tensorflow模型量化实例
Posted jiangxinyang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow模型量化实例相关的知识,希望对你有一定的参考价值。
1,概述
模型量化应该是现在最容易实现的模型压缩技术,而且也基本上是在移动端部署的模型的毕竟之路。模型量化基本可以分为两种:post training quantizated和quantization aware training。在pyrotch和tensroflow中都提供了相应的实现接口。
对于量化用现在常见的min-max方式可以用公式概括为:
$r = S (q - Z)$
上面式子中q为量化后的值,r为原始浮点值,S为浮点类型的缩放稀疏,Z为和q相同类型的表示r中0点的值。根据:
$frac{q - q_{min}}{q_{max} - q_{min}} = frac{r - r_{min}}{r_{max} - r_{min}}$
可以推断得到S和Z的值:
$S = frac{r_{max} - r_{min}}{q_{max} - q_{min}}$
$Z = q_{min} - frac{r_{min}}{S}$
2,实验部分
基于tensorflow在LeNet上实验了这两种量化方式,代码见GitHub:https://github.com/jiangxinyang227/model_quantization。
post training quantizated
在tensorflow中实现起来特别简单,训练后的模型可是选择用savedModel保存的模型作为输入进行量化并转换成tflite,我们将这个版本称为v1版本。
import tensorflow as tf saved_model_dir = "./pb_model" converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir, input_arrays=["inputs"], input_shapes={"inputs": [1, 784]}, output_arrays=["predictions"]) converter.optimizations = ["DEFAULT"] tflite_model = converter.convert() open("tflite_model_v3/eval_graph.tflite", "wb").write(tflite_model)
但在实际过程中这份代码转换后的tflite模型大小并没有缩小到1/4。所以非常奇怪,目前还不确定原因。在这基础上我们引入了一行代码,将这个版本称为v2:
import tensorflow as tf saved_model_dir = "./pb_model" converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir, input_arrays=["inputs"], input_shapes={"inputs": [1, 784]}, output_arrays=["predictions"]) converter.optimizations = ["DEFAULT"] # 保存为v1,v2版本时使用 converter.post_training_quantize = True # 保存为v2版本时使用 tflite_model = converter.convert() open("tflite_model_v3/eval_graph.tflite", "wb").write(tflite_model)
这样模型的大小缩小到了1/4。
之后再单独转为tflite的模型,这个称为v3:
import tensorflow as tf saved_model_dir = "./pb_model" converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir, input_arrays=["inputs"], input_shapes={"inputs": [1, 784]}, output_arrays=["predictions"]) tflite_model = converter.convert() open("tflite_model_v3/eval_graph.tflite", "wb").write(tflite_model)
很显然,直接转为tflite,模型大小肯定不会压缩的,我们再来看看推断速度,推断代码再GitHub上,具体结果如下:

上面checkpoint是在cpu上直接加载checkpoint进行预测。在这里看到只有v2版本的模型压缩到了原来的1/4,但是推断速度却不如v1和v3版本,且tflite模型的推断速度明显优于checkpoint。我猜原因可能是:
1,tflite本身的解释器对tflite模型是有加速的。
2,至于为什么量化后的模型反而效果不好,是因为post training quantized本质上计算时是将int转换成float计算的,因此中间存在量化和反量化的操作占绝了些时间。
quantization aware training
在训练中引入量化的操作要复杂很多,首先在训练时在损失计算后面,优化器定义前面要要引入tf.contrib.quantize.create_training_graph()。如下:
self.loss = slim.losses.softmax_cross_entropy(self.train_digits, self.input_labels) # 获取当前的计算图,用于后续的量化 self.g = tf.get_default_graph() if self.is_train: # 在损失函数之后,优化器定义之前,在这里会自动选择计算图中的一些operation和activation做伪量化 tf.contrib.quantize.create_training_graph(self.g, 80000) self.lr = cfg.LEARNING_RATE self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
训练完之后模型会保存为checkpoint文件,该文件中含有伪量化信息。这个里面的变量还是float类型,我们需要将其转换成只含int类型的模型文件,具体做法如下:
1,保存为freeze pb文件,并使用tf.contrib.quantize.create_eval_graph()来转换成推断模式
