小爬虫学习—— urllib 与 urllib3
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小爬虫学习—— urllib 与 urllib3相关的知识,希望对你有一定的参考价值。
urllib 是一个内置官方标准库,无需下载;它是python2中的 urllib 与 urllib2 的合并,urllib3 库是第三方标准库, 解决了线程安全,增加了连接池等功能,urllib与urllib3 相互补充;
一、urllib库
urllib库主要包含4个模块:
- urllib.requests:请求模块
- urlib.error:异常处理模块
- urllib.parse:url解析模块
- urllib.robotparser :robots.txt解析模块
1.1、urllib.request模块
request模块主要负责构造和发起网络请求,并在其中添加Headers,Proxy等。
利用它可以模拟浏览器的请求发起过程。
1.发起网络请求。
2.添加Headers。
3.操作cookie。
4.使用代理。
1.1.1、发起网络请求
urlopen方法
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
功能:urlopen是一个发送简单网络请求的方法,然后返回结果。
参数:
① url:必选;可以是一个字符串或一个 Request 对象。
② data:None–GET请求;有数据(字节类型/文件对象/可迭代对象)–POST请求(POST请求的话,data数据会放进form表单进行提交);
③ timeout:有默认设置;以秒为单位,例:设置timeout=0.1 超时时间为0.1秒(如果超出这个时间就报错!)
返回值:urlib库中的类或者方法,在发送网络请求后,都会返回一个urllib.response的对象。它包含了请求回来的数据结果。它包含了一些属性和方法,供我们处理返回的结果。
示例:
from urllib import request
# test_url="http://httpbin.org/get" 注意使用get请求的话data要为空
test_url="http://httpbin.org/post"
res=request.urlopen(test_url,data=b"spider")
print(res.read())#字节串 所有的内容
print(res.getcode())#获取状态码
print(res.info())#获取响应头信息
print(res.read())#字节串 再次读取,为空
Request对象
利用urlopen可以发起最基本的请求,但这几个简单的参数不足以构建一个完整的请求(添加请求头,添加不同请求方法),可以通过构造来构建更加完整的请求。
class Request:
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None):
pass
功能:Request是一个构造完整网络请求的对象,然后返回请求对象。
参数:
① url:必选;是一个字符串
② data:字节类型
③ headers:请求头信息
④ method:默认GET,可填写 POST、PUT、DELETE等
返回值:一个请求对象
示例:
from urllib import request
#Request对象
test_url="http://httpbin.org/get"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/81.0.4044.138 Safari/537.36"}
req=request.Request(test_url,headers=headers)
res=request.urlopen(req)
print(res.read())
#Request对象 data method 参数的使用
print("************************************")
test_url="http://httpbin.org/put"
req=request.Request(test_url,headers=headers,data=b"updatedata",method="PUT")
res=request.urlopen(req)
print(res.read())
response对象
urlib 库中的类或或者方法,在发送网络请求后,都会返回一个urllib.response的对象。它包含了请求回来的数据结果。它包含了一些属性和方法,供我们处理返回的结果。
read()获取响应返回的数据,只能用一次readline()读取一行info()获取响应头信息geturl()获取访问的urlgetcode()返回状态码
1.1.2、添加请求头
from urllib import request
test_url="http://httpbin.org/get"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"}
req=request.Request(test_url,headers=headers)
res=request.urlopen(req)
print(res.read())
1.1.3、操作cookie
from urllib import request
from http import cookiejar
#创建一个cookie对象
cookie=cookiejar.CookieJar()
#创建一个cookie处理器
cookies=request.HTTPCookieProcessor(cookie)
