机器学习-计算机视觉和卷积网络CNN
Posted tangxiaobo199181
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-计算机视觉和卷积网络CNN相关的知识,希望对你有一定的参考价值。
- 概述
对于计算机视觉的应用现在是非常广泛的,但是它背后的原理其实非常简单,就是将每一个像素的值pixel输入到一个DNN中,然后让这个神经网络去学习这个模型,最后去应用这个模型就可以了。听起来是不是很简单,其实如果大家深入研究的话,这里面还是有很多内容去学习的,例如:咱们的图片大小可能不一样,同一张图片不同的旋转角度可到的结果可能不一样,如何给咱们的本地图片来label(实际中并不是所有的数据都想mnist那样,谷歌都给咱们label好了,拿来用就行),等等这些问题咱们在实际中肯定都是要用到的。这一节首先会先介绍一下如何直接将图片的塞进网络训练;第二部分会介绍一下卷积网络的结构原理和应用(用谷歌自己提供的mnist数据集);第三部分我会介绍一下如何用卷及网络CNN来训练咱们自己的图片数据。其中的核心重点是咱们的第二部分。
- 传统DNN之图片识别
传统的DNN肯定大家都是知道的,就是通过构建Sequential layers, 然后将咱们的图片的pixel值作为数据传递给这个DNN的input layer, 只有这个input layer后面的dense layers是根据用户自己的需求进行创建架构的。那么通过什么流程来训练呢?首先第一步咱们得加载数据,如下所示
mnist = tf.keras.datasets.fashion_mnist (training_images, training_labels), (test_images, test_labels) = mnist.load_data() training_images=training_images/255.0 test_images=test_images/255.0
上面的数据是咱们TensorFlow自带的,它都帮助咱们这里好了,也帮助咱们把图片的labels都设定好了,帮助咱们省了很多的功夫,但是很遗憾,这些数据只能在学习的时候用,在实际的工业环境中,咱们是不可能这么幸运的,嘿嘿。那么咱们这里就先用这个demo 数据来学习吧。接下来第二步,咱们来构建咱们的DNN,咱们接着往下看
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
这里跟咱们前面说的普通DNN稍微有点不同,那就是咱们在dense layers之前加了一个tf.keras.layers.Flatten()函数,因为咱们的图片不像咱们之前dataframe数据那样每一行数据都是将features排列好的,每一张图片都是一个二维(或者三维)的pixel值,这些pixel就是咱们这个model的features,所以咱们必须得将这个图片的像素全部转化成一列数据,而咱们的Flatten()函数就是做这个工作的。在这个classification的场景中,咱们一共有的classes是10个,所以咱们最后的output layer的units的数量是10个,这个数量必须要匹配,否则会有error。第三部就是configure这个模型,如下
model.compile(optimizer=‘adam‘, loss=‘sparse_categorical_crossentropy‘)
当然啦,在这里咱们可以加一个callbacks,当咱们的loss小于0.4的时候,咱们就停止咱们模型的训练
class myCallback(tf.keras.callbacks.Callback): def on_epoch_end(self, epoch, logs={}): if(logs.get(‘loss‘)<0.4): print(logs) print(" Reached 0.4 loss so cancelling training!") self.model.stop_training = True callbacks = myCallback()
最后当然就是咱们的训练的过程啦,
model.fit(training_images, training_labels, epochs=5, callbacks=[callbacks])
至于后面的predict和evaluate的过程,更前面章节讲的都是一模一样的,这里就不在展示啦。上面展示的是一个用传统的DNN来训练label好了的图片来创建一个神经网络,可惜的是在实际中我们几乎不会用这种方式来做图片的classification,因为在实际中每一个图片的大小都是不一样的,所以每一个input layer都是不一样,很显然这不符合咱们的实际情况;另外实际中图片不可能都是给你label好了,并且放在dataset里面,这些都需要咱们额外去做的工作,那么咱们这里就要来看看咱们如何来解决这些问题。
- 计算机视觉之图片数据准备
