《爬虫学习》
Posted whgy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《爬虫学习》相关的知识,希望对你有一定的参考价值。
Http请求:
1.在浏览器中发送一个http请求的过程:

2.url详解:
URL是Uniform Resource Locator的简写,统一资源定位符。 一个URL由以下几部分组成
scheme://host:port/path/?query-string=xxx#anchor
解析:

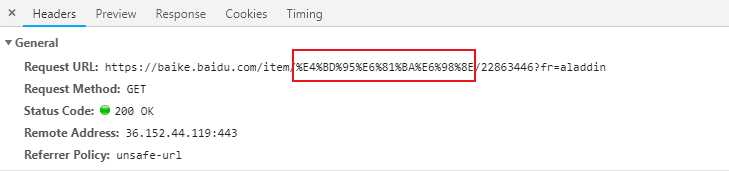
注意:写代码时,URL请求之中,中文必须转化为相对应的编码:%+16进制字符(例:何凯明=%E4%BD%95%E6%81%BA%E6%98%8E)
3.常用请求方法:
get请求:一般情况下,浏览器从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求。
post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用post请求。 以上是在网站开发中常用的两种方法。并且一般情况下都会遵循使用的原则。但是有的网站和服务器为了做反爬虫机制,也经常会不按常理出牌,有可能一个应该使用get方法的请求就一定要改成post请求,这个要视情况而定。
4.请求头以及参数:
在http协议中,向服务器发送一个请求,数据分为三部分,第一个是把数据放在url中,第二个是把数据放在body中(在post请求中),第三个就是把数据放在head中。这里介绍在网络爬虫中经常会用到的一些请求头参数:
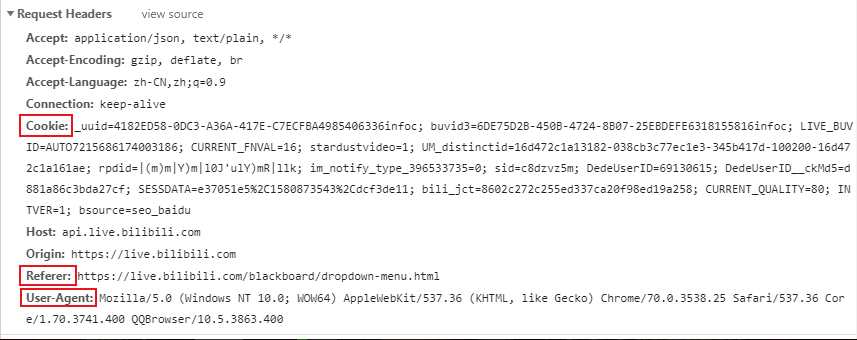
User-Agent:浏览器名称。这个在网络爬虫中经常会被使用到。请求一个网页的时候,服务器通过这个参数就可以知道这个请求是由哪种浏览器发送的。如果我们是通过爬虫发送请求,那么我们的User-Agent就是Python,这对于那些有反爬虫机制的网站来说,可以轻易的判断你这个请求是爬虫。因此我们要经常设置这个值为一些浏览器的值,来伪装我们的爬虫。
Referer:表明当前这个请求是从哪个url过来的。这个一般也可以用来做反爬虫技术。如果不是从指定页面过来的,那么就不做相关的响应。
Cookie:http协议是无状态的。也就是同一个人发送了两次请求,服务器没有能力知道这两个请求是否来自同一个人。因此这时候就用cookie来做标识。一般如果想要做登录后才能访问的网站,那么就需要发送cookie信息了。
5.状态码:

6.F12开发者工具:
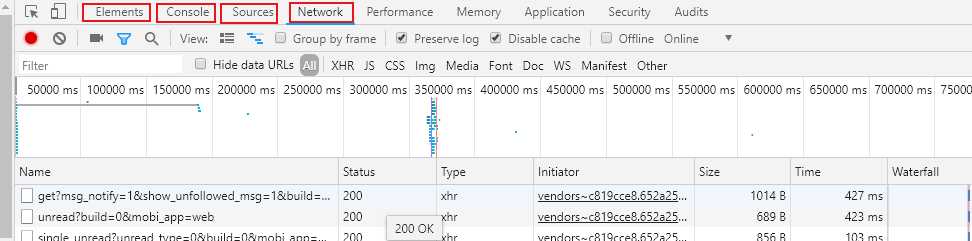
Element整体布局
console一些js代码
source文件组成
network浏览器发送的请求
以上是关于《爬虫学习》的主要内容,如果未能解决你的问题,请参考以下文章