机器学习-NLP之Word embedding 原理及应用
Posted tangxiaobo199181
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-NLP之Word embedding 原理及应用相关的知识,希望对你有一定的参考价值。
- 概述
自然语言是非常复杂多变的,计算机也不认识咱们的语言,那么咱们如何让咱们的计算机学习咱们的语言呢?首先肯定得对咱们的所有文字进行编码吧,那咱们很多小伙伴肯定立马就想出了这还不简单嘛,咱们的计算机不都是ASCII编码的嘛,咱直接拿来用不就好啦?我只能说too young too simple。咱们的计算机只是对咱们的“字母”进行ASCII编码,并没有对咱们的“Word”编码。world应该是咱们处理自然语言的最基本的元素,而不是字母。那么世界上有千千万万的Word,咱们具体怎么表示呢?就算找出了一种方式来表示每一个Word,那么这些Word之间的关系如何来表示,毕竟有些词汇在某种维度上是比较相似的,有些词汇在某些维度上的距离则是比较远的,那么咱们如何还找到他们的关系呢?还有一个问题就是咱们如何通过咱们的text corpus(training dataset)来最终来学习咱们的模型呢?等等这些问题都是咱们NLP的内容的最基础也是最根本的问题。这一节主要就是解决这些问题的。
- One-hot encoding Word Representation
首先咱们来看咱们如何在机器学习系统中表示咱们的词汇,这里呢先说答案,那就是有两种方式,一种就是One-hot encoding, 另外一种就是 Featured representation (word embedding)。首先咱们来看一下One-hot encoding,它是咱们定义的长度固定的vocabulary中赋予每一个Word一个index,例如vocabulary的长度是10000,其中“cat”的index是3202,那么咱们对于cat的表示方式就是[0,0,0,0,..........1.........,0], 其中只在3202的位置是1,其他的9999个位置都是0. 咱们也可以结合下面的图片来更加直观的展示一下Word的one-hot encoding。

上面的图片是不是一目了然了什么是Word的one-hot encoding呢?那么问题来了?这种方式的representation有没有什么缺点是避免不了的以至于咱们必须得用Word Embedding呢?