文本挖掘与智慧教育
Posted 数字教育
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘与智慧教育相关的知识,希望对你有一定的参考价值。

本文发表于 《数字教育》 2020年第3期(总第33期)特稿栏目,页码:1-8。转载请注明出处。

摘要:随着互联网和移动通信技术的日益普及和成熟,教育行业正在向着信息化的方向快速发展,例如在线课堂、慕课等新的教学形式已改变了原有的教育形态。与此同时,人工智能技术的大量运用,使得教育信息化不再满足于形式的创新,而是更重视教育数据的采集和挖掘,提高教育的针对性和智能化,产生了所谓的智慧教育。实际上,智慧教育更多地体现在从教育相关的数据中挖掘到新的教育理念,学习到重要的模式与方法,与数据挖掘技术密切相关。本文首先介绍文本挖掘的理论与方法,并进一步讨论如何将其应用到智慧教育中,且以教育类新闻主题挖掘和在线课堂的智能化作为实例展示和证明了文本挖掘对智慧教育的发展能够起到至关重要的作用。
关键词:智慧教育;文本挖掘;机器学习;深度学习;主题发现
| 全文共6504字,建议阅读时长6分钟 |
引言
随着互联网和移动通信技术的快速发展,信号的生成、采集、处理和分享的速度和规模都达到了前所未有的程度,人类已经进入了大数据(Big Data)时代。在这一崭新的数据时代中,我们能够获得大批量数据信息,使得许多问题的处理更加快速、准确和智能。然而,有价值的信息往往隐藏在大量数据的背后,并且被一些无关的数据或噪声所干扰,因此,能够从数据中挖掘出有价值信息的数据挖掘(Data Mining)技术近年来得到了快速的发展和广泛的应用。韩家炜在2011年给出了数据挖掘的广义解释:从大量数据中挖掘出有趣模式和知识的过程。实际上,数据挖掘是从数据库中发现知识(Knowledge Discovery in Database,KDD)的重要途径之一,也是人工智能的基础。[1]
在大数据时代中,文本数据成为许多信息的来源,对文本数据的挖掘蕴含着巨大的商业价值,因此文本挖掘(Text Mining)已引起学术界以及业界的广泛关注。实际上,在人与人之间、人与机器之间都会产生大量的文本数据。与传统数据挖掘不同,文本挖掘需要进行文本预处理,将非结构的文本转化为结构性数据,通过对结构性数据的进一步挖掘,得到文本数据内部潜在的模式和规则,进而提高人们获取文本信息的准确性和速度。根据人们的实际需求,文本挖掘的任务包括文本分类、文本聚类、信息抽取、情感与观点分析、话题检测与追踪等。
虽然文本挖掘具有巨大的应用价值,但开展文本挖掘技术研究却是一项非常具有挑战性的工作,最根本的原因在于文本数据是一种非常不规则的、难以通过数学方法精确描述的数据类型,比具有精准数值表示的数字图像和语音信号更难处理[2]。除此之外,在研究文本挖掘技术时,算法的表现还总是受困于文本噪声繁多、歧义、语义的隐蔽性等语言现象[3]。比如“小明还欠款500元”,这个句子既可以理解为“小明偿还欠款500元”,也可以理解为“小明仍然欠款500元”。从20世纪90年代开始,随着计算机和互联网的大规模使用,社交网络的兴起,文本挖掘开始走进人们的视野。文本数据的挖掘经历了从开始的基于词法、句法的分析向统计学方法的过渡和发展,目前已经进入基于机器学习和深度学习的快速发展时期。
