卷积神经网络CNN在图像识别问题应用综述(20191219)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积神经网络CNN在图像识别问题应用综述(20191219)相关的知识,希望对你有一定的参考价值。
参考技术A 这两天在公司做PM实习,主要是自学一些CV的知识,以了解产品在解决一些在图像识别、图像搜索方面的问题,学习的主要方式是在知网检索了6.7篇国内近3年计算机视觉和物体识别的硕博士论文。由于时间关系,后面还会继续更新图片相似度计算(以图搜图)等方面的学习成果
将这两天的学习成果在这里总结一下。你将会看到计算机视觉在解决特定物体识别问题(主要是卷积神经网络CNNs)的基础过程和原理,但这里不会深入到技术的实现层面。
计算机视觉(Computer vision)是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图像处理,用计算机处理成为更适合人眼观察或传送给仪器检测的图像。
————维基百科
通常而言,计算机视觉的研究包括三个层次:
(1)底层特征的研究:
这一层次的研究主要聚焦如何高效提取出图像对象具有判别性能的特征,具体的研究内容通常包括:物体识别、字符识别等
(2)中层语义特征的研究:
该层次的研究在于在识别出对象的基础上,对其位置、边缘等信息能够准确区分。现在比较热门的:图像分割;语义分割;场景标注等,都属于该领域的范畴
(3)高层语义理解:
这一层次建立在前两层的基础上,其核心在于“理解”一词。 目标在于对复杂图像中的各个对象完成语义级别的理解。这一层次的研究常常应用于:场景识别、图像摘要生成及图像语义回答等。
而我研究的问题主要隶属于底层特征和中层语义特征研究中的物体识别和场景标注问题。
人类的视觉工作模式是这样的:
首先,我们大脑中的神经元接收到大量的信息微粒,但我们的大脑还并不能处理它们。
于是接着神经元与神经元之间交互将大量的微粒信息整合成一条又一条的线。
接着,无数条线又整合成一个个轮廓。
最后多个轮廓累加终于聚合我们现在眼前看到的样子。
计算机科学受到神经科学的启发,也采用了类似的工作方式。具体而言,图像识别问题一般都遵循下面几个流程
(1)获取底层信息。获取充分且清洁的高质量数据往往是图像识别工作能否成功的关键所在
(2)数据预处理工作,在图像识别领域主要包括四个方面的技术:去噪处理(提升信噪比)、图像增强和图像修复(主要针对不够清晰或有破损缺失的图像);归一化处理(一方面是为了减少开销、提高算法的性能,另一方面则是为了能成功使用深度学习等算法,这类算法必须使用归一化数据)。
(3)特征提取,这一点是该领域的核心,也是本文的核心。图像识别的基础是能够提取出足够高质量,能体现图像独特性和区分度的特征。
过去在10年代之前我们主要还是更多的使用传统的人工特征提取方法,如PCA\\LCA等来提取一些人工设计的特征,主要的方法有(HOG、LBP以及十分著名的SIFT算法)。但是这些方法普遍存在(a)一般基于图像的一些提层特征信息(如色彩、纹理等)难以表达复杂的图像高层语义,故泛化能力普遍比较弱。(b)这些方法一般都针对特定领域的特定应用设计,泛化能力和迁移的能力大多比较弱。
另外一种思路是使用BP方法,但是毕竟BP方法是一个全连接的神经网络。这以为这我们非常容易发生过拟合问题(每个元素都要负责底层的所有参数),另外也不能根据样本对训练过程进行优化,实在是费时又费力。
因此,一些研究者开始尝试把诸如神经网络、深度学习等方法运用到特征提取的过程中,以十几年前深度学习方法在业界最重要的比赛ImageNet中第一次战胜了SIFT算法为分界线,由于其使用权重共享和特征降采样,充分利用了数据的特征。几乎每次比赛的冠军和主流都被深度学习算法及其各自改进型所占领。其中,目前使用较多又最为主流的是CNN算法,在第四部分主要也研究CNN方法的机理。
