小白学习之pytorch框架-动手学深度学习(begin)
Posted jadenfk3326
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白学习之pytorch框架-动手学深度学习(begin)相关的知识,希望对你有一定的参考价值。
在这向大家推荐一本书-花书-动手学深度学习pytorch版,原书用的深度学习框架是MXNet,这个框架经过Gluon重新再封装,使用风格非常接近pytorch,但是由于pytorch越来越火,个人又比较执着,想学pytorch,好,有个大神来了,把《动手学深度学习》整本书用pytorch代码重现了,其GitHub网址为:https://github.com/ShusenTang/Dive-into-DL-PyTorch 原书GitHub网址为:https://github.com/d2l-ai/d2l-zh 看大家爱好,其实客观的说哪个框架都行,只要能实现代码,学会一个框架,另外的就好上手了。菜鸟的见解哈,下面是个人感觉重要的一些
索引(x[:,1])出来和view()改变形状后,结果数据与原数据共享内存,就是修改其中一个,另外一个会跟着修改。类似于数据结构中的链表,指向的地址是同一个
若是想不修改原数据,可以用clone()返回一个副本再修改:x.clone().view(5,3)
item():把一个标量tensor转成python number
梯度
标量out:out.backward() #等价于out.backward(torch.tensor(1))
张量out:调用backward()时需要传入一个和out同形状的权重向量进行加权求和得到一个标量
想要修改tensor的值但又不想被autograd记录(不会影响反向传播),可以通过tensor.data来操作
x = torch.tensor(1.0, requires_grad=True) print(x.data) # tensor(1.) print(x.data.requires_grad) # False y = 2 * x x.data *= 100 y.backward() print(x) # tensor(100.,requires_grad=True) print(x.grad) # tensor(2.) 不是tensor(200.),因为用x.data计算不被记录到计算图内
线性回归实现 参考《动手学深度学习》第三章深度学习基础-线性回归的从零开始实现
这真是一本不错的书,我个人感觉
%matplotlib inline:在开头导入包前加入这个,可以在后面使用matplotlib画图时不用每次都调用pyplot.show()
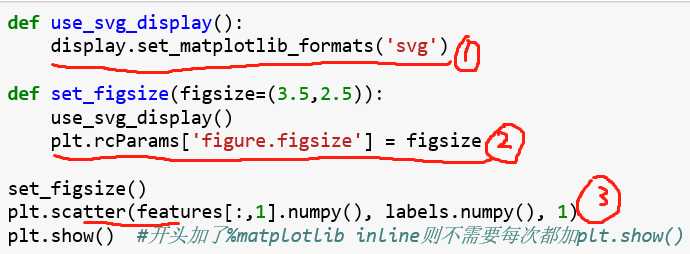
上面的图中,圈1是通过display包设置图像显示的文件格式为svg(可以算是目前最火的图像文件格式)
圈2中的rcParams()函数可以设置图形的各种属性,圈2是设置图像尺寸大小,还有
plt.rcParams[‘image.interpolation‘] = ‘nearest‘ #设置插值
plt.rcParams[‘image.cmap‘] = ‘gray‘ # 设置颜色
plt.rcParams[‘figure.dpi‘] = 300 # 每英寸的点数(图片分辨率)
plt.rcParams[‘savefig.dpi‘] = 300 # 图片像素
plt.rcParams[‘font.sans-serif‘] = ‘SimHei‘ # 设置字体
plt.rcParams[‘font.size‘] = 10.0 #设置字体大小
plt.rcParams[‘hist.bins‘] = 10 #设置直方图分箱个数
plt.rcParams[‘lines.linewidth‘] = 1.5 #设置线宽
plt.rcParams[‘text.color‘] = ‘red‘ #设置文本颜色
# 还有其他参数可以百度看看
圈3是画散点图,前两个参数是x,y,为点的横纵坐标,第三个是点的大小。其他的参数可百度
记录一下这段读取数据的代码,由于本人太菜了,好不容易查懂不想再重新查
def data_iter(batch_size, features, labels): # 这里batch_size:10 features:(1000,2)的矩阵 labels是经过线性回归公式计算得到的预测值,labels=X*w+b
num_examples = len(features) # features:(1000,2) len(features):1000
indices = list(range(num_examples)) # [0,1,2...,999]
random.shuffle(indices) # 将一个列表中的元素打乱,例子见下面
for i in range(0, num_examples, batch_size): # 0-1000,step=10 [0,10,20,...,999]
j = torch.LongTensor(indices[i:min(i + batch_size, num_examples)]) # 取indice值,并且返回成一个tensor。最后一次可能不足一个batch故用min函数
yield features.index_select(0, j), labels.index_select(0, j) #
yield的理解请移步,https://blog.csdn.net/mieleizhi0522/article/details/82142856 很好理解的,感谢博主了
random.shuffle() # 将一个数组打乱
li = list(range(5)) # [0,1,2,3,4]
random.shuffle(li) # 作用于li列表,而不是print(random.shuffle(li)),这是输不出来的
print(li) # [3,1,0,4,2]
torch之torch.index_select(x,1,indices) # x即要从其中(tensor x中)选择数据的tensor;1代表列,0代表行;indices筛选时的索引序号
x.index_select(n,index) # n代表从第几维开始,index是筛选时的索引序号
可以参考博客,感谢博主 https://www.jb51.net/article/174524.htm
数据特征和标签组合
import torch.utils.data as Data batch_size = 10 dataset = Data.TensorDataset(features,labels) #把训练数据的特征和标签(y值) data_iter = Data.DataLoader(dataset, batch_size,shuffle=True) #读取批量数据,批量大小为batch_size
for X, y in data_iter: # 这样才能打出
print(X, y)
break
搭建模型:
方法1:使用nn.Module定义
from torch import nn
class LinearNet(nn.Module):
def __init__(self, n_feature):
super(LinearNet, self).__init__()
self.linear = nn.Linear(n_feature, 1)
# 定义前向传播
def forward(self, x):
y = self.linear(x)
return y
net = LinearNet(num_inputs)
print(net) #显示网络结构
方法2:使用nn.Sequential
# nn.Sequential搭建网络
# 写法1
net = nn.Sequential(
nn.Linear(num_inputs, 1)
# 还可加入其他层
)
# 写法2
net = nn.Sequential()
net.add_module(‘linear‘, nn.Linear(num_inputs, 1))
# net.add_module.....
# 写法3
from collections import OrderedDict
net = nn.Sequential(OrderedDict([
(‘linear‘, nn.Linear(num_inputs, 1))
# ......
]))
print(net)
print(net[0])
以上是关于小白学习之pytorch框架-动手学深度学习(begin)的主要内容,如果未能解决你的问题,请参考以下文章
小白学习之pytorch框架之实战Kaggle比赛:房价预测(K折交叉验证*args**kwargs)
小白学习之pytorch框架-模型选择(K折交叉验证)欠拟合过拟合(权重衰减法(=L2范数正则化)丢弃法)正向传播反向传播
小白学习之pytorch框架-多层感知机(MLP)-(tensorvariable计算图ReLU()sigmoid()tanh())
PyTorch版《动手学深度学习》开源了,最美DL书遇上最赞DL框架