咱们都知道在实际中,咱们没有准备好的mnist dataset,所有的图片都需要咱们自己去label,那么如何给不同的本地图片分配不同的labels, 并且最后怎么组织这是图片和label数据来训练呢?这里咱们就要用到一个TensorFlow里面专门用于处理图片的一个库了,那就是ImageDataGenerator,它会给咱们的图片根据文件夹的名称来label,并且将这些图片和labels组织起来变成一个类似于dataset的数据集,我们称之于generator,咱们在这里就将它看成一个类似于dataset的数据集就行了,并且可以直接传递给model.fit()来训练,就跟dataset一样。那咱们就来看一下这个具体的流程吧,咱们这里就以一个本地的压缩文件为例来展示一下,如何将一个本地的图片来label并且生成一个generator。
第一步:解压文件夹
import os import zipfile local_zip = "C:Users angxOneDriveDesktopDATAcats_and_dogs_filtered.zip" zip_ref = zipfile.ZipFile(local_zip,‘r‘) zip_ref.extractall("C:Users angxOneDriveDesktopDATA")#where we extract our zip file to zip_ref.close
上面将一个压缩的文件夹cats_and_dogs_filtered.zip解压到C:Users angxOneDriveDesktopDATA这个文件夹中,并且解压后的文件名就是cats_and_dogs_filtered。
第二步:define all subdirectories
base_dir = "C:Users angxOneDriveDesktopDATAcats_and_dogs_filtered"
train_dir = os.path.join(base_dir, "train") val_dir = os.path.join(base_dir,"validation") train_cats_dir = os.path.join(train_dir,"cats") train_dogs_dir = os.path.join(train_dir,"dogs") val_cats_dir = os.path.join(val_dir,"cats") val_dogs_dir = os.path.join(val_dir,"dogs")
这一步咱们定义了咱们所有图片的子文件夹,这些子文件夹中装着的正是咱们的图片。
第三步:生成ImageDataGenerator
from tensorflow.keras.preprocessing.image import ImageDataGenerator #rescale train_imagegen = ImageDataGenerator(rescale=1/255.0) val_imagegen = ImageDataGenerator(rescale=1/255.0) #flow image data """ train_dir: which directory our image data are embeded in batch_size:the number of images our image generator yields each time target_size: our oringial images are various shape, so here we set all the image to a fixed size, wich is (150,150) """ #the labels will be based on the directories‘s name, wwhich is sorted alphanumeric; for example: cats:0; dogs:1 train_imagegen = train_imagegen.flow_from_directory(train_dir,batch_size=20,class_mode="binary",target_size=(150,150)) val_imagegen = val_imagegen.flow_from_directory(val_dir,batch_size=20,class_mode="binary",target_size=(150,150))
这里首先咱们实例化一个ImageDatagenerator并且对咱们后面要导入的照片进行一个rescale, 然后通过这个generator调用它的对象方法flow_from_directory()来给咱们的图片label并且生成咱们的最终的数据对generator。这里有几个参数需要了解一下,一个batch_size是指到时候在训练数据的时候每一个gradient选择多少个数据来计算, class_mode是指你的classification是什么类型,这里有这几种可能是 “binary”,“sparse”, "categorical", "input"和None这几种情况,根据咱们的实际情况来选择。还有一个很重要的参数,那就是target_size, 这个参数能把咱们的图片全部转化成相同的大小,这给咱们后面创建神经网络的时候带来了极大的方便,在创建神经网络的时候咱们可以固定咱们input layer中node的数量了。还有一个很小的细节容易忽视,那就是imagegenerator给咱们图片label的时候是根据装咱们图片的文件夹的名称的字母顺序来得,例如cats,label是0;dogs, label是1。至此,咱们已经完成了所有的图片的准备工作的了,包括图片的label,图片的大小统一等工作。下面咱们就要来说说咱们在计算机视觉中应用的最广泛的一种网络结构了,那就是卷积网络CNN。