上图是一个简易的神经网络,只有一层隐含层,而且是全连接的(如图,上一层的每个节点都要对下一层的每个节点负责。)具体神经元与神经元的作用过程可见下图。
在诸多传统的神经网络中,BP算法可能是性能最好、应用最广泛的算法之一了。其核心思想是:导入训练样本、计算期望值和实际值之间的差值,不断地调整权重,使得误差减少的规定值的范围内。其具体过程如下图:
一般来说,机器学习又分成浅层学习和深度学习。传统的机器学习算法,如SVM、贝叶斯、神经网络等都属于浅层模型,其特点是只有一个隐含层。逻辑简单易懂、但是其存在理论上缺乏深度、训练时间较长、参数很大程度上依赖经验和运气等问题。
如果是有多个隐含层的多层神经网络(一般定义为大于5层),那么我们将把这个模型称为深度学习,其往往也和分层训练配套使用。这也是目前AI最火的领域之一了。如果是浅层模型的问题在于对一个复杂函数的表示能力不够,特别是在复杂问题分类情况上容易出现分类不足的弊端,深度网络的优势则在于其多层的架构可以分层表示逻辑,这样就可以用简单的方法表示出复杂的问题,一个简单的例子是:
如果我们想计算sin(cos(log(exp(x)))),
那么深度学习则可分层表示为exp(x)—>log(x)—>cos(x)—>sin(x)
图像识别问题是物体识别的一个子问题,其鲁棒性往往是解决该类问题一个非常重要的指标,该指标是指分类结果对于传入数据中的一些转化和扭曲具有保持不变的特性。这些转化和扭曲具体主要包括了:
(1)噪音(2)尺度变化(3)旋转(4)光线变化(5)位移
该部分具体的内容,想要快速理解原理的话推荐看[知乎相关文章] ( https://www.zhihu.com/search?type=content&q=CNN ),
特别是其中有些高赞回答中都有很多动图和动画,非常有助于理解。
但核心而言,CNN的核心优势在于 共享权重 以及 感受野 ,减少了网络的参数,实现了更快的训练速度和同样预测结果下更少的训练样本,而且相对于人工方法,一般使用深度学习实现的CNN算法使用无监督学习,其也不需要手工提取特征。
CNN算法的过程给我的感觉,个人很像一个“擦玻璃”的过程。其技术主要包括了三个特性:局部感知、权重共享和池化。
CNN中的神经元主要分成了两种:
(a)用于特征提取的S元,它们一起组成了卷积层,用于对于图片中的每一个特征首先局部感知。其又包含很关键的阈值参数(控制输出对输入的反映敏感度)和感受野参数(决定了从输入层中提取多大的空间进行输入,可以简单理解为擦玻璃的抹布有多大)
(b)抗形变的C元,它们一起组成了池化层,也被称为欠采样或下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性。
(c*)激活函数,及卷积层输出的结果要经过一次激励函数才会映射到池化层中,主要的激活函数有Sigmoid函数、Tanh函数、ReLU、Leaky ReLU、ELU、Maxout等。
也许你会抱有疑问,CNN算法和传统的BP算法等究竟有什么区别呢。这就会引出区域感受野的概念。在前面我们提到,一个全连接中,较高一层的每个神经元要对低层的每一个神经元负责,从而导致了过拟合和维度灾难的问题。但是有了区域感受野和,每个神经元只需要记录一个小区域,而高层会把这些信息综合起来,从而解决了全连接的问题。
了解区域感受野后,你也许会想,区域感受野的底层神经元具体是怎么聚合信息映射到上一层的神经元呢,这就要提到重要的卷积核的概念。这个过程非常像上面曾提到的“神经元与神经元的联系”一图,下面给大家一个很直观的理解。
上面的这个过程就被称为一个卷积核。在实际应用中,单特征不足以被系统学习分类,因此我们往往会使用多个滤波器,每个滤波器对应1个卷积核,也对应了一个不同的特征。比如:我们现在有一个人脸识别应用,我们使用一个卷积核提取出眼睛的特征,然后使用另一个卷积核提取出鼻子的特征,再用一个卷积核提取出嘴巴的特征,最后高层把这些信息聚合起来,就形成了分辨一个人与另一个人不同的判断特征。
