[转帖]RISC-V 加速芯片,496核!RTL开源!
Posted jinanxiaolaohu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[转帖]RISC-V 加速芯片,496核!RTL开源!相关的知识,希望对你有一定的参考价值。
https://news.cnblogs.com/n/653553/

来源:wikichip
Celerity 是在多家大学共同努力下,而创造的一个开源多核 RISC-V 分层(tiered)加速器芯片。该项目是 DARPA 快速电路实现(Circuit Realization At Faster Timescales:CRAFT)计划的一部分,该计划希望将定制集成电路的设计周期从几年缩短到几个月甚至几周。Celerity 团队首先在 Hot Chips 29 上展示了该芯片。在去年的 VLSI 2019 上,Celerity 团队谈论了其第二代芯片的 PLL 和 NoC。
此外,Celerity 的 RTL 设计已在其官网开源提供下载!
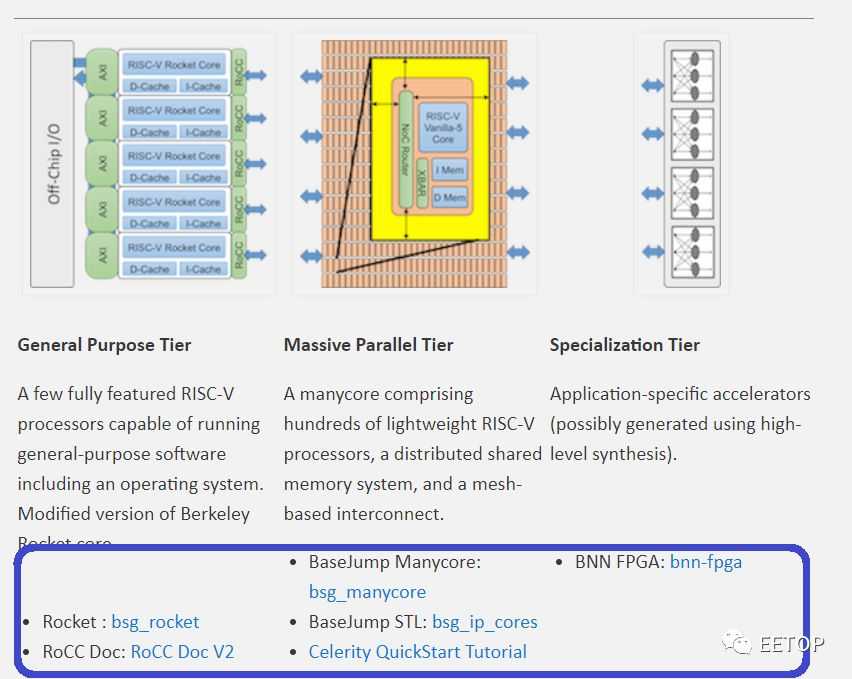
接下来先对整个 CeleritySoC 做一个快速概述,Celerity 是一个多核多层的 AI 加速器。总体而言,该芯片包括三个主要层:通用层,大规模并行层和专用层。为什么要使用分层 SoC?主要原因是为了在典型的 CPU 设计上实现高灵活性和更高的电源效率(尽管效率不及 ASIC NPU)。
通用层几乎可以执行任何操作:通用计算、内存管理以及控制芯片的其余部分。因此,他们集成了 Free Chip Project 的五个高性能乱序 RISC-V Rocket 内核。下一层是大规模并行层,它将 496 个低功耗定制设计的 RISC-V 内核集成到一个网格中。这些称为 Vanilla-5 的自定义内核是有序标量内核,其占用的空间比 Rocket 内核少 40 倍。最后一层是集成二值神经网络(BNN)加速器的专业化层。这三层都是紧密链接的,并与以 400 MHz 的 DDR 存储器接口。
