初识 HBase
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识 HBase相关的知识,希望对你有一定的参考价值。

HBase简介
对大数据领域有一定了解的小伙伴对HBase应该不会陌生,HBase是Apache基金会开源的一个分布式非关系型数据库,属于Hadoop的组件。它使用Java编写,需运行于HDFS文件系统之上。HBase与Hadoop中的其他组件一样,可以运行在廉价硬件上,并可提供数10亿行 X 数百万列的大数据存储、管理能力,以及随机访问和实时读/写能力。HBase的设计模型参考了Google的Bigtable,可以说是Bigtable的开源实现版本。
HBase特性
- 数据容量大,单表可以有百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性
- 多版本,每一列存储的数据可以有多个version
- 稀疏性,为空的列并不占用存储空间,表可以设计的非常稀疏
- 读写强一致,非 “最终一致性” 的数据存储,使得它非常适合高速的计算聚合
- 自动分片,通过Region分散在集群中,当行数增长的时候,Region也会自动的切分和再分配
- Hadoop/HDFS集成,和HDFS开箱即用,不用太麻烦的衔接。扩展性强,只需要增加DataNode就可以增加存储空间
- 丰富的“简洁,高效”API,提供了Thrift/REST API,Java API等方式对HBase进行访问
- 块缓存,布隆过滤器,可以高效的列查询优化
- 操作管理,Hbase提供了内置的web界面来操作,还可以监控JMX指标
- 高可靠,保证了系统的容错能力,WAL机制使得数据写入时不会因为集群异常而导致写入数据丢失。故HBase选择了CAP中的CP
- 面向列的存储和权限控制,并支持独立检索,可以动态的增加列
- 列式存储:其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数据量
- 高性能,具备海量数据的随机访问和实时读写能力
- 写方面:底层的 LSM 数据结构和 Rowkey 有序排列等架构上的独特设计,使得HBase具有非常高的写入性能。
- 读方面:region 切分、主键索引和缓存机制使得HBase在海量数据下具备一定的随机读取性能,针对 Rowkey 的查询能够达到毫秒级别
综上,HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌Bigtable的开源实现。主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。更多内容详见官方文档。
HBase提供的访问接口
| 类型 | 特点 | 场合 |
|---|---|---|
| Native Java API | 最常规和高效的访问方式 | 适合Hadoop MapReduce作业并行批处理HBase表数据 |
| HBase Shell | HBase的命令行工具,最简单的接口 | 适合管理HBase时使用 |
