05-05 主成分分析代码(手写数字识别)
Posted nickchen121
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了05-05 主成分分析代码(手写数字识别)相关的知识,希望对你有一定的参考价值。
目录
更新、更全的《机器学习》的更新网站,更有python、go、数据结构与算法、爬虫、人工智能教学等着你:https://www.cnblogs.com/nickchen121/
主成分分析代码(手写数字识别)
一、导入模块
import time
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifier
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')二、数据预处理
# 导入手写识别数字数据集
digits = datasets.load_digits()
X = digits.data
y = digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)三、KNN训练数据
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')3.1 准确度
knn.score(X_train, y_train)0.9866369710467706四、降维(2维)
pca = PCA(n_components=2)
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)4.1 KNN训练数据
begin = time.time()
knn = KNeighborsClassifier()
knn.fit(X_train_reduction, y_train)
end = time.time()
print('训练耗时:{}'.format(end-begin))训练耗时:0.00115680694580078124.2 准确度
knn.score(X_test_reduction, y_test)0.62666666666666674.3 二维特征方差比例
pca.explained_variance_ratio_array([0.14566794, 0.13448185])五、查看原始数据特征方差比例
pca = PCA(n_components=X_train.shape[1])
pca.fit(X_train)
pca.explained_variance_ratio_array([1.45667940e-01, 1.34481846e-01, 1.19590806e-01, 8.63833775e-02,
5.90548655e-02, 4.89518409e-02, 4.31561171e-02, 3.63466115e-02,
3.41098378e-02, 3.03787911e-02, 2.38923779e-02, 2.24613809e-02,
1.81136494e-02, 1.81125785e-02, 1.51771863e-02, 1.39510696e-02,
1.32079987e-02, 1.21938163e-02, 9.95264723e-03, 9.39755156e-03,
9.02644073e-03, 7.96537048e-03, 7.64762648e-03, 7.10249621e-03,
7.04448539e-03, 5.89513570e-03, 5.65827618e-03, 5.08671500e-03,
4.97354466e-03, 4.32832415e-03, 3.72181436e-03, 3.42451450e-03,
3.34729452e-03, 3.20924019e-03, 3.03301292e-03, 2.98738373e-03,
2.61397965e-03, 2.28591480e-03, 2.21699566e-03, 2.14081498e-03,
1.86018920e-03, 1.57568319e-03, 1.49171335e-03, 1.46157540e-03,
1.17829304e-03, 1.06805854e-03, 9.41934676e-04, 7.76116004e-04,
5.59378443e-04, 3.65463486e-04, 1.71625943e-04, 8.78242589e-05,
5.20662123e-05, 5.19689192e-05, 4.16826522e-05, 1.50475650e-05,
4.42917130e-06, 3.53610879e-06, 7.14554374e-07, 6.80092943e-07,
3.48757835e-07, 8.17776361e-34, 8.17776361e-34, 7.97764241e-34])5.1 主成分所占方差比例
plt.plot([i for i in range(X_train.shape[1])],
[np.sum(pca.explained_variance_ratio_[:i+1]) for i in range(X_train.shape[1])],c='r')
plt.xlabel('前n个主成分',fontproperties=font)
plt.ylabel('前n个主成分方差所占比例',fontproperties=font)
plt.show()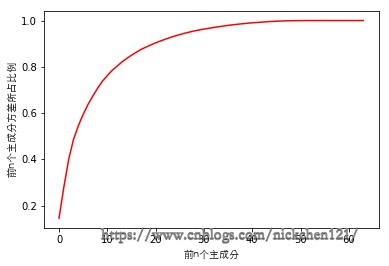
通过上图可以确定取多少比例的主成分能平衡模型的准确率和训练速度。
六、保留原始维度的80%的维度
# 0.95表示保留原始维度的80%的维度
pca = PCA(0.80)
pca.fit(X_train)PCA(copy=True, iterated_power='auto', n_components=0.8, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)6.1 查看主成分个数
pca.n_components_136.2 降维(13维)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)6.3 KNN训练数据
begin = time.time()
knn = KNeighborsClassifier()
knn.fit(X_train_reduction, y_train)
end = time.time()
print('训练耗时:{}'.format(end-begin))训练耗时:0.0042140483856201176.4 准确度
knn.score(X_test_reduction, y_test)0.9844444444444445七、小结
主成分分析作为降维的作用,但是如果过分降维,降维到2维的时候可以看到模型的准确率非常低;如果降维到80%左右,准确度没有什么太大的影响。由于数据量过少,所以降维的优点即模型训练速度加快的优势并没有体现出来,但是在工业上PCA一定是通过丢失一部分信息+降低模型准确度换取模型训练速度。
以上是关于05-05 主成分分析代码(手写数字识别)的主要内容,如果未能解决你的问题,请参考以下文章
秒懂算法 | 基于主成分分析法随机森林算法和SVM算法的人脸识别问题