而不是GoogleNet是为了向CNN的开山之作LeNet致敬。
GoogLeNet从Google公司的角度明确了该网络的归属,而Inception则从这个全新网络的内在本质特征来明确了该网络区别于其他网络的特性。
在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。
GoogLeNet(Inception)则通对网络结构进行改造来提升训练结果,改造后的结构,能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
从网络的深度和宽度两个方面都有所增加。该网络是一个22层的卷积神经网络,要比VGGNet的19层更深,然后,其网络参数和浮点数计算量都远远小于VGG19网络。
2.2 Christian Szegedy(克里斯蒂安·塞格迪)其人

Christian Szegedy谷歌的资深研究科学家,现在Google从事人工智能领域的研究。
GoogLeNet获得了2014年ImageNet挑战赛(ILSVRC14)的第一名,VGG获得了第二名。
2.3 googLeNet提出的动机与背景
提高神经网络性能的最直接的方法就是增加其规模。这包括:
- 增加网络深度:网络的层数。
- 每一层的宽度:神经元的数量。
但是,这种简单的方法有一些问题:比如参数大量增加、过拟合overfit、梯度消失、梯度爆炸等。
解决这些问题的方法就是:在增加网络深度和宽度的同时减少参数,这就引入了稀疏连接,将全连接变成稀疏连接。但是全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。
