在学习爬虫的路上,有多少坑在前边
Posted 文盲老顾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在学习爬虫的路上,有多少坑在前边相关的知识,希望对你有一定的参考价值。
在学习爬虫的路上,有多少坑在前边
前言
爬虫,采集,这些东西已经越来越耳熟能详了,越来越多的进入到初学者的学习范畴了,那么这些初学者到底有没有做好采集,爬虫的准备工作呢?一路上摔了多少跟斗,踩了多少坑,才真正理顺了采集的流程呢?
老顾虽然刚学python不久,但是采集这块用的时间还是不算短了,下面结合一些实际案例,讲一讲在采集的路上,容易踩中的有多少坑。
采集成功了,但是没有数据?
很多小伙伴,经常会遇到这种情况,最近混在问答里,也有很多这样的例子
那么,到底有没有采集成功呢?数据去哪里了?咱们先分情况来说明一下
数据就在采集到的页面,并有正确的格式
这种是最理想的状态,返回的页面代码,就是我们看到的内容
大家在采集的时候,非常喜欢做的一件事就是打开控制台,查看元素
比如,我们采集这么一个页面 https://www.ccgp.gov.cn/cggg/zygg/jzxcs/202303/t20230312_19542353.htm
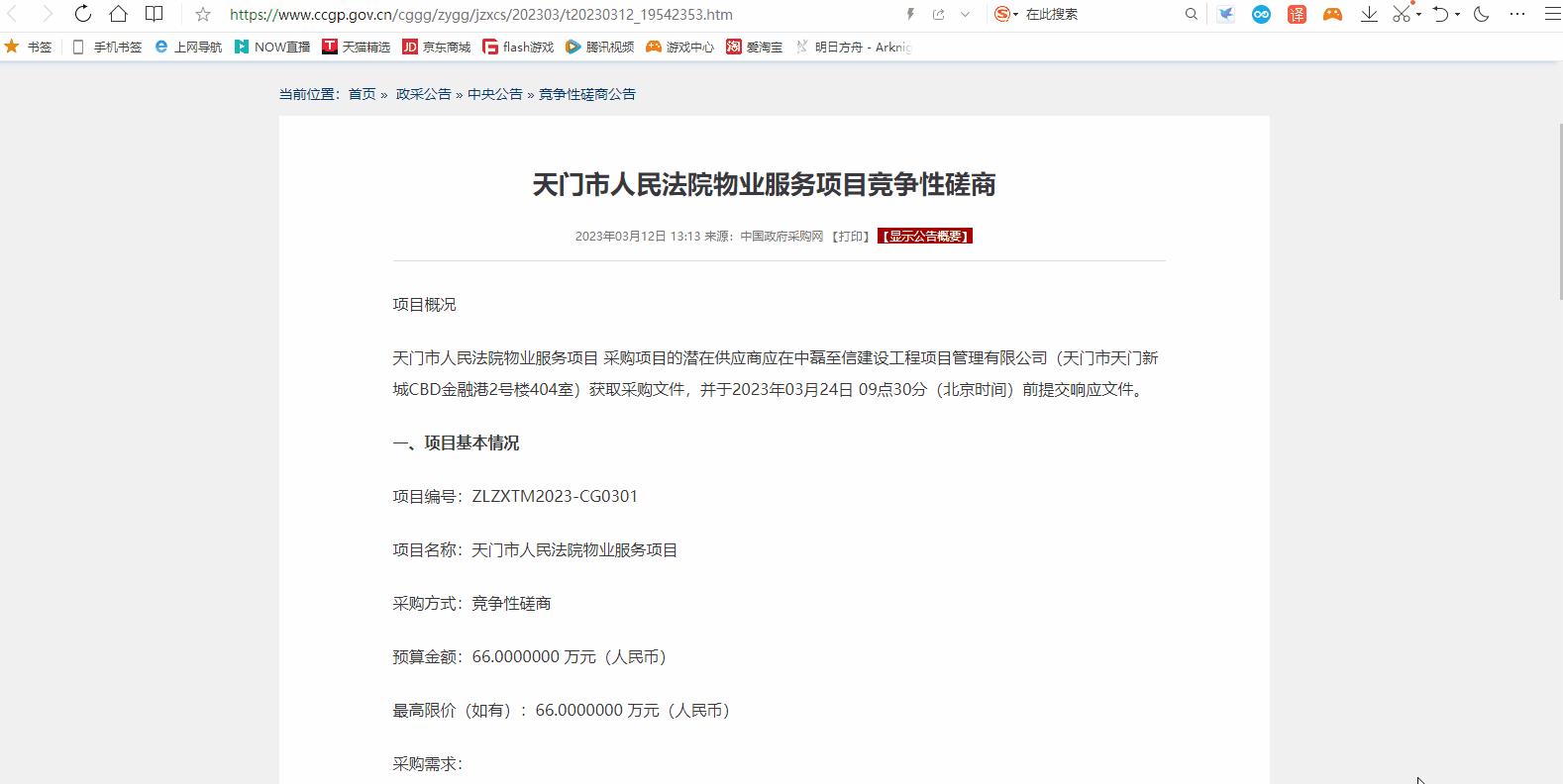
我们通过查看元素的方式,很容易找到我们需要抓取的正文所在位置,就在样式类名为vF_detail_content_container的div里,我们尝试用 python 来实现这个抓取,并提取正文
from bs4 import BeautifulSoup
import requests
headers=
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.63"
response = requests.get("https://www.ccgp.gov.cn/cggg/zygg/jzxcs/202303/t20230312_19542353.htm",headers=headers)
html = response.content.decode('utf8')
soup = BeautifulSoup(html, "html.parser")
contents = soup.findAll('div',attrs='class':'vF_detail_content_container')
for content in contents:
print(content)
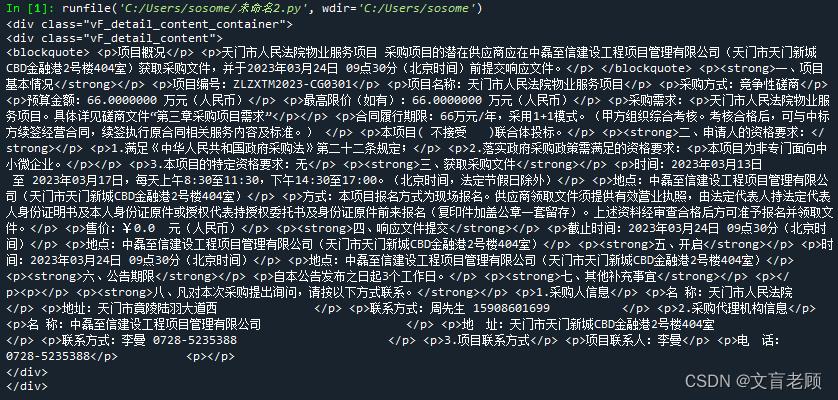
这就是最理想的采集,非常简单的几句话,就把数据拿到手了
数据就在采集到的页面,但提取的时候没有信息
以问答区某个小伙伴的问题为例,https://ask.csdn.net/questions/7897149/54099048?spm=1001.2014.3001.5501,这次的采集目标是 https://pic.sogou.com/pics?query=橘子皮
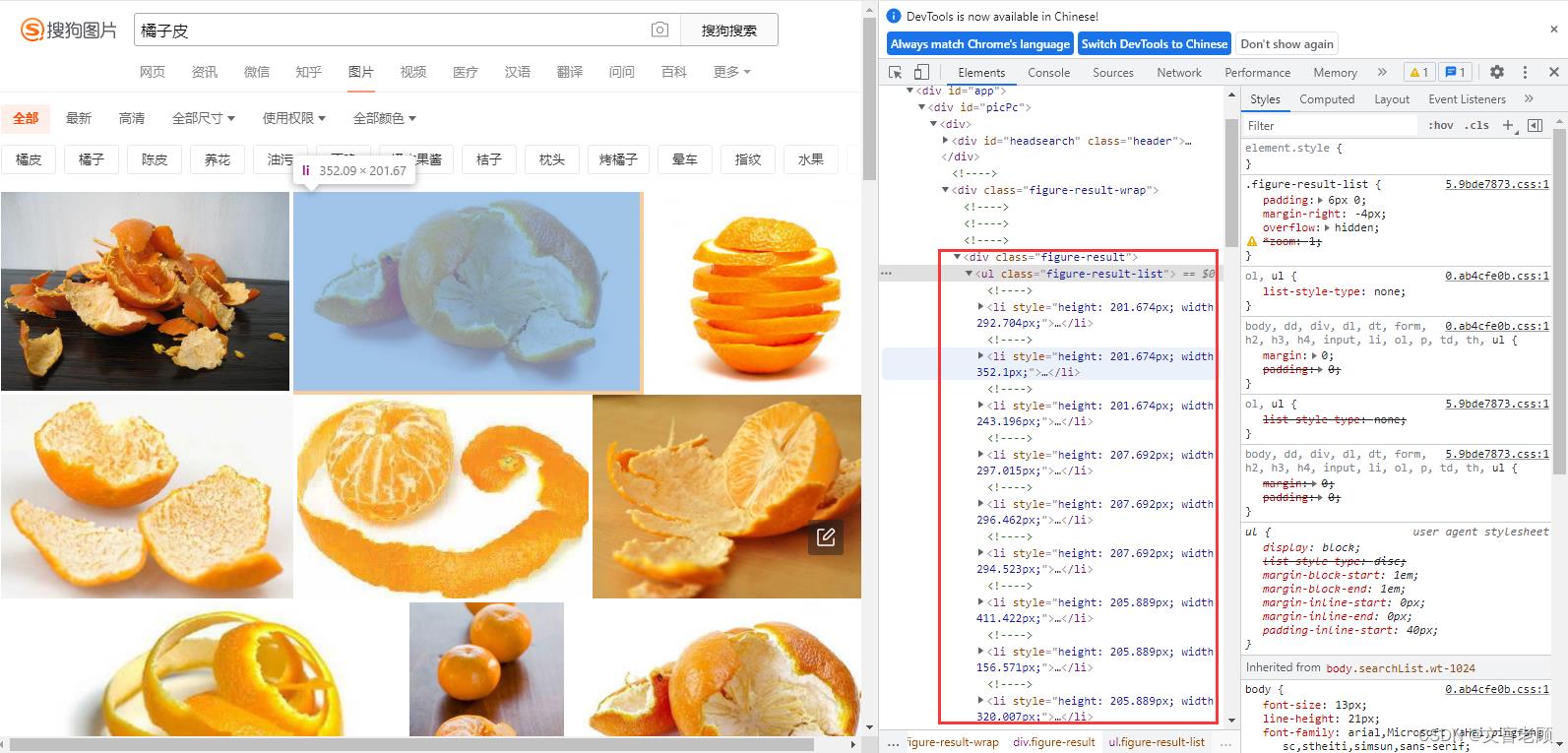
我们还是通过查看元素的方式,找到了所有图片的节点信息,嗯,在样式 figure-result-list 下的所有 li 里,问答的小伙伴也是这么做的,来我们模拟实现一下
import requests
from lxml import etree
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
url = 'https://pic.sogou.com/pics?query=橘子皮'
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="figure-result"]/ul/li')
print(li_list)