#以它为参数创建Openner对象
opener=request.build_opener(cookies)
#使用这个openner来发送请求
res=opener.open("http://www.baidu.com")
1.1.4、设置代理
from urllib import request
url='http://httpbin.org/ip'
#代理地址
proxy={'http':'180.76.111.69:3128'}
#代理处理器
proxies=request.ProxyHandler(proxy)
#创建openner对象
opener=request.build_opener(proxies)
res=opener.open(url)
print(res.read().decode())
1.2、urllib.parse模块
parse模块是一个工具模块,提供了需要对url处理的方法,用于解析url,url中只能包含ascii字符,在实际操作过程中,get请求通过url传递的参数中会有大量的特殊字符,例如汉字,那么就需要进行url编码。
1.2.1、单个参数转码
parse.quote()汉字转ascII码
from urllib import parse
name="动画片"
asc_name=parse.quote(name)# 汉字转ascII码
print(asc_name) #结果:%E5%8A%A8%E7%94%BB%E7%89%87
parse.unquote()ascll转中文
from urllib import parse
name = '%E5%8A%A8%E7%94%BB%E7%89%87'
print(parse.unquote(name)) #结果:动画片
1.2.2、多个参数转码
在发送请求的时候,往往会需要传递很多的参数,如果用字符串方法去拼接会比较麻烦,parse.urlencode()方法可以将字典转换为url的请求参数并完成拼接。也可以通过parse.parse_qs()方法将它转回字典。
parse.urlencode()parse.parse_qs()
示例:
from urllib import parse,request
#parse.urlencode()方法将字典转换为url的请求参数
params={"name":"电影","name2":"电视剧","name3":"动画片"}
asc_name=parse.urlencode(params)# 将要字典形式 转成url请求参数形式
print(asc_name)#name=%E7%94%B5%E5%BD%B1&name2=%E7%94%B5%E8%A7%86%E5%89%A7&name3=%E5%8A%A8%E7%94%BB%E7%89%87
test_url="http://httpbin.org/get?{}".format(asc_name)
print(test_url)
res=request.urlopen(test_url)
print(res.read())
#parse_qs 转换回原来的形式
new_params=parse.parse_qs(asc_name)
print(new_params)#{'name': ['电影'], 'name2': ['电视剧'], 'name3': ['动画片']}
1.3、urllib.error模块
1.3.1、URLError与HTTPError
error模块主要负责处理异常,如果请求出现错误,我们可以用error模块进行处理主要包含URLError和HTTPError。
URLError:是error异常模块的基类,由request模块产生的异常都可以用这个类来处理。HTTPError:是URLError的子类,主要包含三个属性:- Code:请求的状态码
- reason:错误的原因
- headers:响应的报头
示例:
from urllib import error,request
try:
res=request.urlopen("https://jianshu.com")
print(res.read())
except error.HTTPError as e:
print('请求的状态码:',e.code)
print('错误的原因:',e.reason)
print('响应的报头:',e.headers)
------------结果-----------------
请求的状态码: 403
错误的原因: Forbidden
响应的报头: Server: Tengine
Date: Mon, 12 Jul 2021 04:40:02 GMT
Content-Type: text/html
Content-Length: 584
Connection: close
Vary: Accept-Encoding
Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
1.4、urllib.robotparse模块
robotparse模块主要负责处理爬虫协议文件,robots.txt 的解析。(君子协定)爬虫一般不会去遵守,所以基本不会使用这个模块;
查看robots协议: 在网址之后添加robots.txt即可。
例如:百度的robots协议(http://www.baidu.com/robots.txt)
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器,比如Windows系统自带的Notepad,就可以创建和编辑它 。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
二、urllib3库