有没有一种方法:既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。GoogLeNet就是基于此提出的。
2.4 googLeNet特点与更新
(1)1 * 1卷积核的使用:发现更细微的特征
(2)同一个层,可以使用多个不同长度的卷积核:发现不同尺度的特征,局部+更宽+更宽的特征
能够综合不同尺寸的特征。
(3)增加层数:发现更多抽象层次的宏观特征(20层左右是极限)
(4)Inception(感知器)的引入:不同大小卷积核的组合
2.5 inception的本意

Inception源于一部知名的电影:盗梦空间。
Inception的英文是:(机构、组织等的)开端,创始。这里是指多维视角单元。
第3章 GoogLeNet网络组成单元
3.1 GoogLeNet基本、核心组成单元Inception的结构介绍 - 原始版本
Inception就是把多个卷积或池化操作,放在一起组装成一个网络模块,设计神经网络时以模块为单位去组装整个网络结构。模块如下图所示:
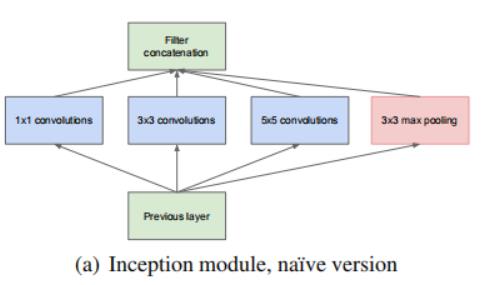
在未使用这种方式的网络之前,我们一层往往只使用一种操作,比如卷积或者池化,而且卷积操作的卷积核尺寸也是固定大小的。
但是,在实际情况下,在不同尺度的图片里,需要不同大小的卷积核,这样才能使性能最好,或者或,对于同一张图片,不同尺寸的卷积核的表现效果是不一样的,因为他们的感受野不同。
所以,我们希望让网络自己去选择,Inception便能够满足这样的需求,一个Inception模块中并列提供多种卷积核的操作,网络在训练的过程中通过调节参数自己去选择使用,
同时,由于网络中都需要池化操作,所以此处也把池化层并列加入网络中。