文本挖掘技术已经被广泛应用于医疗、法律、商务、金融、国家安全和教育等多个领域。在医疗领域,利用文本挖掘技术分析病人化验报告,给出病情的初步诊断结果,能够有效地缩短病人的就诊时间且提高医生的诊断效率;在法律领域,文本自动生成技术会帮助律师撰写出法律文书的初稿,能够为律师节约大量时间;在商务和金融领域,利用文本挖掘技术对大量的财经新闻、财务报告、用户评论进行挖掘和分析,能够帮助企业做出正确的决策。祝智庭在2012年指出,信息时代下智慧教育要以先进的、适宜的信息技术作为基本支持,设计开发能适应各种特定教学需求的智慧学习环境[4]。从广义上讲,智慧教育是指在教育领域全面深入地运用现代信息技术来促进教育向数字化、网络化、智能化和多媒体化的转变,达到开放、共享、交互、协作、泛在的目标。目前,我国智慧教育更多地集中在硬件、软件和网络等基础技术和环境的建设上,已经在数字课本、在线课堂、学校云平台等建设上取得了很大的进步,但作为教育智能化核心技术的文本挖掘还没有很好地应用到智慧教育中来。为此,我们将文本挖掘技术引入到智慧教育领域,并以主题挖掘为例来说明它对智慧教育的作用和价值,希望能引起大家的关注和重视。
一、基本模型与算法
(一)文本表示
文本是由文字和标点符号组成的字符串。想要使计算机更高效地处理文本,就需要对文本进行预处理,具体来说就是对文本进行数字化编码,达到相似文本表示相近、不同文本表示有着较大区别的目的。对于中文文本,我们还需要对其进行分词,这是一个很具挑战性的任务,但目前已经有一些有效的分词工具可以利用,对此就不再讨论了。

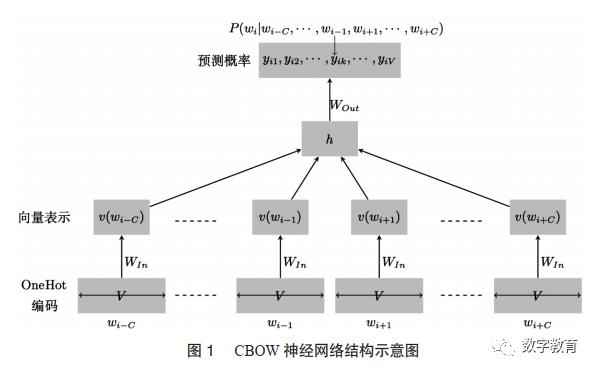
为了更精细地描述单词的语义,人们进一步提出了分布式表示,其思想基于这样一种假设:一个词的语义由其上下文决定,上下文相近的词,其语义也相似。Mikolov等在2013年提出了基于神经网络的词嵌入(WordEmbedding)模型CBOW(Continuous Bag-Of-Words,连续词袋)[6]和Skip-gram[7],也就是现在经常所说的词向量表示。以CBOW模型为例,利用整个训练语料(V个文本),通过极大化下面的似然函数即可训练出较理想的神经网络模型(如图1所示的网络结构):


(二)文本挖掘技术
1.文本聚类分析聚类分析是最基本的数据挖掘方法,在无任何类别标签的前提下,通过对数据自身内在结构的学习来建立一种自动归类规则或函数。聚类分析是一种传统的非监督统计学习方法,与有监督的分类统计学习方法形成鲜明的对照。从聚类过程来看,聚类分析可分为单层聚类和层次聚类。单层聚类是初始时刻将全部文档划分为若干个不同的簇,通过迭代不断修正和完善,其经典方法便是K-Means(K-均值)算法[8]。而层次聚类是按不同尺度逐步建立数据的层次聚类结构,最后达到所需要的聚类结果,其典型代表便是基于最小方差标准的Ward(沃德)算法。近年来,人们还提出了基于数据点分布密度的聚类分析方法,即根据数据点的聚集程度进行划分,其典型代表便是DBSCAN(Density-Based SpatialClustering ofApplications with Noise,基于密度且可应用于噪声环境的空间聚类)算法[9]。