吖?明明页面里有内容啊,为什么我抓取不到?
嗯。。。。。这里,咱们需要补充一点点的基础知识,就是浏览器显示的内容,到底来自哪里
小伙伴不禁就问了,难道不是来自页面吗?
这么说,其实是没什么错啦,但是不完整。先听听老顾的说法。
补课:页面内到底有哪些信息
html 部分
第一,浏览器首先加载的就是 html 页面,不管这个页面后缀是什么,用的什么语言开发的,到浏览器的时候,他一定是 html 格式的。这里是第一个要素,刚才我们采集 ccgp 页面的时候,就只针对了这个 html 格式的内容进行提取就可以了。
css 部分
在浏览器加载完了 html 内容后,他开始要对页面进行渲染,已达到友好的视觉效果,这个时候,他就开始解析 html 了,他会从里面找出所有的 style 定义,以及通过 link 标签引进的 css 文件,对页面内容进行渲染
script 部分
在渲染效果弄好了之后,浏览器又开始了下一个工作,对脚本进行解释并运行,也就是我们通常锁说的 js ,或者是 vbs(虽然现在用的人很少了),这个时候有些交互内容,或者一些后续补充的内容,也会通过脚本的操作陆续添加的当前渲染的页面里
其他通过脚本引进或请求的部分
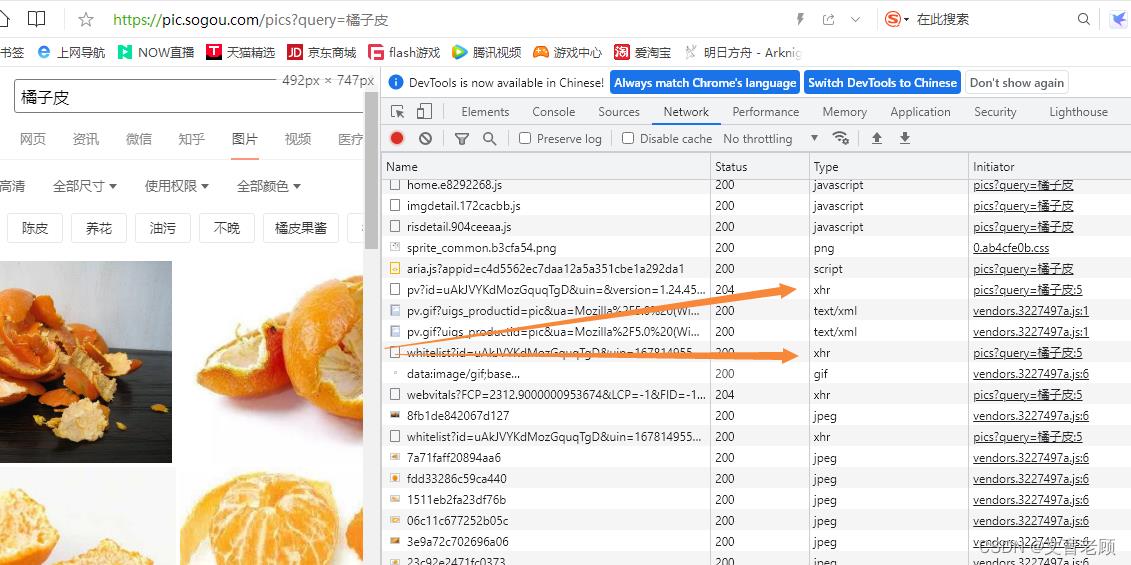
还是这个橘子皮,我们可以通过网络(network)页发现,他的请求类型有很多,除了常见的图片,js,还有一个xhr,这个就是引进的请求部分
补课结束了,以上内容就是一个页面完整的数据了,那么我们就回到橘子皮这个页面的数据提取,他的数据到底在哪里?
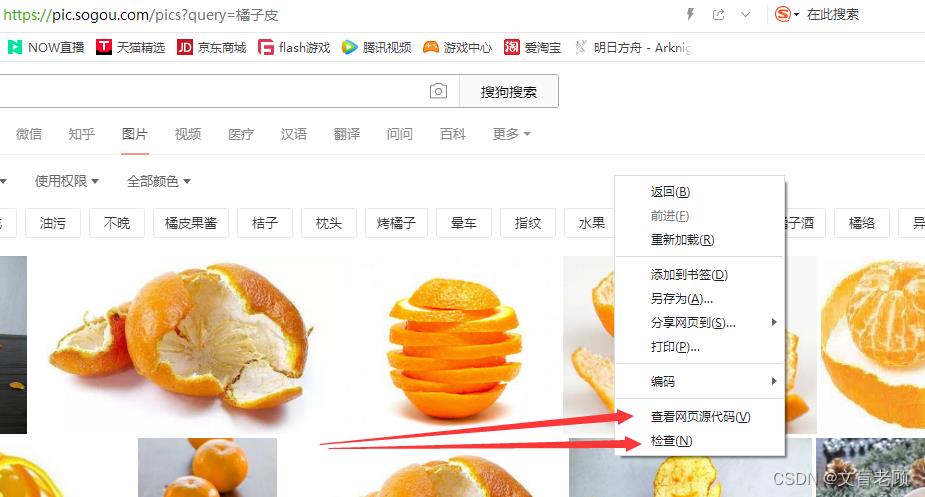
在页面上,我们点击鼠标右键,他会弹出一个快捷菜单,最下边就是我们常用的查看元素(部分浏览器里是检查),他可以方便的查看DOM信息,但更重要的其实是查看源代码
这次,我们就来查看一下源代码,看看橘子皮这个页面到底有没有我们需要的东西
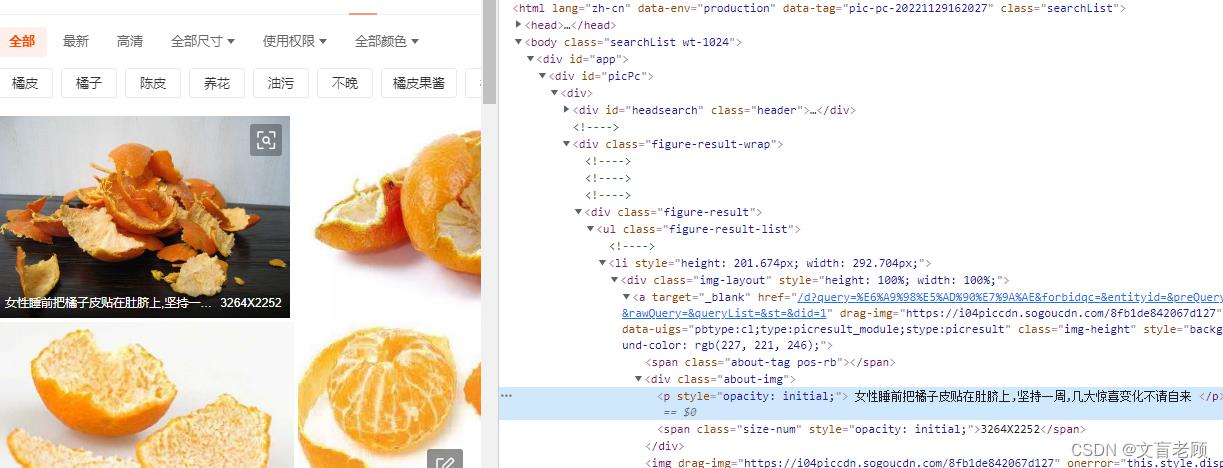
根据检查元素,我们可以看到,第一个图片的名字是“女性睡前把橘子皮贴在肚脐上,坚持一周,几大惊喜变化不请自来”,那么我们就在源文件里找这个内容
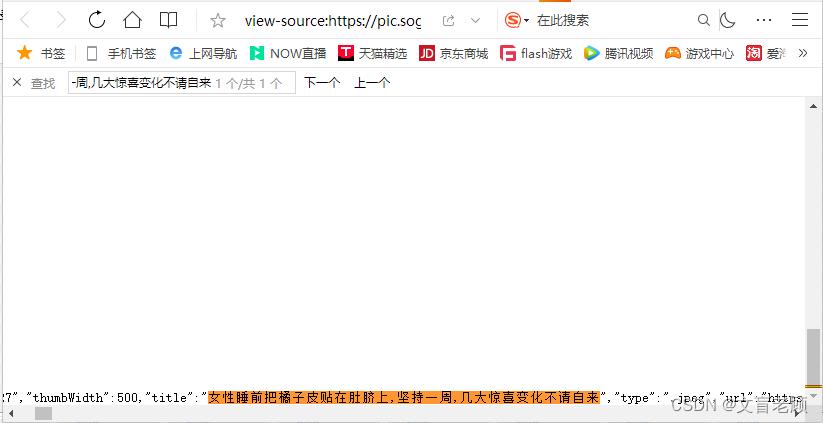
找到了,那么他就在采集到的页面里,但不在正确的位置上,他是通过脚本(js)后边渲染到我们看到的位置上的,那么我们该怎么拿到呢,那就是看到底出现的位置,我们发现是在一个 script 标签里,那么我们就来实现这个信息的提取吧
import requests
from lxml import etree
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
url = 'https://pic.sogou.com/pics?query=橘子皮'
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
js_list = tree.xpath('//script')
for i,js in enumerate(js_list):
print(' == > ')
print(i,etree.tostring(js_list[i]))
通过遍历,我们看到第二个 script 片段里就是我们需要的数据,但是我们需要自己解析出来,但里面的文字全都是 unicode 格式的,需要转换出来
来,我们掐头去尾,只留下数据部分来看看
import requests
from lxml import etree
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
url = 'https://pic.sogou.com/pics?query=橘子皮'