3.2 GoogLeNet基本、核心组成单元Inception的结构介绍 - 改进版本
我们在上面提供了一种Inception的结构,存在很多问题,是不能够直接使用的。
首要问题就是参数太多,导致特征图厚度太大。
为了解决这个问题,作者在其中加入了1X1的卷积核,改进后的Inception结构如下图:
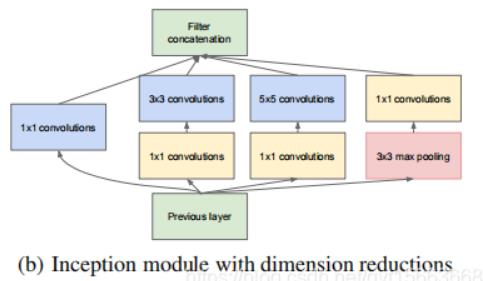
这样做有两个好处:
首先:是大大减少了参数量,
其次,是增加的1X1卷积后面也会跟着有非线性激励,这样同时也能够提升网络的表达能力。
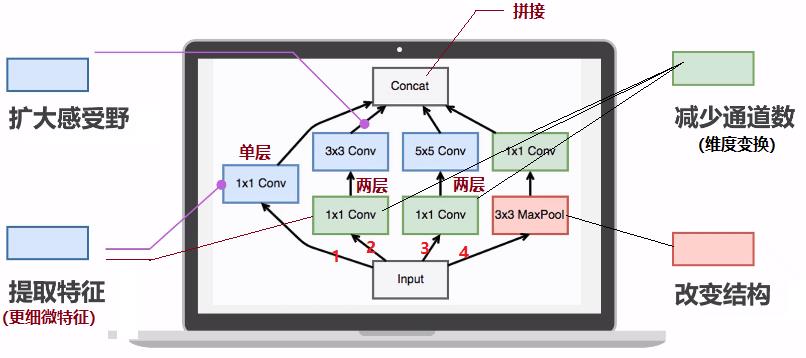
(1)4个并行流
(2) 最大2层串联
(3)步长为1
(4)GoogLeNet是Inception结构的堆叠,而不是卷积核的堆叠。
3.3 什么是1x1卷积核?
1x1卷积核,又称为网中网(Network in Network).
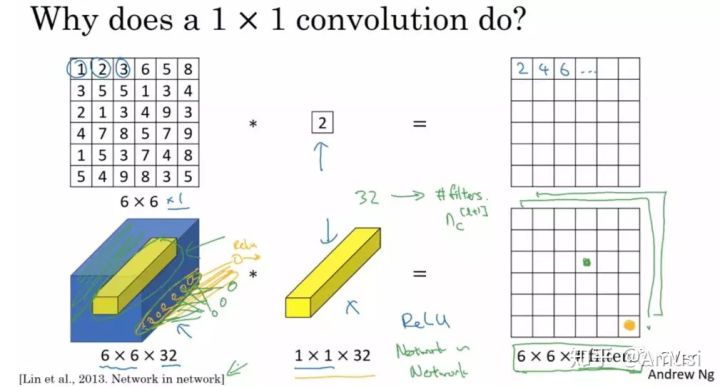
这里通过一个例子来直观地介绍1x1卷积。输入6x6x1的矩阵,这里的1x1卷积形式为1x1x1,即为元素2,输出也是6x6x1的矩阵。但输出矩阵中的每个元素值是输入矩阵中每个元素值x2的结果。

上述情况,并没有显示1x1卷积的特殊之处,那是因为上面输入的矩阵channel为1,所以1x1卷积的channel也为1。这时候只能起到升维的作用。这并不是1x1卷积的魅力所在。
让我们看一下真正work的示例。当输入为6x6x32时,1x1卷积的形式是1x1x32,当只有一个1x1卷积核的时候,此时输出为6x6x1。此时便可以体会到1x1卷积的实质作用:降维。当1x1卷积核的个数小于输入channels数量时,即降维[3]。
