教育行业漏洞报告平台(Beta)数据爬取分析
Posted qi-lin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教育行业漏洞报告平台(Beta)数据爬取分析相关的知识,希望对你有一定的参考价值。
解决问题
对教育漏洞提交平台的漏洞相关数据进行分析。
内容与要求
爬取网站提交的漏洞的相关信息,对每年漏洞数量,漏洞类型变化,漏洞类型比例,提交漏洞排名,存在漏洞数最多等方面进行统计分析,并可视化
使用工具
Requests 用于爬取页面
BeautifulSoup用于页面分析
Pandas用于数据分析
Time 用于爬取时进度条显示进度
tqdm用于爬取时进度条显示进度
matplotlib用于数据可视化,绘制统计图
wordcloud 用于数据可视化,绘制云图
爬取数据
网站分析
1、网站为:教育行业漏洞报告平台(Beta),该网站是专门针对教育学校网站的漏洞提交搜集平台
2、对网站漏洞页面数据爬取,url为https://src.sjtu.edu.cn/list/?page=1
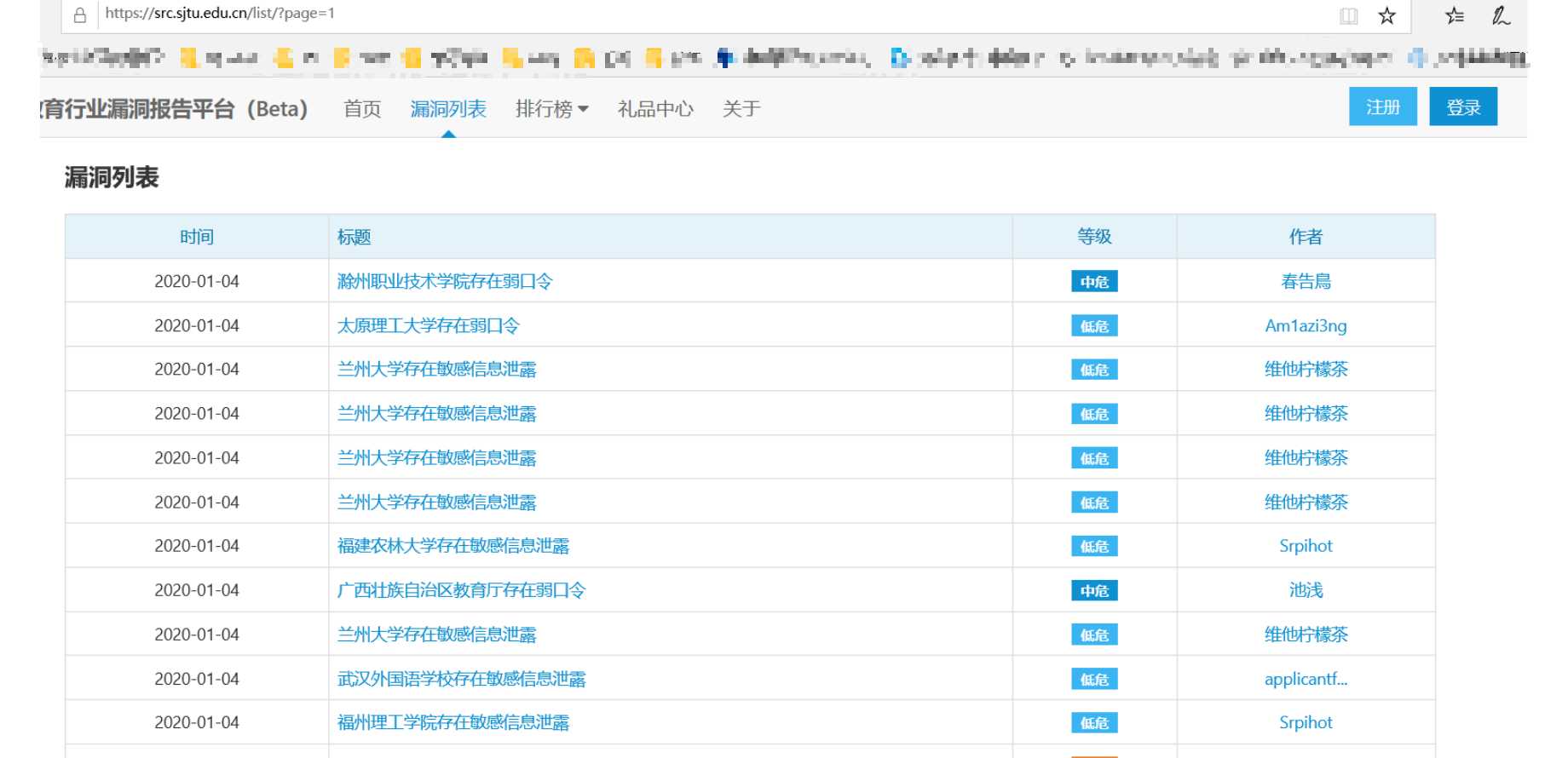
3、截止2020-1-3 22:00,共有2172个页面,所以可以通过修改page的参数请求不同页面
4、查看页面结构,如下图,发现第一个table标签里为所需数据,每一行在tr标签中,每一个表格在td在中,所以通过bs4可以进行进行提取
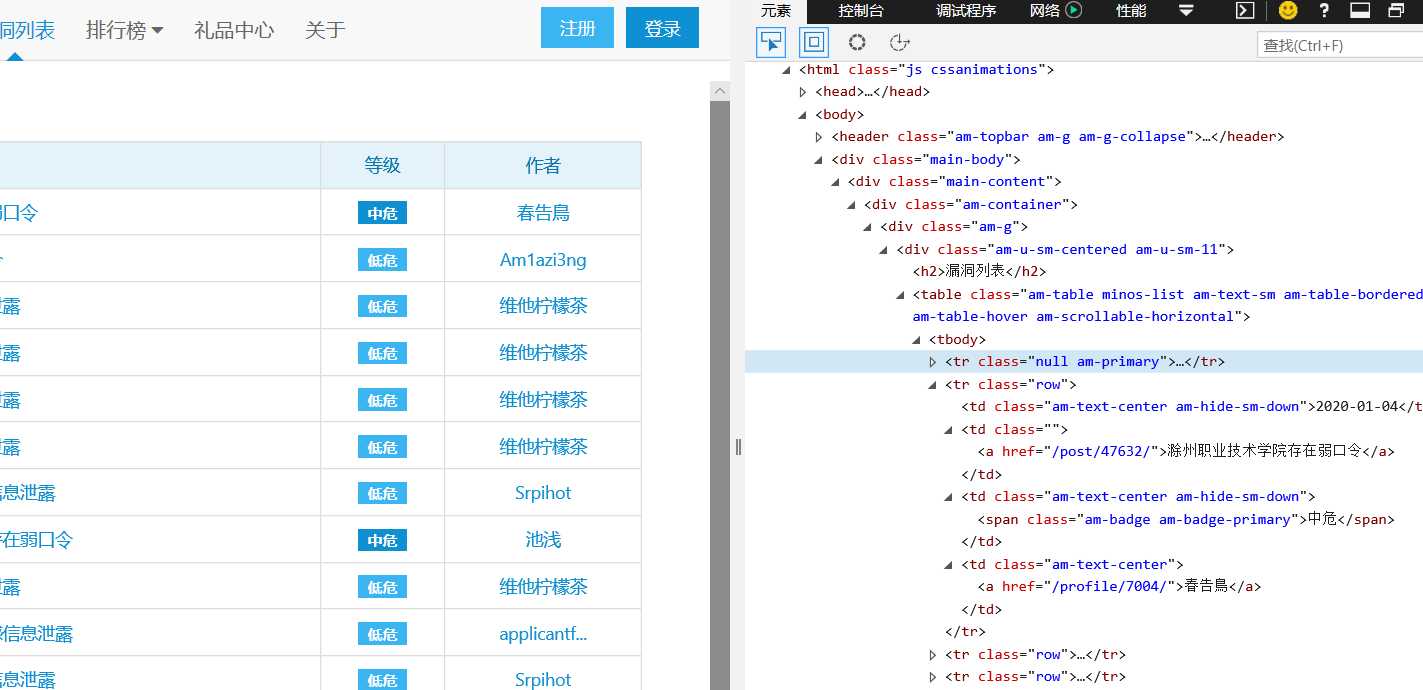
开始爬取

大约一个半小时后
全部保存到excel文件中
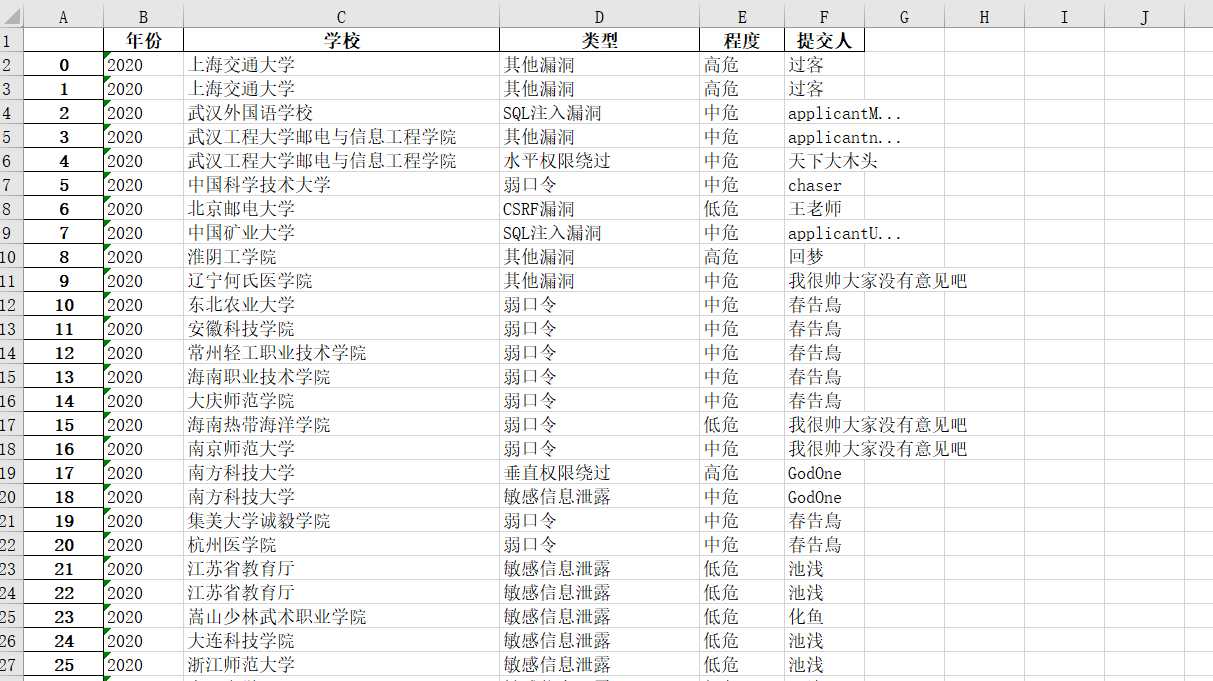
程序如下
