p86 SRC挖掘-教育行业平台&规则&批量自动化
Posted 正经人_____
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了p86 SRC挖掘-教育行业平台&规则&批量自动化相关的知识,希望对你有一定的参考价值。
本文仅用于信息安全的学习,请遵守相关法律法规,严禁用于非法途径。若观众因此作出任何危害网络安全的行为,后果自负,与本人无关。
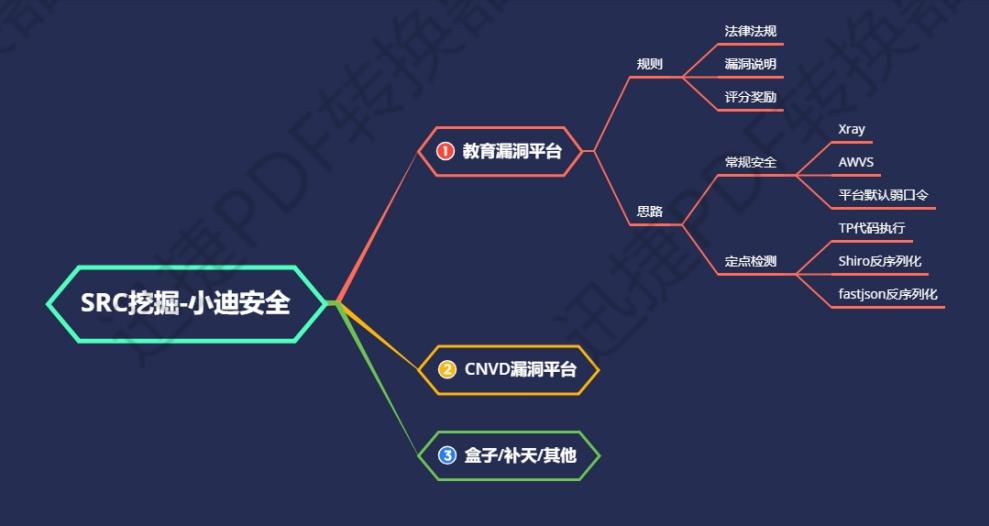
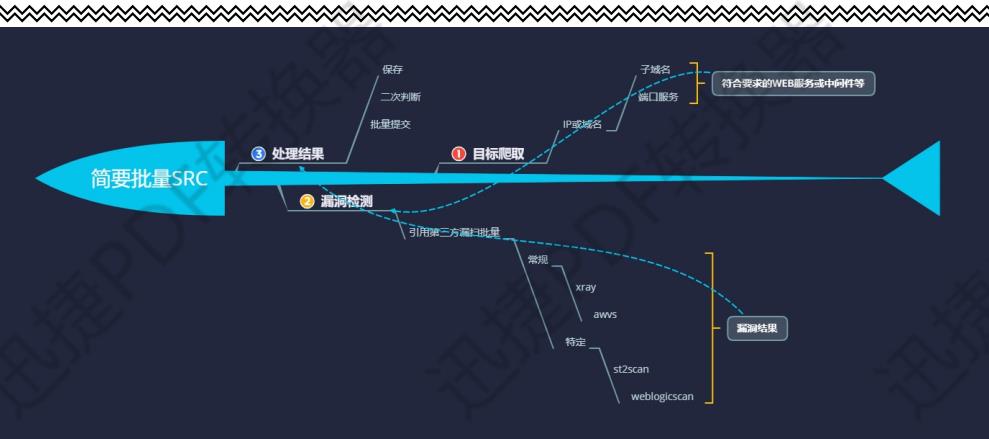
常见的漏洞平台:
教育漏洞报告平台介绍(这篇文章主要就是围绕这个教育平台展开)
演示案例:
-
Python-Fofa-Xray 联动常规批量自动化
-
Python-Fofa-Exploit 联动定点批量自动化
-
Python-Fofa-平台默认口令安全批量自动化
案例一:Python-Fofa-Xray 联动常规批量自动化
常规安全(使用脚本+工具)
思路:
- 找.edu.cn后缀的网站
- 找漏洞平台已经提交过漏洞的网站,进行爬取
1、找.edu.cn后缀的网站
.edu 是互联网的通用顶级域之一,主要供教育机构,如大学等院校使用。它原供全世界的教育机构使用,但实际使用的教育机构大部份位于美国
演示:写个python的脚本帮我们实现
脚本该如何写?我们要收集一下信息
网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统
"edu.cn"&& country="CN" # edu.cn 查找的关键字,用这个后缀名的网站 查找对应country国家,cn 中国(就是查找中国境内网站后缀名是edu.cn的)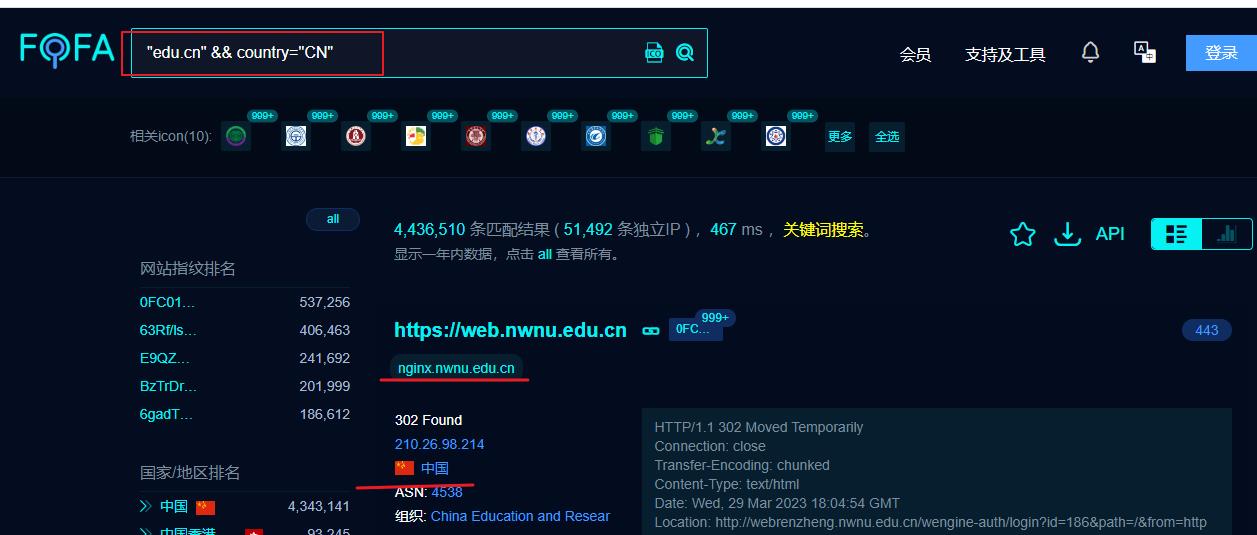