2.1、特点
Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库里所没有的重要特性:
1、 线程安全;2、 连接池;3、 客户端SSL/TLS验证;4、 文件分部编码上传;5、 协助处理重复请求和HTTP重定位;6、 支持压缩编码;7、 支持HTTP和SOCKS代理;8、 100%测试覆盖率。
2.2、安装
通过pip命令来安装:
pip install urllib3
2.3、urllib3的使用
2.3.1、发起请求基本步骤
1、导入 urllib3库
import utllib3
2、实例化一个PoolManager对象,这个对象处理了连接池与线程安全的所有细节
http=urllib3.PoolManager()
3、用request方法发送一个请求
res=http.request("GET","http://www.baidu.com")
2.3.2、request方法
request(self, method, url, fields=None, headers=None,**urlopen_kw)
功能:发送完整的网络请求
参数:
① method:请求方法 GET ,POST,PUT,DELETE…
② url:字符串格式
③ fields:字典类型 GET请求时转化为url参数 POST请求时会转化成form表单数据
④ headers:字典类型
返回值:response对象
示例:
import urllib3
http = urllib3.PoolManager()
url = 'http://httpbin.org/get'
headers = {'header1':'python','header2':'java'}
fields = {'name':'you','passwd':'12345'}
res = http.request('GET',url,fields=fields,headers=headers)
print('状态码:',res.status)
print('响应头:',res.headers)
print('data:',res.data)
2.3.3、Proxies
可以利用ProxyManager进行http代理操作
import urllib3
proxy=urllib3.ProxyManager('http://180.76.111.69:31281')
res=proxy.request('get','http://httpbin.org/ip')
print(res.data)
2.3.4、Request data
- get,head,delete请求,可以通过提供字典类型的参数fields来添加查询参数
import urllib3
http=urllib3.PoolManager()
r=http.request('get','http://httpbin.org/get',fields={'mydata':'python'})
print(r.data.decode())
- 对于post和put请求,需要通过url编码将参数编码成正确格式然后拼接到url中
import urllib3
from urllib import parse
http=urllib3.PoolManager()
data = parse.urlencode({'myname':'pipi'})
url = 'http://httpbin.org/post?'+data
r=http.request('post',url)
print(r.data.decode())
- JSON
在发起请求时,可以通过定义body 参数并定义headers的Content-Type参数来发送一个已经过编译的JSON数据
import urllib3
import json
http=urllib3. PoolManager()
data={'username':'python'}
encoded_data=json.dumps(data).encode('utf-8')
r=http.request('post',
'http://httpbin.org/post',
body=encoded_data,
headers={'Content-Type1':'appLication/json'})
print(json.loads(r.data.decode('utf-8'))['json'])
- Files
对于文件上传,我们可以模仿浏览器表单的方式
import json
import urllib3
http=urllib3.PoolManager()
with open('example.txt') as fp:
file_data=fp.read()
r=http.request('POST',
'http://httpbin. org/post',
fields={'filefield':('example.txt', file_data)}
)
print(json.loads(r.data.decode('utf-8'))['files'])
- binary data
对于二进制的数据上传,我们用指定body的方式,并设置Content-Type的请求头
import urllib3
import json
http=urllib3. PoolManager()
with open('example.jpg','rb') as fb:
binary_data=fb.read()
r=http.request('post',
'http://httpbin.org/post',
body=binary_data,
headers={'Content-Type':'image/jpeg'}