现在我们已经有了区域感受野,也已经了解了卷积核的概念。但你会发现在实际应用中还是有问题:
给一个100 100的参数空间,假设我们的感受野大小是10 10,那么一共有squar(1000-10+1)个,即10的六次方个感受野。每个感受野中就有100个参数特征,及时每个感受野只对应一个卷积核,那么空间内也会有10的八次方个次数,,更何况我们常常使用很多个卷积核。巨大的参数要求我们还需要进一步减少权重参数,这就引出了权重共享的概念。
用一句话概括就是,对同一个特征图,每个感受野的卷积核是一样的,如这样操作后上例只需要100个参数。
池化是CNN技术的最后一个特性,其基本思想是: 一块区域有用的图像特征,在另一块相似的区域中很可能仍然有用。即我们通过卷积得到了大量的边缘EDGE数据,但往往相邻的边缘具有相似的特性,就好像我们已经得到了一个强边缘,再拥有大量相似的次边缘特征其实是没有太大增量价值的,因为这样会使得系统里充斥大量冗余信息消耗计算资源。 具体而言,池化层把语义上相似的特征合并起来,通过池化操作减少卷积层输出的特征向量,减少了参数,缓解了过拟合问题。常见的池化操作主要包括3种:
分别是最大值池化(保留了图像的纹理特征)、均值池化(保留了图像的整体特征)和随机值池化。该技术的弊端是容易过快减小数据尺寸,目前趋势是用其他方法代替池化的作用,比如胶囊网络推荐采用动态路由来代替传统池化方法,原因是池化会带来一定程度上表征的位移不变性,传统观点认为这是一个优势,但是胶囊网络的作者Hinton et al.认为图像中位置信息是应该保留的有价值信息,利用特别的聚类评分算法和动态路由的方式可以学习到更高级且灵活的表征,有望冲破目前卷积网络构架的瓶颈。
CNN总体来说是一种结构,其包含了多种网络模型结构,数目繁多的的网络模型结构决定了数据拟合能力和泛化能力的差异。其中的复杂性对用户的技术能力有较高的要求。此外,CNN仍然没有很好的解决过拟合问题和计算速度较慢的问题。
该部分的核心参考文献:
《深度学习在图像识别中的应用研究综述》郑远攀,李广阳,李晔.[J].计算机工程与应用,2019,55(12):20-36.
深度学习技术在计算机图像识别方面的领域应用研究是目前以及可预见的未来的主流趋势,在这里首先对深度学习的基本概念作一简介,其次对深度学习常用的结构模型进行概述说明,主要简述了深度信念网络(DBN)、卷积神经网络(CNN)、循环神经网络(RNN)、生成式对抗网络(GAN)、胶囊网络(CapsNet)以及对各个深度模型的改进模型做一对比分析。
深度学习按照学习架构可分为生成架构、判别架构及混合架构。
其生成架构模型主要包括:
受限波尔兹曼机、自编码器、深层信念网络等。判别架构模型主要包括:深层前馈网络、卷积神经网络等。混合架构模型则是这两种架构的集合。深度学习按数据是否具有标签可分为非监督学习与监督学习。非监督学习方法主要包括:受限玻尔兹曼机、自动编码器、深层信念网络、深层玻尔兹曼机等。
监督学习方法主要包括:深层感知器、深层前馈网络、卷积神经网络、深层堆叠网络、循环神经网络等。大量实验研究表明,监督学习与非监督学习之间无明确的界限,如:深度信念网络在训练过程中既用到监督学习方法又涉及非监督学习方法。
[1]周彬. 多视图视觉检测关键技术及其应用研究[D].浙江大学,2019.
[2]郑远攀,李广阳,李晔.深度学习在图像识别中的应用研究综述[J].计算机工程与应用,2019,55(12):20-36.
[3]逄淑超. 深度学习在计算机视觉领域的若干关键技术研究[D].吉林大学,2017.
[4]段萌. 基于卷积神经网络的图像识别方法研究[D].郑州大学,2017.
[5]李彦冬. 基于卷积神经网络的计算机视觉关键技术研究[D].电子科技大学,2017.
[6]李卫. 深度学习在图像识别中的研究及应用[D].武汉理工大学,2014.
[7]许可. 卷积神经网络在图像识别上的应用的研究[D].浙江大学,2012.