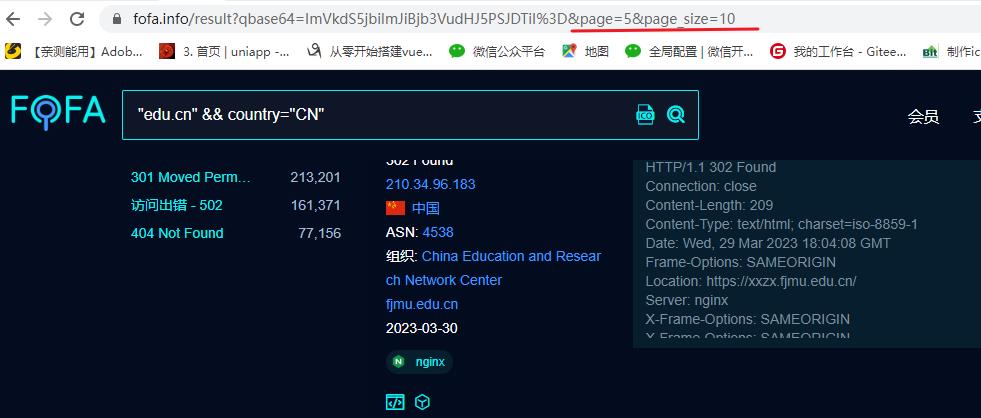
先登录网站,然后用python帮我们实现翻页(不然要是几百上千页能累死)
选择分页后的网站URL:
https://fofa.info/result?qbase64=ImdsYXNzZmlzaCIgJiYgcG9ydD0iNDg0OCI%3D&page=2&page_size=10
 开始写脚本
开始写脚本
1)先获取第一页数据看看情况
fofa.py
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
# 第1页
search_data = '"edu.cn"&& country="CN"' # edu.cn搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
urls = url + search_data_bs # 拼接网站url
result = requests.get(urls).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
print(urls)
print(result.decode('utf-8'))这里发现获取到的数据是网页的源代码,这可不行我们要处理一下数据
2)使用lxml模块中的etree方法提取我们需要的数据(网站的ip)
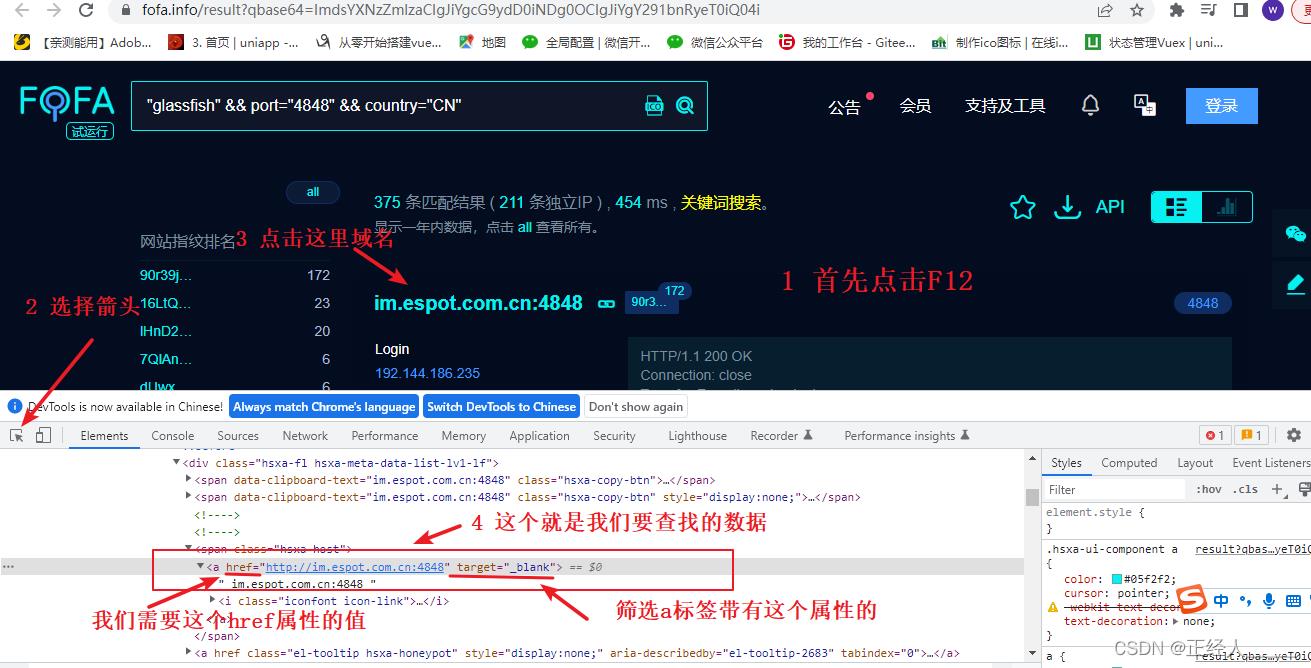
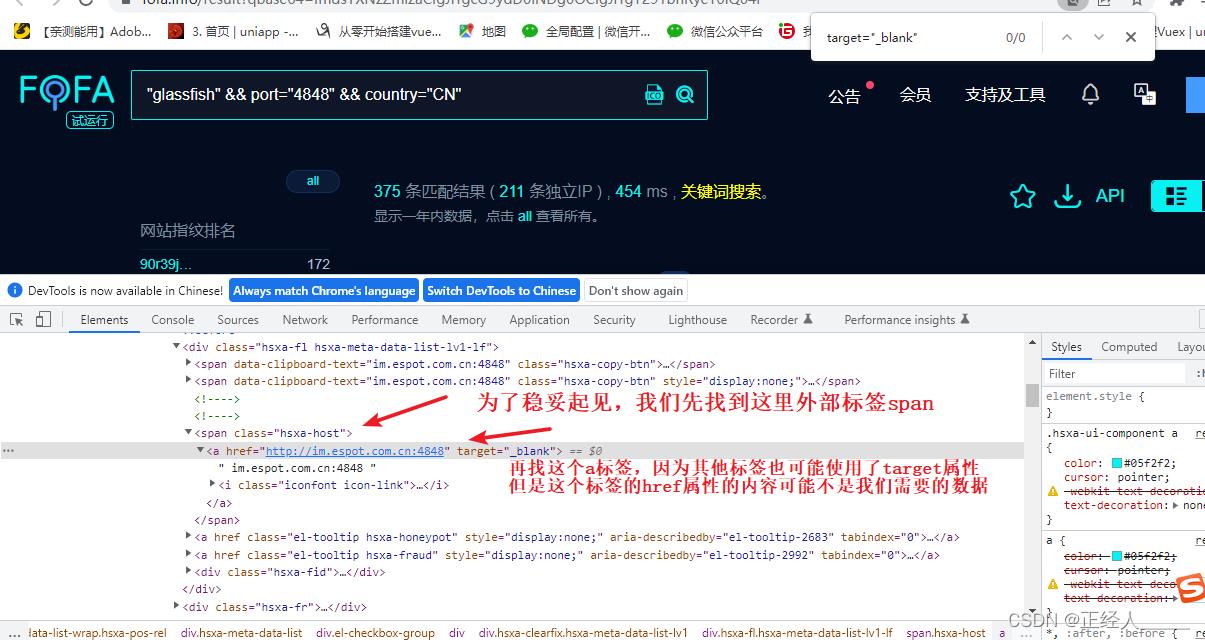
首先需要明确我们需要的数据是啥,对我们最有价值的数据就是使用了glassfish这个服务器搭建的网站的IP/域名
然后要找到IP/域名在源码中的那个位置,方法:在浏览器中先使用fofa搜索网站 -> 打开开发者工具(F12) ->使用开发者工具栏中的箭头点击我们要查看的IP/域名
(这里的图片我懒得重新打注释,就直接用我之前写的文章内的图片,操作都是一样的)
在原来的基础上添加点代码
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
# 第1页 && country="CN"
search_data = '"edu.cn" && country="CN"' # edu.cn搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
urls = url + search_data_bs # 拼接网站url
result = requests.get(urls).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
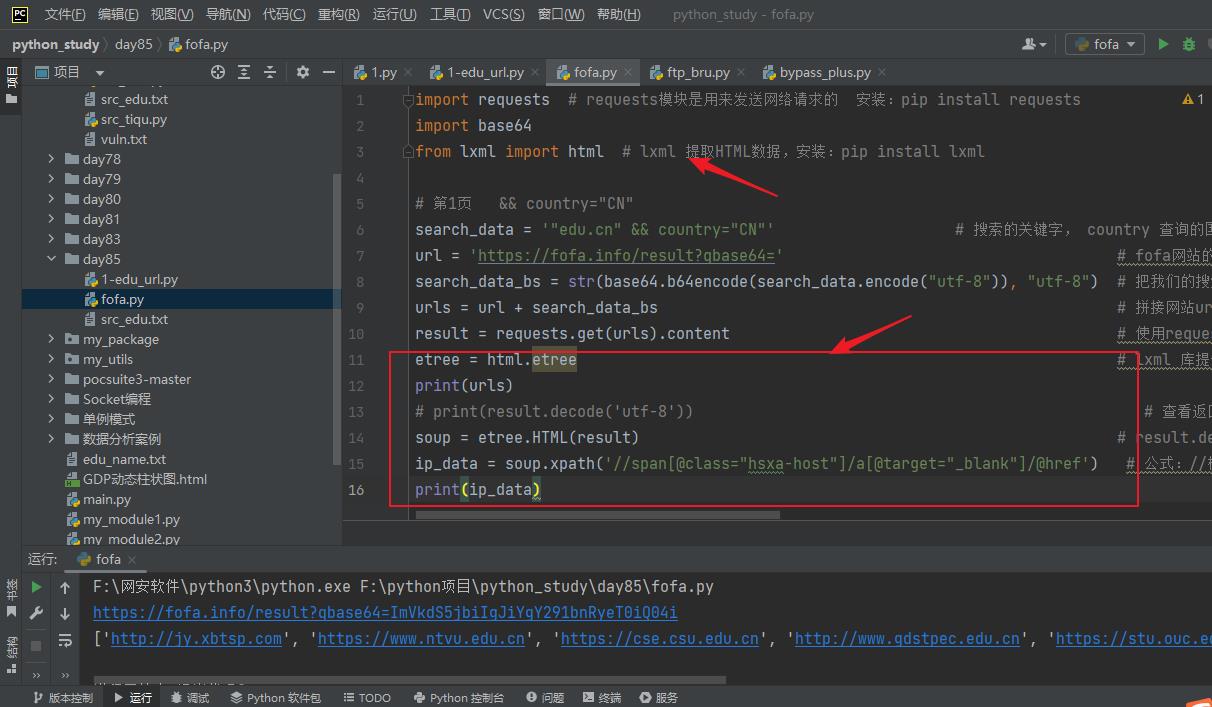
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
print(urls)
# print(result.decode('utf-8')) # 查看返回结果
soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码
ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)
print(ip_data)成功拿到网站的域名/url
3)实现翻页获取数据
现在只是获取了第一页的数据只有10条,我们这里实现一个翻页,但是这个网站需要我们登录之后才能进行翻页,所以我们先登录一下,然后选择翻页查看网站url路径的变化,如果url没有变化就要打开F12或者使用抓包软件进行查看,因为如果没有变化就说明这个翻页的请求不是get可能是post或者其他
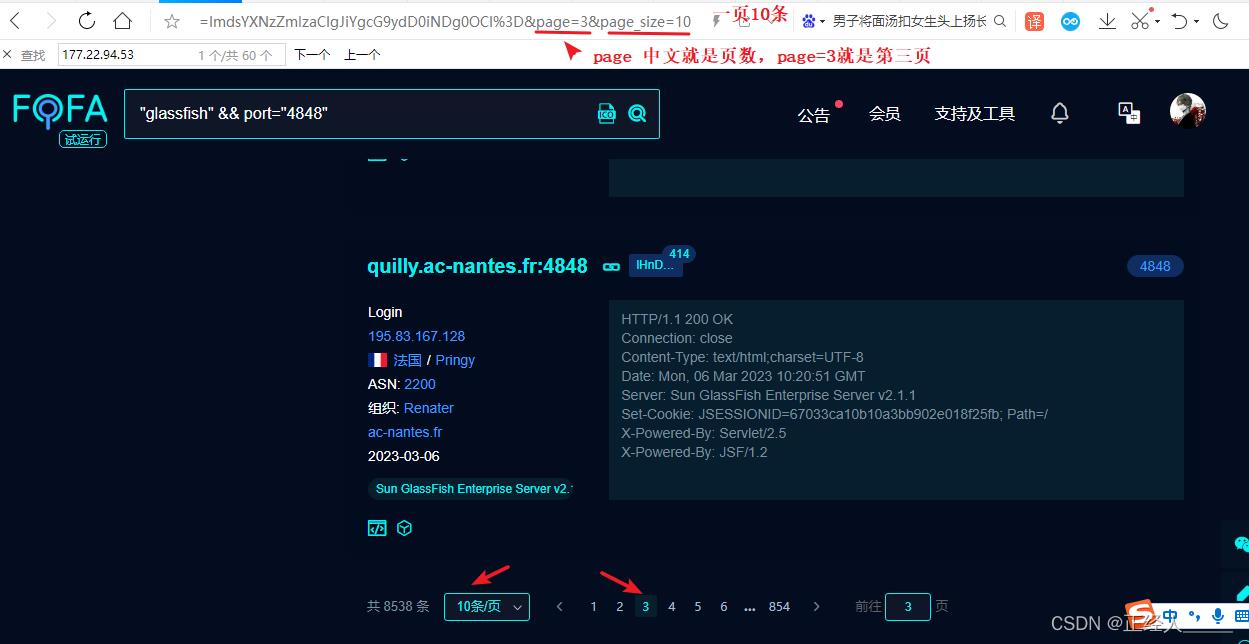
知道了网站是通过page这个参数控制页数后我们也改下自己的代码,如果要改一页的展示数量也可以加上page_size
获取登录后的cookie(用来验证身份的)
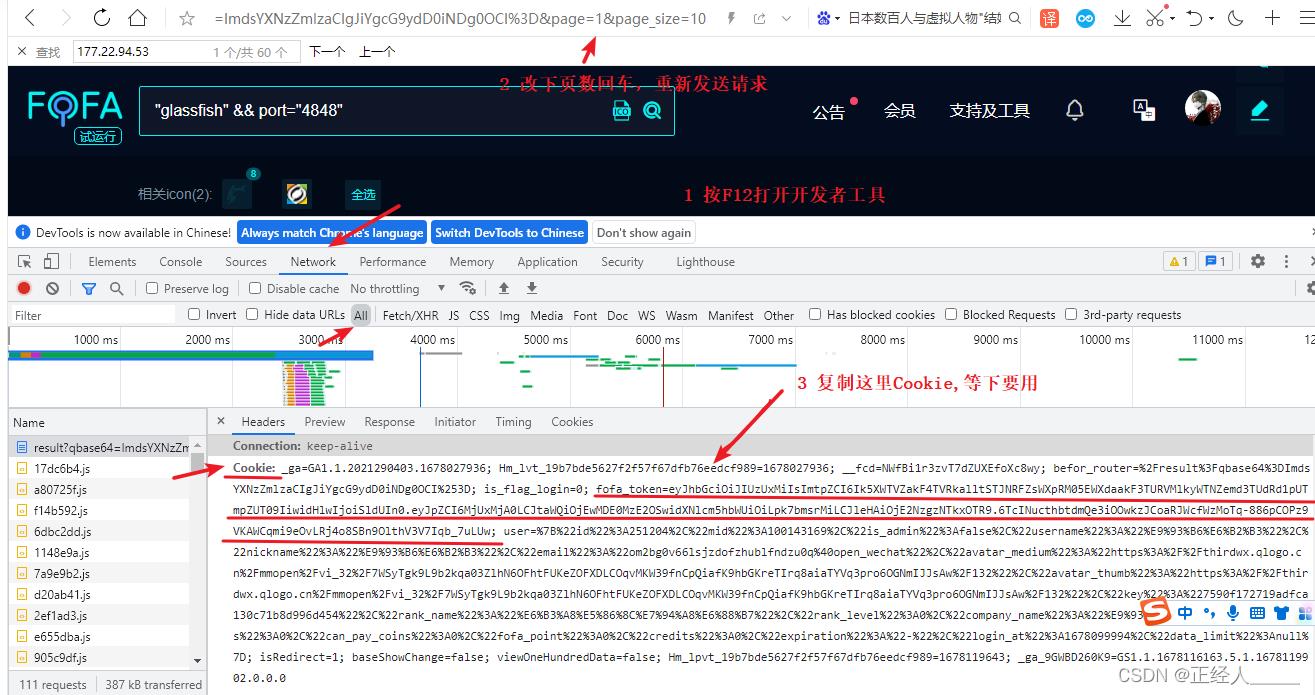
改下代码
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import time
# 循环切换分页
search_data = '"edu.cn"&& country="CN"' # edu.cn搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
headers = # 请求的头部,用于身份验证
# cookie 要改成你自己的,我的账号一退出,这cookie就会过期了
'cookie':'fofa_token=eyJhbGciOiJIUzUxMiIsImtpZCI6Ik5XWTVZakF4TVRkalltSTJNRFZsWXpRM05EWXdaakF3TURVMlkyWTNZemd3TUdRd1pUTmpZUT09IiwidHlwIjoiSldUIn0.eyJpZCI6MjUxMjA0LCJtaWQiOjEwMDE0MzE2OSwidXNlcm5hbWUiOiLpk7bmsrMiLCJleHAiOjE2ODAzNzI2NTd9.h_uVySL9-8aIk2TLbK8UseKkbJBxW2pIXvQ1WwnWRhh-fGoneK48kDQ5XYsTemRThPINHj_tLfNmd9WLJ8pDxg;'
# 这里就是遍历9页数据,如果需要更多也可以把数字改大
for yeshu in range(1,10): # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身
try:
# print(yeshu) # 1,2,3,4,5,6,7,8,9
urls = url + search_data_bs +"&page="+ str(yeshu) +"&page_size=10" # 拼接网站url,str()将元素转换成字符串,page页数, page_size每页展示多少条数据
print(f"正在提取第yeshu页数据")
# urls 请求的URL headers 请求头,里面包含身份信息
result = requests.get(urls,headers=headers).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
print(urls)
# print(result.decode('utf-8')) # 查看返回结果
soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码
ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)
# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重
ipdata = '\\n'.join(set(ip_data)) # join()将指定的元素以\\n换行进行拆分在拼接(\\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)
time.sleep(0.5) # time.sleep(0.5) 阻塞0.5秒,让程序不要执行太快不然容易报错
if ipdata == '': # 我的fofa账号就是普通的账号,没开通会员可以查看上网数据有限,所以这里写个判断
print(f"第yeshu页数据,提取失败数据为空,没有权限")
else:
print(f"第yeshu页数据ipdata")
with open(r'ip.txt','a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加
f.write(ipdata) # write() 方法写入数据
f.close() # close() 关闭保存文件
except Exception as e:
pass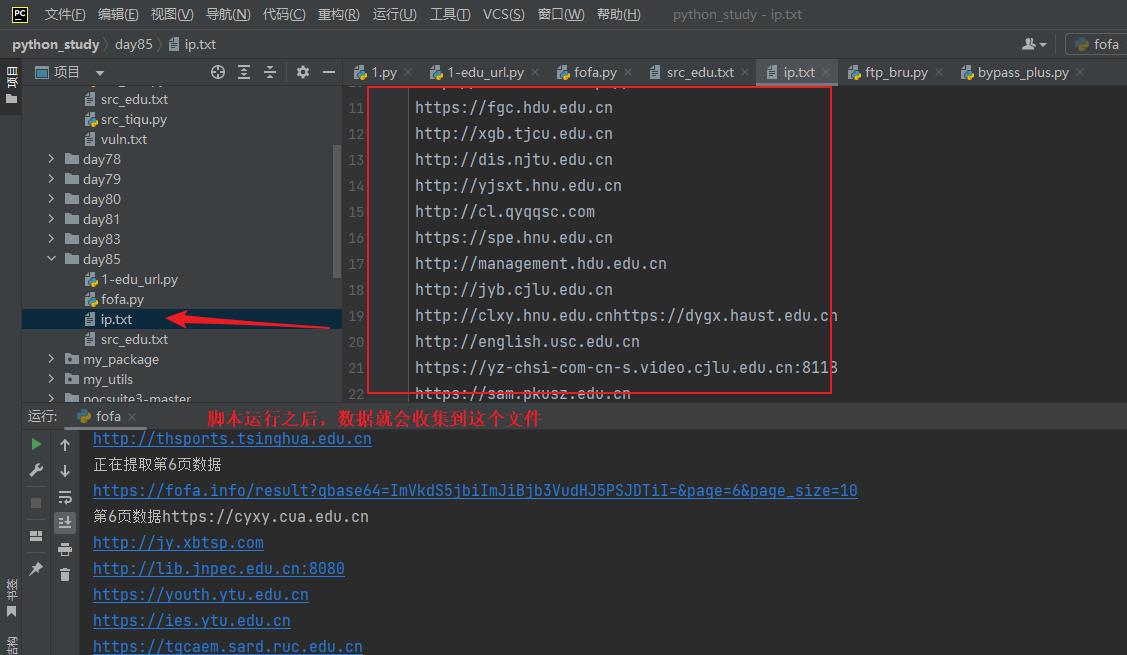
4)优化一下代码开启多线程,真男人就是要快!

