模糊聚类-模拟花朵聚类
Posted bokeyuancj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模糊聚类-模拟花朵聚类相关的知识,希望对你有一定的参考价值。
模糊聚类
模糊聚类与K-means算法有异曲同工之妙,两者各有优劣势,K-means算法的介绍连接:https://www.cnblogs.com/bokeyuancj/p/11460883.html
基本概念:
聚类分析是多元统计分析的一种,也是无监督模式识别的一个重要分支,在模式分类 图像处理和模糊规则处理等众多领域中获得最广泛的应用。它把一个没有类别标记的样本按照某种准则划分为若干子集,使相似的样本尽可能归于一类,而把不相似的样本划分到不同的类中。硬聚类把每个待识别的对象严格的划分某类中,具有非此即彼的性质,而模糊聚类建立了样本对类别的不确定描述,更能客观的反应客观世界,从而成为聚类分析的主流。模糊聚类算法是一种基于函数最优方法的聚类算法,使用微积分计算技术求最优代价函数,在基于概率算法的聚类方法中将使用概率密度函数,为此要假定合适的模型,模糊聚类算法的向量可以同时属于多个聚类,从而摆脱上述问题。
模糊聚类分析算法大致可分为三类
(1)分类数不定,根据不同要求对事物进行动态聚类,此类方法是基于模糊等价矩阵聚类的,称为模糊等价矩阵动态聚类分析法。
(2)分类数给定,寻找出对事物的最佳分析方案,此类方法是基于目标函数聚类的,称为模糊C均值聚类。
(3)在摄动有意义的情况下,根据模糊相似矩阵聚类,此类方法称为基于摄动的模糊聚类分析法
本次仅介绍模糊C均值聚类。
隶属度概念:
模糊聚类算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。模糊聚类(FCM)对数据进行模糊划分,使用隶属度表示一个样本属于某一类的程度。
隶属度函数是表示一个对象x 隶属于集合A 的程度的函数,通常记做μA(x),其自变量范围是所有可能属于集合A 的对象(即集合A 所在空间中的所有点),取值范围是[0,1],即0<=μA(x),μA(x)<=1。μA(x)=1 表示x 完全隶属于集合A,相当于传统集合概念上的x∈A。一个定义在空间X={x}上的隶属度函数就定义了一个模糊集合A,或者叫定义在论域X={x}上的模糊子集A’。对于有限个对象x1,x2,……,xn 模糊集合A’可以表示为:
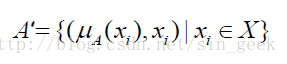
在聚类的问题中,可以把聚类生成的簇看成模糊集合,因此,每个样本点隶属于簇的隶属度就是[0,1]区间里面的值。
模糊聚类算法步骤:
(1)确定类别数,参数,和迭代停止误差以及最大迭代次数
(2)初始化聚类中心P
(3)计算初始的距离矩阵D
(4)按下列公式更新隶属度
(5)按公式更新隶属度
(6)更新聚类中心
(7)重新计算距离矩阵,并计算目标函数的值
(8)若达到最大迭代次数或者前后两次的J的绝对差小于迭代停止误差则停止,否则使用前后两次隶属度矩阵的差来判断。
(9)将样本点划分为隶属度最大的那一类。
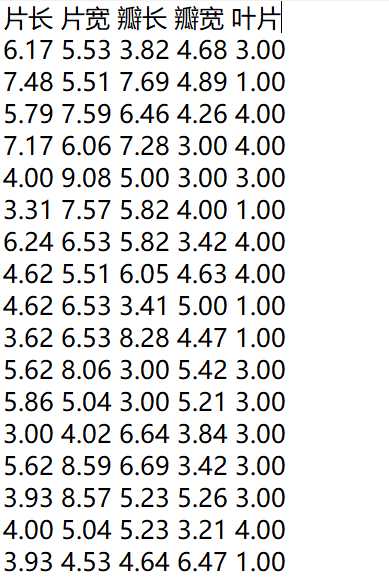
数据样本:
| 数据量 | 1500(条) |
| 数据属性(影响变量) | 5(种) |
| 属性1 | 花片长度(厘米) |
| 属性2 | 花片宽度(厘米) |
| 属性3 | 花瓣长度(厘米) |
| 属性4 | 花瓣宽度(厘米) |
| 属性5 | 花叶数量(片) |
代码部分:
1 #include "stdio.h" 2 #include "stdlib.h" 3 #include "time.h" 4 #include "math.h" 5 #include "vector" 6 using namespace std; 7 8 9 #define alpha 0.5 //分裂比 10 #define dimNum 3 //维数为3 11 #define cNum 10 //初始类数 12 #define expectNum 10 //预期成类数 13 #define minNum 3 //小于此数则不能成类 14 #define splitVar 1.2 //大于此数分裂 15 #define connectVar 0.3 //小于此数合并 16 #define connectNum 2 //每次迭代允许合并的最大数 17 #define iterNum 30 //迭代次数为30 18 19 20 21 22 typedef vector<double> doubleVector; 23 typedef vector<doubleVector> clusterVector; 24 25 26 void ISODATA(vector<doubleVector> srcInf); //开始引擎 27 vector<doubleVector> getInf(); //获取文件数据 28 int getClusterNum(vector<doubleVector> mCenter, doubleVector srcInf); //归类 29 double getEUCdis(doubleVector t1, doubleVector t2); //计算欧式距离 30 doubleVector get_wMean(clusterVector