| Thrift Gateway | 利用Thrift序列化技术进行访问,支持C++、php、Python等多种语言 | 适合其他异构系统在线访问HBase表数据 |
| REST Gateway | 解除了语言限制,任何语言都可以通过该方式访问HBase | 支持REST风格的HTTP API访问HBase |
| Pig | 使用 Pig Latin 流式编程语言来处理HBase中的数据 | 适合做数据统计 |
| Hive | 简单 | 当需要以类似SQL语言方式来访问HBase的时候 |
HBase 与 HDFS 的区别
- HDFS是面向批量的访问模式,其类型为文件系统,存储的是文件类型的数据
- HBase是面向随机访问和实时读写模式,其类型为数据库服务,存储的是非结构化和半结构化的松散数据
- HBase 使用 HDFS 作为底层的文件系统,HBase 的数据最终会写到 HDFS 中。就像其他的数据库一样,真正的数据是存储在操作系统里的文件系统中的
- 打个不恰当的比方:它们的区别就像是Linux文件系统与MongoDB的区别
HBase 与关系数据库的区别
数据类型:
- 关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串。
数据操作:
- 关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表和表之间的关系。所以HBase也就不支持复杂的条件查询,只能是通过行键查询。
存储模式:
- 关系数据库是基于行模式存储的。HBase是基于列存储的,每个列簇都由几个文件保存,不同列簇的文件是分离的。并且列簇中的列是可以动态增加的,而关系数据库需要一开始就设计好。除此之外,HBase可以自动切分数据,关系型数据库则需要我们人工切分数据。
数据索引:
- 关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。HBase只有一个索引——行键,通过巧妙的设计,HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来。
数据维护:
- 在关系数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留。
可伸缩性:
- 关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase和BigTable这些分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩。
HBase 常见应用场景
- 存储业务数据:交通工具GPS信息,司机点位信息,订单信息,物流信息,设备访问信息,用户行为信息等
- 存储日志数据:架构监控数据(登录日志,中间件访问日志,推送日志,短信邮件发送记录等),业务操作日志信息等
- 存储业务附件:UDFS系统存储图像,视频,文档等附件信息,智慧城市系统的监控图像、流量数据等
HBase 的版本选择与定位
如何选择合适的 HBase 版本
HBase属于Hadoop生态体系,所以HBase的版本选择实际就是Hadoop的版本选择。而Hadoop就像Linux一样,也有多个发行版,常用发行版有以下几种:
- 原生的Apache Hadoop
- CDH:Cloudera Distributed Hadoop
- HDP:Hortonworks Data Platform
原生的Apache Hadoop在生产环境中不建议使用,因为Apache社区里的Hadoop生态系统的框架只是解决了单个框架的问题,如果想要将不同的框架,例如Hive、Hbase等框架综合起来使用的话,总是会产生jar包的冲突问题,而且这些冲突问题通常都是无法解决的。所以在学习的时候可以使用Apache Hadoop,但是生产环境中就不太建议使用了。
CDH以及HDP都是基于Apache Hadoop社区版衍生出来的,这两个发行版虽然都是商业版的,但不属于收费版本,除非需要提供技术服务,才需要收取一定的服务费用,并且它们也都是开源的。在国内绝大多数公司都会选择使用CDH版本,所以在这里也主要介绍CDH,选择CDH的主要理由如下:
- CDH对Hadoop版本的划分非常清晰,目前只有三个系列的版本(现在已经更新到CDH6.32了,基于hadoop3.x),分别是cdh4、cdh5和cdh6,分别对应第一代Hadoop(Hadoop 1.0)、第二代Hadoop(Hadoop 2.0)和第三代Hadoop(Hadoop 3.0),相比而言,Apache版本则混乱得多;
- CDH文档清晰且丰富,很多采用Apache版本的用户都会阅读cdh提供的文档,包括安装文档、升级文档等。
而且CDH提供了一个CM组件,让我们在安装它的时候只需要在浏览器上的页面中,点击各种下一步就可以完成安装,比起Apache Hadoop的安装要方便很多,而且很多操作都可以在图形界面上完成,例如集群的搭建以及节点切换等。CDH与Spark的合作是非常好的,所以在CDH中对Spark的支持比较好。最主要的是一般情况下使用同一版本的CDH,就不会发生jar冲突的情况。
CDH6的下载地址如下:
注:选择版本的时候尽量保持一致,例如hive选择了cdh5.7.0的话,那么其他框架也要选择cdh5.7.0,不然有可能会发生jar包的冲突。
HBase 在 Hadoop 生态系统中的定位
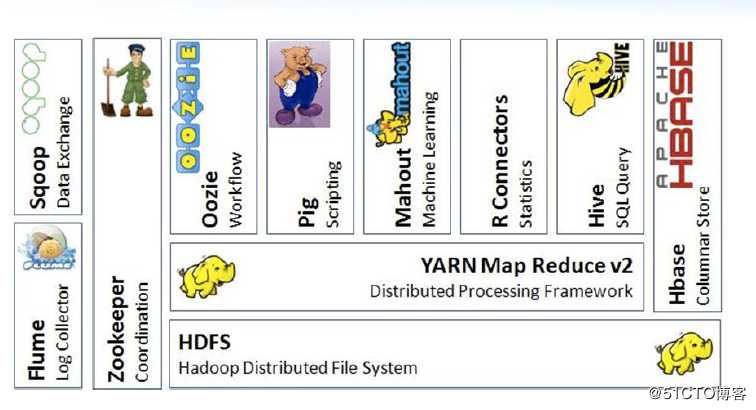
HBase 系统架构与数据模型
系统架构
大致的架构体系
在HBase中,表被分割成多个更小的块然后分散的存储在不同的服务器上,这些小块叫做Region,存放Region的地方叫做RegionServer。Master进程负责处理不同的RegionServer之间的Region的分发。HBase里的HRegionServer和HRegion类代表RegionServer和Region。HRegionServer除了包含一些HRegion之外,还处理两种类型的文件用于数据存储。
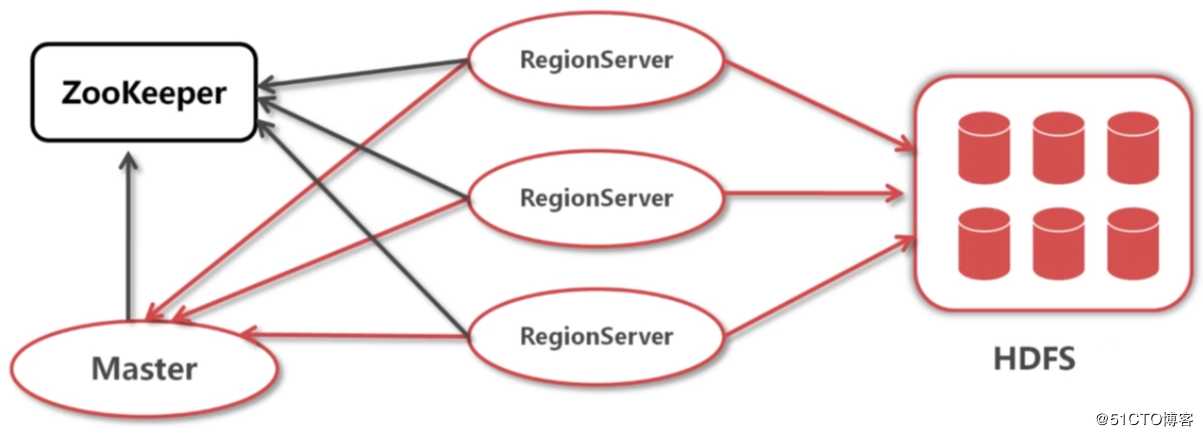
- HBase 依赖 Zookeeper 作为分布式的协调、治理工具,RegionServer、Master也会把自己的信息写到ZooKeeper中
- HBase 还依赖 HDFS 作为底层的文件系统,HBase 的数据最终是存储到 HDFS 服务中的