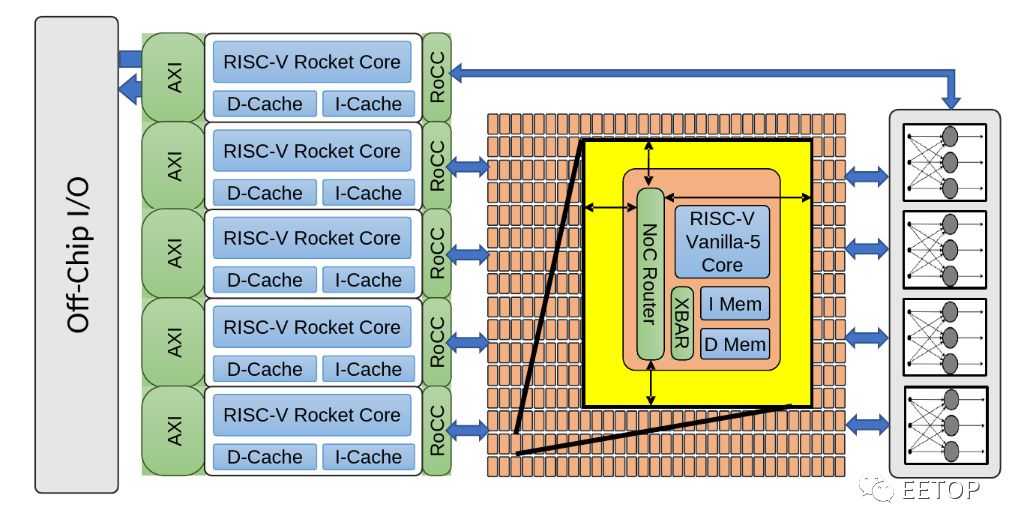
Celerity 上的多核网络(Manycore Mesh)时钟由一个定制的锁相环(PLL)提供。这是一个相当简单的一阶ΔΣ频率数字转换器(FDC)PLL。该实现单元采用 16 个 DCO 组成一个组,每个实现单元为环形振荡器,其中反相元件加载有如下幻灯片上的电路图所示的 NAND 门 fce,如以下幻灯片中的电路图所示。这样做是为了仅使用标准单元来实现整个设计。为此,整个数字 PPL 是一个完全综合和自动放置和路由设计。该 PLL 在其 16 纳米芯片上的频率范围为 10 MHz 至 3.3GHz。
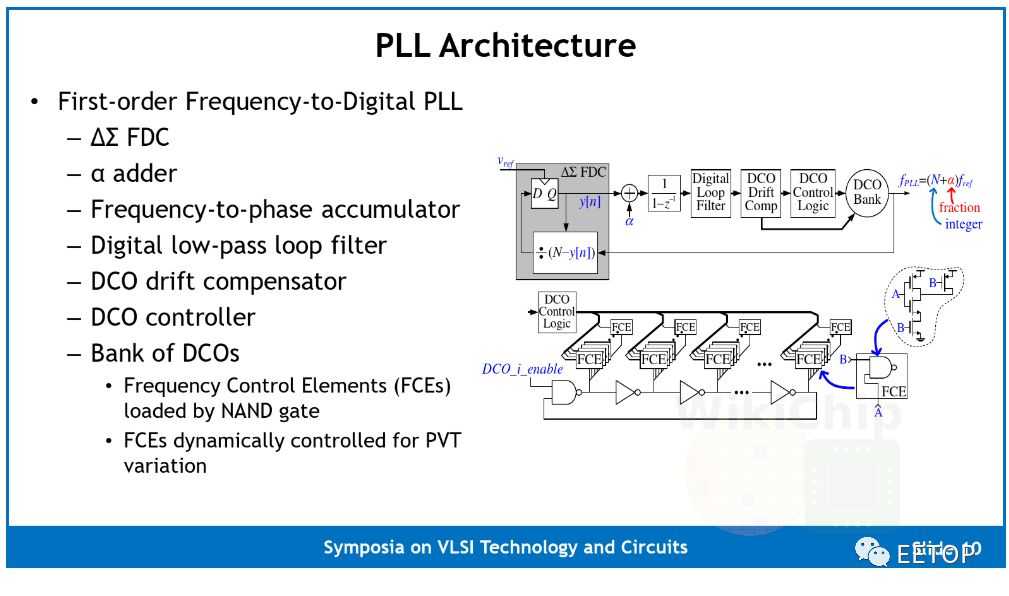
与许多学术项目一样,硅面积也非常重要的,整个芯片为 25 平方毫米(5×5)。对于 Celerity 而言,许多关键的架构设计决策都以限制硅面积的需求为主导,这意味着降低了复杂性。Manycore 本身是 16 乘 31 的 Vanilla-5 RISC-V 小型内核阵列。该阵列的第 32 行用于外部主机,该主机用于与芯片上的其他组件连接(例如,将消息/数据发送到 Rocket 核心进行最终处理)。整个网格为 3.38 毫米乘 4.51 毫米(15.24 毫米²),约占整个芯片的 61%。Vanilla-5 核心是 5 级有序流水线 RV32IM 核心,因此它们支持整数和乘法扩展。硅芯片实现,这些内核能够达到 1.4 GHz,比他们在 Hot Chips 29 上展示的第一个硅芯片高 350 MHz。
为了降低多核阵列的复杂性,Celerity 利用分区的全局地址空间进行单芯片数据包和远程存储编程模型。