cluster); //计算均值向量 31 doubleVector averageDist(doubleVector mCenter, clusterVector cluster); //计算Wi中所有样本距其相应聚类中心的平均距离 32 doubleVector allAvgDist(vector<doubleVector> avgDis); //计算所以样本距其相应的聚类中心的平均值 33 doubleVector getDeviation(doubleVector mCenter, clusterVector cluster); //计算没一聚类的标准偏差 34 double getMaxDev(doubleVector Dev); //获取最大标准偏差 35 doubleVector clusterSplit(doubleVector wMean, double sigma); //进行分裂 36 doubleVector eachCenterDist(doubleVector t1, doubleVector t2, int i, int j); //计算聚类中心两两间的距离 37 vector<doubleVector> distSort(vector<doubleVector> eachDist); //按距离进行排序 38 vector<doubleVector> Union(vector<doubleVector> mCenter, vector<doubleVector> sortDist); //进行合并 39 void Output(vector<clusterVector> cluster); //结果输出 40 41 42 //主函数 43 int main() 44 { 45 vector<doubleVector> srcInf; 46 srcInf = getInf(); 47 ISODATA(srcInf); 48 } 49 50 51 52 53 //迭代开始引擎 54 void ISODATA(vector<doubleVector> srcInf) 55 { 56 int c; 57 int i, j; 58 int iter=1; 59 int lable; 60 vector<doubleVector> mCenter; 61 vector<clusterVector> cluster; 62 vector<doubleVector> wMean; //均值向量 63 vector<doubleVector> avgDist; 64 doubleVector all_AvgDis; 65 vector<doubleVector> devVal; //标准偏差值 66 vector<doubleVector> eachDist; //两两聚类中心距离 67 vector<doubleVector> eachDistSort; //两两聚类中心距离 68 doubleVector devMax; //最大偏差值 69 double sigma; 70 71 72 start: 73 printf("聚类开始: "); 74 75 76 77 78 //初始化类聚中心 79 step1: 80 srand(time(NULL)); 81 int chooseNum; 82 if(mCenter.empty()==NULL) 83 mCenter.clear(); 84 85 86 mCenter.resize(cNum); 87 for(i=0; i<cNum; i++) 88 { 89 chooseNum = rand()%(int)(srcInf.size()/cNum)+i*(srcInf.size()/cNum); 90 for(j=0; j<dimNum; j++) 91 mCenter[i].push_back(srcInf[chooseNum][j]); 92 } 93 94 95 96 97 //根据距离归类 98 step2: 99 if(cluster.empty()==NULL) 100 cluster.clear(); 101 102 103 cluster.resize(2*cNum); 104 for(i=0; i<srcInf.size(); i++) 105 { 106 lable = getClusterNum(mCenter, srcInf[i]); 107 cluster[lable].push_back(srcInf[i]); 108 } 109 110 111 112 113 //舍弃过小的类 114 step3: 115 for(i=0; i<cluster.size(); ) 116 { 117 if(cluster[i].size()<minNum) 118 { 119 cluster.erase(cluster.begin()+i); 120 if(i<mCenter.size()) 121 mCenter.erase(mCenter.begin()+i); 122 } 123 124 else 125 i++; 126 } 127 c = mCenter.size(); 128 129 130 131 132 //更新均值向量 133 step4: 134 if(wMean.empty()==NULL) 135 wMean.clear(); 136 137 138 