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
js_list = tree.xpath('//script')
#for i,js in enumerate(js_list):
# print(' == > ')
# print(i,etree.tostring(js_list[i]))
# 已知js_list第二项是数据了
def unicode(n): # 通过正则,将unicode转成字符
return chr(int(n.group(1)))
import re
import json
jscode = re.sub('^.*?=|;\\(function.*|;?</script>','',etree.tostring(js_list[1]).decode('utf8'))
jscode = re.sub('&#(\\d+);',unicode,jscode)
jsdata = json.loads(jscode)
print(jscode)
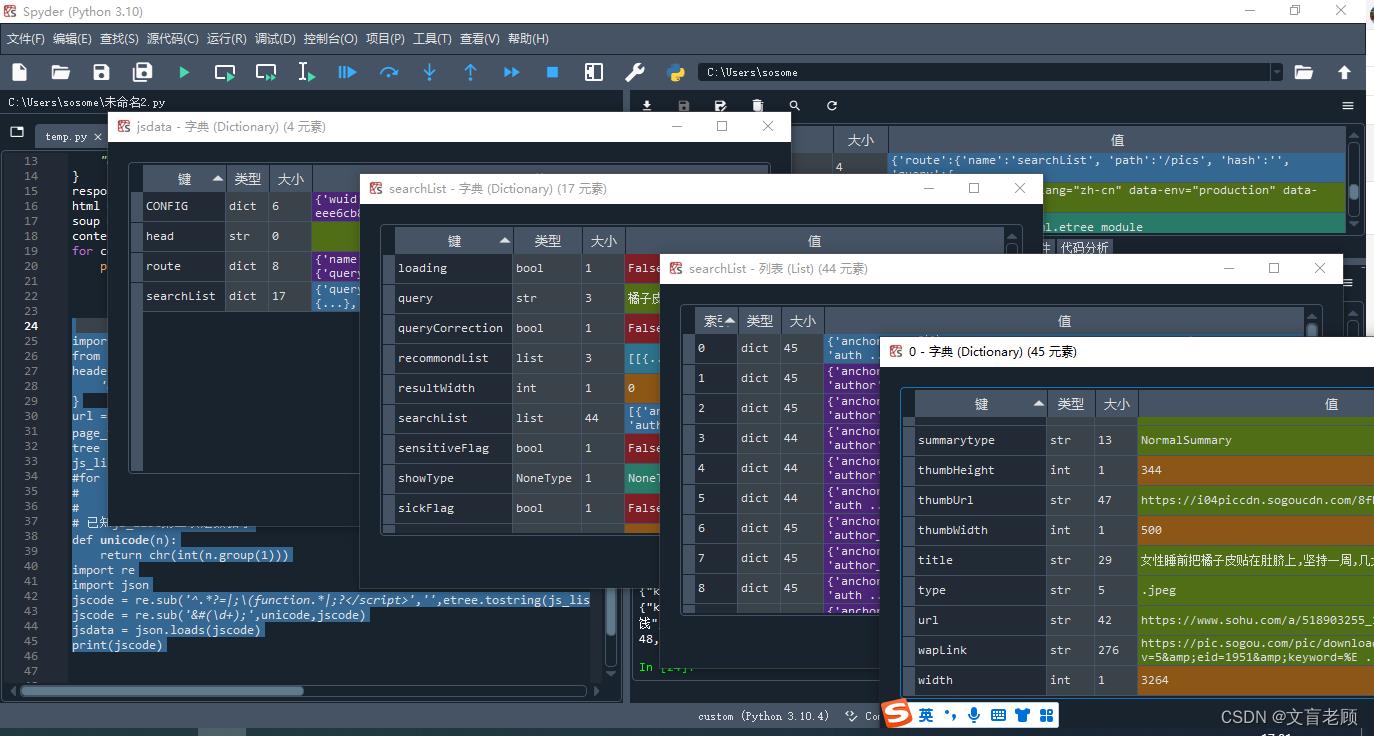
很好,我们通过 json 把数据加载成 json 格式,并通过变量查看,得到了 jsdata[‘searchList’][‘searchList’][0] 就是第一个图片的内容了,他的 title 就是我们刚才找的标题,什么女性睡前。。。
那么,这个小坑算是过去了
数据就在页面的 js 片段里,但不知道怎么正确的拿出来
刚才这个橘子皮的例子,我们就遇到了这个情况,我们已经知道了,他就在第二个js片段里,但是里面全是 &#数字; 这样的内容,在浏览器里,他会正确的显示对应的 unicode 字符,但是我们抓取的时候,这东西我们不认识啊,这是给人看的吗?
再来看另一个小伙伴的问答题目,https://ask.csdn.net/questions/7896060/54096521?spm=1001.2014.3001.5501
他要抓一个小说章节内容,也碰到这样的情况了,我们先把内容抓取出来,再一起分析
import requests
url = 'https://yc.ifeng.com/book/3303804/10/'
headers =
'host':'yc.ifeng.com',
'referer':'https://yc.ifeng.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
res = requests.get(url=url,headers=headers)
res.encoding = 'UTF-8'
print(res.text)
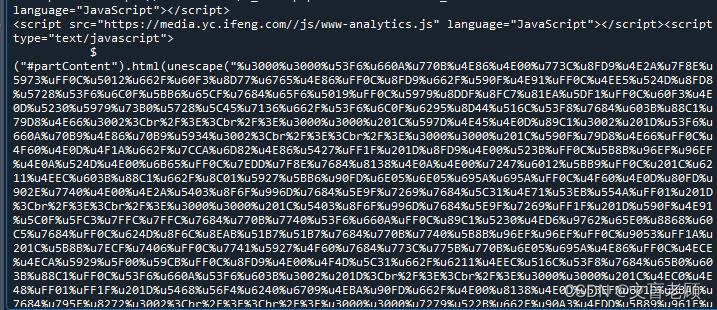
啊。这次正文是十六进制unicode字符了。。。。而且,也在js里,别急,我们先来补课
补课:使用正则,将 unicode 或其他编码格式的字符转换成正常字符
在 python 中,正则所在的包就是 re 了,我们 import re 就可以使用正则了
而正则中,我们最常用的就是判断是否合法,比如手机,比如信箱之类的,还有就是根据正则提取出我们需要的内容了
但是,真正在采集中,还有一个正则替换,也是非常非常常用的,而且是非常非常好用的,关于正则的内容,这里不细说了,大家可以看我以前的文章文盲的正则入门,以及 python 的正则部分
这里直接讲 python 正则替换使用委托的方式
在橘子皮的例子里,我们已经有了这么一个自定义方法 unicode
import re
def unicode(n):
return chr(int(n.group(1)))
print(re.sub('&#(\\d+);',unicode,'女性睡前把橘子皮贴在肚脐上,坚持一周,几大惊喜变化不请自来'))