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
from tqdm import tqdm
mylist = []
user = {'user-agent': 'Mozilla/5.0'}
for i in tqdm(range(1,2173)):#共有2172页需要爬取,设置url链接中page的参数,其中tqdm用于进度条
url = 'https://src.sjtu.edu.cn/list/?page='+str(i)
r = requests.get(url, headers=user)#请求页面
r.encoding = r.apparent_encoding
html = BeautifulSoup(r.text, 'html.parser')
mytable=html.find('table')#找到页面中的表格
mytr=mytable.find_all('tr')#找到表格中所有行
mytr.pop(0)#去掉数据中表头那一行
#对每一行各个单元格处理
for m in mytr:
tds=m('td')#将这一行所有单元格保存在tds中
j=tds[1].a.string.split()[0]#第二个单元格(这一个单元格保存的数据为xx学校存在xx漏洞)包围在<a>标签中,将其中的字符串取出来,并去掉空格换行等
jj=j.split('存在')#将改字符串通过存在分割
#因为里面的数据有一点不是xx学校存在xx漏洞的形式,需要分别处理
if(len(jj)==2):#如果有存在这个字符
ty = jj.pop()#保存漏洞类型
school = jj.pop()#保存学校
else:#如果没有,将漏洞类型设为其它
school=jj.pop()
ty='其他漏洞'
#将这一行所有内容存在mylist中