for(i=0; i<cluster.size(); i++) 139 wMean.push_back(get_wMean(cluster[i])); 140 141 142 143 //获取各平均距离 144 step5: 145 if(avgDist.empty()==NULL) 146 avgDist.clear(); 147 148 149 for(i=0; i<cluster.size(); i++) //计算Wi中所有样本距其相应聚类中心的平均距离 150 avgDist.push_back(averageDist(mCenter[i], cluster[i])); 151 152 153 all_AvgDis = allAvgDist(avgDist); //计算所以样本距其相应的聚类中心的平均值 154 155 156 157 158 //判断分裂、合并及迭代的运算步骤 159 step7: 160 if(iter==iterNum) //步骤(1) 161 { 162 163 // connectNum = 0; 164 goto step11; 165 } 166 167 168 if(c<=expectNum/2)//步骤(2) 169 goto step8; 170 171 172 if(iter%2==0 || c>=2*expectNum)//步骤(3) 173 goto step11; 174 175 176 177 178 //计算标准偏差 179 step8: 180 if(devVal.empty()==NULL) 181 devVal.clear(); 182 183 184 for(i=0; i<mCenter.size(); i++) //计算标准偏差 185 devVal.push_back(getDeviation(mCenter[i], cluster[i])); 186 187 188 189 190 191 192 //计算标准偏差中偏差最大值 193 step9: 194 if(devMax.empty()==NULL) 195 devMax.clear(); 196 197 198 for(i=0; i<devVal.size(); i++) //计算标准偏差中偏差最大值 199 devMax.push_back(getMaxDev(devVal[i])); 200 201 202 203 204 205 206 //进行分裂 207 step10: 208 for(i=0; i<devMax.size(); i++) 209 { 210 if((devMax[i]>splitVar && cluster[i].size()>2*minNum) || c<=expectNum/2) 211 { 212 sigma = alpha*devMax[i]; 213 mCenter.push_back(clusterSplit(wMean[i], sigma)); 214 mCenter.push_back(clusterSplit(wMean[i], -sigma)); 215 mCenter.erase(mCenter.begin()+i); 216 } 217 } 218 c = mCenter.size(); 219 220 221 222 223 //计算两两聚类间的距离 224 step11: 225 if(eachDist.empty()==NULL) 226 eachDist.clear(); 227 228 229 for(i=0; i<mCenter.size()-1; i++) 230 for(j=i+1; j<mCenter.size(); j++) 231 { 232 eachDist.push_back(eachCenterDist(mCenter[i], mCenter[j], i, j)); 233 234 } 235 236 237 238 239 240 241 //对距离进行排序 242 step12: 243 eachDistSort = distSort(eachDist); 244 245 246 247 248 //进行合并 249 step13: 250 mCenter = Union(mCenter, eachDistSort); 251 c = mCenter.size(); 252 253 254 255 256 step14: 257 if(iter==iterNum) 258 { 259 printf("类聚结果为: "); 260 Output(cluster); 261 system("pause"); 262 return; 263 } 264 265 266 else 267 { 268 iter++; 269 goto step2; 270 } 271 272 273 } 274 275 276 277 278 279 280 //获取文件数据 281 vector<doubleVector> getInf() 282 { 283 int i=1; 284 vector<doubleVector> dst; 285 doubleVector temp; 286 double num; 287 288 FILE *fp; 289 290 fp = fopen("Inf.txt","r"); 291 //fp = fopen("Inf.txt", "r"); 292 293 if(fp == NULL) 294 printf("Open file error! "); 295 296 //读取文件的数据 297 while(fscanf(fp, "%lf", &num)!