- 卷积网络CNN
对于Convolutional Neuro Network (CNN), 咱们第一步得了解他的结构是什么样的,然后才能理解它的一些概念,例如:filter, pooling等概念。那么下面我自己花了一张简易的CNN的网络结构图,如果大家理解了下面的这个网络结构,那么大家肯定也就立即了CNN的一下概念,咱们直接看下面的图片
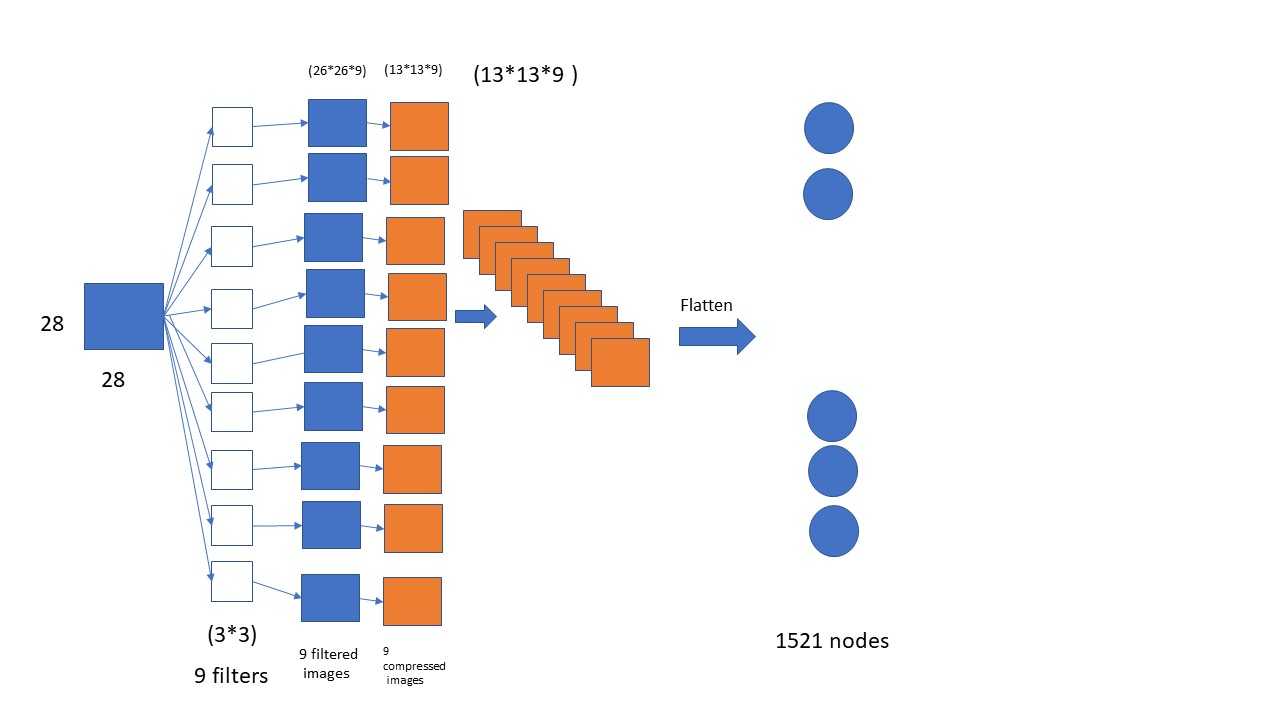
上面的图片展示的就是一个含有一个convolution layer, 一个pooling layer的一个卷积网络。首先咱们的原始图片是一张28*28像素的图片,之后咱们让TensorFlow随机生成9个filter,每一个filter都是一个3*3结构的filter,这里就是咱们整个CNN的核心了。然后让每一个filter都去cover一下咱们的原始图片都会生成一个26*26的图片,所以咱们一共生成了9个26*26的图片;注意实际上这里每一个filter都是根据不同的角度来提取咱们原始图片的特征,这就是这些filter的本质。之后所有的这些经过过滤后的26*26size 的图片再经过一个Maxpooling(2*2)层来压缩咱们的26*26的图片,结果就是生成了9个13*13的图片。为了将这个数据加载在咱们后面的DNN中进行计算,很显然咱们还是得将这9个13*13的图片经过flatten操作后才能将它作为咱们的input layer。后面的步骤就跟咱们传统的DNN是一模一样的了。那么这里的核心就是filter的过程,它是用来提取不同角度的图片的特征的。如果上面的CNN的结构理解了,那么我们就接着上面的imagegenerator的例子,看看如何用TensorFlow来应用CNN吧。首先搭建CNN结构
model = tf.keras.Sequential([ # Note the input shape is the desired size of the image 150x150 with 3 bytes color tf.keras.layers.Conv2D(32, (3,3), activation=‘relu‘, input_shape=(150, 150, 3)), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(16, (3,3), activation=‘relu‘), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(64, (3,3), activation=‘relu‘), tf.keras.layers.MaxPooling2D(2,2), # Flatten the results to feed into a DNN tf.keras.layers.Flatten(), tf.keras.layers.Dense(1024, activation=‘relu‘), tf.keras.layers.Dense(128, activation=‘relu‘), # Only 1 output neuron. It will contain a value from 0-1 where 0 for 1 class (‘cats‘) and 1 for the other (‘dogs‘) tf.keras.layers.Dense(1, activation=‘sigmoid‘) ]) model.compile( optimizer = tf.optimizers.Adam(0.0001), loss = "binary_crossentropy", metrics = ["acc"] )
首先咱们看出这个网络结构中,咱们构建了3个convolutional layers, 第一个卷积层的filter数量四32,第二个卷积层的filter数量是16,第三个卷积层数量是64。并且在第一个卷积层咱们声明了咱们每一个图片的size和dimension,例如咱们的图片是彩色的图片,长宽都是150,然后彩色图片有3个channel,所以咱们的input_shape=(150, 150, 3)。接下来就是咱们的training的过程了。
model.fit(train_imagegen, epochs=15, validation_data=val_imagegen, shuffle=True)
这里的fit函数咱们可以看出来,咱们就是直接传递的generator当做数据传递给它当做咱们的数据源了。至于后面的predict,evaluate等方式,跟前面章节讲的DNN的过程完全一样,这里我就不在赘述了。好了这就是CNN在计算机视觉中的应用。
以上是关于机器学习-计算机视觉和卷积网络CNN的主要内容,如果未能解决你的问题,请参考以下文章
毕业设计 题目:基于深度学习的动物识别 - 卷积神经网络 机器视觉 图像识别
深度学习多变量时间序列预测:卷积神经网络(CNN)算法构建时间序列多变量模型预测交通流量+代码实战