import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import time
import threading # 导入threading模块实现多线程
def fofa_tiqu(Start,End):
# 循环切换分页
search_data = '"edu.cn"&& country="CN"' # edu.cn搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
headers = # 请求的头部,用于身份验证
# cookie 要改成你自己的,我的账号一退出,这cookie就会过期了
'cookie':'fofa_token=eyJhbGciOiJIUzUxMiIsImtpZCI6Ik5XWTVZakF4TVRkalltSTJNRFZsWXpRM05EWXdaakF3TURVMlkyWTNZemd3TUdRd1pUTmpZUT09IiwidHlwIjoiSldUIn0.eyJpZCI6MjUxMjA0LCJtaWQiOjEwMDE0MzE2OSwidXNlcm5hbWUiOiLpk7bmsrMiLCJleHAiOjE2ODAzNzI2NTd9.h_uVySL9-8aIk2TLbK8UseKkbJBxW2pIXvQ1WwnWRhh-fGoneK48kDQ5XYsTemRThPINHj_tLfNmd9WLJ8pDxg;'
# 循环爬取数据
for yeshu in range(Start,End + 1): # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身
try:
# print(yeshu) # 1,2,3,4,5,6,7,8,9
urls = url + search_data_bs + "&page=" + str(yeshu) # 拼接网站url,str()将元素转换成字符串,page页数, page_size每页展示多少条数据
print(f"正在提取第yeshu页数据-urls")
# urls 请求的URL headers 请求头,里面包含身份信息
result = requests.get(urls, headers=headers).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
# print(result.decode('utf-8')) # 查看返回结果
soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码
ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)
# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重
ipdata = '\\n'.join(set(ip_data)) # join()将指定的元素以\\n换行进行拆分在拼接(\\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)
if 'http' in ipdata: # 判断ipdata中是否存在http字符串,存在说明数据获取成功
print(f"第yeshu页数据ipdata")
with open(r'ip.txt', 'a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加
f.write(ipdata) # write() 方法写入数据
except Exception as e:
pass
if __name__ == '__main__': # __main__ 就是一个模块的测试变量,在这个判断内的代码只会在运行当前模块才会执行,在模块外部引入文件进行调用是不会执行的
yeshu = int(input("您要爬取多少页数据(整数):"))
thread = 5 # 控制要创建的线程,本来开10个但是太快了服务器反应不过来,获取到的数据少了很多
# 创建多线程,这个循环的次数越多创建的线程的次数就越多,线程不是越多越好,建议5到10个
for x in range(1,thread + 1):
i = int(yeshu / thread) # 页数除线程数(目的是让每一个线程都获取部分数据,分工)
End = int(i * x) # 结束的页数,设yeshu=50: 5、10、15、20、25...
Start = int(i * (x-1) +1) # 开始的页数, 1、6、11、16、21
# 我上面这样写的目的就是,让线程分工合作。如:线程1就去获取1 -5页的数据、线程2就去获取6 -10页的数据...
# print(Start,End)
t = threading.Thread(target=fofa_tiqu,kwargs="Start":Start,"End":End) # 创建线程对象,target=执行目标任务名,args 以元组的形式传参,kwargs 以字典的形式传参
t.start() # 启动线程,让他开始工作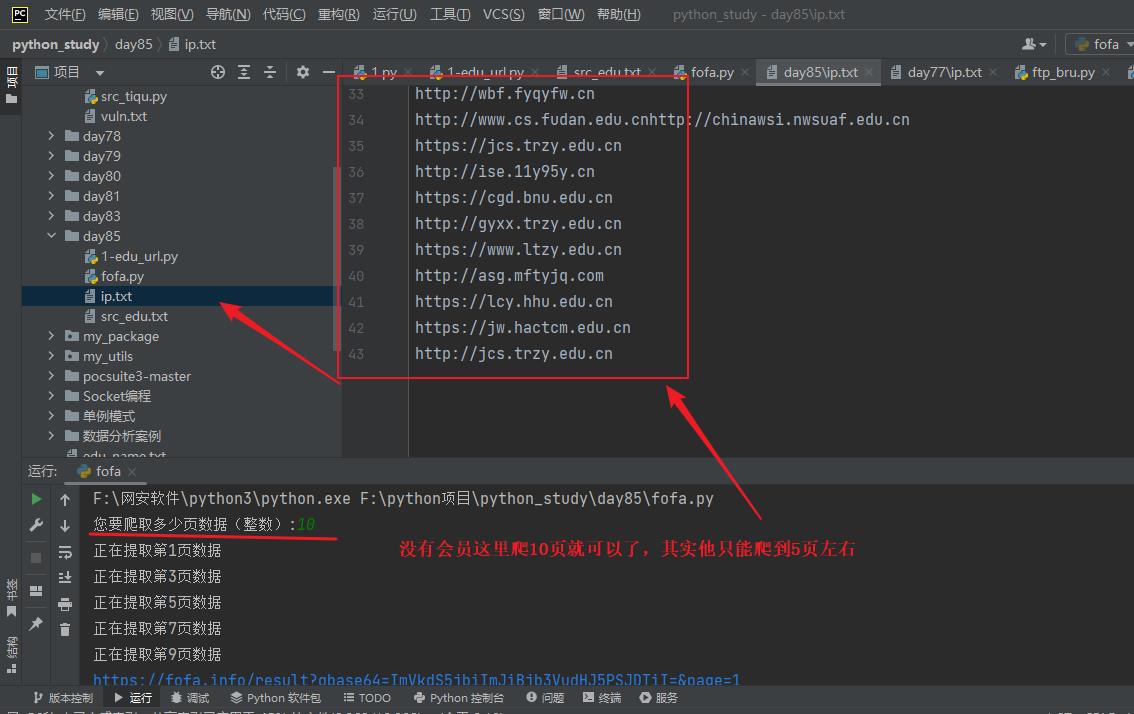
我这里使用awvs14检测漏洞
1)有个url后我们就可以用工具批量检测,安装工具
安装: docker pull xiaomimi8/docker-awvs-14.7.220401065
启动用法: docker run -it -d -p 13443:3443 xiaomimi8/docker-awvs-14.7.220401065
登录: Username:admin@admin.com password:Admin123 2)这里使用脚本批量添加目标
2)这里使用脚本批量添加目标
获取urlkey
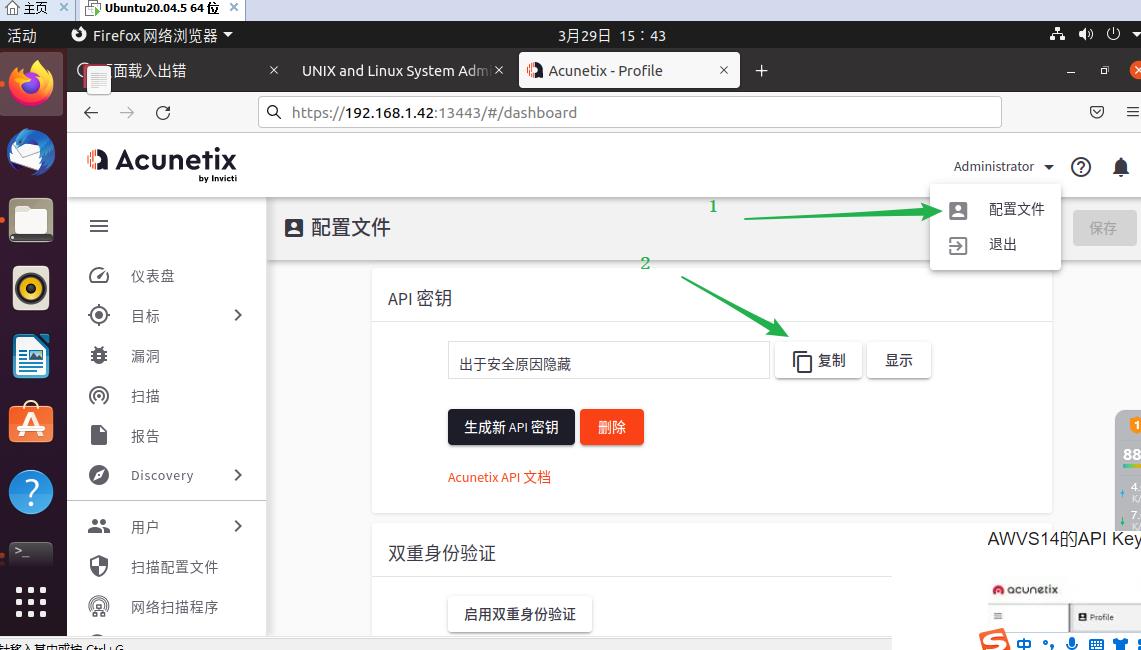
要配置文件:url、kay