[8]CSDN、知乎、机器之心、维基百科
图像识别基于卷积神经网络CNN实现车牌识别matlab源码
过去几年,深度学习(Deep learning)在解决诸如视觉识别(visual recognition)、语音识别(speech recognition)和自然语言处理(natural language processing)等很多问题方面都表现出非常好的性能。在不同类型的深度神经网络当中,卷积神经网络是得到最深入研究的。早期由于缺乏训练数据和计算能力,要在不产生过拟合(overfitting)的情况下训练高性能卷积神经网络是很困难的。标记数据和近来GPU的发展,使得卷积神经网络研究涌现并取得一流结果。本文中,我们将纵览卷积神经网络近来发展,同时介绍卷积神经网络在视觉识别方面的一些应用。
CNN快速发展,得益于LeNet-5、Alexnet、ZFNet、VGGNet、GoogleNet、ResNet等不同结构的设计出现。
1.CNN的基本结构
卷积神经网络的结构有很多种,但是其基本架构是相似的,拿LeNet-5为例来介绍,如下图,它包含三个主要的层——卷积层( convolutional layer)、池化层( pooling layer)、全连接层( fully-connected layer)

图中的卷积网络工作流程如下,输入层由32×32个感知节点组成,接收原始图像。然后,计算流程在卷积和子抽样之间交替进行,如下所述:
第一隐藏层进行卷积,它由6个特征映射组成,每个特征映射由28×28个神经元组成,每个神经元指定一个 5×5 的接受域;
第二隐藏层实现子抽样和局部平均,它同样由 6 个特征映射组成,但其每个特征映射由14×14 个神经元组成。每个神经元具有一个 2×2 的接受域,一个可训练系数,一个可训练偏置和一个 sigmoid 激活函数。可训练系数和偏置控制神经元的操作点。
第三隐藏层进行第二次卷积,它由 16个特征映射组 成,每个特征映射由 10×10 个神经元组成。该隐藏层中的每个神经元可能具有和下一个隐藏层几个特征映射相连的突触连接,它以与第一个卷积 层相似的方式操作。
第四个隐藏层进行第二次子抽样和局部平均计算。它由 16 个特征映射组成,但每个特征映射由 5×5 个神经元组成,它以 与第一次抽样相似的方式操作。
第五个隐藏层实现卷积的最后阶段,它由 120 个神经元组成,每个神经元指定一个 5×5 的接受域。
最后是个全连接层,得到输出向量。
相继的计算层在卷积和抽样之间的连续交替,我们得到一个“双尖塔”的效果,也就是在每个卷积或抽样层,随着空 间分辨率下降,与相应的前一层相比特征映射的数量增加。卷积之后进行子抽样的思想是受到动物视觉系统中的“简单的”细胞后面跟着“复杂的”细胞的想法的启发而产生的。
其中,卷积层,用来学习输入数据的特征表征。卷积层由很多的卷积核(convolutional kernel)组成,卷积核用来计算不同的feature map;
激励函数(activation function)给CNN卷积神经网络引入了非线性,常用的有sigmoid 、tanh、 ReLU函数;
池化层降低卷积层输出的特征向量,同时改善结果(使结构不容易出现过拟合),典型应用有average pooling 和 max pooling;
全连接层将卷积层和Pooling 层堆叠起来以后,就能够形成一层或多层全连接层,这样就能够实现高阶的推力能力
2.CNN卷积神经网络的改进策略
自从2012年AlexNet 取得成功以后,科研工作者提出了很多改进CNN的方法,基本都是从以下六个方面入手:convolutional layer、pooling layer、activation function、loss function、regularization 、optimization
2.1convolutional layer
1). Network in network
It replaces the linear filter of the convolutional layer by a micro network

2). Inception module : 是继承了NIN的扩展. 使用不同size的filter来捕获不同size的visual patterns.