2.主题模型
主题模型是用来刻画文本中主题分布的模型。所谓主题可以理解为文本所谈论的话题或关键词。在主题模型里,主题常常被选定为一组关键词,并通过这些词的概率分布来描述它们的可能性或重要性。实际上,我们可以自然地认为不同主题的文本中词的出现频率是不同的,比如“演唱会”一词在娱乐新闻中出现的频率明显高于科技新闻,相反,“人工智能”一词在科技新闻中出现的频率明显高于娱乐新闻。
比较典型的主题模型包括潜在语义分析(Latent Semantic Analysis,LSA)[10]、概率潜在语义分析(ProbabilisticLatentSemantic Analysis,PLSA)[11]、潜在狄利克雷分布(Latent DirichletAllocation,LDA)[12]和贝叶斯Unigram(一元文法)模型[13]。
3.自动摘要
文本自动摘要是指通过算法自动从原始文档中全面准确地提取出能够反映该文档中心思想的简单连贯的短文。按照算法输出结果的类型可以分为抽取式摘要和生成式摘要。抽取式摘要是从原文档中抽取关键句和关键词来组成摘要,而生成式摘要则允许根据原文生成新的词语、短语来组成摘要,这样显然更接近人们做摘要的方式[14]。
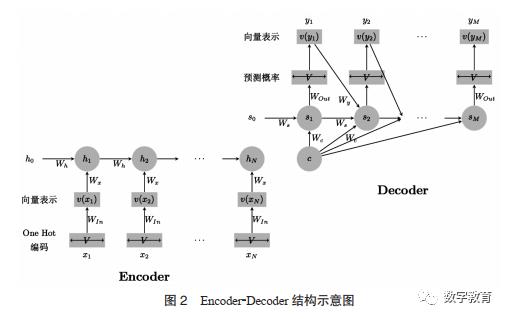
抽取式摘要的代表算法是依据网页检索排序的PageRank算法所改进的TextRank算法[15]。其过程是首先构建一个词节点的有向加权图。对于当前词节点,





二、文本挖掘在智慧教育中的应用
近年来,随着人工智能技术的长足发展,智能化的浪潮已涌入各行各业,教育行业也成为热点之一。
2017年国务院印发《新一代人工智能发展规划》文件明确提出了智能教育的概念,积极推进人工智能技术应用于教育领域的各个方面,引领中国智慧教育的大发展。目前的智慧教育还处在教育的信息化阶段,利用信息技术打造教育平台环境。接下来的发展更要突出人工智能的应用,即对教育过程中产生的数据进行深入分析和挖掘,为学生、教师与管理者的决策提供更有力的支持。
在智慧教育的发展过程中,文本挖掘逐渐崭露头角。例如网络智能答疑系统[18]就是通过建立学科领域知识问答库,将学生自然语言表达的问题和知识库文档进行特征项提取并按TF-IDF方法计算特征项的权重,采用向量空间模型计算二者的相似度,从而找到最佳答案。
在教育研究领域,通过文本挖掘分析国内教育信息化领域的研究热点与趋势也是一个很好的应用方向[19]。通常的做法是先对文本数据进行聚类分析,然后根据不同类别来发现其主题。在对文本数据进行预处理后,我们则可以采用传统的聚类分析算法进行文本的聚类分析,而这些算法的优劣则会影响到文本聚类的结果。我们采用了K-Means、Ward和DBSCAN算法在多个文本数据集进行实验和比较。实验结果表明,K-Means算法和Ward算法聚类效果要明显优于DBSCAN算法。进一步还可发现,K-Means算法运行速度快,Ward算法比较耗时,这是由于Ward算法要不断地对所合并类之间的数据点的距离进行计算,而K-Means算法每次迭代只需计K×N次距离。因此我们在后面的应用中便选择了K-Means算法进行下一步的文本聚类分析。对于N个数据样本,K-Means算法的迭代过程如下:第一步,随机初始化K个聚类中心(K<N);第二步,对于每个样本,确定其类别为距离其最近的中心所代表的类别;第三步,根据新划分的样本类别来更新每个类别的中心;第四步,重复第二步和第三步,直至中心变化小于给定阈值。其他两个算法可能在一些复杂数据结构的聚类分析中具有某些优势,但所花费的时间代价会大得多。