mylist.append([tds[0].string.split('-')[0],school,ty,tds[2].string,tds[3].string])#第一个单元格通过-分割,只取年份
time.sleep(2)#一方面降低爬取速度,一方面用于显示爬取进度条
my=pd.DataFrame(mylist,columns=['年份','学校','类型','程度','提交人'])
my.to_excel(r'C:UsersDesktopmy.xlsx')数据分析
因为2020只有1月的数据,所以分析时将2020年的数据先去除data = data.drop(data[data[‘年份‘] == 2020].index)
对每年漏洞数量分析
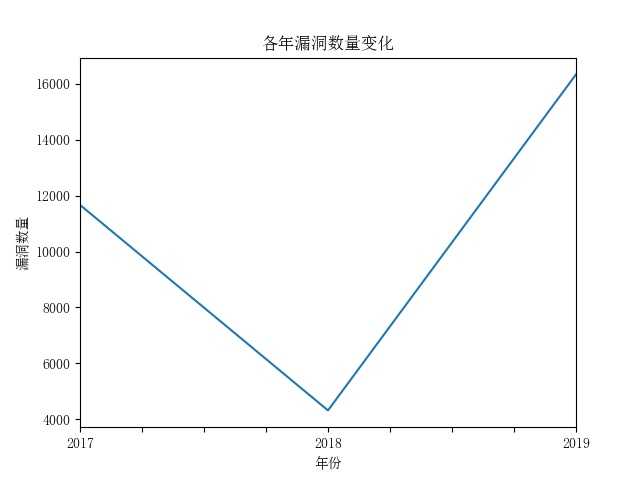
可以看出,漏洞发现数量在这三年是波动的,但总体还是在增加。随着互联网发展,相应的安全问题肯定也越来越多。
对漏洞类型比例的统计
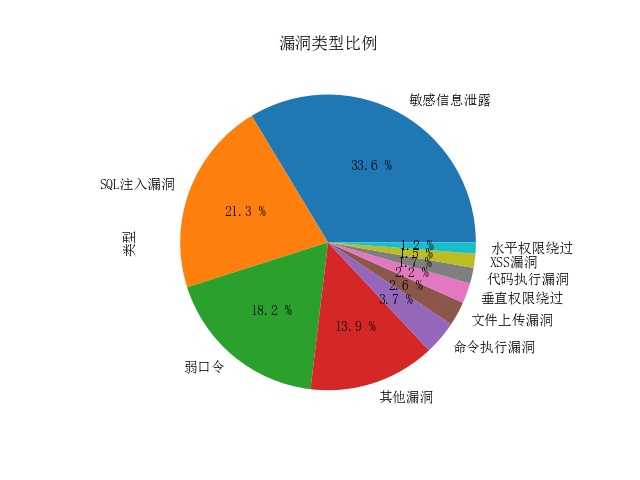
可以看到,漏洞类型前三是常见的信息泄露,sql注入,弱口令。学校网站一般都面向学生,保存有大量学生的个人信息,加上学生的自我保护意识弱。一旦违法者利用漏洞窃取信息,再将这些信息倒卖,或利用信息进行诈骗,将引起严重后果。切实感受学校网站的口令一般都是由规律的学号,身份证号构成,安全性确实不够。
对提交漏洞者分析
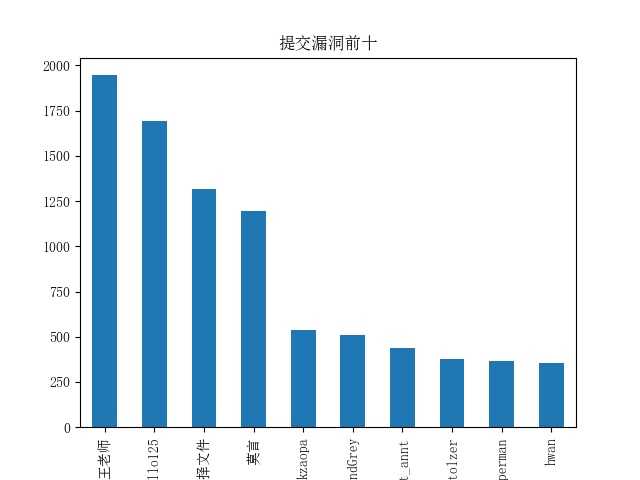
前几名的大佬提交了上千漏洞,虽然一些漏洞可以批量刷出来,但三年间能提交这么多,实在佩服。

所使用的罩图

对学校存在漏洞数分析
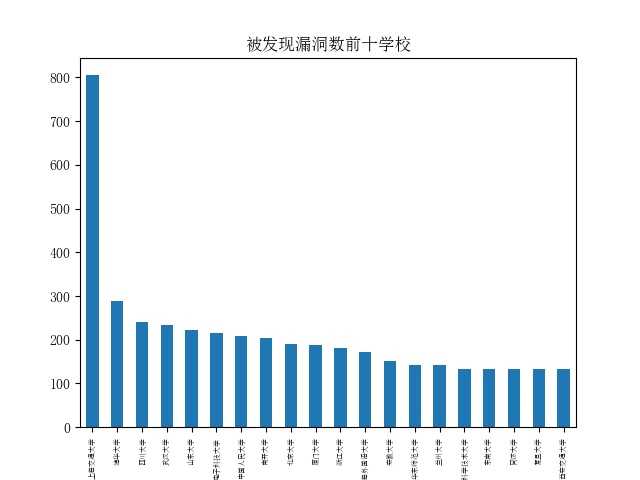