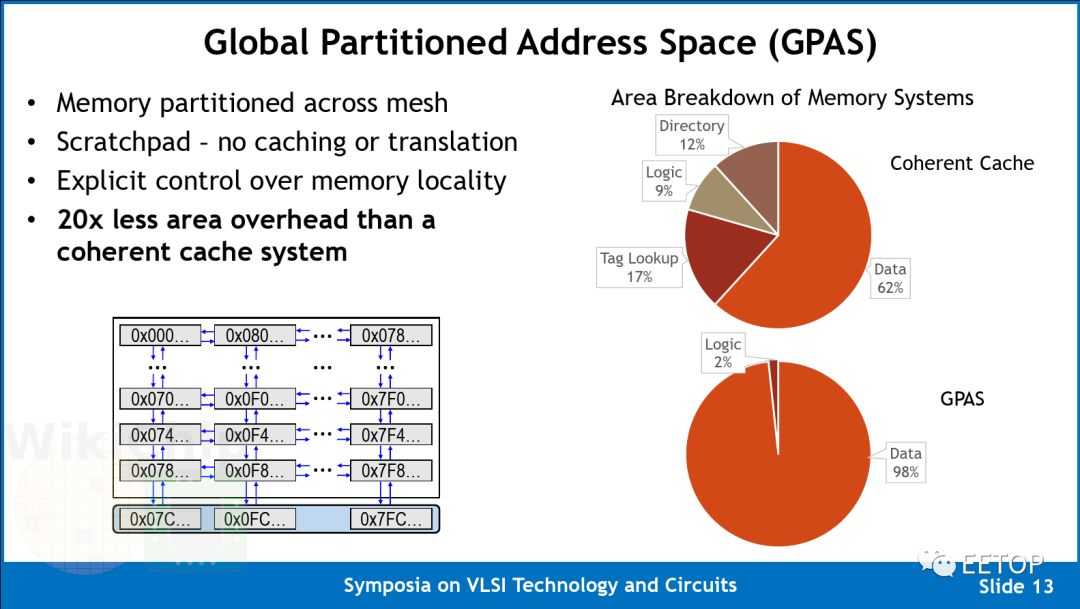
该阵列利用了全局分区地址空间(GPAS)。换句话说,不是使用高速缓存,而是使用 32 位地址方案将整个内存地址空间映射到网络中的所有节点上。这种方法也意味着无需虚拟化或转换,从而大大简化了设计。
他们声称,与等效的一致性缓存系统相比,该设计可将区域开销降低 20 倍。值得指出的是,由于该多核阵列的目标工作负载是 AI 加速(相对于更通用的计算),因此它们可以采用显式分区(explicitly partitione)的暂存器存储方案,因为这些工作负载表现出高度并行的定义良好的独立流模式。而且,对于这种类型的代码,控制存储器局部性的能力可能证明是非常有利的。阵列中的每个核都可以自由执行加载并存储到任何本地地址,但是,它只能执行对远程地址的存储。没有远程负载意味着它们将路由器面积减少了 10%,并且由于可以对远程存储进行流水线处理,因此可以防止流水线停顿。
这种远程存储编程模型方案允许他们使用两个网络,实现这一个数据网络和 credit 网络用于管理未完成的存储。
如前所述,第 32 行用于外部主机。实际上,这意味着内存映射扩展到位于阵列底部的 16 个路由停靠点,允许消息进出多核阵列,到达芯片上的大核和其他外围设备。
Celerity 并没有使用非常常见的 wormholerouting(被 Kilocore,Piton,Tile64 等使用),而是将地址和数据合并到单个 flit 数据包中。该设计摆脱了发送数据和元数据都需要的头/尾部信息。另外,由于没有保留的路由,它摆脱了 HOL 阻塞。每个 flit 均为 80b 宽-控制位 16 位,数据位 32 位,节点地址位 10 位,存储器地址位 22 位。flit 节点地址保留了将数据发送到任何目的地的能力。该设计的主要好处是,由于仅将单个 flit 注入网络,因此可以使用一个有序管道在每个周期中执行一个存储。