这里,用到的是 re.sub(匹配正则,替换的字符或方法,原始字符串)中替换的方法,通过委托这个方法来将特定的内容按照一定规则转换
那么,刚才这个小说,也是一样的
import re
def unicodeHex(n):
return chr(int(n.group(1),16))
print(re.sub('%u([0-9a-fA-F]4)',unicodeHex,'%u3000%u3000%u53F6%u660A%u770B%u4E86%u4E00%u773C%u8FD9%u4E2A%u7F8E%u5973%uFF0C%u5012%u662F%u60F3%u8D77%u6765%u4E86%uFF0C%u8FD9%u662F%u590F%u4E91%uFF0C%u4EE5%u524D%u8FD8%u5728%u53F6%u6C0F%u5BB6%u65CF%u7684%u65F6%u5019%uFF0C%u5979%u8DDF%u8FC7%u81EA%u5DF1%uFF0C%u60F3%u4E0D%u5230%u5979%u73B0%u5728%u5C45%u7136%u662F%u53F6%u6C0F%u6295%u8D44%u516C%u53F8%u7684%u603B%u88C1%u79D8%u4E66%u3002%3Cbr%2F%3E%3Cbr%2F%3E%u3000%u3000%u201C%u597D%u4E45%u4E0D%u89C1%u3002%u201D%u53F6%u660A%u70B9%u4E86%u70B9%u5934%u3002%3Cbr%2F%3E%3Cbr%2F%3E%u3000%u3000%u201C%u590F%u79D8%u4E66%uFF0C%u4F60%u4E0D%u4F1A%u662F%u7CCA%u6D82%u4E86%u5427%uFF1F'))
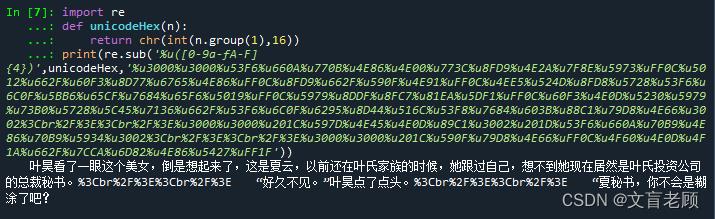
这里只举这两个例子,在实际工作中,还会碰到各种各样的需要解码的字符,比如 urldecode,unescape等等等等,总之,碰到这种就在页面内,但抓取到的信息不是给人看的东西的时候,记得转码哦
查看源文件,里面没有我们需要的内容?
这种情况也非常非常常见,这就是我们刚才补课所说的,其他通过脚本引进或请求的部分
还是用问答的小伙伴们的例子来说明,https://ask.csdn.net/questions/7900390/54106867?spm=1001.2014.3001.5501,这次的目标对准了B站
from bs4 import BeautifulSoup
import requests
headers=
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.63"
for page in range(1,10,1):
response = requests.get(f"https://www.bilibili.com/anime/index/#season_version=-1&spoken_language_type=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&year=-1&style_id=-1&order=3&st=1&sort=0&page=page",headers=headers)
html = response.text
print(html)
soup = BeautifulSoup(html, "html.parser")
all_bangumi_titles = soup.findAll("a", attrs="class":"bangumi-title")
all_pub_infos = soup.findAll("p", attrs="class": "pub-info")
for bangumi_title in all_bangumi_titles:
bangumi_title_string=bangumi_title.string
print(bangumi_title)
小伙伴的代码,其中一些语法错误咱们忽略,我帮他先修改正确
然后这个小伙伴很疑惑,吖,我都抓取成功了啊,为什么
但是运行结果没有对应的番剧名称和信息,并且我尝试打印了一下返回的response.text
结果是重复的一段不包含目标字段的代码
好吧,我们回到查看元素这里
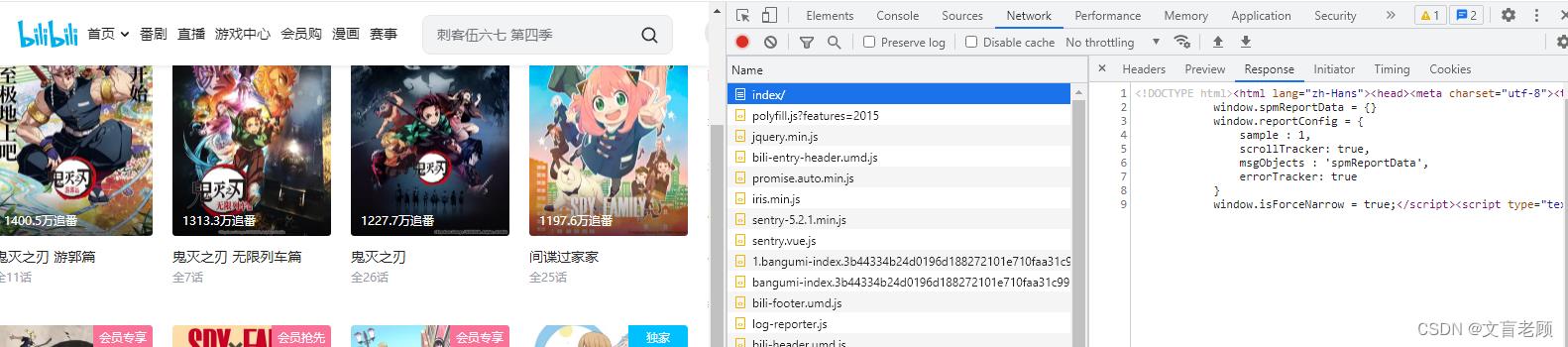
哦吼,index这个页面的内容很少啊,就是一个架子,所有的内容基本上都是通过其他方式加载的,来我们设置一下 network 的过滤,看看有多少 xhr
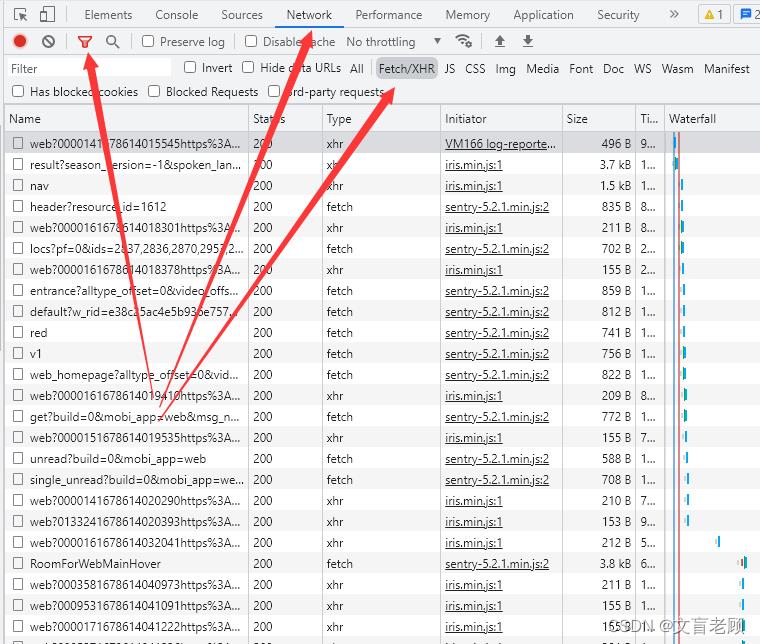
在network(网络)页,点漏斗,然后选择 xhr,发现好多好多啊,这些都是一些异步请求的数据,因为是异步请求,所以有个单独的分类叫做xhr,同步的,就叫 js
那么,我们就需要找,数据到底在哪里了
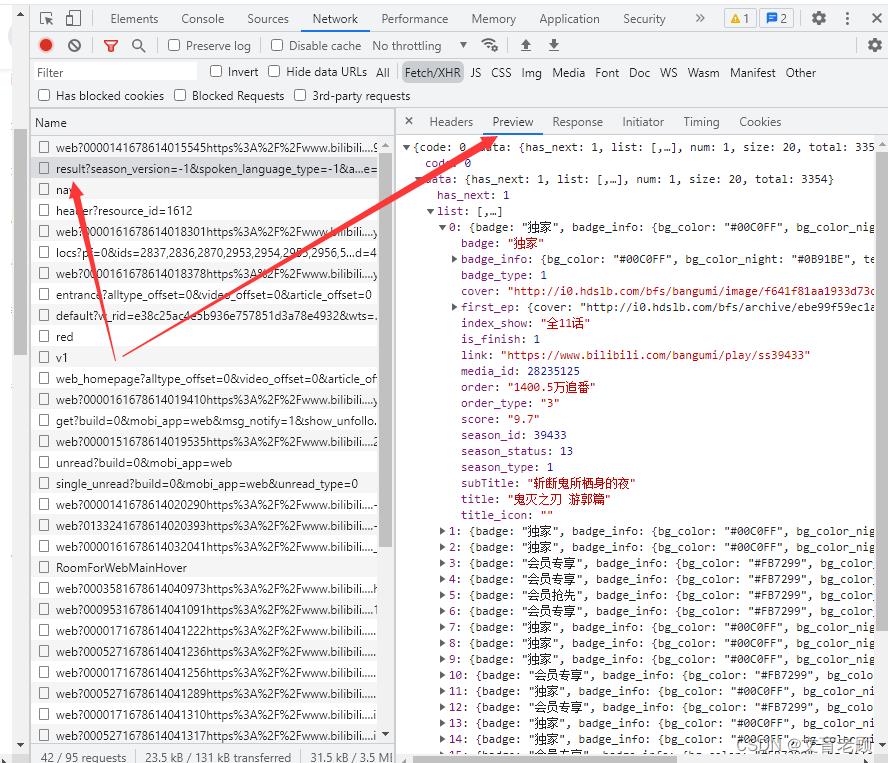
对于 xhr 来说,他通常只有两种返回的内容,一种是需要立刻执行的指令,一般是防采集用的,另一种就是 json 格式的数据了,我们可以通过 preview(预览)方式来方便的查看他的数据内容,并记住这个xhr请求地址,这个才是我们需要抓取的内容,而不是说B站的这个index页面
采集成功了,但是内容是乱码
在网络上,由于各种历史原因,很多网站的编码不一定是utf8,都是一些ansi标准的本地编码,比如gbk,big5之类的,有的,甚至就是utf8,但抓到本地也是乱码
我们回到本文的第一个采集
from bs4 import BeautifulSoup
import requests
headers=
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.63"
response = requests.get("https://www.ccgp.gov.cn/cggg/zygg/jzxcs/202303/t20230312_19542353.htm",headers=headers)
html = response.content.decode('utf8')
soup = BeautifulSoup(html, "html.parser")
contents = soup.findAll('div',attrs='class':'vF_detail_content_container')
for content in contents:
print(content)
小伙伴们有没有发现,我使用的是 response.content,而不是常用的 response.text,因为我们在发送请求的时候没有指定编码格式,而采集小说的那个小伙伴做的非常好,就指定了编码,虽然他最后也没能把小说拿出来。回到ccgp这个页面,由于我没有指定编码,所以 response.text 得到的就是一堆乱码内容了
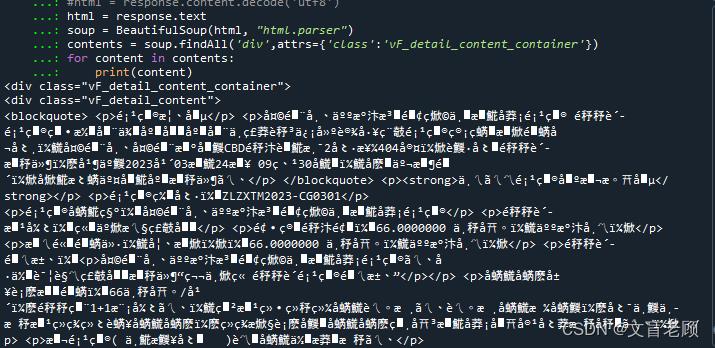
这里就要说明一下,网站乱码的各种情况了
乱码的产生,基本上就是两边的编码不一致造成的,这种情况下,要么我们像那个采集小说的小伙伴一样,指定编码,要么像老顾这样,在采集到之后,使用 response.content.decode 来解码
这些还都好说,但是,很多站他的数据就不是正经的可读数据,至少不是给人看的,比如刚才我们遇到的小说站,搜狗图片站,就需要我们自己把编码后的内容解码出来
还有一些小伙伴会碰到一些更严重的问题,我这里暂时无法复现出这个情况了,但还是可以描述一下,那就是在对 resposne.content.decode 的时候,会碰到这样的错误
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x8b in position 1: invalid start byte
这是因为返回的数据,使用了 gzip 或者deflate压缩技术,我们需要通过同样的办法对这些数据进行解压解码
根据 response.header 里,content-encoding 的信息,来确定使用哪个方式来解压解码
# content-encoding : gzip
import gzip
html = gzip.decompress(response.content).decode('utf8')
# content-encoding : deflate
import zlib
try:
html = zlib.decompress(response.content, -zlib.MAX_WBITS).decode('utf8')
except zlib.error:
html = zlib.decompress(response.content).decode('utf8')
当然,还有一种已知的压缩算法 br,但老顾还没碰到过,暂时不知道需要什么包来解压解码
我们该怎么提取抓取到的内容
使用 lxml 或 bs4 处理 html
通常,我们对页面抓取,抓到的就是 html ,大家都已经很熟悉了,使用 BeautifulSoup 的 html.parser 也好,使用 lxml 的 xpath 也好,都可以对 html 内容进行分析
import requests
headers=
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.63"
,'accept-encoding':'gzip, deflate, br'
response = requests.get("https://www.ccgp.gov.cn/cggg/zygg/jzxcs/202303/t20230312_19542353.htm",headers=headers)
html = response.content.decode('utf8')
正文 = []
# 使用 BeautifulSoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
contents = soup.findAll('div',attrs='class':'vF_detail_content_container')
for content in contents:
正文.append(str(content))
# 使用 lxml
from lxml import etree
tree = etree.HTML(html)
contents = tree.xpath('//div[@class="vF_detail_content_container"]')
for content in contents:
正文.append(etree.tostring(content,encoding='utf8').decode('utf8'))
可以看到,两种方式都能正确的抓到信息,并提取出来,当然,小伙伴们用哪个熟就用哪个好了,老顾对这些都不熟。。。不知道有没有更简单的不乱码的情况
使用 json 处理 json 数据
还有的,就是本文中提到的,抓到的就是 json 数据了,这个时候就不要想那么多了,直接使用 json.loads 就好,还是用B站的这个吧
url = 'https://api.bilibili.com/pgc/season/index/result?season_version=-1&spoken_language_type=-1&area=-1&is_finish=-1%C2%A9right&season_status=-1&season_month=-1&year=-1&style_id=-1&order=3&st=1&sort=0&page=1©right=-1&season_type=1&pagesize=20&type=1'
import requests
headers=
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.63"
response = requests.get(url,headers=headers)
data = response.content.decode('utf8')
# 使用 json 直接加载数据
import json
json_data = json.loads(data)
for k in json_data:
print(k,json_data[k])
加载之后,我们就需要找到我们需要的数据所在的深度和路径了
lst = json_data['data']['list']
for k in lst:
print(k['title'],k['index_show'],k['link'])