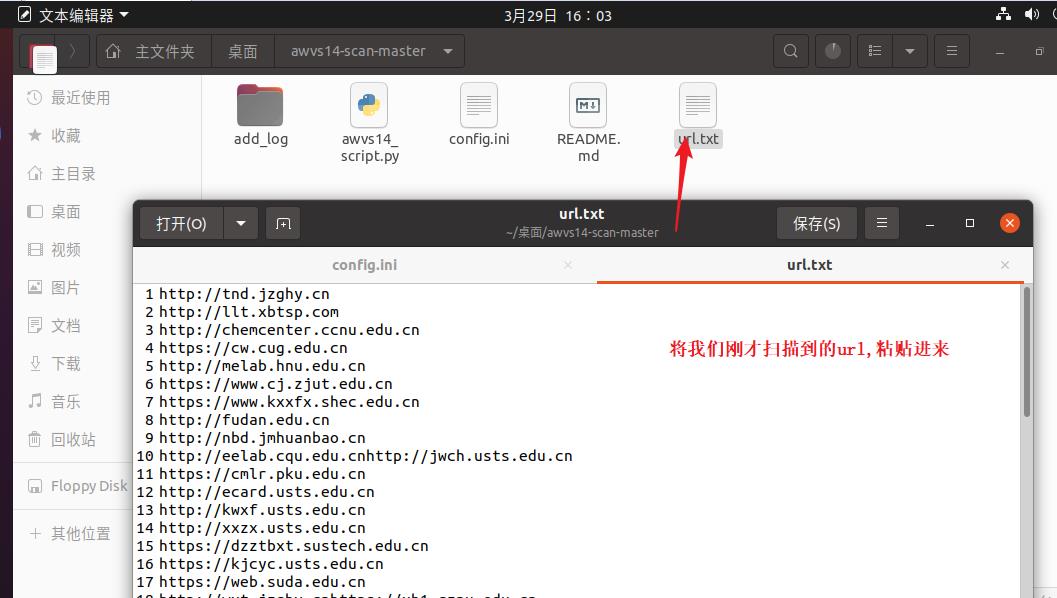
将刚才扫描出来的url,粘贴到url.txt
运行脚本
python3 awvs14_script.py
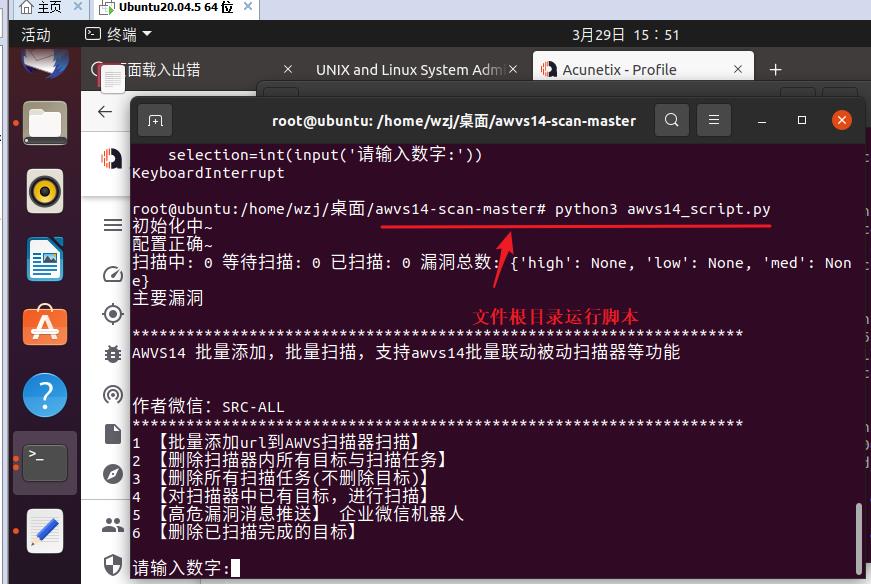
输入:1
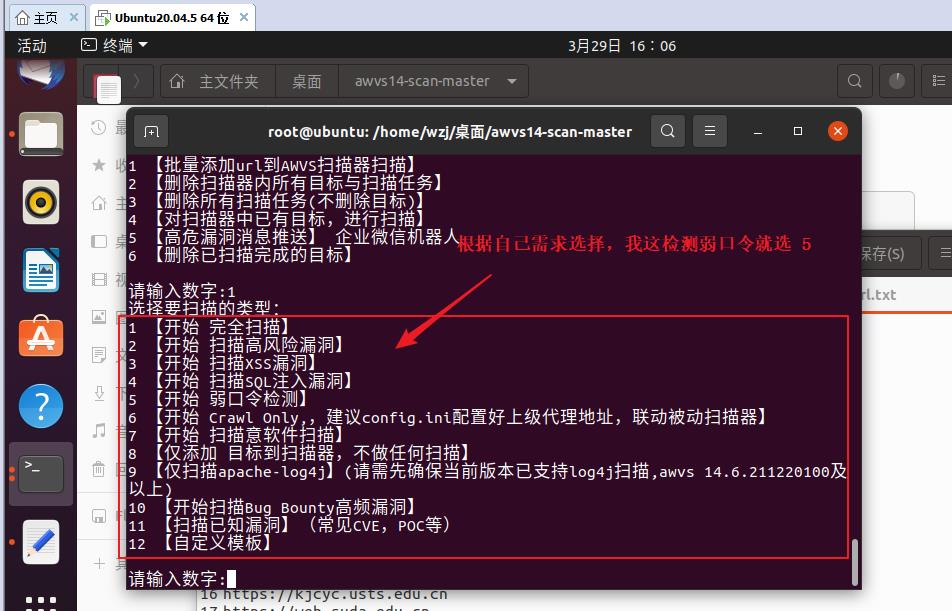
输入:5
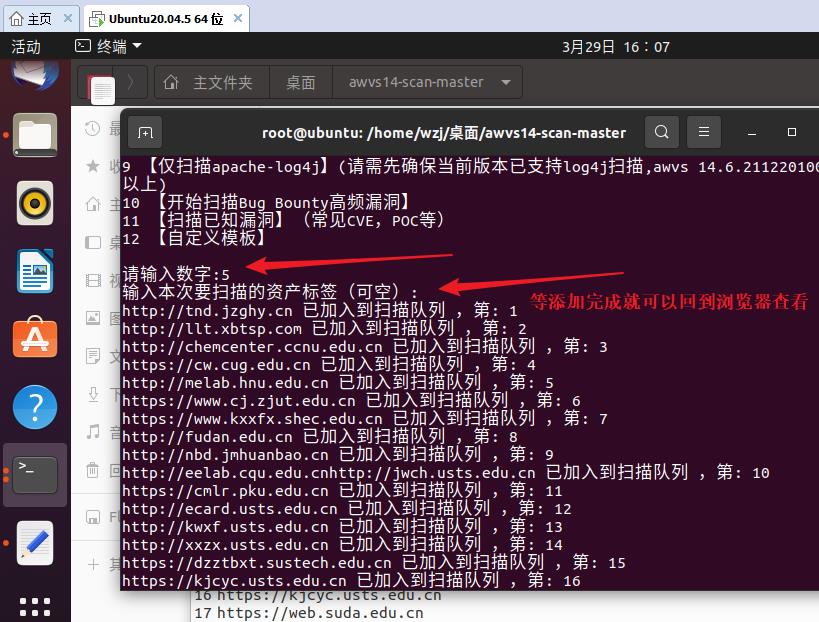