从上图可以看到被存在漏洞数居前列的有很多名校,作为国内有影响力的高校,安全防护也需要同步跟上。另外上海交通大学的漏洞数遥遥领先,远远超出其它高校,个人猜想,可能跟这个平台是由上海交通大学参与建设的关系。
对各年各漏洞程度分析
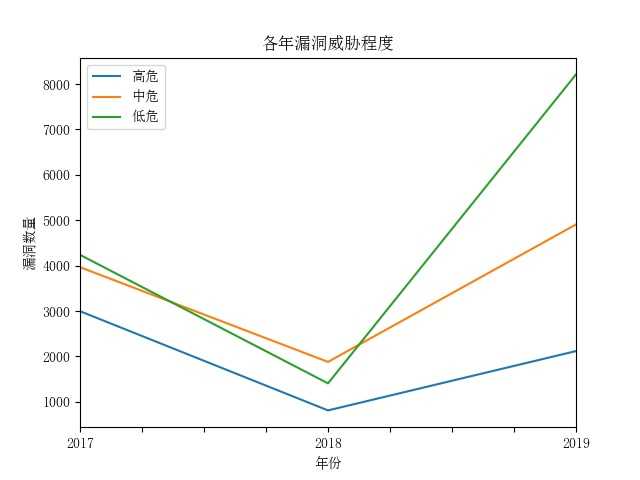
从上图可以比较得出,虽然漏洞数量有增长,但高危漏洞在下降,这也是国家政策推动,人们对安全的意识逐步提高的结果。
程序
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
data = pd.read_excel(r'C:UsersDesktopmy.xlsx')#读取爬取到的数据
data = data.drop(data[data['年份'] == 2020].index)#因为爬取日期为2017-2020.1,所以只分析2017-2019的数据,将2020年的数据全部去掉
#对每年漏洞数量分析
#实际读取相应列就可以,但是发现生成的折线图的点不是顺序连接的,可能是由于x轴的年份是数值形式,所以下几步将年份转化为字符串形式
d = dict(data['年份'].value_counts())#读取年份这一列,转化为字典
#构造新的字典
dd = {}
dd['2017'] = d[2017]
dd['2018'] = d[2018]
dd['2019'] = d[2019]
ddd = pd.Series(dd)
plt.figure(1)#开始画折线图,新建绘图一
ddd.plot()
plt.rcParams['font.sans-serif'] = ['simsun']#以显示中文,奇怪的是,其他字体无法显示,试了几个,这个字体才能显示
