PyTorch-线性回归_SGD_动量梯度下降
Posted yanshw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch-线性回归_SGD_动量梯度下降相关的知识,希望对你有一定的参考价值。
本篇是一个练手项目,目的在于:
1. 熟悉 pytorch
2. 实现 SGD 与 动量梯度下降,并对比收敛性
手动实现线性回归模型,一个很简单的模型,不多介绍,直接上代码
import torch as t import matplotlib.pylab as plt ### 制造数据 def make_data(): # y = 2x+3 x = t.rand(1, 10) * 20 y = x * 2 + 3 + t.randn(1, 10) return x, y ### 初始化参数 t.manual_seed(10000) ### 随机种子 w = t.rand(1, 1) b = t.rand(1, 1) ### 动量梯度的初始值 w0 = 0 b0 = 0 lr = 0.001 loss_record = [] for i in range(10000): x_t, y_t = make_data() y_p = t.matmul(w, x_t) + b loss = t.pow(y_p - y_t, 2) * 0.5 loss = t.mean(loss) ### 可 sum 可 mean,一般和 下面的 grad_b 对应 loss_record.append(loss) ### 手动求导,计算梯度 ## 注意这里对 (yp-yt)^2 求导,是 (yp-yt)x,如果是对 (yt-yp)^2 求导,是 -(yt-yp)x grad_w = t.matmul(y_p - y_t, x_t.t()) ### t() 转置 grad_b = t.mean(y_p - y_t) ### SGD 参数更新 # w -= lr * grad_w # b -= lr * grad_b ### 动量梯度下降的参数更新,收敛效果比 SGD 好很多 grad_w_new = 0.8 * w0 + grad_w w.sub_(lr * grad_w) w0 = grad_w ### 记住本次梯度,作为下次的 w0,这里只是记了上次,可以自己设定计前几次,或者计之前全部 grad_b_new = 0.8 * b0 + grad_b b.sub_(lr * grad_b_new) b0 = grad_b print(w, b) plt.plot(loss_record) plt.show()
下面我把学习率变得很低,并且把 动量梯度下降中 的只记录上次 梯度改为 记录之前全部梯度
lr = 0.0000001 grad_w = 0.9 * w0 + grad_w w.sub_(lr * grad_w) w0 = grad_w ### 计之前全部 grad_b = 0.9 * b0 + grad_b b.sub_(lr * grad_b) b0 = grad_b
其他不变,对比下 SGD 与动量梯度的收敛性
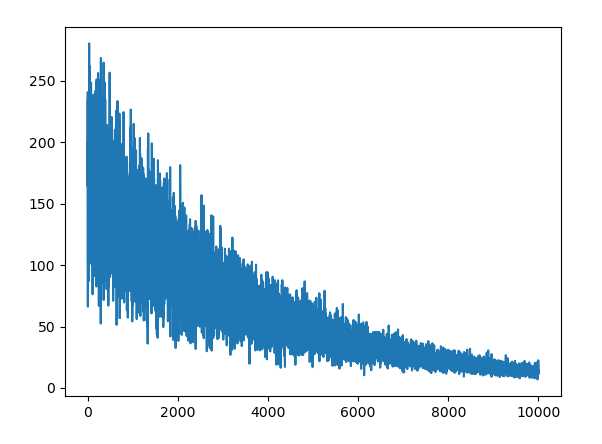
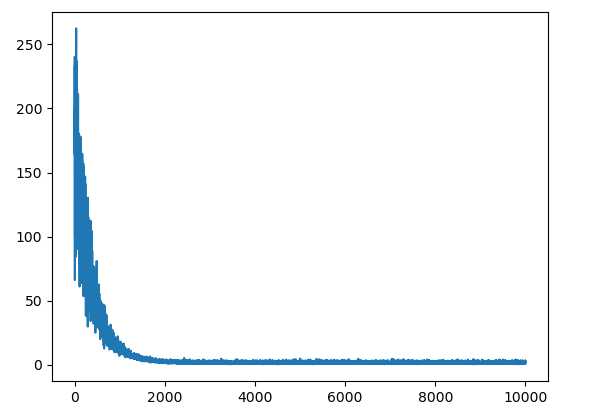
左边 SGD, 右边 动量梯度下降
以上是关于PyTorch-线性回归_SGD_动量梯度下降的主要内容,如果未能解决你的问题,请参考以下文章
pytorch常用优化器总结(包括warmup介绍及代码实现)
pytorch常用优化器总结(包括warmup介绍及代码实现)
Pytorch优化器全总结SGDASGDRpropAdagrad