这个脚本有问题每次扫描完都死机
解决:我不在虚拟机运行了,改在真实机登录,使用Xshell连接虚拟机运行代码




。。。。。嘛的,真实机扫描都卡。。。。我现在觉得不是脚本的问题应该是虚拟机的问题,直接我的windows主机安装看看
kali - Whatweb(扫描工具)与acunetix(漏洞扫描工具 )_正经人_____的博客-CSDN博客
安装过程中我安装的过程比我链接中的多一步,这里勾上
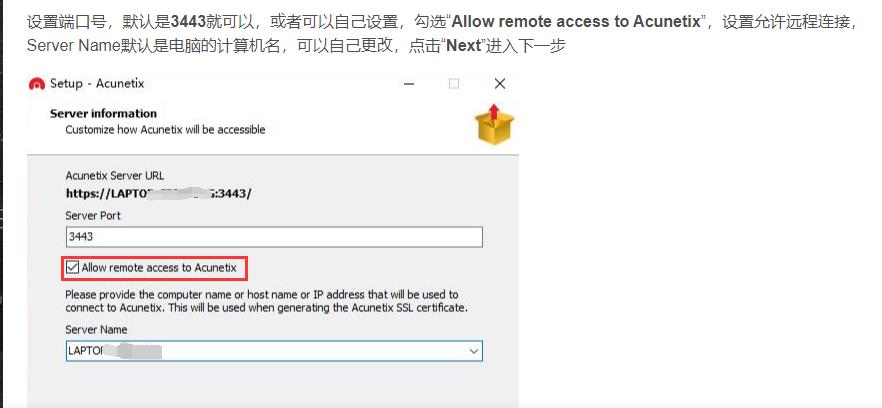
安装完成后,重新配置脚本
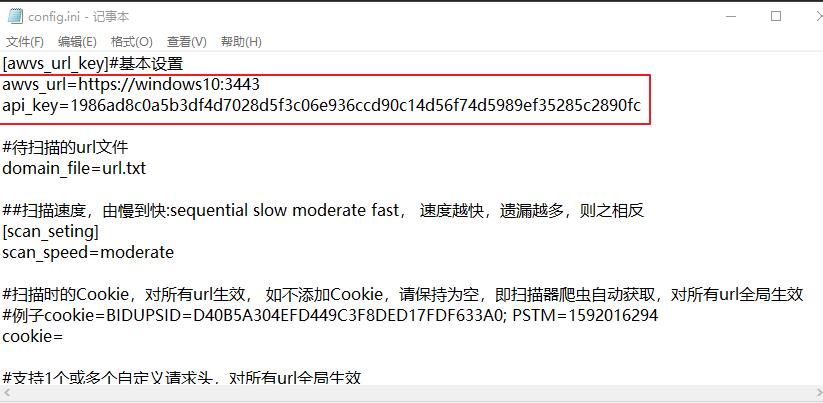
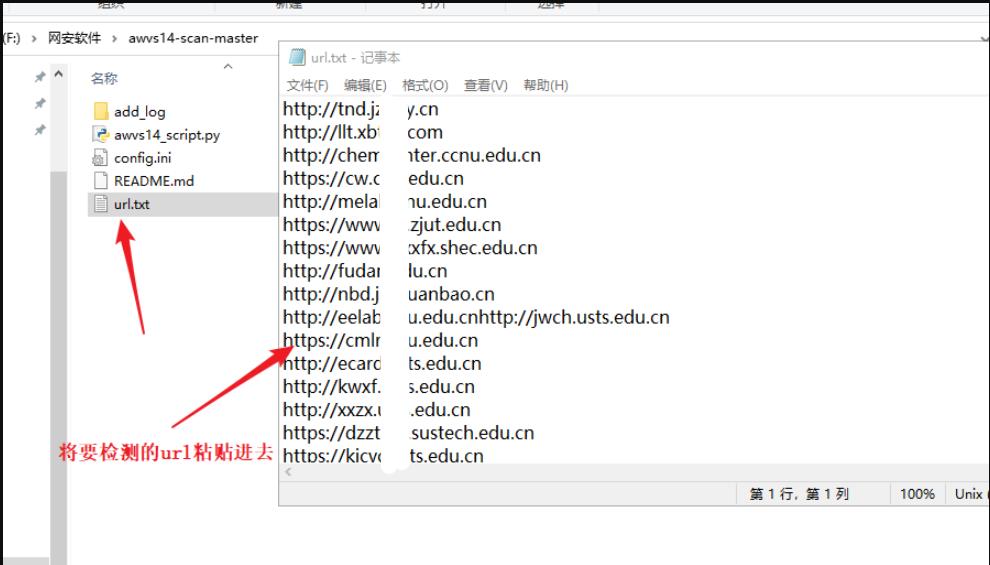
运行脚本
python awvs14_script.py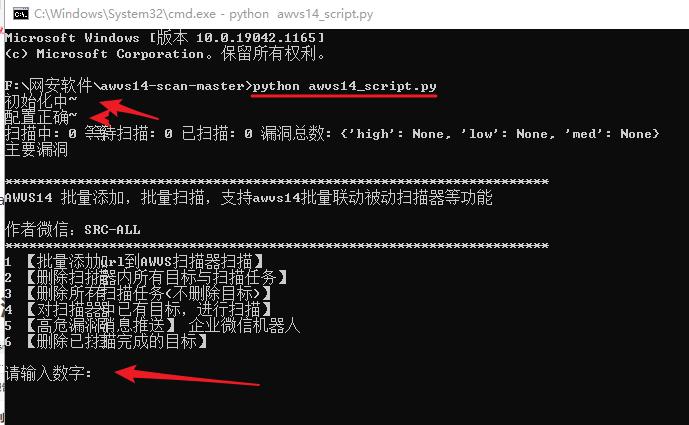
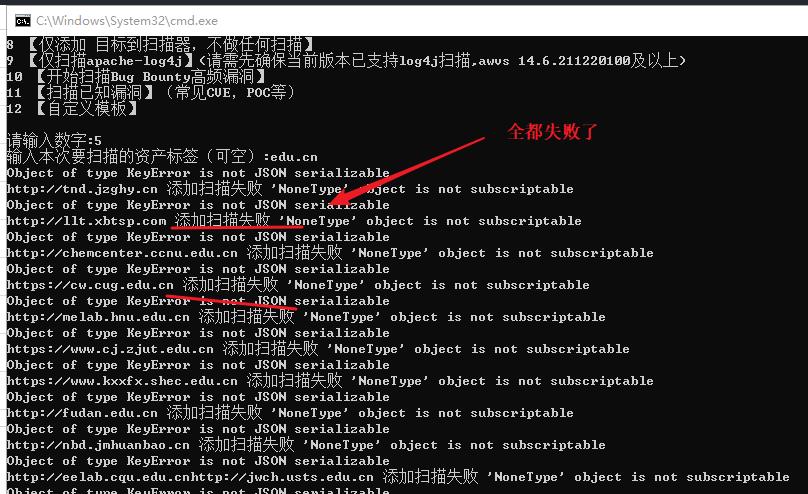
原因:我想了一下才发现我安装的软件版本号是12,这个脚本是14的,要换个脚本
重新在github上下载个一个适合awvs12使用的脚本,重新配置一下
运行脚本
运行脚本往平台添加记录
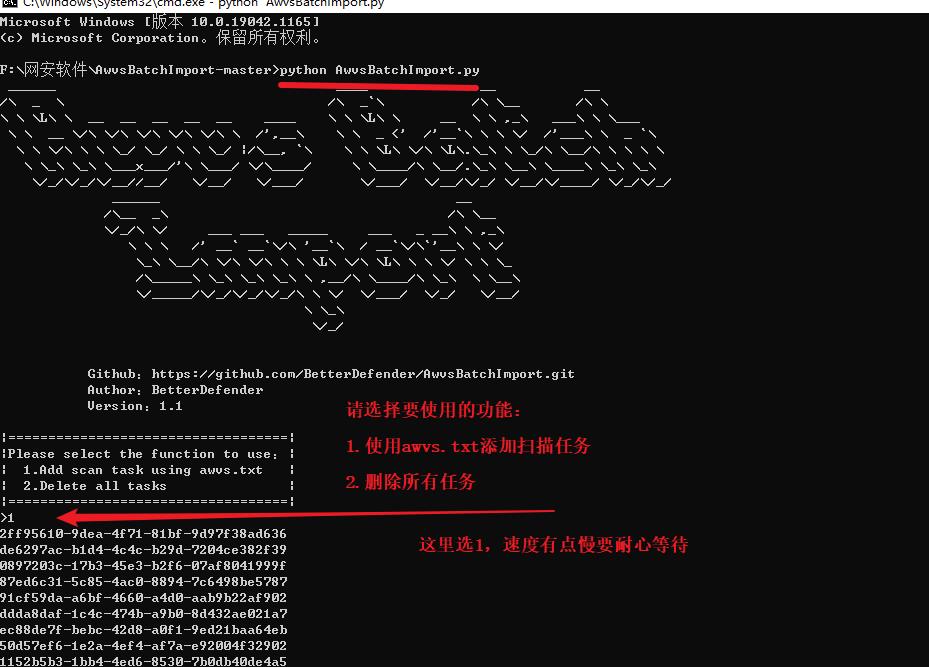
# 注意:虽然我的命令是python但是我安装的是python3,只是我的python可执行文件没有改名
python AwvsBatchImport.py 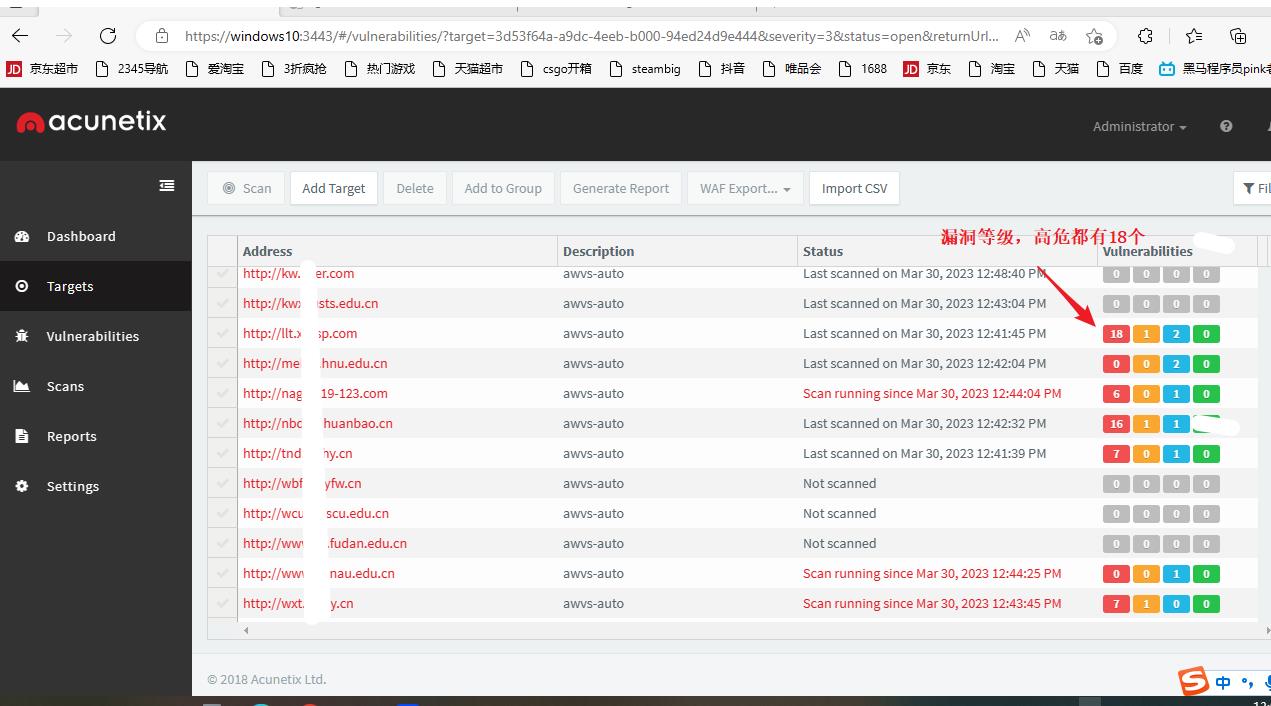