使用 execjs 来获取 js 中的数据
在使用 execjs 之前,先安装 pyexecjs 包,注意安装的包名字和引用的名字不一样哦,由于老顾暂时没能解决 window 未定义,document 未定义的问题,所以还是辅助了一些其他手段,这里还是以采集小说的小伙伴为例子
import requests
url = 'https://yc.ifeng.com/book/3303804/10/'
headers =
'host':'yc.ifeng.com',
'referer':'https://yc.ifeng.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
response = requests.get(url,headers=headers)
html = response.content.decode('utf8')
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
scripts = soup.findAll('script')
# 查到小说正文在第11个script里
#print(scripts[10].text)
# 替换掉 jquery 指令,并把后续的 jquery 指令删除
js = scripts[10].text.replace('$("#partContent").html','var content = ').split('$')[0]
import execjs
ctx = execjs.compile(js)
result = ctx.eval('content')
print(result)

这种方式好就好在他可以使用 js 内的解码,不用我们再去解码了
这里不再介绍的 selenium 执行 js
这里就不介绍了,老顾非常不喜欢可以在后台默默运行的东西蹦到前边来,老顾以前用 c# 做采集的时候,都不喜欢用webbrowser控件的,原谅老顾不够厚道,真不想用这个
一种罕见的 xml 源文件的 html
在老顾的采集生涯中,碰到这样的奇葩网站,看页面是html,查看元素也是 html ,查看源文件。。。他就变成 xml 了,还带有 xslt 样式。当然,如果 xml 没有 xslt 那就没办法变成 html 了,这里举个例子:https://www.govinfo.gov/content/pkg/BILLS-117hr3237ih/xml/BILLS-117hr3237ih.xml,有兴趣的小伙伴可以围观一下,当然这个例子其实还算是好的,比较规整的,有更复杂的,需要 xslt 执行计算的,老顾一时找不到例子了,就不举例了。另外,这里也不细说怎么处理了,可以参考老顾的 python 学习 xml 的文章
其他的一些常见的语法错误,下标越界之类的问题,本文就不再说了。。。这种错误和语言没关系,完全就是小伙伴们不细心没耐心了
致Python初学者-从入门到爬虫开发,这一篇文带你省略学习路上的歪歪扭扭
引子
不知从何时开始,Python火遍了大江南北,有几个有趣的例子可以佐证。
第一个例子是某房地产大佬在56岁生日当天发了一条微博,表示自己要开始学习Python,作为给自己人生的礼物。完成了几个月的学习后,他还参加了NCT青少年编程能力等级考试,居然考了个99分。
 第二个例子是骗子盯上了Python培训。什么“学完Python可以上天”、“三个月拿高薪”、“一行代码教你开启上帝模式”之类的广告遍布微信、微博、抖音等各大社交平台。我们都知道,骗子是最善于紧跟时代变化、抓住人性弱点的,从这个角度对Python的热度也可以窥豹一斑。
第二个例子是骗子盯上了Python培训。什么“学完Python可以上天”、“三个月拿高薪”、“一行代码教你开启上帝模式”之类的广告遍布微信、微博、抖音等各大社交平台。我们都知道,骗子是最善于紧跟时代变化、抓住人性弱点的,从这个角度对Python的热度也可以窥豹一斑。