plt.xlabel('年份')#x轴标签
plt.ylabel('漏洞数量')#y轴标签
plt.title('各年漏洞数量变化')#标题
plt.savefig(r'C:UsersDesktop各年漏洞数量变化.jpg')#保存
#对漏洞类型比例的统计
t_num = data['类型'].value_counts()[:10]#只取排名前十的
plt.figure(2)#开始画饼图,新建绘图二
t_num.plot.pie(autopct='%.1f %%')#设置显示比例
plt.title('漏洞类型比例')
plt.savefig(r'C:UsersDesktop漏洞类型比例.jpg')
#对提交漏洞者分析
people = data['提交人'].value_counts()[:10]#只取提交漏洞前十
plt.figure(3)#开始画柱状图,新建绘图三
people.plot.bar()
plt.title('提交漏洞前十')
plt.savefig(r'C:UsersDesktop提交漏洞前十.jpg')
#对前十名的昵称绘制云图
c_mask = plt.imread(r'C:UsersDesktophack.jpg') # 读入罩图
wc = WordCloud(font_path="simhei.ttf", # 设置字体
mask=c_mask, # 添加罩图
background_color="white", # 设置背景色
max_font_size=60) # 最大字体
wc.generate_from_frequencies(people) # 产生词云
wc.to_file(r'C:UsersDesktop1.jpg')
#对学校存在漏洞数分析
school = data['学校'].value_counts()[:20]#只取前20名