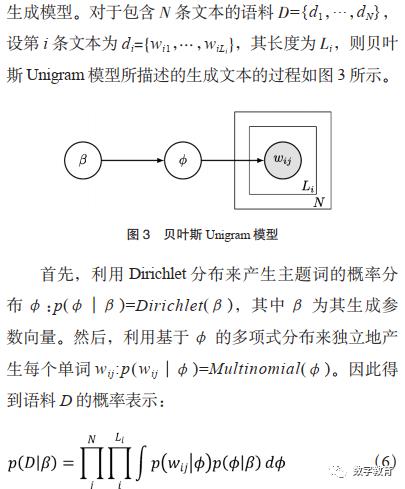



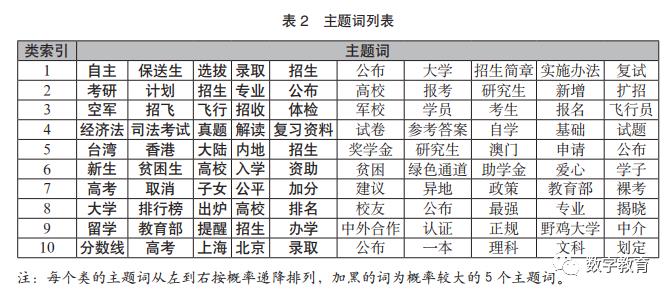
200维向量表示,同时计算每条文本的TF-IDF表示,把两者进行融合,得到每条文本的200维向量表示。我们对所有文本样本的向量表示通过t-SNE[21]降维至2维平面得到其可视化表示,从中可以看出,大部分区域有着明显的团状结构,因此可以通过聚类分析算法将相似文本归并在一起。这样,我们进一步采用K-Means算法进行聚类分析,且根据经验设置170个类别。最后,根据相似文本应具有共同主题的思想,随机抽取10个类别,通过贝叶斯Unigram模型找到代表每个类的主题词。
四、在线课堂教学的智能化应用
随着信息化教学手段的提高和普及,各类学校都越来越重视网络教学平台的建设,并在课堂教学中增加了多种线上互动与交流的环节。在这些环节中可通过文本挖掘做到智能化教学,提高教学的水平和效率。
实际中,在线课堂面对着大量的学生,他们随时可能提出许多问题,老师无法逐个阅读,而文本挖掘技术可以很快地将这些问题分类并找出代表性的问题,为老师的教学提供快捷智能的辅助。另外,针对某一个事件或论点的多种评论,也可快速地计算出正面评价多还是负面评价多,为老师判断学生的意见提供依据。对于线上课堂的留言板、论坛、聊天室的评论可进行文本聚类分析与主题发现,有利于快速了解大量学生在课堂学习中所遇到的普遍问题、学生的学习兴趣、教学难点等,帮助教师制定相应的教学计划,同时也为老师的教学评价提供指导信息。
另一方面,我们可根据线上课堂所产生的大量文本数据,结合现有的知识文本数据,采用文本挖掘技术来构建辅助线上课堂教学的系统。最具代表性的便是知识图谱和问答系统。对于学生来说,系统的可视化的知识图谱能够提升学生对知识理解的速度和深度。我们可采用文本挖掘中的主题发现、关联分析等技术,结合老师与学生的需求,构建课堂教学知识的图谱,使学生可更直观地了解知识的关联和逻辑。对于老师来说,通常会重复地回答学生提出的相似问题,在特定的知识领域内搭建问答系统可以很好地减轻老师的教学强度,同时也方便学生快速便捷解决学习中遇到的问题。
五、总结和展望
本文介绍了文本挖掘中的基本思想、模型和方法,并讨论如何将其应用于智慧教育中,推进我国教育智能化的发展。对教育类新闻主题的挖掘,可以清晰地看出教育类报道在一定时期内围绕着的热点,这能方便教育工作者快速了解教育领域关注的热点和方向,对教育工作的展开能起到一定的参考作用。另外,通过在线课堂中的讨论,我们也能看出文本挖掘与教育的智能化紧密相连,具有广阔的应用前景。
参考文献:
[1]HAN J,PEI J,KAMBER M.Data Mining:Concepts and Techniques[M].Amsterdam:Elsevier,2011.