2、找漏洞平台已经提交过漏洞的网站,进行爬取
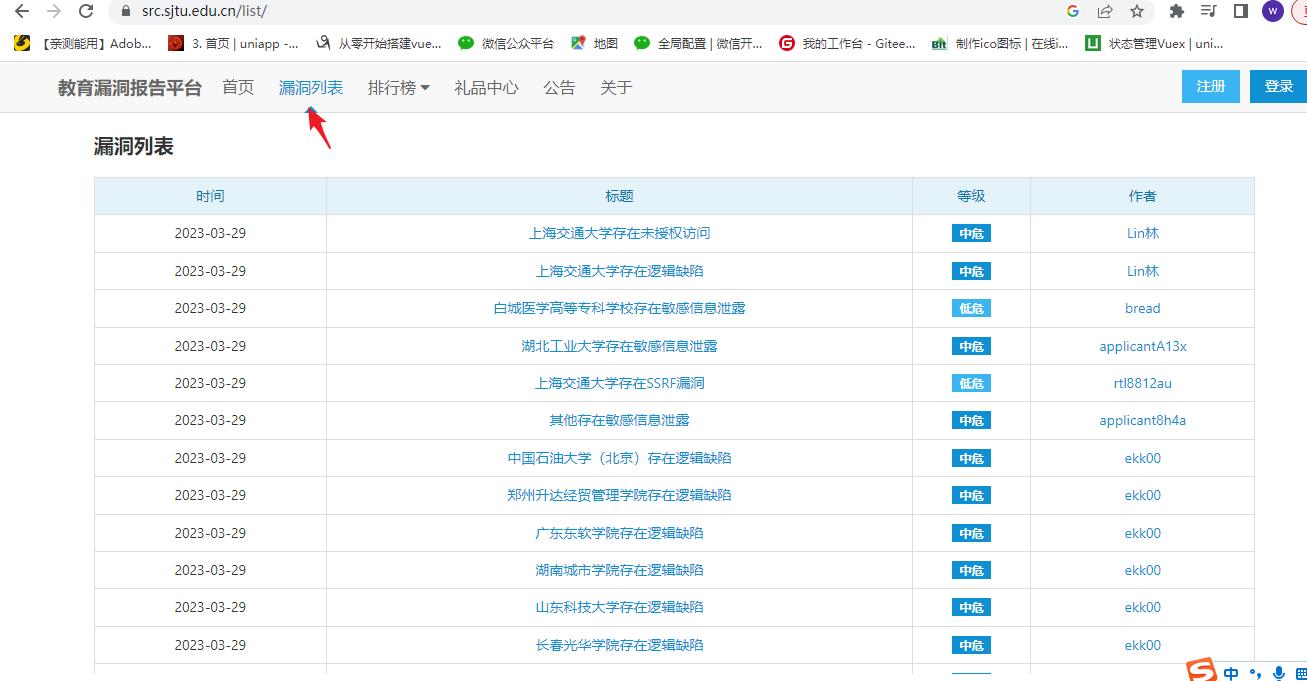
演示:写个python的脚本帮我们实现
1)收集漏洞信息
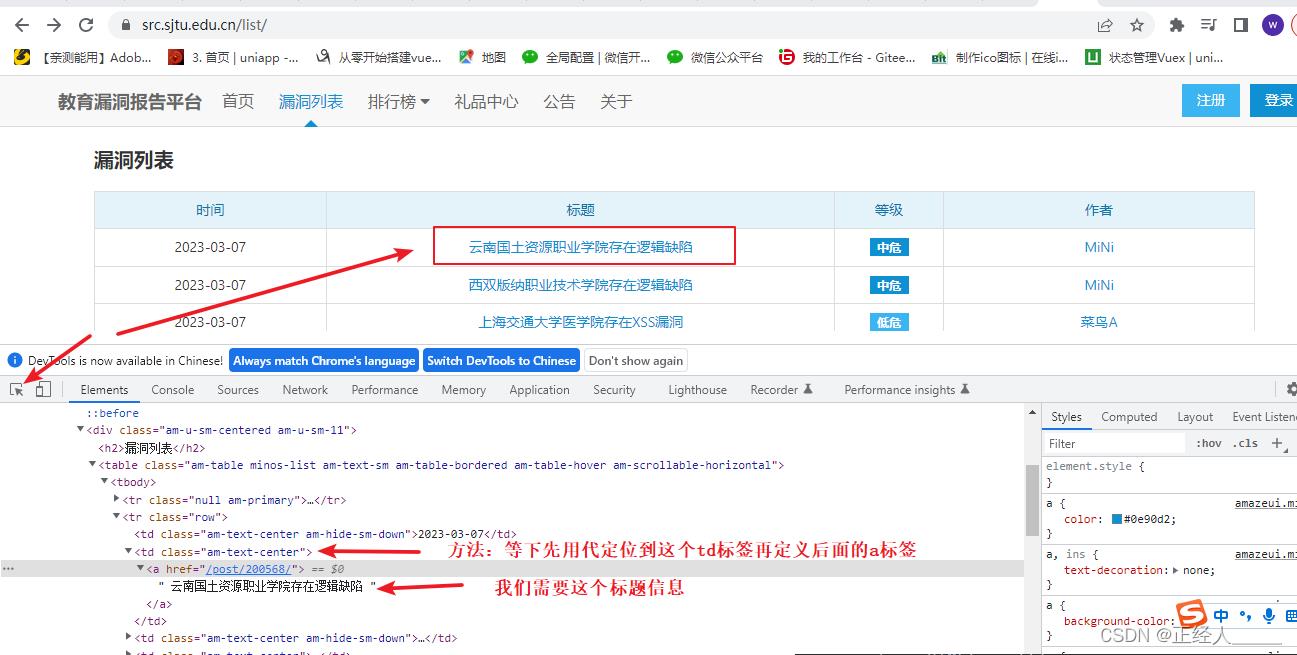
1-edu_url.py
import requests
from lxml import html
# 从教育漏洞报告平台中提取之前网络安全的前辈提交的漏洞报告
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
# 这里循环的是页数(数据的页数),我这里搞少一点爬取50页
for i in range(1,51): # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身
url='https://src.sjtu.edu.cn/list/?page='+str(i)
data = requests.get(url).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
# print(data.decode('utf-8')) # 请求返回的HTML代码
soup = etree.HTML(data)
result = soup.xpath('//td[@class="am-text-center"]/a/text()') # 提取符合标签为td属性class值为am-text-center这个标签内的a标签text()a标签的值/内容
results = '\\n'.join(result).split() # join()将指定的元素以\\n换行进行拆分在拼接 split()方法不传参数就是清除两边的空格
print(results)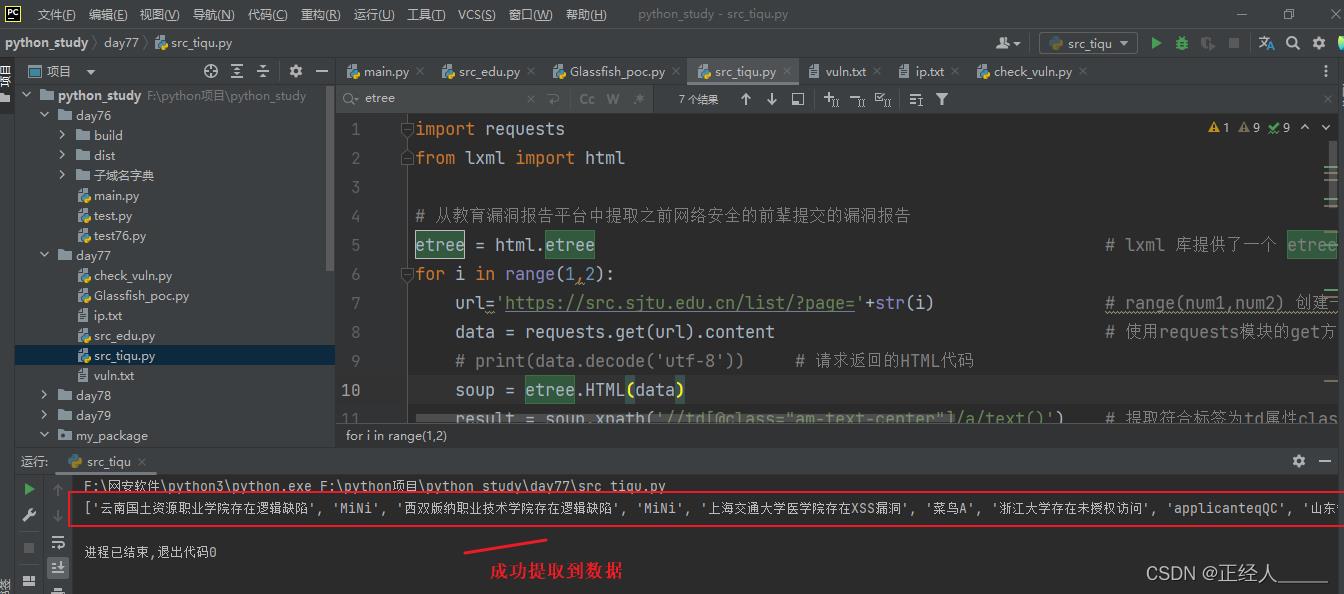
2)优化代码,并把收集到的数据保存到本地文件中并开启多线程(开启多线程你就是快男 )
)
import requests # requests模块是用来发送网络请求的 安装:pip install requests
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import threading # 导入threading模块实现多线程
# 从教育漏洞报告平台中提取之前网络安全的前辈提交的漏洞报告
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
def src_tiqu(Start,End):
"""
src_tiqu 从教育漏洞报告平台中提取之前网络安全的前辈提交的漏洞报告
:param Start: 开始爬取的页数
:param End: 结束爬取的页数
:return: None
"""
for i in range(Start,End + 1):
url='https://src.sjtu.edu.cn/list/?page='+str(i) # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身
print(f'正在读取Start~End页数据')
try:
data = requests.get(url).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
# print(data.decode('utf-8')) # 请求返回的HTML代码
soup = etree.HTML(data)
result = soup.xpath('//td[@class="am-text-center"]/a/text()') # 提取符合标签为td属性class值为am-text-center这个标签内的a标签text()a标签的值/内容
results = '\\n'.join(result).split() # join()将指定的元素以\\n换行进行拆分在拼接 split()方法不传参数就是清除两边的空格
print(results)
for edu in results: # 遍历results列表拿到每一项
# print(edu)
with open(r'src_edu.txt', 'a+', encoding='utf-8') as f: # open()打开函数 with open打开函数与open()的区别就是使用完成后会自动关闭打开的文件 a+:以读写模式打开,如果文件不存在就创建,以存在就追加 encoding 指定编码格式
f.write(edu + '\\n')
except Exception as e:
pass
if __name__ == '__main__': # __main__ 就是一个模块的测试变量,在这个判断内的代码只会在运行当前模块才会执行,在模块外部引入文件进行调用是不会执行的
yeshu = int(input("您要爬取多少页数据(整数):"))
thread = 10 # 控制要创建的线程
# 创建多线程,这个循环的次数越多创建的线程的次数就越多,线程不是越多越好,建议5到10个
for x in range(1,thread + 1):
i = int(yeshu / thread) # 页数除线程数(目的是让每一个线程都获取部分数据,分工)
End = int(i * x) # 结束的页数,设yeshu=50: 5、10、15、20、25...
Start = int(i * (x-1) +1) # 开始的页数, 1、6、11、16、21
# 我上面这样写的目的就是,让线程分工合作。如:线程1就去获取1 -5页的数据、线程2就去获取6 -10页的数据...
print(Start,End)
t = threading.Thread(target=src_tiqu,kwargs="Start":Start,"End":End) # 创建线程对象,target=执行目标任务名,args 以元组的形式传参,kwargs 以字典的形式传参
t.start() # 启动线程,让他开始工作 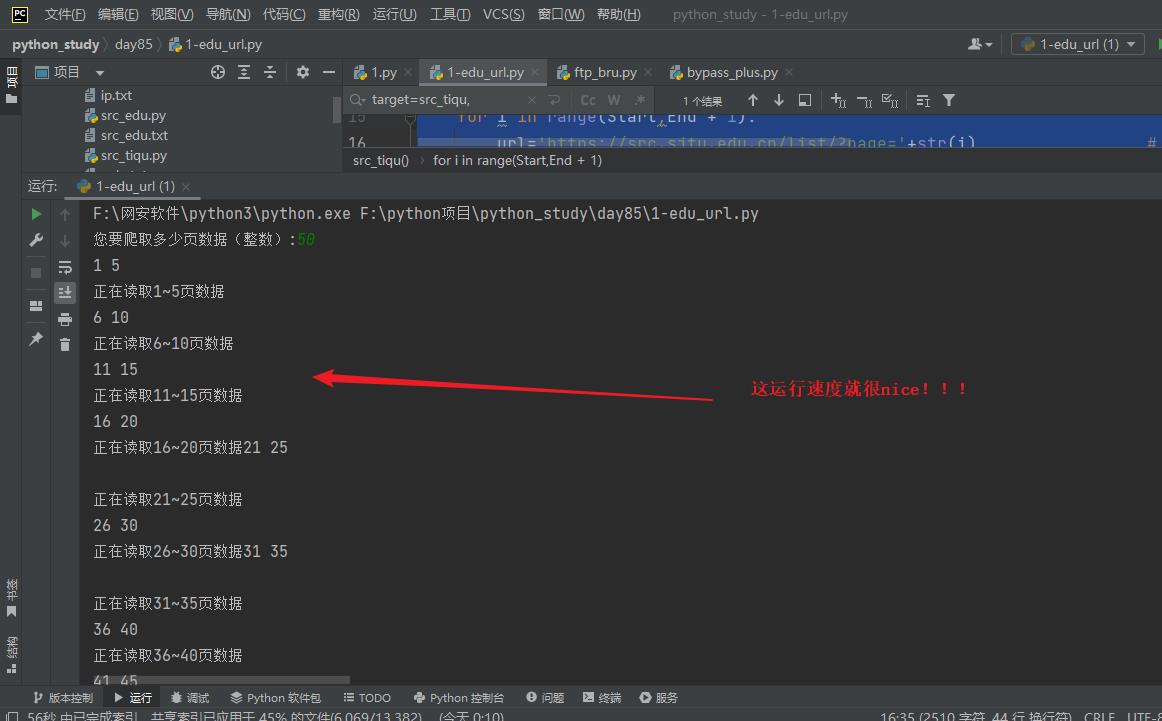
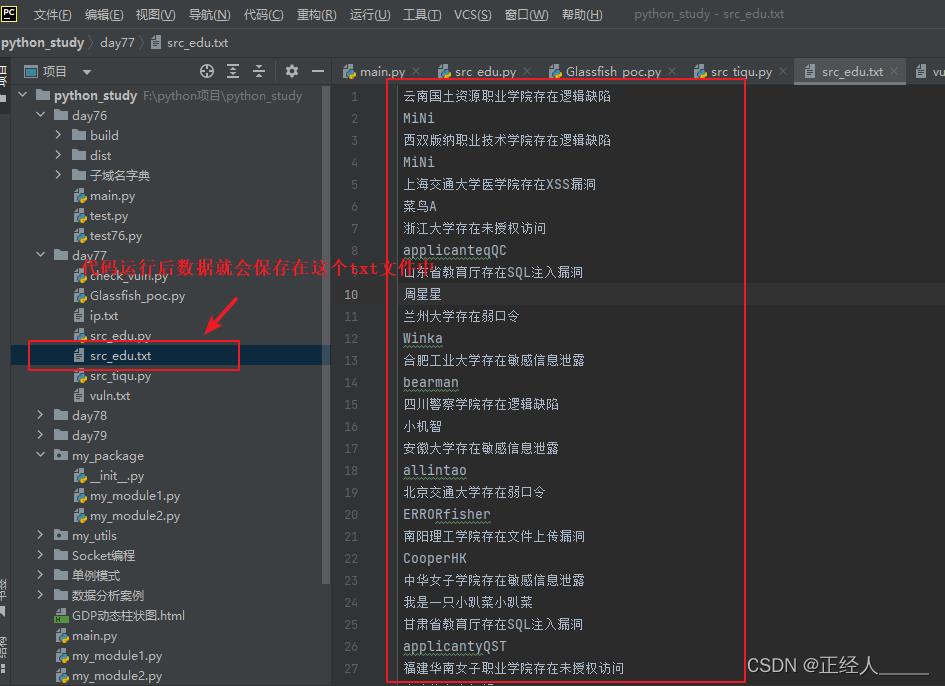
3)拿到这些学校名有啥用?这就是我们测试的目标
........此处省略一万字.......
案例2 - Python-Fofa-Exploit 联动定点批量自动化
1)首先要寻找最新的漏洞,找有poc的


