《爬虫学习》(urllib库使用)
Posted whgy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《爬虫学习》(urllib库使用)相关的知识,希望对你有一定的参考价值。
urllib库是Python中一个最基本的网络请求库。可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据。
1.urlopen函数:
在Python3的urllib库中,所有和网络请求相关的方法,都被集到urllib.request模块下面了,以先来看下urlopen函数基本的使用:
from urllib import request
resp = request.urlopen(‘http://www.baidu.com‘)
print(resp.read())
实际上,使用浏览器访问百度,右键查看源代码。你会发现,跟我们刚才打印出来的数据是一模一样的。也就是说,上面的三行代码就已经帮我们把百度的首页的全部代码爬下来了。一个基本的url请求对应的python代码真的非常简单。
以下对urlopen函数的进行详细讲解:
url:请求的url。data:请求的data,如果设置了这个值,那么将变成post请求。- 返回值:返回值是一个
http.client.HTTPResponse对象,这个对象是一个类文件句柄对象。有read(size)、readline、readlines以及getcode等方法。
2.urlretrieve函数:
这个函数可以方便的将网页上的一个文件保存到本地。以下代码可以非常方便的将百度的首页下载到本地:
from urllib import request
request.urlretrieve(‘http://www.baidu.com/‘,‘baidu.html‘)
3.编码解码urlencode函数/parse_qs函数:
urlencode函数
用浏览器发送请求的时候,如果url中包含了中文或者其他特殊字符,那么浏览器会自动的给我们进行编码。而如果使用代码发送请求,那么就必须手动的进行编码,这时候就应该使用urlencode函数来实现。urlencode可以把字典数据转换为URL编码的数据。示例代码如下:
from urllib import parse
data = {‘name‘:‘爬虫基础‘,‘greet‘:‘hello world‘,‘age‘:100}
qs = parse.urlencode(data)
print(qs)parse_qs函数:
可以将经过编码后的url参数进行解码。示例代码如下:
from urllib import parse
qs = "name=%E7%88%AC%E8%99%AB%E5%9F%BA%E7%A1%80&greet=hello+world&age=100"
print(parse.parse_qs(qs))
4.urlpares函数/urlsplit函数:
有时候拿到一个url,想要对这个url中的各个组成部分进行分割,那么这时候就可以使用urlparse或者是urlsplit来进行分割。示例代码如下:
from urllib import request,parse
url = ‘http://www.baidu.com/s?username=zhiliao‘
result = parse.urlsplit(url)
# result = parse.urlparse(url)
print(‘scheme:‘,result.scheme)
print(‘netloc:‘,result.netloc)
print(‘path:‘,result.path)
print(‘query:‘,result.query)
urlparse和urlsplit基本上是一模一样的。唯一不一样的地方是,urlparse里面多了一个params属性,而urlsplit没有这个params属性。比如有一个url为:url = ‘http://www.baidu.com/s;hello?wd=python&username=abc#1‘,
那么urlparse可以获取到hello,而urlsplit不可以获取到。url中的params也用得比较少。
5.request.Request函数:
如果想要在请求的时候增加一些请求头,那么就必须使用request.Request类来实现。比如要增加一个User-Agent,示例代码如下:
from urllib import request
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36‘
}
req = request.Request("http://www.baidu.com/",headers=headers)
resp = request.urlopen(req)
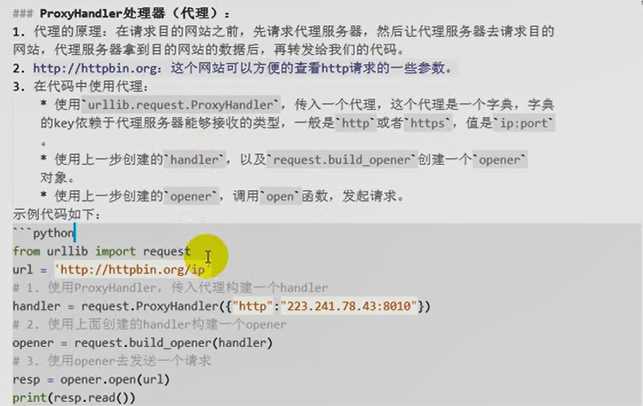
print(resp.read())6.代理器设置(ProxyHandler):
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
urllib中通过ProxyHandler来设置使用代理服务器,下面代码说明如何使用自定义opener来使用代理:
from urllib import request
# 这个是没有使用代理的
# resp = request.urlopen(‘http://httpbin.org/get‘)
# print(resp.read().decode("utf-8"))
# 这个是使用了代理的
handler = request.ProxyHandler({"http":"218.66.161.88:31769"})
opener = request.build_opener(handler)
req = request.Request("http://httpbin.org/ip")
resp = opener.open(req)
print(resp.read())
代码:
from urllib import request from urllib import parse #resp = request.urlopen(‘https://www.sohu.com‘)打开 #print(resp.readlines()) #resp = request.urlretrieve(‘http://www.jd.com‘, ‘jd.html‘)下载 # 编码 # infomation = {‘name‘:‘张三‘, ‘age‘:18, ‘code‘:‘niu‘} # result = parse.urlencode(infomation) # print(result) # url = "http://www.sogou.com" # par = {‘query‘:‘武佩齐‘} # qs = parse.urlencode(par) # url = url + "/web?" +qs # request.urlretrieve(url, ‘1.html‘) # 解码 # infomation = {‘name‘:‘张三‘, ‘age‘:18, ‘code‘:‘niu‘} # qs = parse.urlencode(infomation) # res = parse.parse_qs(qs) # print(res) #解析 # url = ‘http://www.baidu.com/s?wd=python&username=jd#1‘ # # result = parse.urlparse(url) # print(result.netloc) # result = parse.urlsplit(url) # print(result) # 实战 # url = ‘https://search.bilibili.com/all?keyword=opencv&from_source=nav_search_new‘ # head = { # ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400‘, # ‘Referer‘: ‘https://www.bilibili.com/‘ # # } # data = { # ‘first‘:‘true‘, # ‘pn‘:1, # ‘kd‘:‘opencv‘ # } # # req = request.Request(url, headers=head,data=parse.urlencode(data).encode(‘utf-8‘), method=‘GET‘) # resp = request.urlopen(req) # print(resp.read().decode(‘utf-8‘)) # 代理服务器 # 没有使用代理 # url = ‘http://www.httpbin.org/ip‘ # resp = request.urlopen(url) # print(resp.read()) # 使用代理 # url = ‘http://www.httpbin.org/ip‘ # # 1.使用request.ProxyHandler创建hander # hander = request.ProxyHandler({"http":"125.123.137.33:9999"}) # # 2.使用request.build_opener创建opener,通过hander # opener = request.build_opener(hander) # # 3.使用opener进行open连接 # resp = opener.open(url) # print(resp.read())
补充:Cookie:
在网站中,http请求是无状态的。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。cookie的出现就是为了解决这个问题,第一次登录后服务器返回一些数据(cookie)给浏览器,然后浏览器保存在本地,当该用户发送第二次请求的时候,就会自动的把上次请求存储的cookie数据自动的携带给服务器,服务器通过浏览器携带的数据就能判断当前用户是哪个了。cookie存储的数据量有限,不同的浏览器有不同的存储大小,但一般不超过4KB。因此使用cookie只能存储一些小量的数据。
以上是关于《爬虫学习》(urllib库使用)的主要内容,如果未能解决你的问题,请参考以下文章