[2]宗成庆,夏睿,张家俊.文本数据挖掘[M].北京:清华大学出版社,2019.
[3]宗成庆.统计自然语言处理[M].北京:清华大学出版社,2013.
[4]祝智庭,贺斌.智慧教育:教育信息化的新境界[J].电化教育研究,2012 (12):5-13.
[5]SALTON G,WONG A,YANG C S.A Vector Space Model for Auto-matic Indexing[J].Communications of the ACM(S0001-0782),1975,18(11):613-620.
[6]MIKOLOV T,CHEN K,CORRADO G,et al.Efficient Estimation ofWord Representations in Vector Space[OB/OL].(2013-9-7)[2020-2-10].http://arxiv.org/abs/1301.3781.
[7]MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed Represen-tations of Words and Phrases and Their Compositionality[C]//Ad-vances in Neural Information Processing Systems.2013:3111-3119.
[8]MACQUEEN J.Some Methods for Classification and Analysis of Mu-ltivariate Observations[C]//Proceedings of the Fifth BerkeleySymposium on Mathematical Statistics and Probability.1967,1(14):281-297.
[9]ESTER M,KRIEGEL H P,SANDER J,et al.A Density-Based Algo-rithm for Discovering Clusters in Large Spatial Databases withNoise[C]//KDD.1996,96(34):226-231.
[10]LANDAUER T K,DUMAIS S.Latent Semantic Analysis[J].Scholarpedia(S1941-6016),2008,3(11):4356.
[11]DEERWESTER S,DUMAIS S T,FURNAS G W,et al.Indexingby Latent Semantic Analysis[J].Journal of the American Society forInformation Science(S1097-4571),1990,41(6):391-407.
[12]HOFMANN T.Probabilistic Latent Semantic Indexing[C]//Pro-ceedings of the 22nd Annual International ACM SIGIR Conference onResearch and Development in Information Retrieval.1999:50-57.
[13]BLEI D M,NG A Y,JORDAN M I.Latent Dirichlet Allocation[J].Journal of Machine Learning Research(S1533-7928),2003,3:993-1022.
[14]WU D Q,GUO X Y,MA J W.News Topic Discovery through Com-munity Detection[C]//IEEE International Conference on Signal,Infor-mation and Data Processing.2019:43-48.
[15]MIHALCEA R,TARAU P.Textrank:Bringing Order into Text[C]//Proceedings of the 2004 Conference on Empirical Methods in NaturalLanguage Processing.2004:404-411.
作者简介:
吴大庆(1994—),男,安徽淮北人,北京大学数学科学学院博士研究生,研究方向为机器学习与数据挖掘;
郭向阳(1995—),男,河南商丘人,北京大学数学科学学院博士研究生,研究方向为统计学习与智能信息处理;
马尽文(1962—),男,陕西周至人,北京大学数学科学学院教授、博士生导师、中国电子学会信号处理分会常务委员,主要研究方向包括神经计算、模式识别、机器学习、数据挖掘、图像处理等。


喜欢《数字教育》的广大读者朋友们,现在可以去天猫旗舰店购买啦
扫描二维码进入大象出版社天猫旗舰店,搜索数字教育即可购买
喜欢就点个赞吧!
以上是关于文本挖掘与智慧教育的主要内容,如果未能解决你的问题,请参考以下文章