小白学习之pytorch框架-多层感知机(MLP)-(tensorvariable计算图ReLU()sigmoid()tanh())
Posted jadenfk3326
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白学习之pytorch框架-多层感知机(MLP)-(tensorvariable计算图ReLU()sigmoid()tanh())相关的知识,希望对你有一定的参考价值。
先记录一下一开始学习torch时未曾记录(也未好好弄懂哈)导致又忘记了的tensor、variable、计算图
计算图
计算图直白的来说,就是数学公式(也叫模型)用图表示,这个图即计算图。借用 https://hzzone.io/cs231n/%E7%90%86%E8%A7%A3-PyTorch-%E8%AE%A1%E7%AE%97%E5%9B%BE%E3%80%81Autograd-%E6%9C%BA%E5%88%B6%E5%92%8C%E5%AE%9E%E7%8E%B0%E7%BA%BF%E6%80%A7%E6%8B%9F%E5%90%88.html 一张图 ,红色圈里就是计算图
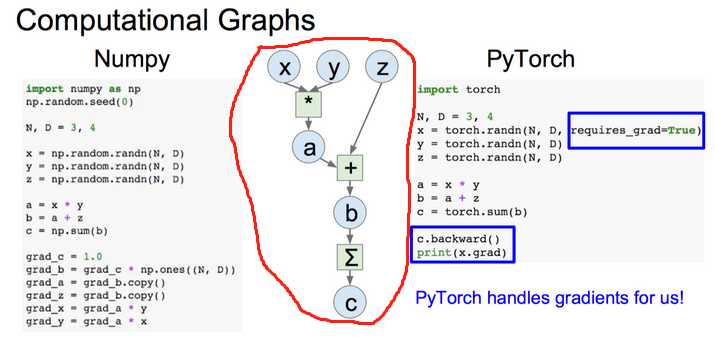
Tensor应该是好懂的,就是一张量,百度一下就可以的。torch.tensor和numpy.ndarray可以相互转换,
Variable本质上和Tensor一样,Variable是对Tensor的封装,操作和tensor基本一致,但是既然封装了,肯定加了东西,加了什么呢?每个Variable被构建时都含三个属性,1、tensor本身的.data(可取出Variable中tensor数值);2、对应tensor的梯度.grad(反向传播的梯度);3、grad_fn属性,如何得到的Variable的操作,如加减乘除。
detach()方法,官网解释是从当前计算图中分离的Variable,意思是通过此方法把requires_grad设置为False了,然后返回一个新的Variable,数据存放位置未变。
在博客 https://www.cnblogs.com/JadenFK3326/p/12072272.html 说了torch.mm()(正常矩阵相乘)和torch.mul()(矩阵对应值相乘) 参考博客 https://blog.csdn.net/da_kao_la/article/details/87484403 感谢博主 还有tensor乘法是torch.matmul()、torch.bmm()
补充一下,torch.mm()是矩阵相乘,输入的tenso维度只能两维;torch.matmul()可以说是torch.mm()的boradcast版本,可以进行大于2维的tensor乘法。多个矩阵并行计算 官网解释如下(看不懂英语自己在谷歌浏览器上打开官网,自动翻译):

torch.bmm(),两个三维张量相乘,分别为(b*n*m)和(b*m*p),其中b代表batch_size,输出为(b*n*p)
torch.max(input,dim,keepdim=False,out=None):按维度dim返回最大值
torch.max(input,other,out=None):两个tensor:input和other元素相比较,返回大的那个
下面的多层感知机和激活函数都比较简单,就说一下其公式了
多层感知机
即含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。
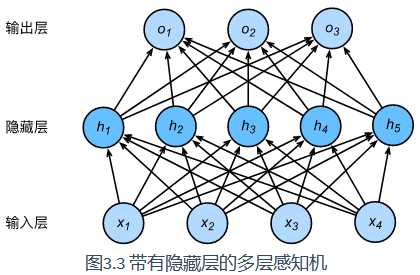
$ H = varnothing (XW_{h})+b_{h} $
$ O = HW_{o}+b_{o} $
其中,$ varnothing$表示激活函数
ReLU函数
$ ReLU(x) = max(x,0) $
Sigmoid函数
$ sigmoid(x) = frac{1}{1 + exp(-x)} $
tanh函数
$ tanh(x) = frac{1 - exp(-2x)}{1 + exp(-2x)} $
以上是关于小白学习之pytorch框架-多层感知机(MLP)-(tensorvariable计算图ReLU()sigmoid()tanh())的主要内容,如果未能解决你的问题,请参考以下文章