第三个例子是各大电商的畅销书排行榜,看看计算机类图书,不出意外的话,Top3里面肯定会有一本有关Python学习的书籍。
 最后一个例子离我更近,从这学期开始,蚌工商非计算机专业的《计算机应用技术》课程全部由VB程序设计改成了Python。开课之前,我认真思考了一下,为什么非计算机专业的学生要学习Python。我觉得要回答这个问题,可以分成两步:一是为什么要学习编程;二是在众多编程语言中为什么要首选Python。
最后一个例子离我更近,从这学期开始,蚌工商非计算机专业的《计算机应用技术》课程全部由VB程序设计改成了Python。开课之前,我认真思考了一下,为什么非计算机专业的学生要学习Python。我觉得要回答这个问题,可以分成两步:一是为什么要学习编程;二是在众多编程语言中为什么要首选Python。
为什么编程者首选Python?
编程语言那么多,为什么一定要学Python呢?
截止目前世界上有多少种编程语言?我在网上搜了搜,没有找到一个确切的数字。因为很多编程语言比较小众,使用的人很少,而且每年都会有新的编程语言出现,也会有很多编程语言渐渐不再被人使用。虽然没有确切数字,但怎么说也得有上千种吧,而且这些编程语言的首字母早已涵盖了字母表A到Z。