)
print(json.loads(r.data.decode('utf-8')))
2.3.4、response对象
- http响应对象提供status, data,和header等属性
import urllib3
http=urllib3.PoolManager()
r=http.request('GET','http://httpbin.org/ip')
print(r.status)
print(r.data)
print(r.headers)
-
JSON content
返回的json格式数据可以通过json模块,loads为字典数据类型 -
Binary content
响应返回的数据都是字节类型,对于大量的数据我们通过stream来处理更好
import urllib3
http=urllib3.PoolManager()
r=http.request('GET','http://httpbin.org/bytes/10241', preload_content=False)
for chunk in r.stream(32):
print(chunk)
也可以当做一个文件对象来处理
import urllib3
http=urllib3.PoolManager()
r=http.request('GET','http://httpbin.org/bytes/10241', preload_content=False)
for line in r:
print(line)
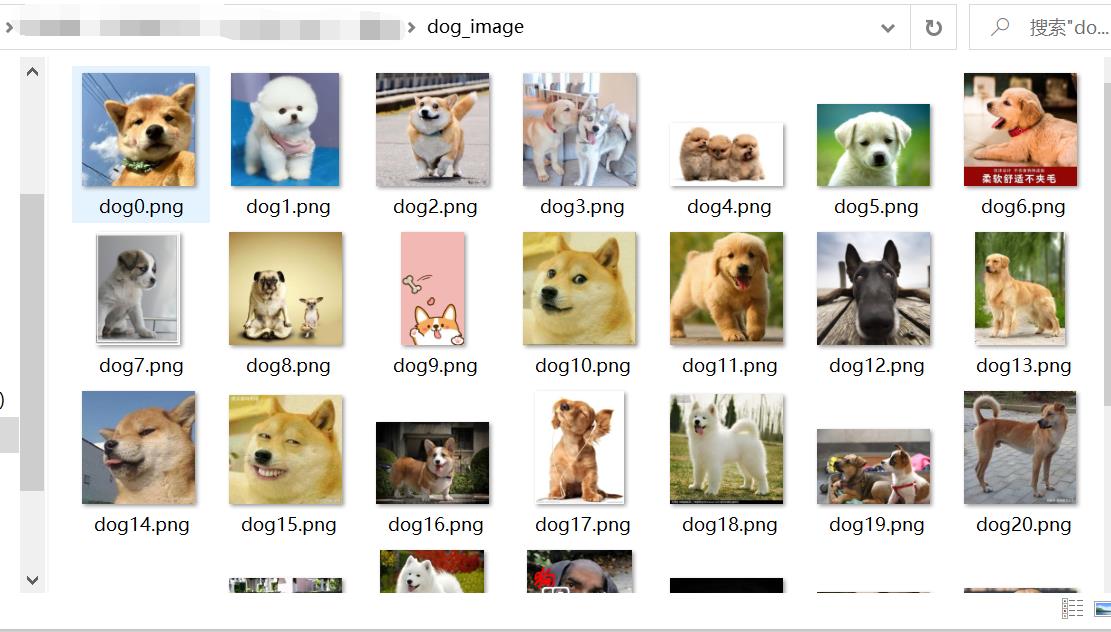
三、小案例:下载百度图片首页图片
(如果有想爬取多页百度图片的话,可以看我博客:使用 requests 爬取百度图片,里面有详细的过程)
3.1、使用urllib下载
from urllib import request
import gzip
from io import BytesIO
import re
import os
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111110&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E7%8B%97&oq=%E7%8B%97&rsp=-1'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'BDqhfp=%E7%8B%97%26%260-10-1undefined%26%260%26%261; BIDUPSID=4B61D634D704A324E3C7E274BF11F280; PSTM=1624157516; BAIDUID=4B61D634D704A324C7EA5BA47BA5886E:FG=1; __yjs_duid=1_f7116f04cddf75093b9236654a2d70931624173362209; indexPageSugList=%5B%22%E7%8B%97%22%2C%22%E7%8C%AB%E5%92%AA%22%2C%22%E5%B0%8F%E9%80%8F%E6%98%8E%22%5D; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID_BFESS=5DD3805F1A4CC3C9562CEAC3C22A1408:FG=1; __yjs_st=2_YTMzN2ZlYWQwNjg5NTFlNGY4NTMxMDBhOTc0ZDQxZjYwZWI0NzBiNjU1N2UyOGRiY2MzNWQ4OTM2YjU4MGU4MmNjYTNiZTk4ZDFkMWE1YmU2ODZhNGMwYzQ3OGE1YjcxZjNmZTEzYWY2ZjNiNGYxNjc0NWNlYjY5YmRhMTI3MmI2N2ZjOTkyYWUwYTZlZDUyMzY3NTc3YmU0MWUwNGM3MDk5NWE1ZTRhNzE4NjQwYWJlMjE3OTg5YzdkYjc0NmE4MjBhMjA2MDBkZmIwNDhjMjYzZjYxMTcyOGM2OTZmYjRlOGUwNTc1N2ZhYWI5YzEwZTVkODg0ZjI4OWM2ZjcyZF83XzM0OWQ2ZTJh; H_PS_PSSID=34268_34099_33969_34222_31660_34226_33848_34113_34073_34107_26350_22159; delPer=0; PSINO=6; BA_HECTOR=al21a125ag2l25851j1genv370q; BDRCVFR[X_XKQks0S63]=mk3SLVN4HKm; firstShowTip=1; cleanHistoryStatus=0; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; userFrom=null; ab_sr=1.0.1_NzczYjg1NGJiOWUwOGQwM2E4YTE0MDJkM2E0YjQ4M2E1ZDk0YWQ1MGUyMmNjZTg4NzhjZDNkZDI0YjcwMjU5N2MxYmQxNWIwZmRjMWEwZjVkNmZkYzkwYTNiYTE3NDUwYWFkZDkyZWM3Njg3ZjQ0OGQ5ZWU3YTkxNDk1M2FiZTAxZTY5NmY3ZjA1NDgxODE3ZWE4MWQxOWUwMmIwYmUxZA==',
'Host': 'image.baidu.com',
'Referer': 'https://image.baidu.com/',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
