Flink输出到Kafka(两种方式)
Posted wddqy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink输出到Kafka(两种方式)相关的知识,希望对你有一定的参考价值。
方式一:读取文件输出到Kafka
1.代码
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011
//温度传感器读取样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object KafkaSinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
import org.apache.flink.api.scala._
val inputStream = env.readTextFile("sensor.txt")
val dataStream = inputStream.map(x => {
val arr = x.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble).toString //转成String方便序列化输出
})
//sink
dataStream.addSink(new FlinkKafkaProducer011[String]("localhost:9092", "sinkTest", new SimpleStringSchema()))
dataStream.print()
env.execute(" kafka sink test")
}
}
2.启动zookeeper:参考https://www.cnblogs.com/wddqy/p/12156527.html
3.启动kafka:参考https://www.cnblogs.com/wddqy/p/12156527.html
4.创建kafka消费者观察结果

方式二:Kafka到Kafka
1.代码
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer011, FlinkKafkaProducer011}
//温度传感器读取样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object KafkaSinkTest1 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
import org.apache.flink.api.scala._
//从Kafka到Kafka
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
val inputStream = env.addSource(new FlinkKafkaConsumer011[String]("sensor", new SimpleStringSchema(), properties))
val dataStream = inputStream.map(x => {
val arr = x.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble).toString //转成String方便序列化输出
})
//sink
dataStream.addSink(new FlinkKafkaProducer011[String]("localhost:9092", "sinkTest", new SimpleStringSchema()))
dataStream.print()
env.execute(" kafka sink test")
}
}
2.启动zookeeper:参考https://www.cnblogs.com/wddqy/p/12156527.html
3.启动kafka:参考https://www.cnblogs.com/wddqy/p/12156527.html
4.创建Kafka生产者和消费者,运行代码,观察结果
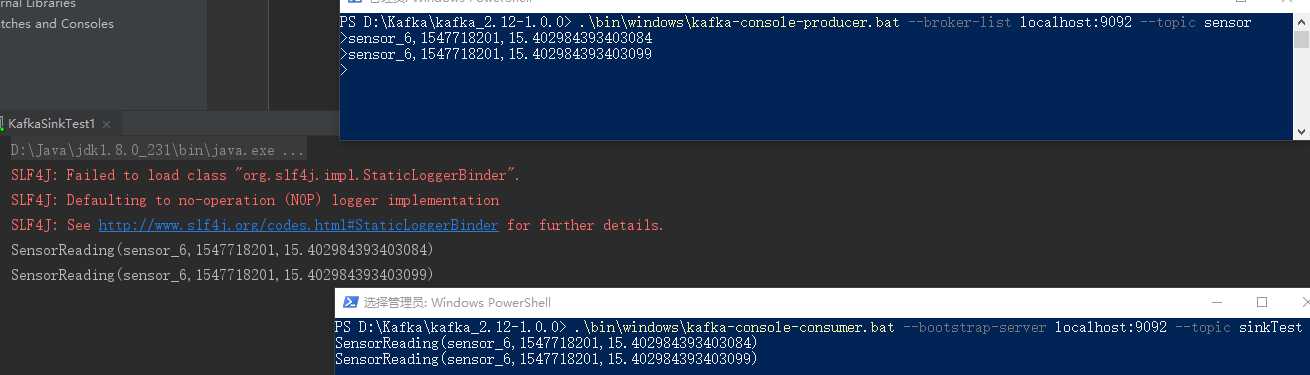
以上是关于Flink输出到Kafka(两种方式)的主要内容,如果未能解决你的问题,请参考以下文章