with tf.Session() as sess: le_net = Lenet(False) saver = tf.train.Saver() # 不可以导入train graph,需要重新创建一个graph,然后将train graph图中的参数来填充该图 saver.restore(sess, cfg.PARAMETER_FILE) frozen_graph_def = graph_util.convert_variables_to_constants( sess, sess.graph_def, [‘predictions‘]) tf.io.write_graph( frozen_graph_def, "pb_model", "freeze_eval_graph.pb", as_text=False)
注意上面的注释,在这里的saver一定不能用类似tf.train.import_meta_graph的方式导入训练时的计算图,而是通过再次调用Lenet类初始一个计算图,然后将训练图中的参数变量赋给该计算图。
2,转换成tflite文件
import tensorflow as tf path_to_frozen_graphdef_pb = ‘pb_model/freeze_eval_graph.pb‘ converter = tf.contrib.lite.TFLiteConverter.from_frozen_graph(path_to_frozen_graphdef_pb, ["inputs"], ["predictions"]) converter.inference_type = tf.contrib.lite.constants.QUANTIZED_UINT8 converter.quantized_input_stats = {"inputs": (0., 1.)} converter.allow_custom_ops = True converter.default_ranges_stats = (0, 255) converter.post_training_quantize = True tflite_model = converter.convert() open("tflite_model/eval_graph.tflite", "wb").write(tflite_model)
注意几点:
1),["inputs"], ["predictions"]是freeze pb中的输入节点和输出节点
2),quantized_input_states是定义输入的均值和方差,tensorflow lite的文档中说这个mean和var的计算方式是:mean 是 0 到 255 之间的整数值,映射到浮点数 0.0f。std_dev = 255 /(float_max - float_min)但我发现再这里采用0. 和 1.的效果也是不错的。
3),default_ranges_states是指量化后的值的范围,其中255就是2^8 - 1。
3,使用tflite预测
import time import tensorflow as tf import numpy as np import tensorflow.examples.tutorials.mnist.input_data as input_data mnist = input_data.read_data_sets(‘MNIST_data/‘, one_hot=True) labels = [label.index(1) for label in mnist.test.labels.tolist()] images = mnist.test.images """ 预测的时候需要将输入归一化到标准正态分布 """ means = np.mean(images, axis=1).reshape([10000, 1]) std = np.std(images, axis=1, ddof=1).reshape([10000, 1]) images = (images - means) / std """ 需要将输入的值转换成uint8的类型才可以 """ images = np.array(images, dtype="uint8") interpreter = tf.contrib.lite.Interpreter(model_path="tflite_model/eval_graph.tflite") interpreter.allocate_tensors() input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() start_time = time.time() predictions = [] for image in images: interpreter.set_tensor(input_details[0][‘index‘], [image]) interpreter.invoke() score = interpreter.get_tensor(output_details[0][‘index‘])[0][0] predictions.append(score) correct = 0 for prediction, label in zip(predictions, labels): if prediction == label: correct += 1 end_time = time.time() print((end_time - start_time) / len(labels) * 1000) print(correct / len(labels))
同样要注意两点:
1),输入要归一化到标准正态分布,这个我认为是和之前设定的quantized_inputs_states保持一致的。
2),输入要转换成uint8类型,不然会会报错。
4,性能对比
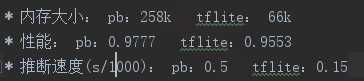
模型大小降低到之前的1/4,这个是没什么问题的,性能下降2%,可以接受,推断速度提升了3倍左右。
我们再和之前post training quantized中对比下:大小和v2一样,性能较v2差2%,推断速度快0.02。个人认为原因可能如下:
1,首先可能LeNet在mnist数据集上算是大模型,因此post training quantized对性能损失不大,因此和quantization aware training比并没有劣势,反而还有些优势。
2,quantization aware training的推断速度要快一些(注:这个值不是偶然,我测试过很多次,推断速度基本都稳定在一个值,平均上差0.02),但是快的不明显,而且较v1和v3还有所下降,因为在卷积网络中,计算复杂度主要受卷积的影响,而在这里的卷积并不大,量化后对推断速度的影响并不明显,其次引入量化操作还会损耗一些时间,且v2中还有反量化操作,因此时间消耗更多一点。最后就是可能硬件上并没有特别支持int8的计算。
总之上面只是测试了整个tensorflow中量化的流程。因为选择的网络比较简单,并没有看到在诸如Inception3,mobileNet上那样明显一点的差距。另外tflite确实能加速。
以上是关于tensorflow模型量化实例的主要内容,如果未能解决你的问题,请参考以下文章