=EOF) 298 { 299 temp.push_back(num); 300 if(i%3==0) 301 { 302 dst.push_back(temp); 303 temp.clear(); 304 } 305 i++; 306 } 307 308 fclose(fp); 309 310 return dst; 311 } 312 313 314 315 316 //计算欧式距离 317 double getEUCdis(doubleVector t1, doubleVector t2) 318 { 319 double distance=0; 320 int i; 321 322 323 for(i=0; i<dimNum; i++) 324 distance += (t1[i]-t2[i])*(t1[i]-t2[i]); 325 326 327 return sqrtf(distance); 328 } 329 330 331 //根据初始中心进行归类 332 int getClusterNum(vector<doubleVector> mCenter, doubleVector srcInf) 333 { 334 double Dis; 335 double minDis = getEUCdis(mCenter[0], srcInf); 336 int i, lable=0; 337 338 339 for(i=1; i<mCenter.size(); i++) 340 { 341 Dis = getEUCdis(mCenter[i], srcInf); 342 if(Dis<minDis) 343 { 344 minDis = Dis; 345 lable = i; 346 } 347 } 348 349 350 return lable; 351 } 352 353 354 355 356 //计算均值向量 357 doubleVector get_wMean(clusterVector cluster) 358 { 359 doubleVector wMean; 360 double temp[dimNum]; 361 int i, j; 362 363 364 for(i=0; i<dimNum; i++) 365 temp[i] = 0; 366 367 368 for(i=0; i<cluster.size(); i++) 369 for(j=0; j<dimNum; j++) 370 temp[j] += cluster[i][j]; 371 372 373 for(i=0; i<dimNum; i++) 374 temp[i] = temp[i]/cluster.size(); 375 376 377 wMean.clear(); 378 for(i=0; i<dimNum; i++) 379 wMean.push_back(temp[i]); 380 381 382 return wMean; 383 } 384 385 386 387 388 //计算类聚中心m[i]的平均距离 389 doubleVector averageDist(doubleVector mCenter, clusterVector cluster) 390 { 391 int i, j; 392 doubleVector avgDist; 393 double temp[dimNum]={0}; 394 395 396 for(i=0; i<cluster.size(); i++) 397 for(j=0; j<dimNum; j++) 398 temp[j] += cluster[i][j]; 399 400 401 for(i=0; i<dimNum; i++) 402 temp[i] /= cluster.size(); 403 404 405 avgDist.clear(); 406 for(i=0; i<dimNum; i++) 407 avgDist.push_back(temp[i]); 408 409 410 return avgDist; 411 412 413 } 414 415 416 417 418 //计算所以样本距其相应的聚类中心的平均值 419 doubleVector allAvgDist(vector<doubleVector> avgDis) 420 { 421 int i, j; 422 doubleVector allAvg; 423 double temp[dimNum]={0}; 424 425 426 for(i=0; i<avgDis.size(); i++) 427 for(j=0; j<dimNum; j++) 428 temp[j] += (i+1)*avgDis[i][j]; 429 430 431 for(i=0; i<dimNum; i++) 432 temp[i] /= avgDis.size(); 433 434 435 allAvg.clear(); 436 for(i=0; i<dimNum; i++) 437 allAvg.push_back(temp[i]); 438 