不同的编程语言出现的年代不同、所处的层次不同、设计的初衷也不同。在计算机出现的萌芽阶段,所使用的主要是机器语言,直接与硬件设备打交道。后来,为了方便程序员,出现了使用助记符的汇编语言。再后来,接近自然语言的高级语言出现,进一步让程序员聚焦实际的计算问题,不再考虑计算机实现的细节。
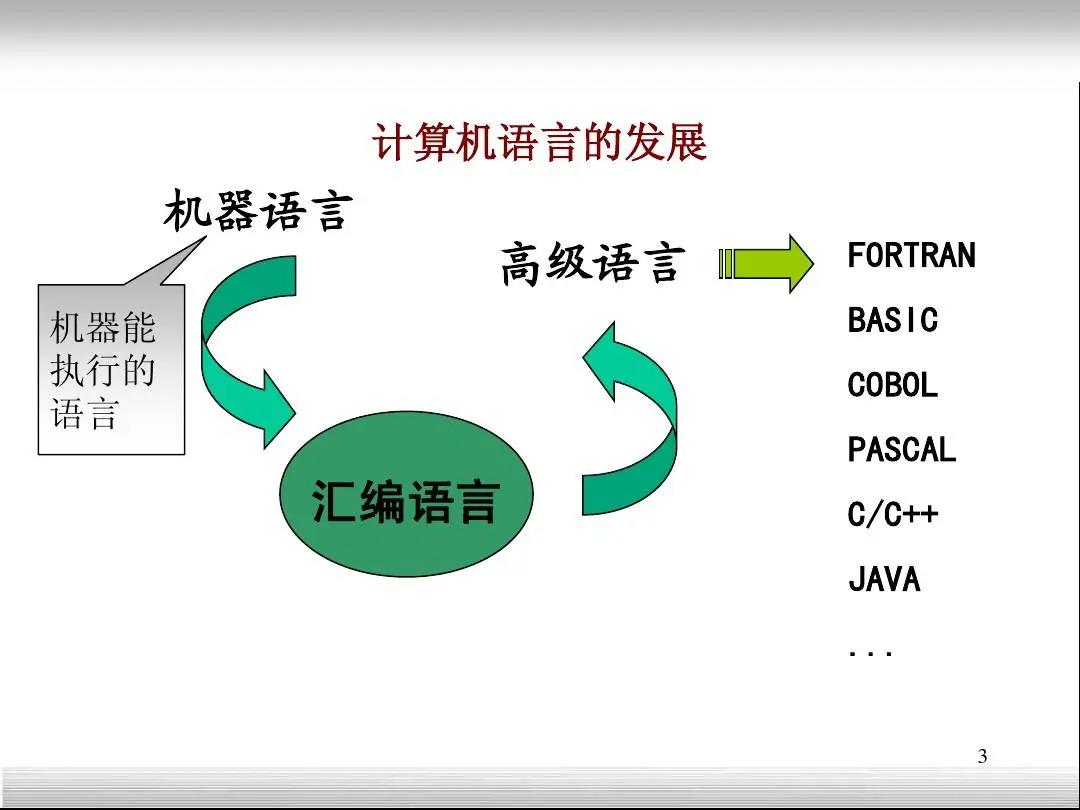
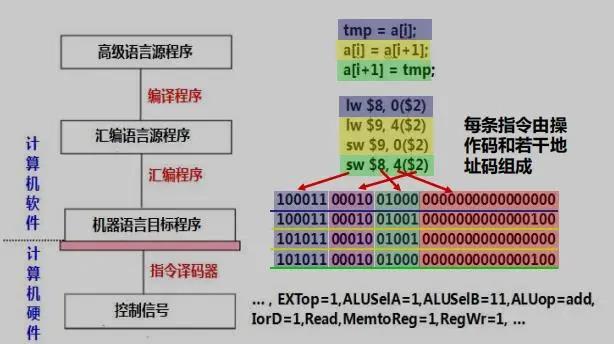
编程语言设计的目的还和所处的时代需求紧密相关。在网络出现之前,计算机科学领域研究的重点主要是提高性能。所以这一阶段编程语言的本质是理解计算机系统结构,以C语言为代表。随着互联网和视窗操作系统的出现,编程语言的主要使命变成了解决人-机交互和机-机交互的问题。人-机交互主要采用可视化编程语言来解决,比如VB。机-机交互主要是解决跨平台的问题,最具代表性的就是JAVA语言。随着智能手机和移动互联网的出现,计算机进入了复杂信息系统时代。这一时代的主题是数据,从数据的产生到数据的处理与分析,与之相应,最基础的如SQL语言,专业的有MATLAB、R语言等。如今,我们进入了人工智能时代,基础的计算工作已经逐渐被AI接管,这时候就需要一种与之相适应的编程语言。这种编程语言应该具有什么特点呢?
首先,语法要简洁。语法简洁才易于上手、容易调试,要尽可能的不涉及底层语法元素,才能为更多的人所使用,尤其是对于众多非计算机专业人员。其次生态要强大。要兼容并包,具有快速共享的计算生态,要开放共享,能够跨越操作系统平台。综合考察这两个方面,Python是目前最适合的那一个。