- HBase 存在两个主要进程,分别是RegionServer和Master
- HBase 中的 RegionServer,可以类比为 HDFS 的 DataNode 即数据节点。客户端通过RegionServer对数据进行读写操作,而RegionServer会负责与 HDFS 进行数据交互
- RegionServer会实时向Master报告自身状态及region等信息。Master知道全局的RegionServer运行情况,可以控制RegionServer的故障转移和region的切分。Master相当于是RegionServer集群的管理者,并且任何时刻只有一个Master在运行
细化的架构体系
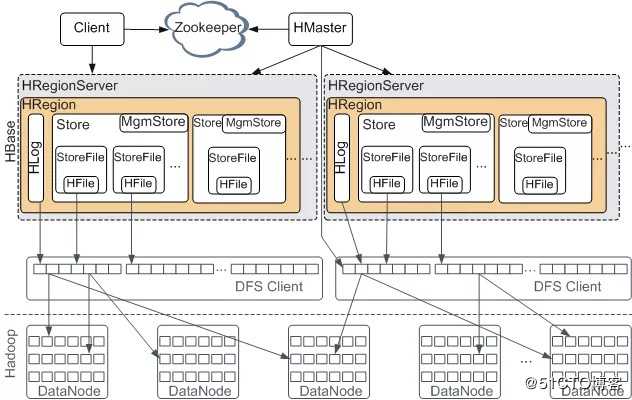
Client
- 客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程
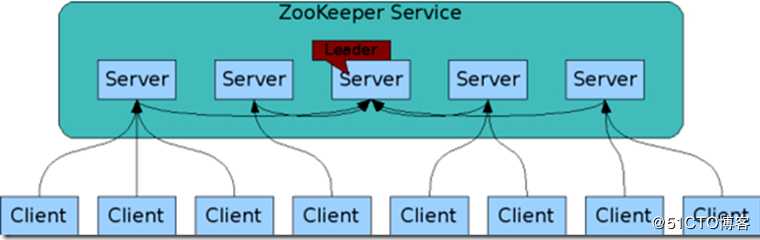
Zookeeper
- Zookeeper作为协调工具可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点故障”的问题
Master
- 主要负责表和Region的管理工作
- 管理客户端对表的增加、删除、修改、查询等操作
- 实现不同RegionServer之间的负载均衡
- 在Region分裂或合并后,负责重新调整Region的分布
- 对发生故障失效的RegionServer上的Region进行迁移
RegionServer
- RegionServer是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求。
- 用户读写数据过程:
- 用户写入数据时,被分配到相应Region服务器去执行
- 用户数据首先被写入到MEMStore和Hlog中
- 只有当操作写入Hlog之后,commit()调用才会将其返回给客户端
- 当用户读取数据时,Region服务器首先访问MEMStore缓存,如果找不到,再去磁盘上面的StoreFile中寻找
- 缓存的刷新:
- 系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记
- 每次刷写都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件
- 每个Region服务器都有一个自己的HLog 文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务。
- StoreFile的合并:
- 每次刷写都生成一个新的StoreFile,数量太多,影响查找速度、
- 调用Store.compact()把多个合并成一个
- 合并操作比较耗费资源,只有数量达到一个阈值才启动合并
读写流程示意图: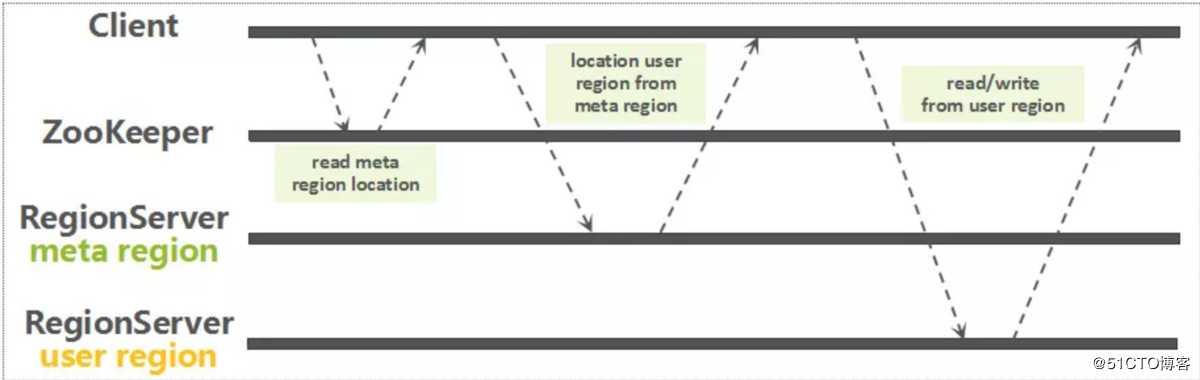
HLog
- 预写日志文件,也叫做WAL(write-ahead log),WAL位于
/hbase/WALs/目录下 - 通常情况,每个RegionServer只有一个WAL实例。在2.0之前,WAL的实现叫做HLog