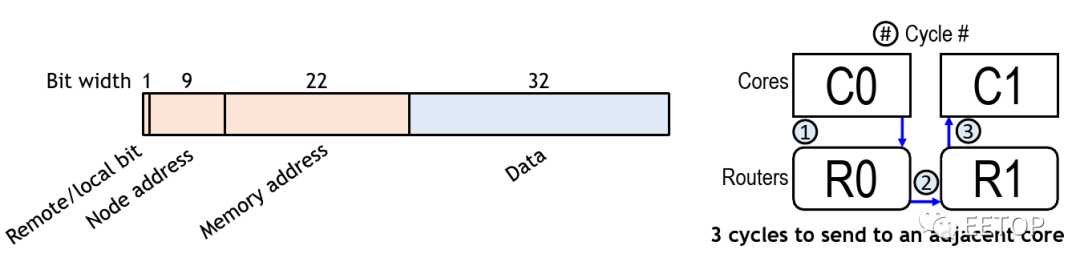
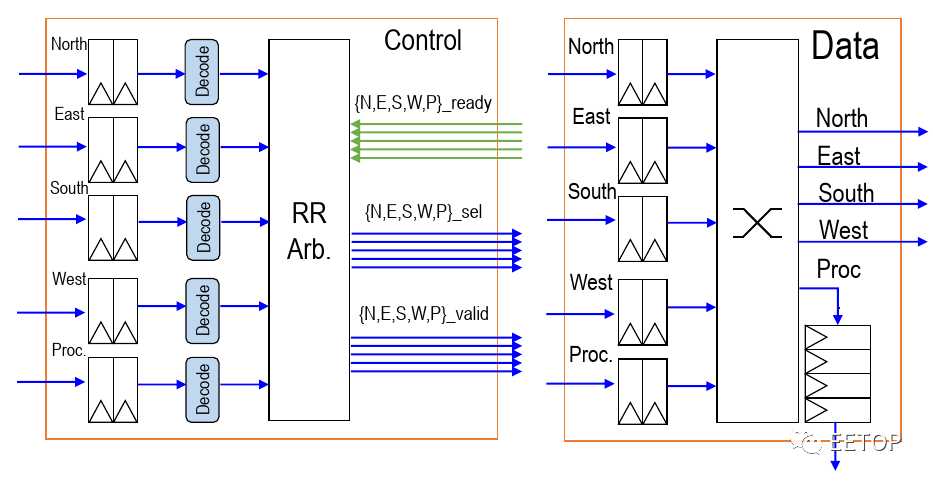
在多核阵列中的 496 个节点中,每个节点都有一个路由。路由本身在每个基本方向(N,S,E,W)的输入处都包含两个元素的 FIFO,以及在网络拥塞情况下用作临时存储的控制处理器。他们使用循环仲裁(round-robin arbitration)来确定数据包的优先级,从而可以在每个周期对每个方向进行仲裁(arbitrate )。他们使用尺寸顺序的布线(在一个方向上减小偏移,然后再移动到另一方向)。通过简单的设计,他们可以将整个路由实现为单级设计,而节点之间没有管道寄存器。换句话说,每跳只需要一个周期。例如,任何相邻的核心存储区的延迟只有 3 个周期-转到本地路由,跳到相邻路由,最后去邻居的记忆空间,路由器与内核位于相同的时钟域,这意味着它们还可以在高达 1.4 GHz 的频率下运行。
有两个网络-一个数据网络和一个 credit 计数器网络。该路由器使用一个受源代码控制的 credit 计数器,每当一个远程存储包被注入网络时,该计数器就会递减。通过 credit 计数器网络返回,该网络使用与上面描述的数据相同的架构,但只有 9 位,因为它只包含节点地址。
那么,这些意味着什么呢?Celerity 团队报告了在 600 mV 至 980 mV 工作频率从 500 MH 一直到 1.4GHz。我们相信 Celerity 现在是时钟频率第二高的大学芯片,仅次于 Kilocore(尽管值得指出的是,由于封装方面的限制,Kiloecore 只能支持其 1000 个内核中的 160 个)。在 1.4 GHz 时,整个网格的最大计算能力为 694.4 INT 32 GOPS。