439 440 return allAvg; 441 } 442 443 444 445 446 //计算每一个聚类的标准偏差 447 doubleVector getDeviation(doubleVector mCenter, clusterVector cluster) 448 { 449 doubleVector dst; 450 int i, j; 451 double temp[dimNum]={0}; 452 453 454 for(i=0; i<cluster.size(); i++) 455 for(j=0; j<dimNum; j++) 456 temp[j] += (cluster[i][j]-mCenter[j])*(cluster[i][j]-mCenter[j]); 457 458 459 dst.clear(); 460 for(i=0; i<dimNum; i++) 461 { 462 temp[i] /= cluster.size(); 463 temp[i] = sqrtf(temp[i]); 464 dst.push_back(temp[i]); 465 } 466 467 468 return dst; 469 470 471 } 472 473 474 475 476 //获取最大标准偏差 477 double getMaxDev(doubleVector Dev) 478 { 479 int i; 480 double max = Dev[0]; 481 482 483 for(i=1; i<dimNum; i++) 484 if(max<Dev[i]) 485 max = Dev[i]; 486 487 488 return max; 489 } 490 491 492 493 494 //进行分裂 495 doubleVector clusterSplit(doubleVector wMean, double sigma) 496 { 497 int i; 498 doubleVector newMean; 499 double temp; 500 501 502 newMean.clear(); 503 for(i=0; i<dimNum; i++) 504 { 505 temp = wMean[i]+sigma; 506 newMean.push_back(temp); 507 } 508 509 510 return newMean; 511 } 512 513 514 515 516 //计算聚类中心两两间的距离 517 doubleVector eachCenterDist(doubleVector t1, doubleVector t2, int x, int y) 518 { 519 int i; 520 doubleVector dist; 521 522 523 dist.clear(); 524 for(i=0; i<dimNum; i++) 525 dist.push_back(fabs(t1[i]-t2[i])); 526 527 528 dist.push_back(x); 529 dist.push_back(y); 530 531 532 return dist; 533 } 534 535 536 537 538 //按距离进行排序 539 vector<doubleVector> distSort(vector<doubleVector> eachDist) 540 { 541 int i, j, l; 542 vector<doubleVector> dst; 543 doubleVector maxEachDist; 544 double temp; 545 doubleVector tempVet; 546 double min; 547 548 549 dst = eachDist; 550 //寻找每组中最大的距离 551 maxEachDist.clear(); 552 for(i=0; i<eachDist.size(); i++) 553 maxEachDist.push_back(getMaxDev(eachDist[i])); 554 555 556 //排序 557 for(i=0; i<maxEachDist.size(); i++) 558 { 559 l=i; 560 min = maxEachDist[i]; 561 for(j=i+1; j<maxEachDist.size(); j++) 562 if(min>maxEachDist[j]) 563 { 564 min = maxEachDist[j]; 565 l = j; 566 } 567 568 569 temp = maxEachDist[i]; 570 maxEachDist[i] = maxEachDist[l]; 571 maxEachDist[l] = temp; 572 573 574 tempVet = dst[i]; 575 dst[i] = dst[l]; 576 dst[l] = tempVet; 577 } 578 579 580 return dst; 581 } 582 583 584 585 586 //进行合并 587 vector<doubleVector> Union(vector<doubleVector> mCenter, vector<doubleVector> sortDist) 