注意,下图中第二行左起第二幅图像中的黄色立方体即为1x1x32卷积核,而第二行左起第一幅图像中的黄色立方体即是要与1x1x32卷积核进行叠加运算的区域。
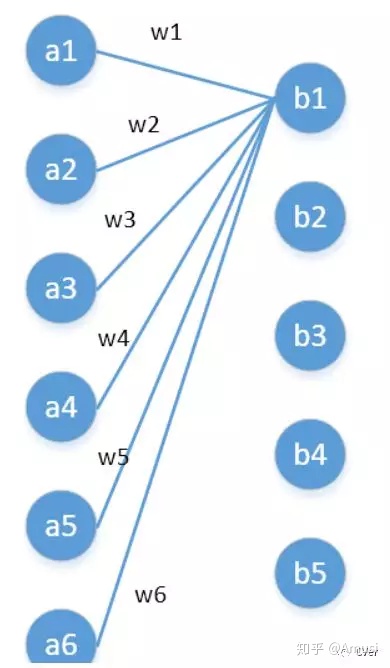
其实1x1卷积,可以看成一种全连接(full connection)。
第一层有6个神经元,分别是a1—a6,通过全连接之后变成5个,分别是b1—b5,第一层的六个神经元要和后面五个实现全连接,本图中只画了a1—a6连接到b1的示意,可以看到,在全连接层b1其实是前面6个神经元的加权和,权对应的就是w1—w6,到这里就很清晰了。
第一层的6个神经元其实就相当于输入特征里面那个通道数:6,而第二层的5个神经元相当于1*1卷积之后的新的特征通道数:5。
w1—w6是一个卷积核的权系数,若要计算b2—b5,显然还需要4个同样尺寸的卷积核[4]。
备注:1x1卷积一般只改变输出通道数(channels),而不改变输出的宽度和高度
3.4 1x1卷积核的意义与作用
(1)降维/升维
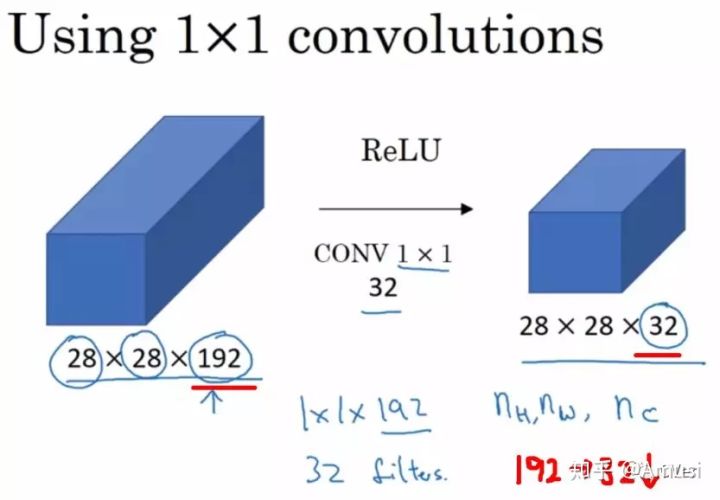
(2) 更加精细的特征提取:精细到每个像素。
第4章 GoogLeNet网络结构分析
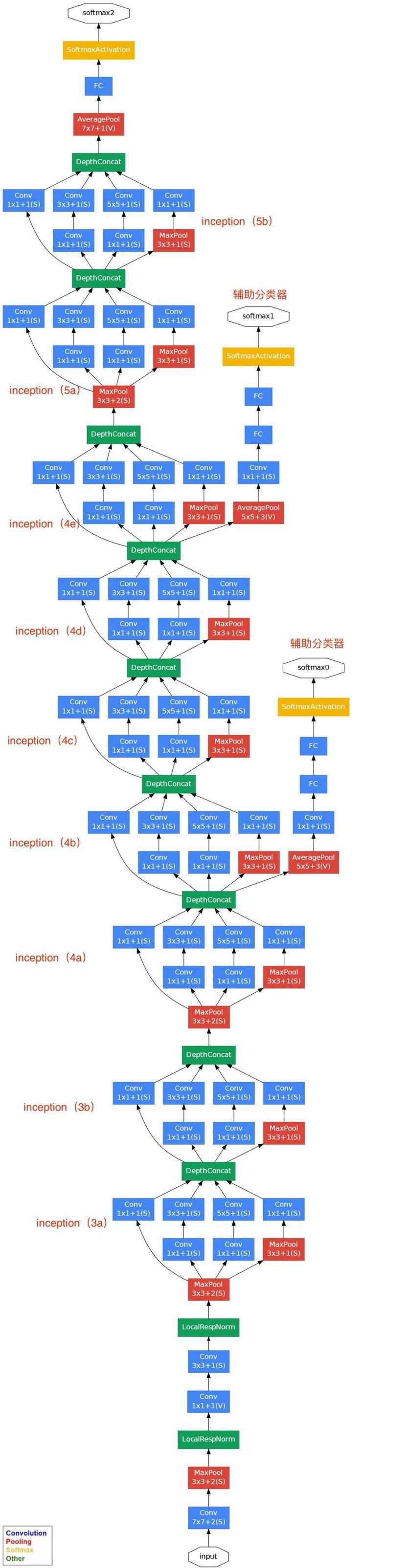
4.1 inception网络结构:横向表示法
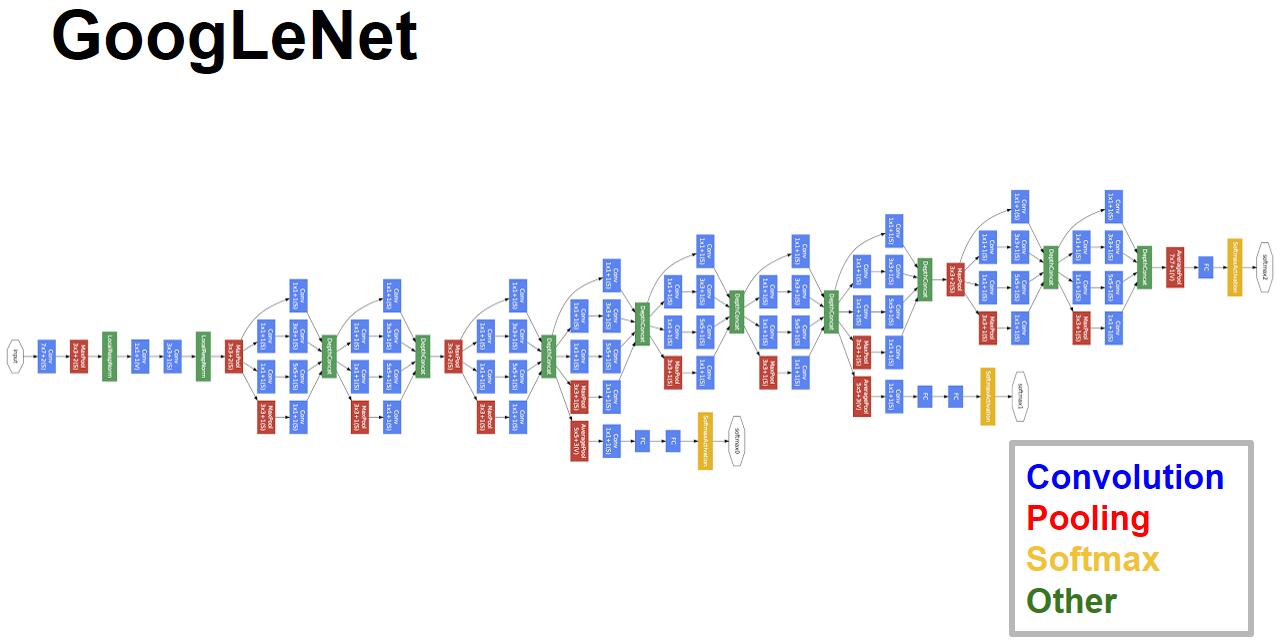
4.2 inception网络结构:纵向表示法
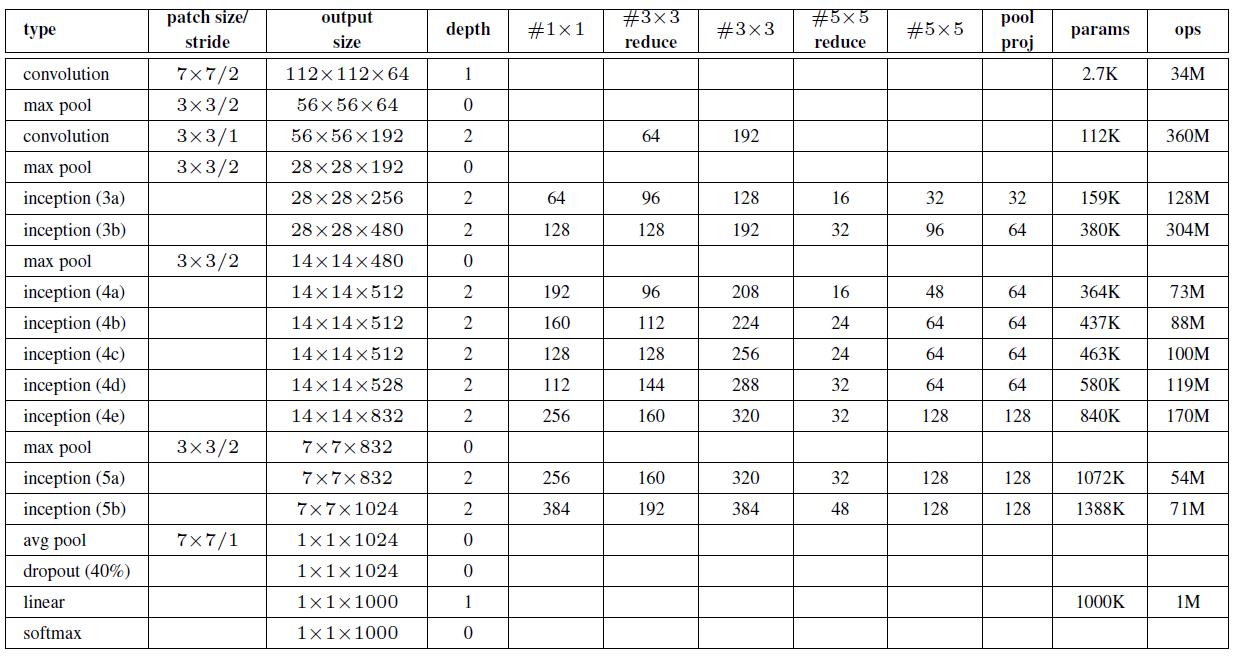
4.3 不同子版本的比较