他们以每秒 Giga-RISC-V 指令(GRVIS)而不是 GOPS 报告其数字,以便强调一个事实,即这些指令是完整的 RISC-V 指令,而不仅仅是整数运算。请注意,由于 Vanilla-5 内核是 RV32IM,它们支持 RISC-V 整数和乘法扩展,但不支持浮点运算,因此所有 AI 工作负载都必须进行量化。由于将节点互连的路由器与核心位于相同的时钟域,每个路由器每个周期支持 5 个 flit,因此每个节点的总聚合带宽为 748Gbps,总聚合网络带宽为 371Tb/s。
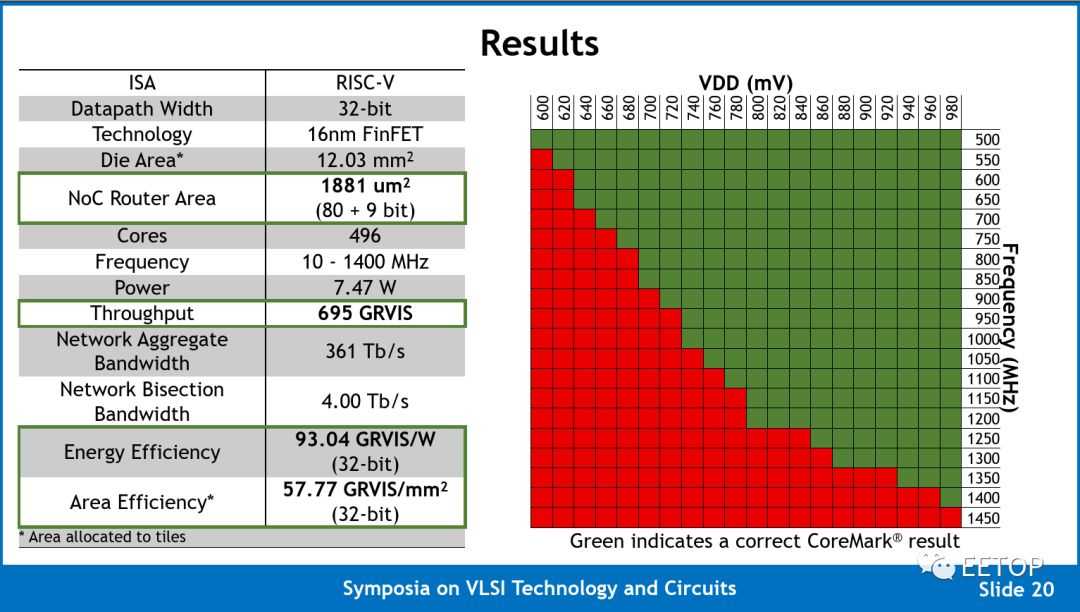
不幸的是,Celerity 团队没有报告任何与人工智能相关的常见基准测试结果。相反,他们选择使用 CoreMark,当他们达到 580.25 CoreMark /MHz 时,总得分为 812350。CoreMark 在过去几年中一直是 RISC-V 社区的比较基准。CoreMark 的问题在于,它通常会为简单的有序设计生成令人难以置信的乐观分数,这些设计似乎能够很好地与调优的现代无序设计竞争,而真实世界的工作负载则显示出非常不同的结果。鉴于该芯片的前提是产生一个高度灵活的人工智能加速器,我们希望鼓励 Celerity 团队产生更有意义的结果,如正式的 MLPerf 提交。
Celerity 的开源 RTL 设计已在 Celerity 网站公开(开源链接:http://opencelerity.org/),部分截屏如下:
以上是关于[转帖]RISC-V 加速芯片,496核!RTL开源!的主要内容,如果未能解决你的问题,请参考以下文章
ARM正在作死,将促使全球加速转向支持RISC-V,有利于中国芯片
多款RiscV芯片发布,中国加速其产业化,有望打破ARM垄断
Intel加入risc-v,联合中国芯片,将加速终结ARM的垄断地位
全志V853芯片 在Tina下RISC-V核E907启动方式的选择