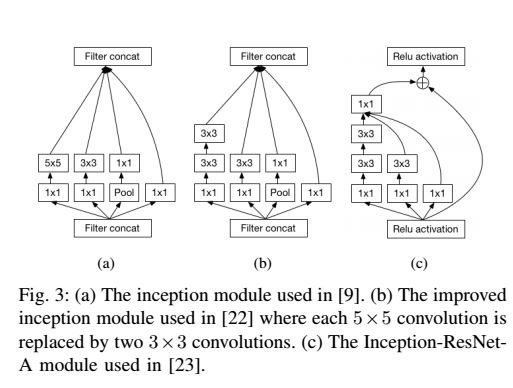
2.2 pooling layer
池化层是CNN的重要组成部分,它通过减少卷积层之间的连接数量来降低计算的复杂度。
1).Lp pooling:Lp 池化是建立在复杂细胞运行机制的基础上,受生物启发而来
2). Mixed pooling:combination of max pooling and average pooling
3).Stochastic pooling:Stochastic pooling 是受 droptout 启发而来的方法
4).Spectral pooling
5). Spatial pyramid pooling
空间金字塔池化可以把任何尺度的图像的卷积特征转化成相同维度,这不仅可以让CNN处理任意尺度的图像,还能避免 cropping和warping操作,导致一些信息的丢失,具有非常重要的意义。
一般的CNN都需要输入图像的大小是固定的,这是因为全连接层的输入需要固定输入维度,但在卷积操作是没有对图像尺度有限制,所有作者提出了空间金字塔池化,先让图像进行卷积操作,然后转化成维度的特征输入到全连接层,这个可以把CNN扩展到任意大小的图像。
2.3activation function
一个合适的激励函数可以有效地提高CNN的运算性能。常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全链接层,后者relu常见于卷积层。
sigmoid函数图像曾在神经网络和深度学习(一)中介绍过,这里再介绍ReLU、LReLU、PReLU、RReLU、ELU几种激励函数的特性曲线

2.4 Loss function
1). Softmax loss :

2). Hinge loss : to train large margin classifiers such as SVM

3). Contrastive loss : to train Siamese network

2.5 Regularization 正则化
通过正则化可以有效的减小CNN的过拟合问题。这里介绍两种正则化技术——Dropout 、 DropConnect

Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已) ; 而DropConnect 是DropOut的进一步发展,不再和DropOut一样随意设置输出神经元的值为0,而是随机设置权重矩阵W 为0。
2.6 Optimization
这里介绍几种优化CNN的关键技术:
1). Weights initialization
2). Stochastic gradient descent
3). Batch Normalization
4). Shortcut connections
3. 加速CNN计算速度
3.1 FFT : 使用快速傅里叶变换,可以重复利用一些单元,比如输出梯度的傅里叶变换
3.2 Matrix Factorization : 矩阵因子分解,可以减小计算量,来加速CNN 的训练
3.3 Vector quantization : 矢量量化(VQ)是用来压缩密集的连接层,使得CNN模型变得更小
4. CNN 的主要应用
使用CNN,可以使得以下几个应用达到最佳的(state-of-the-art)性能:
1). Image Classification
2). Object Tracking
3). Pose Estimation
4). Text Detection
5). Visual Saliency detection
6). Action Recognition
7). Scene Labeling
function varargout = System_Main(varargin)
gui_Singleton = 1;
gui_State = struct('gui_Name', mfilename, ...
'gui_Singleton', gui_Singleton, ...
'gui_OpeningFcn', @System_Main_OpeningFcn, ...
'gui_OutputFcn', @System_Main_OutputFcn, ...
'gui_LayoutFcn', [] , ...
'gui_Callback', []);
if nargin && ischar(varargin{1})
gui_State.gui_Callback = str2func(varargin{1});
end
if nargout
[varargout{1:nargout}] = gui_mainfcn(gui_State, varargin{:});
else
gui_mainfcn(gui_State, varargin{:});
end
function System_Main_OpeningFcn(hObject, eventdata, handles, varargin)
handles.output = hObject;
guidata(hObject, handles);
movegui(hObject,'center');
function varargout = System_Main_OutputFcn(hObject, eventdata, handles)
varargout{1} = handles.output;
%打开图片菜单
function OpenPicture_Callback(hObject, eventdata, handles)
[pathname filename]=uigetfile('.jpg','选择图片');
chepailujing=[pathname filename];
handles.chepailujing=chepailujing;
fpath=[filename pathname];
axes(handles.axes1);
im = imread(fpath);
%im=imresize(im,[240,320])
imshow(im);
title('原图像', 'FontWeight', 'Bold');
handles.IM=im;
guidata(hObject, handles);
fpath;
%保存图片菜单
function SavePicture_Callback(hObject, eventdata, handles)
% --- 车牌定位实现按钮
function CarDiwei_Callback(hObject, eventdata, handles)
[PY2,PY1,PX2,PX1]=caitu_fenge(handles.IM);%分割方法
axes(handles.axes1); hold on;
row = [PY1 PY2];
col = [PX1 PX2];
plot([col(1) col(2)], [row(1) row(1)], 'g-', 'LineWidth', 3);
plot([col(1) col(2)], [row(2) row(2)], 'g-', 'LineWidth', 3);
plot([col(1) col(1)], [row(1) row(2)], 'g-', 'LineWidth', 3);
plot([col(2) col(2)], [row(1) row(2)], 'g-', 'LineWidth', 3);
hold off;
I_bai=handles.IM;
[PY2,PY1,PX2,PX1,threshold]=SEC_xiuzheng(PY2,PY1,PX2,PX1);%选着车牌位置
handles.threshold=threshold;
Plate=I_bai(PY1:PY2,PX1:PX2,:);
bw=Plate;
handles.bw=bw;
guidata(hObject,handles);
axes(handles.axes2);
imshow(bw);
title('车牌图像');
% --- Executes on button press in CarXuanzhuan.