在fofa上搜索使用FastJson的教育行业网站
"edu.cn" && "FastJson"
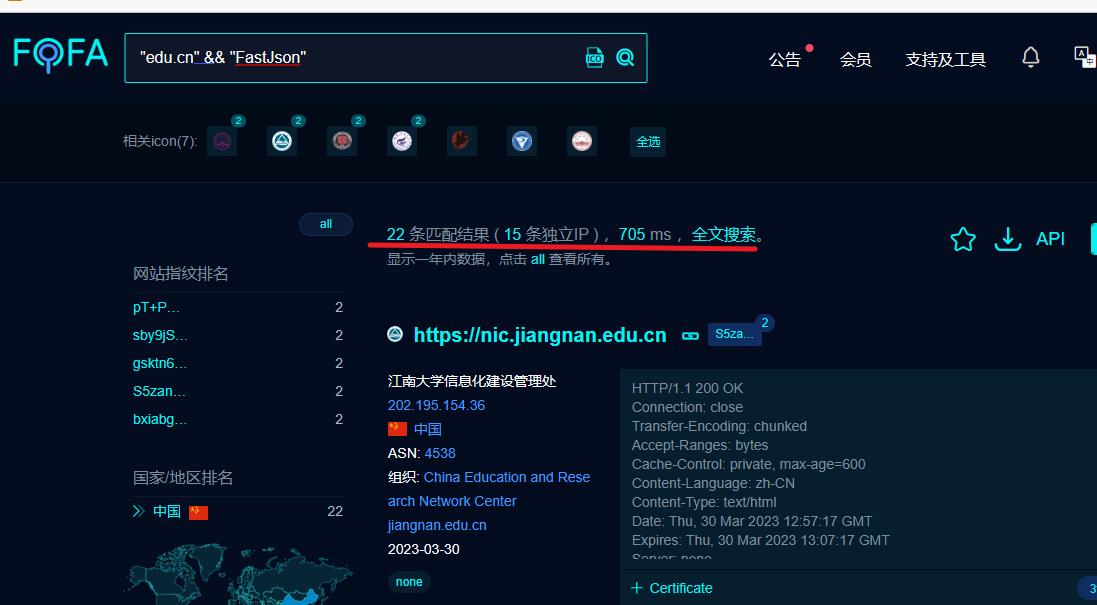
然后就可以根据他给的PoC改成批量化脚本,如果嫌麻烦也可以在百度上搜索

像这个漏洞平台的漏洞一般都是要手动检测的
涉及资源:
- 知道创宇
- 360网络空间测绘 — 因为看见,所以安全
- GitHub - Miagz/XrayFofa: 一款将xray和fofa完美结合的自动化工具,调用fofaAPI进行查询扫描,新增爬虫爬取扫描(懒人必备)
- GitHub - TimelineSec/2020-Vulnerabilities: 2020年漏洞复现大全
- GitHub - ihebski/DefaultCreds-cheat-sheet: One place for all the default credentials to assist the Blue/Red teamers activities on finding devices with default password 🛡️
教育src漏洞挖掘-2022-白帽必挖出教程
0、关于为什么要写这篇文章
作为刚接触渗透的小伙伴儿肯定都想快速挖到漏洞提交平台获取注册码,或者想获取更多积分换取证书,这篇文章就是为了帮助各位师傅们快速上手挖取教育src
1、开始前准备
每一次成功的渗透,都有一个非常完备的信息搜集。某老师傅说的:信息搜集的广度决定了攻击的广度,知识面的广度决定了攻击的深度。信息搜集永远都是渗透人员最重要的必修课,关于信息搜集想必其他的文章都已经提到很多了,比如子公司,域名,子域名,IPV4,IPV6,小程序,APP,PC软件等等,我这儿既然是快速挖取就肯定是用工具来帮助我们
在这里的话建议在自己服务器或者虚拟机装一个ARL灯塔资产信息搜集工具,下面的内容也是基于这款工具进行讲解
2、信息搜集工具安装
「ARL资产安全灯塔」简单来说就是一款信息收集的神奇,用起来非常方便快捷,比纯手工去信息收集快很多,用起来也是爽到飞起,十分推荐。
灯塔是基于docker的,所以需要大家先在linux上安装docker,docker安装很快的,按照步骤几分钟就搞定
Centos安装Docker教程
Kali安装Docker教程
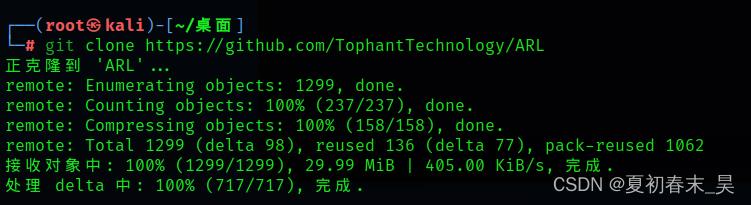
(1)从github克隆ARL
git clone https://github.com/TophantTechnology/ARL
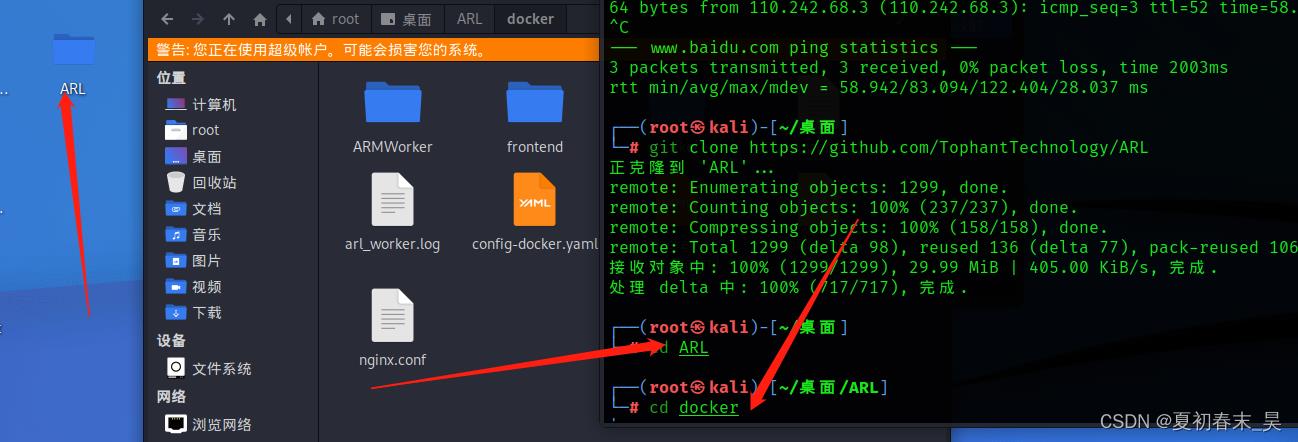
(2)进入桌面的ARL文件夹下的docker文件夹
cd ARL
cd docker
(3)创建容器数据卷
docker volume create --name=arl_db

(4)启动ARL
docker-compose up -d
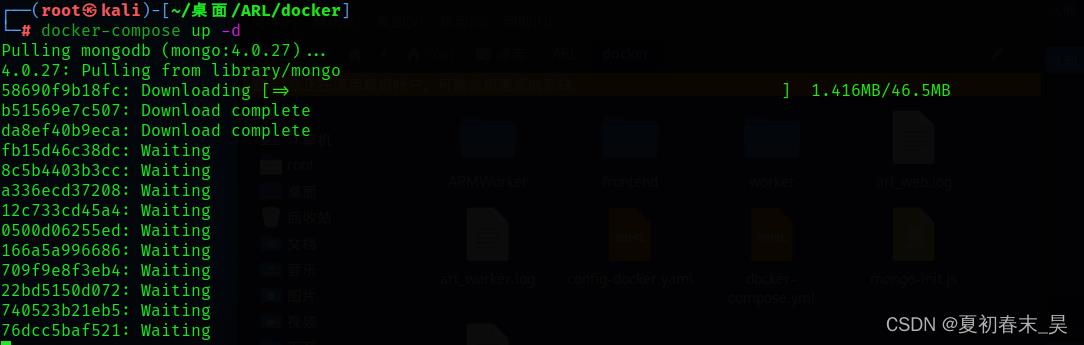
等待下载安装就行,之后会自动启动
(5)配置fofa-api:
安装完成后确定进入ARL/docker目录下,编辑config-docker.yaml文件
vim config-docker.yaml
配置自己的FOFA-API信息如下: PS:(fofa-api在登陆fofa之后,个人中心处查看,这儿最好是有fofa高级会员,因为普通会员只能查看60条数据,高级会员能看10W条,高级会员搜集信息更加全面,这里我提供自有高级会员API)
FOFA:
URL: "https://fofa.info"
EMAIL: "hackfreedom@qq.com"
KEY: "a12cb19bef004a5a5524a58a5e2bee69"
配置好后如图:

(6)登陆到ARL
https://你的ip地址:5003
这里的ip就是kali的ip,如果你的kali安装在虚拟机,你可以用kali自带的火狐浏览器打开,也可以在本机上用自己的浏览器输入kali虚拟机的ip进行访问。
Tips ~:如果你输入ip还是访问不了,记得检查一下是不是https,输入http是打不开的,要输入https。
账号:admin
密码:arlpass
登陆之后进入主页:
最后一步,配置一下资产搜集策略,新建一个策略,输入一个策略名称,之后把所有能选的都选上,提交就行

3、漏洞挖掘
(1)登陆灯塔资产搜集工具,使用如下语法:
host="edu.cn" && country="CN"
这个语句基本上能查找出来fofa中所有的页面了