Inception有众多的子版本。
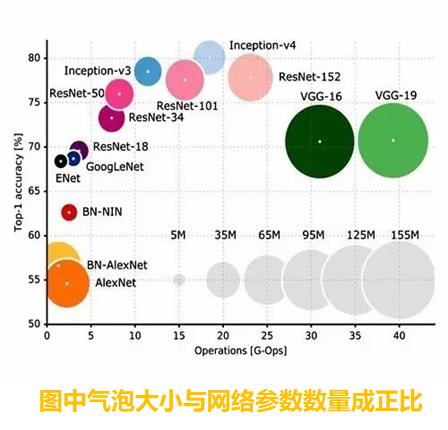
在众多网络中,Inception-3的参数少,准确率高的特点。
Inception-4虽然比Inception-3准确率高一点点,但参数也多出不少。
从准确率看和参数量来看,ResNet相对于Inception-3并没有优势。
4.4 网络结构分析
(1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了average pooling(平均池化)来代替第一层全连接层(分类前的第二层全连接保留),该想法来自NIN(Network in Network),据说,这样可以将准确率提高0.6%。
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)
对于前三点都很好理解,下面我们重点看一下第4点。
4.5 辅助分类器
这里的辅助分类器只是在训练时使用,防止主梯度消失,在正常预测时会被去掉。
当主梯度消失时,可以永辅助分离器,检查是否需要进一步训练,调参。
辅助分类器促进了更稳定的学习和更好的收敛,往往在接近训练结束时,辅助分支网络开始超越没有任何分支的网络的准确性,达到了更高的水平。
疑问:
能否把辅助分类器应用到正常的预测中,进行分层预测?
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120896296
以上是关于[人工智能-深度学习-35]:卷积神经网络CNN - 常见分类网络- GoogLeNet Incepetion网络架构分析与详解的主要内容,如果未能解决你的问题,请参考以下文章