Python语言学习难度低,语法非常简单,容易理解,可以做到快速上手;Python语言开发效率高,相比C++、Java等编译/静态类型语言,其开发效率提升了至少十倍,能够以更少的代码、更短的时间完成编程任务;Python语言生态强大,除了具有功能强大的标准库,还有数量级在10万的开源第三方程序库可以供开发者直接拿来使用;Python语言平台独立,易于移植;Python语言扩展性好,可以通过接口或函数库方便的调用其他编程语言编写的代码,号称“胶水语言”……
既然编程这么有用,Python语言这么好用,那还等什么呢,人生苦短,一起Python吧!

从入门到爬虫开发教学资料
需要文中以下资料的可以到文末免费领取。
Python入门基础教程
第1章 快速上手:基础知识
1.1 交互式解释器
1.2 算法是什么
1.3 数和表达式
1.4 变量
1.5 语句
1.6 获取用户输入
1.7 函数
1.8 模块
1.9 保存并执行程序
1.10 字符串
第2章 列表和元组
2.1 序列概述
2.2 通用的序列操作
2.3 列表:Python的主力
2.4 元组:不可修改的序列
第3章 使用字符串
3.1 字符串基本操作
3.2 设置字符串的格式:精简版
3.3 设置字符串的格式:完整版
3.4 字符串方法
3.5 小结

第4章 当索引行不通时
4.1 字典的用途
4.2 创建和使用字典
第5章 条件、循环及其他语句
5.1 再谈print和import
5.2 赋值魔法
5.3 代码块:缩进的乐趣
5.4 条件和条件语句
5.5 循环
…
第6章 抽象
6.2 抽象和结构
6.3 自定义函数
6.4 参数魔法
6.5 作用域…
第7章 再谈抽象
7.1 对象魔法
7.2 类
7.3 关于面向对象设计的一些思考
第8章 异常
8.1 异常是什么
8.2 让事情沿你指定的轨道出错
8.3 捕获异常
8.4 异常和函数
…
第9章 魔法方法、特性和迭代器
9.1 如果你使用的不是Python 3
9.2 构造函数
9.3 元素访问
…
第10章 开箱即用
10.1 模块
10.2 探索模块
10.3 标准库:一些深受欢迎的模块
…
第11章 文件
11.1 打开文件
11.2 文件的基本方法
11.3 迭代文件内容
第12章 图形用户界面
12.1 创建GUI示例应用程序
12.2 使用其他GUI工具包
…
第13章 数据库支持
13.1 Python数据库API
13.2 SQLite和PySQLite
…

第14章 网络编程
14.2 SocketServer及相关的类
14.3 多个连接
…
第15章 Python和Web
15.1 屏幕抓取
15.2 使用CGI创建动态网页
15.3 使用Web框架
…
第16章 测试基础
16.1 先测试再编码
16.2 测试工具
16.3 超越单元测试
…
第17章 扩展Python
17.1 鱼和熊掌兼得
17.2 简单易行的方式:Jython和IronPython
…

第18章 程序打包
第19章 趣味编程
第20章 项目1:自动添加标签
第21章 项目2:绘制图表
第22章 项目3:万能的XML
第23章 项目4:新闻汇总
第24章 项目5:虚拟茶话会
第25章 项目6:使用CGI进行远程编辑
第26章 项目7:自建公告板
第27章 项目8:使用XML-RPC共享文件
第28章 项目9:使用GUI共享文件
第29章 项目10:自制街机游戏

Python爬虫开发与项目实战
本资料旨在教会大家必要的Python爬取信息的技能(也称为Python爬虫技能)。资料的主要面向群体是已经看完了Python基础课程(0基础小白可以查看上面资料),正准备进行编码实践的爬虫小白。资料讲述的内容为基本的Python爬虫技巧,能应付普通上班族90%的数据爬取需求。
这个资料大致包含以下内容,一共18个章节,内容形式为图文,没有视频;
资料内容详细分为了基础篇:

中级篇

深入篇
部分内容展示


资料内容通俗易懂,循序渐进,让新手也能很容易地接受。如果潜心学习、心无旁骛,一天之内应该就能大致掌握课程的内容。非常适合上班族、学生党业余时间用来充实、提高自己的能力。
废话不多说,在哪里学习呢?扫描下方二维码,免费领取。

以上是关于在学习爬虫的路上,有多少坑在前边的主要内容,如果未能解决你的问题,请参考以下文章