588 { 589 int i[connectNum], j[connectNum]; 590 int m, n, delNum=0; 591 vector<doubleVector> newCenter; 592 vector<int> del; 593 doubleVector temp; 594 595 596 newCenter = mCenter; 597 598 599 //可联合数量 600 for(m=0; m<connectNum; m++) 601 for(n=0; n<dimNum; n++) 602 if(sortDist[m][n]<connectVar) 603 { 604 delNum++; 605 break; 606 } 607 608 609 //进行联合 610 for(m=0; m<delNum; m++) 611 { 612 i[m] = sortDist[m][dimNum]; 613 j[m] = sortDist[m][dimNum+1]; 614 615 616 for(n=0; n<dimNum; n++) 617 temp.push_back((i[m]*mCenter[i[m]][n]+j[m]*mCenter[j[m]][n])/(i[m]+j[m])); 618 619 620 newCenter.push_back(temp); 621 } 622 623 624 //避免重复删除 625 for(m=0; m<delNum; m++) 626 del.push_back(i[m]); 627 628 for(n=0; n<delNum; n++) 629 { 630 if(del[n]==j[n]) 631 continue; 632 else 633 del.push_back(j[n]); 634 } 635 636 637 638 for(m=0; m<del.size(); m++) 639 newCenter[del[m]].clear(); 640 641 642 for(m=0; m<newCenter.size(); ) 643 { 644 if(newCenter[m].empty()) 645 newCenter.erase(newCenter.begin()+m); 646 else 647 m++; 648 } 649 650 return newCenter; 651 } 652 653 654 655 656 //结果输出 657 void Output(vector<clusterVector> cluster) 658 { 659 int i, j, k; 660 661 662 for(i=0; i<cluster.size(); i++) 663 { 664 printf(" 类聚%d : ", i+1); 665 for(j=0; j<cluster[i].size(); j++) 666 printf("%lf %lf %lf %lf %lf ", cluster[i][j][0], cluster[i][j][1], cluster[i][j][2], cluster[i][j][4], cluster[i][j][5]); 667 } 668 }
运行结果:
第一次运行
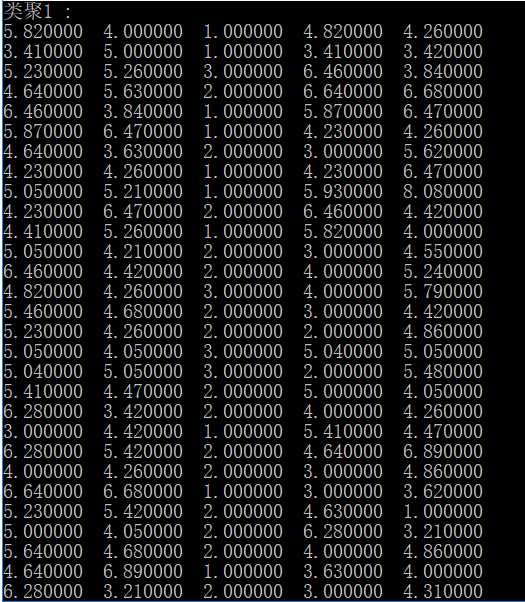
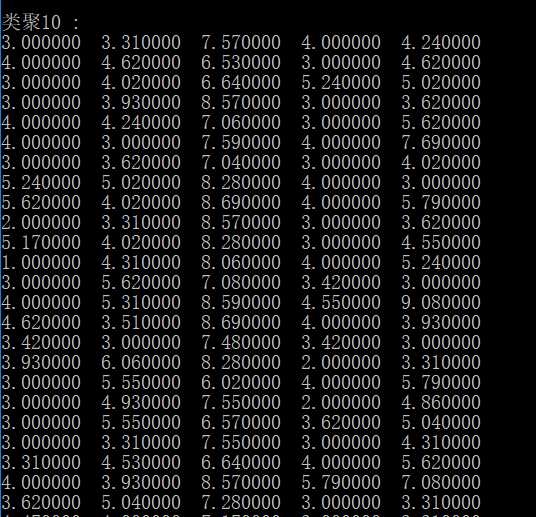
程序运行
- 输出大小: 1.64986419677734 MiB
- 编译时间: 1.06s
第二次运行
程序运行
- 输出大小: 1.64986419677734 MiB
- 编译时间: 1.09s
运行第三次

程序运行
- 输出大小: 1.64986419677734 MiB
- 编译时间: 1.08s
K-Means算法与聚类算法优缺点对比
K-Means算法的优点:
1.算法快速、简单;
2.对大数据集有较高的效率并且是可伸缩性的;
3.时间复杂度近于线性,而且适合挖掘大规模数据集。
K-Means聚类算法的时间复杂度是O(nkt) ,其中n代表数据集中对象的数量,t代表着算法迭代的次数,k代表着簇的数目。
模糊聚类算法优点:
1.FCM方法会计算每个样本对所有类的隶属度,拥有样本分类结果可靠性的计算方法;
2.样本分类更加保险
但是模糊聚类算法的不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。其时间复杂度为O(n3log2n),且存储开销大,很难处理大规模的数据
参考博客:
https://blog.csdn.net/wzl1997/article/details/79264560
https://blog.csdn.net/u012871279/article/details/51656027
http://archive.ics.uci.edu/ml/index.php
https://blog.csdn.net/u013049912/article/details/84782857
以上是关于模糊聚类-模拟花朵聚类的主要内容,如果未能解决你的问题,请参考以下文章
机器学习笔记: 聚类 模糊聚类与模糊层次聚类(论文笔记 Fuzzy Agglomerative Clustering :ICAISC 2015)