MasterProcWAL:HMaster记录管理操作,比如解决冲突的服务器,表创建和其它DDL等操作到它的WAL文件中,这个WALs存储在MasterProcWALs目录下,它不像RegionServer的WALs,HMaster的WAL也支持弹性操作,就是如果Master服务器挂了,其它的Master接管的时候继续操作这个文件。
WAL记录所有的HBase数据改变,如果一个RegionServer在MemStore进行FLush的时候挂掉了,WAL可以保证数据的改变被应用到。如果写WAL失败了,那么修改数据的完整操作就是失败的。
MultiWAL:如果每个RegionServer只有一个WAL,由于HDFS必须是连续的,导致必须写WAL连续的,然后出现性能问题。MultiWAL可以让RegionServer同时写多个WAL并行的,通过HDFS底层的多管道,最终提升总的吞吐量,但是不会提升单个Region的吞吐量。
HFile
- 真实存储数据的文件,HFile是Hbase在HDFS中存储数据的格式,它包含多层的索引,这样在Hbase检索数据的时候就不用完全的加载整个文件。索引的大小(keys的大小,数据量的大小)影响block的大小,在大数据集的情况下,block的大小设置为每个RegionServer 1GB也是常见的。
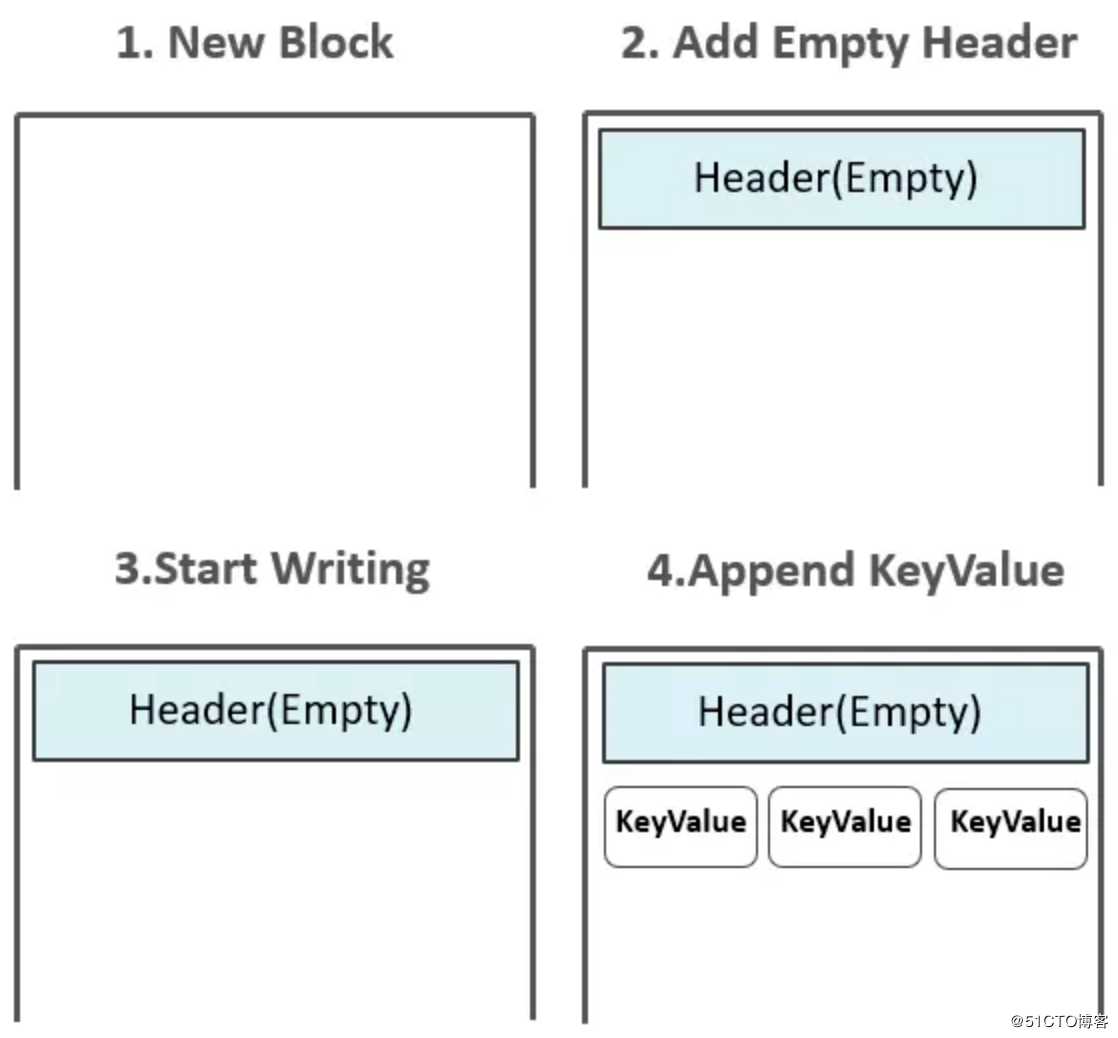
HFile的生成方式:
- 1、起初,HFile中并没有任何Block,数据还存在于MemStore中
- 2、Flush发生时,创建HFile Writer,第一个空的Data Block出现,初始化后的Data Block中为Header部分预留了空间,Header部分用来存放一个Data Block的元数据信息
- 3、而后,位于MemStore中的KeyValues被一个个append到位于内存中的第一个Data Block中
- 4、如果配置了Data Block Encoding,则会在Append KeyValue的时候进行同步编码,编码后的数据不再是单纯的KeyValue模式。Data Block Encoding是HBase为了降低KeyValue结构性膨胀而提供的内部编码机制
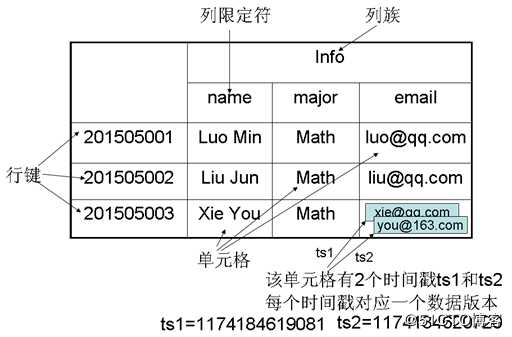
表结构及数据模型
HBase 是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列簇、列限定符和时间戳。在 HBase 中每个值都是一个未经解释的字符串,没有数据类型。用户在表中存储数据,每一行都有一个可排序的行键和任意多的列。
表在水平方向由一个或多个列簇组成,一个列簇中可以包含任意多个列,同一个列簇里面的数据存储在一起。列簇支持动态扩展,可以很轻松地添加一个列簇或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换。
在 HBase 中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的),所以 HBase 的数据是版本化的。