function CarXuanzhuan_Callback(hObject, eventdata, handles)
bw=rgb2gray(handles.bw);
qingxiejiao=rando_bianhuan(bw);
handles.qingxiejiao=qingxiejiao;
bw=imrotate(bw,qingxiejiao,'bilinear','crop');
axes(handles.axes3);
imshow(bw);
title('车牌调整角度图像');
bw=im2bw(bw,graythresh(bw));%figure,imshow(bw);
bw=bwmorph(bw,'hbreak',inf);%figure,imshow(bw);
bw=bwmorph(bw,'spur',inf);%figure,imshow(bw);title('擦除之前');
bw=bwmorph(bw,'open',5);%figure,imshow(bw);title('闭合运算');
handles.bw=bw;
guidata(hObject,handles);
% --- Executes on button press in EditBlue.
function EditBlue_Callback(hObject, eventdata, handles)
bw = bwareaopen(handles.bw, handles.threshold);
bw=~bw;
bw=touying(bw);%Y方向处理
bw=~bw;%擦除反色
bw = bwareaopen(bw, handles.threshold);
bw=~bw;%二次擦除
handles.bw=bw;
guidata(hObject,handles);
axes(handles.axes4);
imshow(bw);
title('擦除多余蓝色');
% --- Executes on button press in EditCar.
function EditCar_Callback(hObject, eventdata, handles)
bw=handles.bw;
[y,x]=size(bw);%对长宽重新赋值
%=================文字分割=================================
fenge=shuzifenge(bw,handles.qingxiejiao)
[m,k]=size(fenge);
%=================显示分割图像结果=========================
figure;
for s=1:2:k-1
subplot(1,k/2,(s+1)/2);imshow(bw( 1:y,fenge(s):fenge(s+1)));
end
function CarShibie_Callback(hObject, eventdata, handles)
bw=handles.bw;
[y,x]=size(bw);
fenge=shuzifenge(bw,handles.qingxiejiao)
[m,k]=size(fenge);
%================ 给七张图片定位===============桂AV6388
han_zi =bw( 1:y,fenge(1):fenge(2));
zi_mu =bw( 1:y,fenge(3):fenge(4));
zm_sz_1 =bw( 1:y,fenge(5):fenge(6));
zm_sz_2 =bw( 1:y,fenge(7):fenge(8));
shuzi_1 =bw( 1:y,fenge(9):fenge(10));
shuzi_2 =bw( 1:y,fenge(11):fenge(12));
shuzi_3 =bw( 1:y,fenge(13):fenge(14));
%==========================识别====================================
%======================把修正数据读入==============================
xiuzhenghanzi = imresize(han_zi, [110 55],'bilinear');
xiuzhengzimu = imresize(zi_mu, [110 55],'bilinear');
xiuzhengzm_sz_1= imresize(zm_sz_1,[110 55],'bilinear');
xiuzhengzm_sz_2 = imresize(zm_sz_2,[110 55],'bilinear');
xiuzhengshuzi_1 = imresize(shuzi_1,[110 55],'bilinear');
xiuzhengshuzi_2 = imresize(shuzi_2,[110 55],'bilinear');
xiuzhengshuzi_3 = imresize(shuzi_3,[110 55],'bilinear');
%============ 把0-9 , A-Z以及省份简称的数据存储方便访问====================
hanzishengfen=duquhanzi(imread('picture/cpgui.bmp'),imread('picture/cpguizhou.bmp'),imread('picture/cpjing.bmp'),imread('picture/cpsu.bmp'),imread('picture/cpyue.bmp'));
%因数字和字母比例不同。这里要修改
shuzizimu=duquszzm(imread('picture/0.bmp'),imread('picture/1.bmp'),imread('picture/2.bmp'),imread('picture/3.bmp'),imread('picture/4.bmp'),...