req = request.Request(url,headers=headers)
res = request.urlopen(req)
# 做gzip的解压 因为请求头里有:'Accept-Encoding': 'gzip, deflate, br',
#否则会出现:UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0x8b in position 1: invalid start byte
buff = BytesIO(res.read())
f = gzip.GzipFile(fileobj=buff)
html= f.read().decode('utf-8')
img_urls = re.findall('"thumbURL":"(.*?)"',html)
for index,img_url in enumerate(img_urls):
rq = request.Request(img_url)
rs = request.urlopen(rq)
if not os.path.exists('dog_image'): #判断文件夹是否存在 不存在则创建
img_file = os.mkdir("dog_image") #创建文件夹
img_path = 'dog_image/'+'dog'+ str(index) +'.png'
with open(img_path,'wb') as f:
print(img_path)
f.write(rs.read())
结果:
3.2、使用urllib3下载
import re
import os
import urllib3
#实例化一个PoolManager对象
http = urllib3.PoolManager()
#目标url
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111110&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E7%8B%97&oq=%E7%8B%97&rsp=-1'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'BDqhfp=%E7%8B%97%26%260-10-1undefined%26%260%26%261; BIDUPSID=4B61D634D704A324E3C7E274BF11F280; PSTM=1624157516; BAIDUID=4B61D634D704A324C7EA5BA47BA5886E:FG=1; __yjs_duid=1_f7116f04cddf75093b9236654a2d70931624173362209; indexPageSugList=%5B%22%E7%8B%97%22%2C%22%E7%8C%AB%E5%92%AA%22%2C%22%E5%B0%8F%E9%80%8F%E6%98%8E%22%5D; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID_BFESS=5DD3805F1A4CC3C9562CEAC3C22A1408:FG=1; __yjs_st=2_YTMzN2ZlYWQwNjg5NTFlNGY4NTMxMDBhOTc0ZDQxZjYwZWI0NzBiNjU1N2UyOGRiY2MzNWQ4OTM2YjU4MGU4MmNjYTNiZTk4ZDFkMWE1YmU2ODZhNGMwYzQ3OGE1YjcxZjNmZTEzYWY2ZjNiNGYxNjc0NWNlYjY5YmRhMTI3MmI2N2ZjOTkyYWUwYTZlZDUyMzY3NTc3YmU0MWUwNGM3MDk5NWE1ZTRhNzE4NjQwYWJlMjE3OTg5YzdkYjc0NmE4MjBhMjA2MDBkZmIwNDhjMjYzZjYxMTcyOGM2OTZmYjRlOGUwNTc1N2ZhYWI5YzEwZTVkODg0ZjI4OWM2ZjcyZF83XzM0OWQ2ZTJh; H_PS_PSSID=34268_34099_33969_34222_31660_34226_33848_34113_34073_34107_26350_22159; delPer=0; PSINO=6; BA_HECTOR=al21a125ag2l25851j1genv370q; BDRCVFR[X_XKQks0S63]=mk3SLVN4HKm; firstShowTip=1; cleanHistoryStatus=0; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; userFrom=null; ab_sr=1.0.1_NzczYjg1NGJiOWUwOGQwM2E4YTE0MDJkM2E0YjQ4M2E1ZDk0YWQ1MGUyMmNjZTg4NzhjZDNkZDI0YjcwMjU5N2MxYmQxNWIwZmRjMWEwZjVkNmZkYzkwYTNiYTE3NDUwYWFkZDkyZWM3Njg3ZjQ0OGQ5ZWU3YTkxNDk1M2FiZTAxZTY5NmY3ZjA1NDgxODE3ZWE4MWQxOWUwMmIwYmUxZA==',
'Host': 'image.baidu.com',
'Referer': 'https://image.baidu.com/',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Moz以上是关于小爬虫学习—— urllib 与 urllib3的主要内容,如果未能解决你的问题,请参考以下文章