(2)灯塔里边,任务管理,选择fofa任务下发,输入查询语句,进行测试,能返回结果就行,接下来点确定
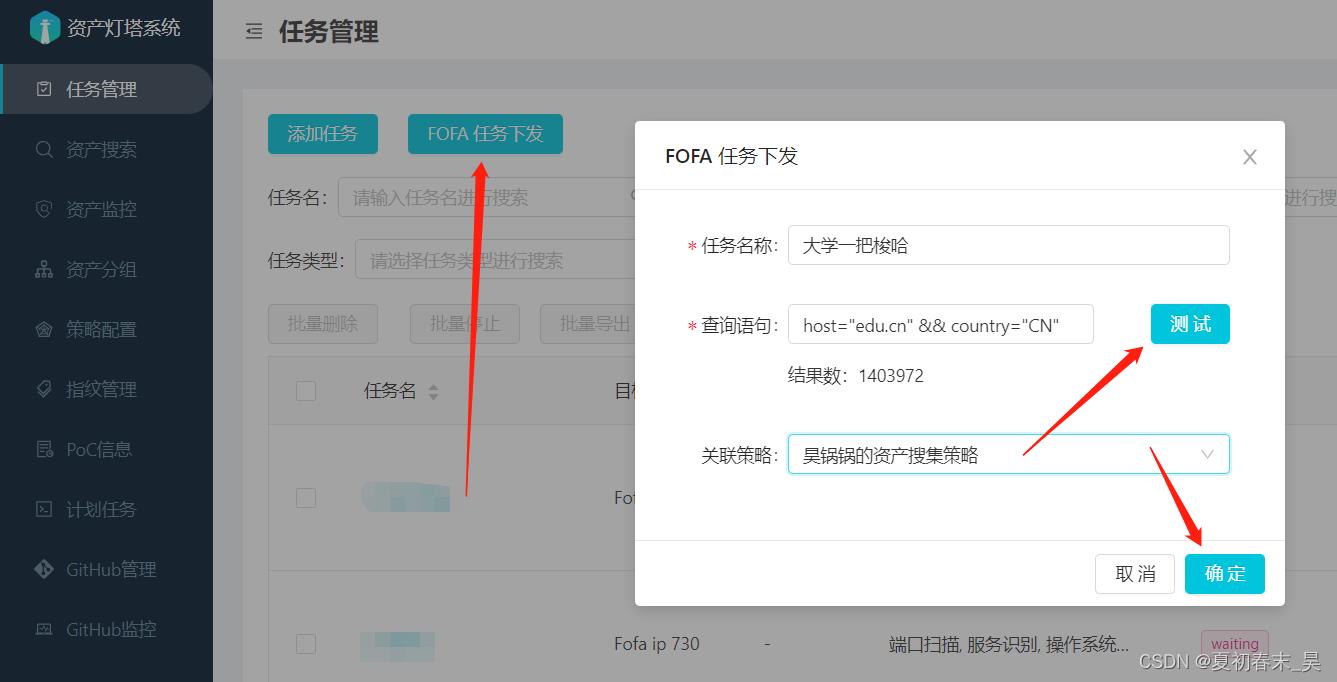
(3)之后就是等待,因为结果太多,看你电脑性能,至少也要1天,等搜集结束就行

(4)结束之后点进去,灯塔搜集资产时自带poc会帮我们发现漏洞点或者文件泄露点
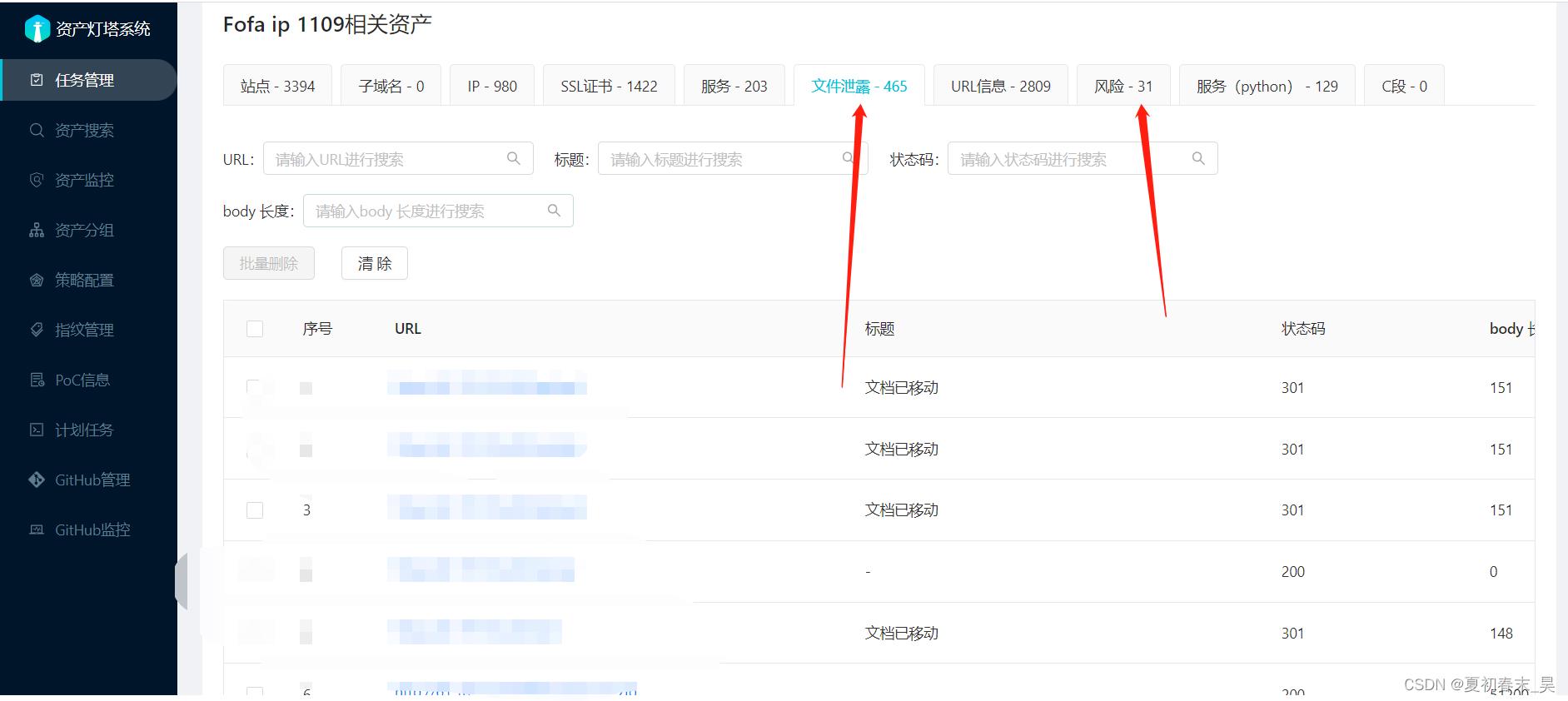
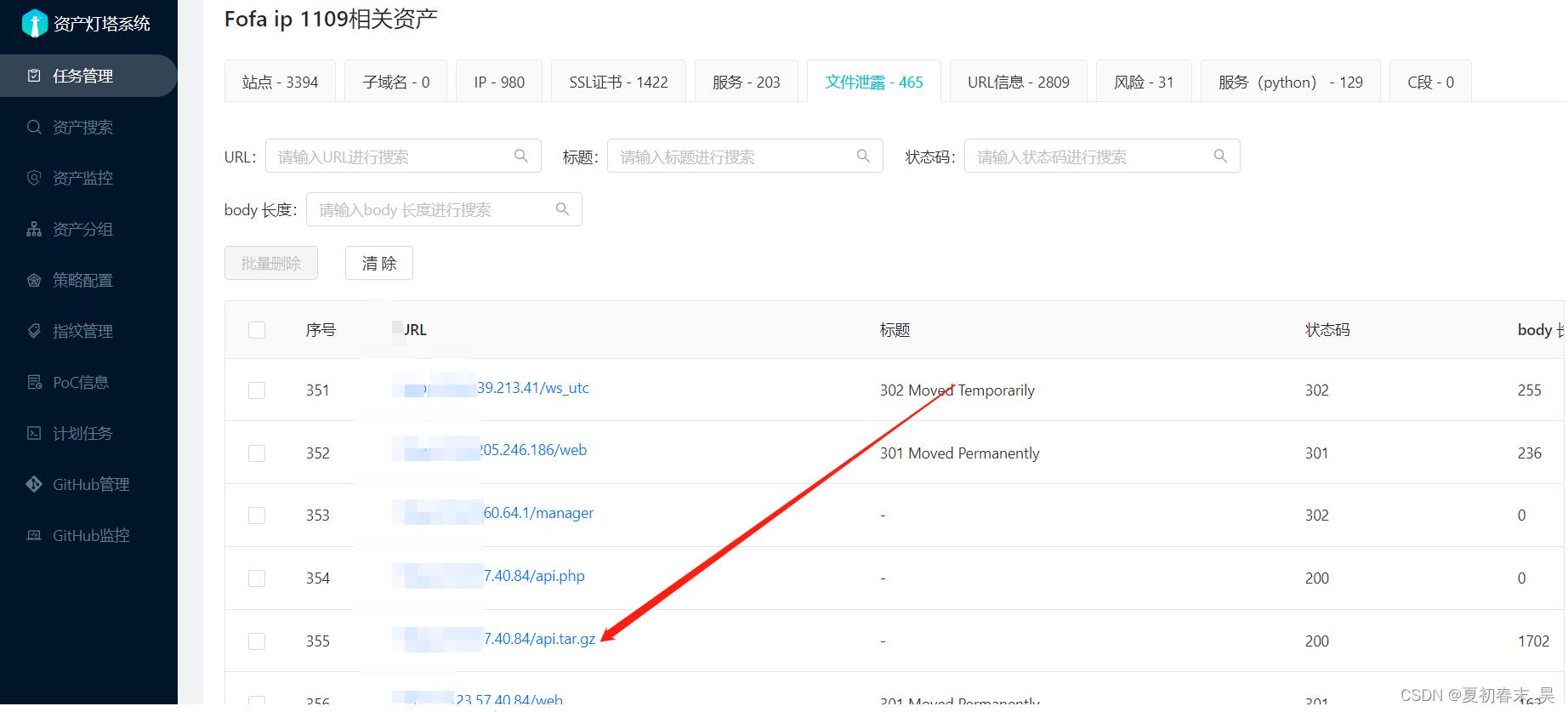
(5)接下来就是挨个验证,我这里给大家举个例
这个文件泄露点,你访问之后会下载该大学的程序源代码
解压之后就是所有程序源代码,
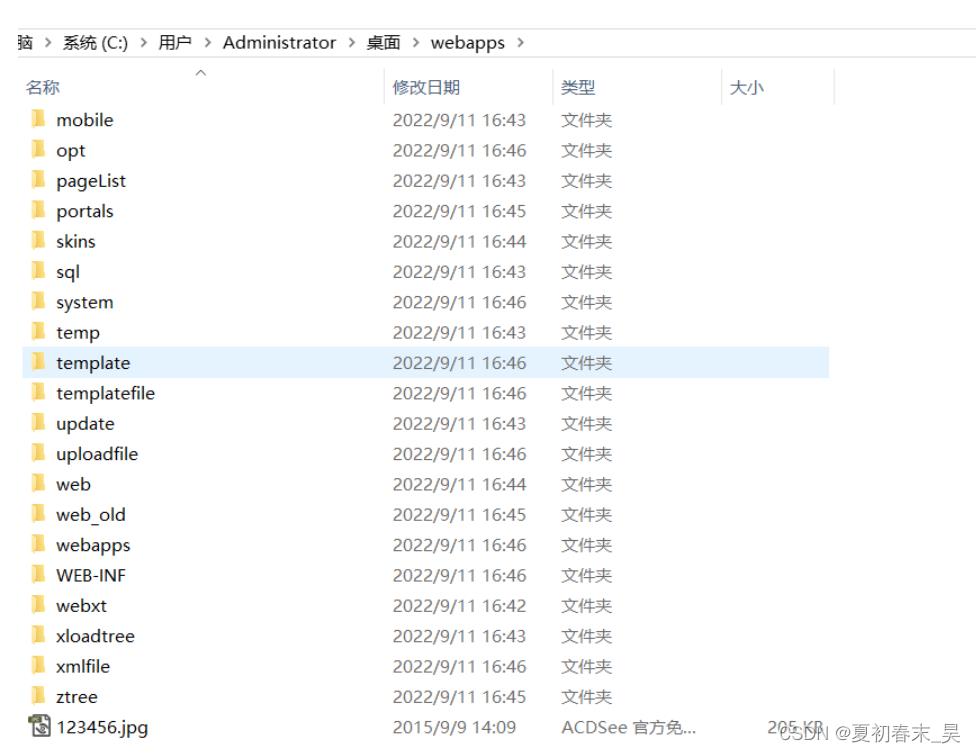
直接查看配置文件就能发现数据库连接账号密码等

(6)去教育src平台提交漏洞等待审核通过就行啦

祝各位师傅早日挖到src漏洞,获取证书,创作不易,点个赞呗~~
以上是关于p86 SRC挖掘-教育行业平台&规则&批量自动化的主要内容,如果未能解决你的问题,请参考以下文章