imread('picture/5.bmp'),imread('picture/6.bmp'),imread('picture/7.bmp'),imread('picture/8.bmp'),imread('picture/9.bmp'),...
imread('picture/10.bmp'),imread('picture/11.bmp'),imread('picture/12.bmp'),imread('picture/13.bmp'),imread('picture/14.bmp'),...
imread('picture/15.bmp'),imread('picture/16.bmp'),imread('picture/17.bmp'),imread('picture/18.bmp'),imread('picture/19.bmp'),...
imread('picture/20.bmp'),imread('picture/21.bmp'),imread('picture/22.bmp'),imread('picture/23.bmp'),imread('picture/24.bmp'),...
imread('picture/25.bmp'),imread('picture/26.bmp'),imread('picture/27.bmp'),imread('picture/28.bmp'),imread('picture/29.bmp'),...
imread('picture/30.bmp'),imread('picture/31.bmp'),imread('picture/32.bmp'),imread('picture/33.bmp'));
zimu = duquzimu(imread('picture/10.bmp'),imread('picture/11.bmp'),imread('picture/12.bmp'),imread('picture/13.bmp'),imread('picture/14.bmp'),...
imread('picture/15.bmp'),imread('picture/16.bmp'),imread('picture/17.bmp'),imread('picture/18.bmp'),imread('picture/19.bmp'),...
imread('picture/20.bmp'),imread('picture/21.bmp'),imread('picture/22.bmp'),imread('picture/23.bmp'),imread('picture/24.bmp'),...
imread('picture/25.bmp'),imread('picture/26.bmp'),imread('picture/27.bmp'),imread('picture/28.bmp'),imread('picture/29.bmp'),...
imread('picture/30.bmp'),imread('picture/31.bmp'),imread('picture/32.bmp'),imread('picture/33.bmp'));
shuzi = duqushuzi(imread('picture/0.bmp'),imread('picture/1.bmp'),imread('picture/2.bmp'),imread('picture/3.bmp'),imread('picture/4.bmp'),...
imread('picture/5.bmp'),imread('picture/6.bmp'),imread('picture/7.bmp'),imread('picture/8.bmp'),imread('picture/9.bmp'));
%============================识别结果================================
i=1;%shibiezm_sz该函数识别数字有问题
jieguohanzi = shibiehanzi(hanzishengfen,xiuzhenghanzi);shibiejieguo(1,i) =jieguohanzi; i=i+1;
jieguozimu = shibiezimu(zimu,xiuzhengzimu); shibiejieguo(1,i) =jieguozimu; i=i+1;
jieguozm_sz_1= shibiezm_sz(shuzizimu,xiuzhengzm_sz_1); shibiejieguo(1,i) =jieguozm_sz_1;i=i+1;
jieguozm_sz_2= shibiezm_sz(shuzizimu,xiuzhengzm_sz_2); shibiejieguo(1,i) =jieguozm_sz_2;i=i+1;
jieguoshuzi_1= shibieshuzi(shuzi,xiuzhengshuzi_1); shibiejieguo(1,i) =jieguoshuzi_1;i=i+1;
jieguoshuzi_2= shibieshuzi(shuzi,xiuzhengshuzi_2); shibiejieguo(1,i) =jieguoshuzi_2;i=i+1;
jieguoshuzi_3= shibieshuzi(shuzi,xiuzhengshuzi_3); shibiejieguo(1,i) =jieguoshuzi_3;i=i+1;
%==========================对话框显示显示=============================================
set(handles.Result,'String', shibiejieguo);
handles.shibiejieguo=shibiejieguo;
guidata(hObject,handles);
% --- Executes on button press in CarVoide.
function CarVoide_Callback(hObject, eventdata, handles)
duchushengyin(handles.shibiejieguo);
% --- Executes on button press in CNNbut.
function CNNbut_Callback(hObject, eventdata, handles)

完整代码或者仿真咨询添加QQ2449341593
以上是关于卷积神经网络CNN在图像识别问题应用综述(20191219)的主要内容,如果未能解决你的问题,请参考以下文章