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干列簇。
- 行:每个HBase表都由若干行组成,每一行由行键(row key)来标识。
- 行键:每一行都会存在一个行键,可以类比为关系型数据库中的主键
- 列簇:一个HBase表被分组成许多“列簇”(Column Family)的集合,列簇中的列是有序的,它是基本的访问控制单元。在设计表时,列簇尽量不超过5个,否则会影响性能。
- 列限定符:列簇里的数据通过限定符(列名)来定位。每个列簇中的列数是没有限制的,列只有在插入数据后才存在
- 单元格:在HBase表中,通过行、列簇和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组
byte[] - 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
这是官方文档中给出的一个示例表: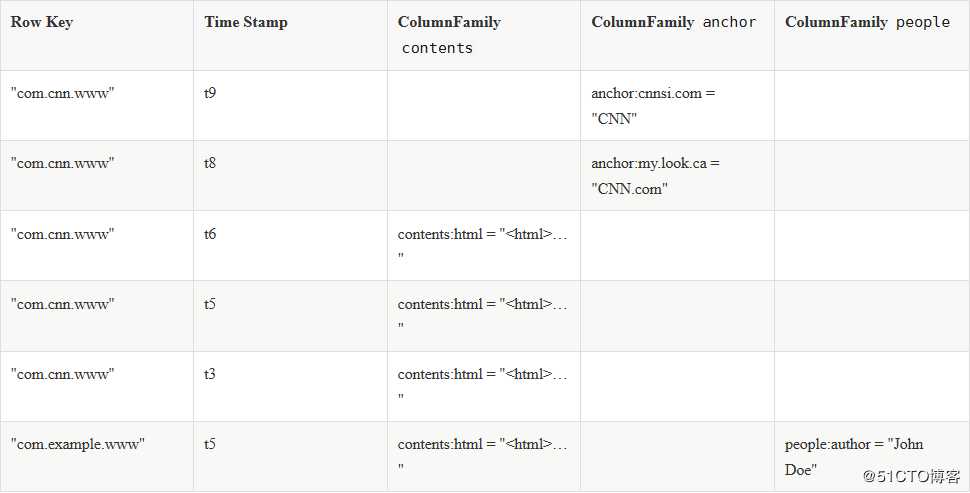
说明:
- 该表中包含两行:
com.cnn.www和com.example.www - 有三个列簇:
contents、anchor和people - 第一行(
com.cnn.www)拥有5个版本,第二行(com.example.www)拥有1个版本 - 对于第一行(
com.cnn.www):contents列簇中包含一列:contents:html- 该列的值为某个网站的html内容
anchor列簇中包含两列:anchor:cnnsi.com和anchor:my.look.cacnnsi.com列的值为CNNmy.look.ca列的值为CNN.com
people列簇中没有任何列
- 对于第二行(
com.example.www):contents列簇中包含一列:contents:html- 该列的值为一段html
anchor列簇中没有任何列people列簇中包含一列:people:author- 该列的值为
John Doe
- 该列的值为
使用json格式表示该表内容如下:
{
"com.cnn.www": {
contents: {
t6: contents:html: "<html>..."
t5: contents:html: "<html>..."
t3: contents:html: "<html>..."
}
anchor: {
t9: anchor:cnnsi.com = "CNN"
t8: anchor:my.look.ca = "CNN.com"
}
people: {}
}
"com.example.www": {
contents: {
t5: contents:html: "<html>..."
}
anchor: {}
people: {
t5: people:author: "John Doe"
}
}
}以上是关于初识 HBase的主要内容,如果未能解决你的问题,请参考以下文章
初识Spring源码 -- doResolveDependency | findAutowireCandidates | @Order@Priority调用排序 | @Autowired注入(代码片段