plt.figure(4)#开始画柱状图,新建绘图四
school.plot.bar()
plt.xticks(fontsize=5)#设置x轴大小,发现转一个角度效果也不好,干脆字体设置小点
plt.title('被发现漏洞数前十学校')
plt.savefig(r'C:UsersDesktop被发现漏洞数前十学校.jpg')
#对各年各漏洞类型数量分析
df = pd.DataFrame(index=['2017', '2018', '2019'])#新建DataFrame类型df
#取出原数据程度为高危的年份那一列,对数量统计,即高危漏洞在各个年出现的数量,再按年份进行升序排列,取得值,插入到df中
df.insert(0, '高危', data[data['程度'] == '高危']['年份'].value_counts().sort_index().values)
df.insert(1, '中危', data[data['程度'] == '中危']['年份'].value_counts().sort_index().values)
df.insert(2, '低危', data[data['程度'] == '低危']['年份'].value_counts().sort_index().values)
plt.figure(5)#开始画折线图,新建绘图五
df.plot()
plt.xlabel('年份')
plt.ylabel('漏洞数量')
plt.title('各年漏洞威胁程度')
plt.savefig(r'C:UsersDesktop各年漏洞威胁程度.jpg')
以上是关于教育行业漏洞报告平台(Beta)数据爬取分析的主要内容,如果未能解决你的问题,请参考以下文章