当然有啦,其实one-hot encoding的主要的缺点主要有2个:第一个大家主要到没有,one-hot encoding表示的方式是非常sparse的,每一个Word都必须要有更vocabulary长度一样多的元素element,而且这些element绝大多是都是0,这是非常浪费资源的一种方式;第二个问题就更加严重了,那就是用one-hot encoding 的方式表示Word的话,那么所用的Word之间都是没有任何联系的,任何两个Word之间的cosin值cos(word1,word2)都是0,这显然是很不符合咱们的实际情况的,例如实际中cat和dog之间关系总是要比cat和book之间的关系要更加紧密才对啊,可是在one-hot encoding中cos(cat, dog) == cos(cat, book) ==0,表示它们之间的关系都是一样的,这显然不符合咱们的实际情况。
- Featured representation - word embedding
Word embedding 应该是咱们整个NLP中最最常用的一个技术点了,它的核心思想就是每一个Word都有一些维度,具体有多少维度咱们用户自己定义,但是这些维度能保证相似的词汇在这个多维的空间上的值是相似的,例如咱们用5维的空间来表示一个词,那么cat可能是[1.0, 1.5, 0.0, 6.4, 0.0], dog可能是[0.95, 1.2, 0.11, 5.5, 0.0], book可能的值是[9.5, 0.0, 3.4, 0.3, 6.2]。从前面的几个值咱们可以很显然的看出cat和dog在这个五维空间是比较接近的,而他们跟book则在这个五维空间上的距离要远的多,这也更加符合咱们的实际情况的认知,那么具体这个五维空间的每一个feature是什么,咱们不需要知道,在后面的部分我会介绍2红算法来计算embedding的。那么下面就接着上面的例子,我画一个图片更加方便大家的理解
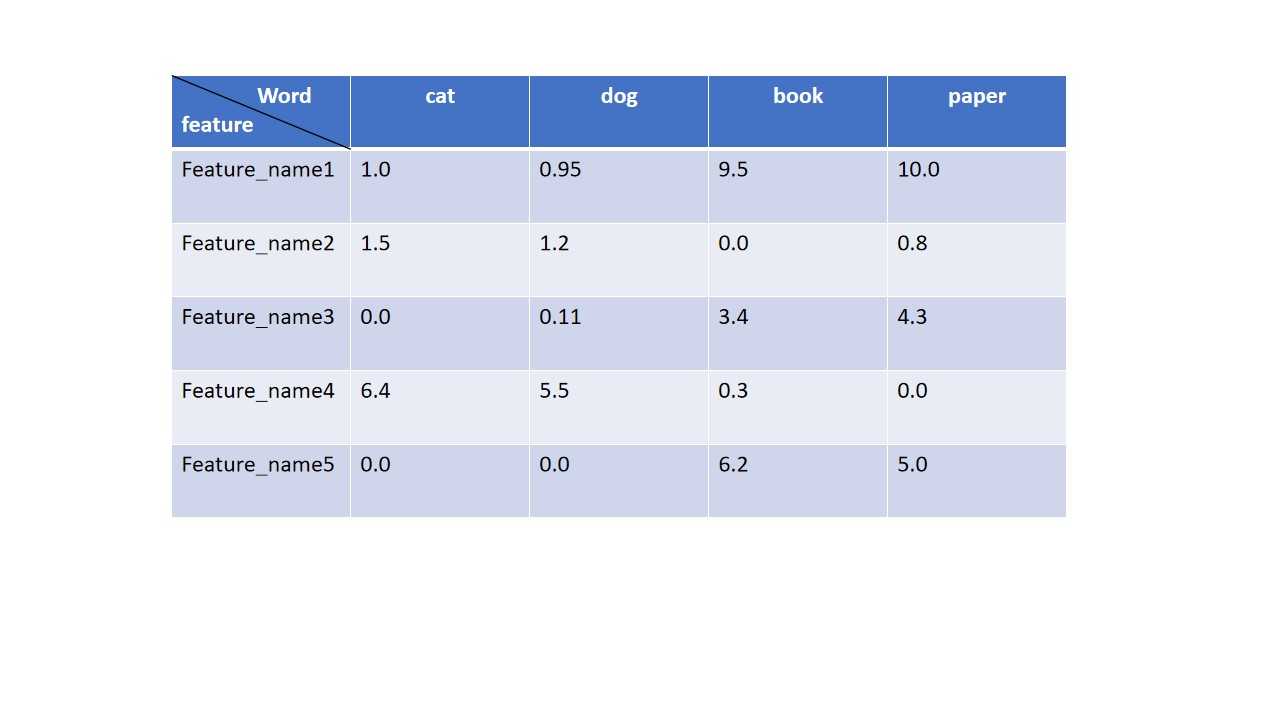
上面的这个图片就是对咱们上面的例子的一个简单的embedding的展示,大家现在不必纠结上面这些数据是怎么来的,大家只需要知道embedding的展现形式和意思就行了。还有一个大家也不需要被多维空间这个词给吓到了,其实就把它当做是多个features的就行,超过三维的数据咱们肉眼是无法通过形象的图像展示的,所以你也不用费神在脑子里面想象多维数据是啥样子了,你就把它看成多个features多个特征就行,至少每一个物体都有很多特性的,例如人有身高,体重,肤色,性别等等等很多的特性。然后咱们还有一个算法就是T-SNE算法可以将咱们多维的数据转化成2维数据给展示出来,大家稍微知道有这么个东西就行,无需深究。
- Embedding - Neural Network NLP modeling
首先咱们介绍第一个计算embedding的算法,那就是通过传统的Neural Network来学习训练咱们的embedding和neural network本身的参数的。那么咱们来看一下它的具体流程,在正式介绍之前咱们展示一下它的流程图,然后在来解释,毕竟这种方式要容易理解的多,咱们的大脑处理图片的速度还是要比文字快的多滴。。。。。
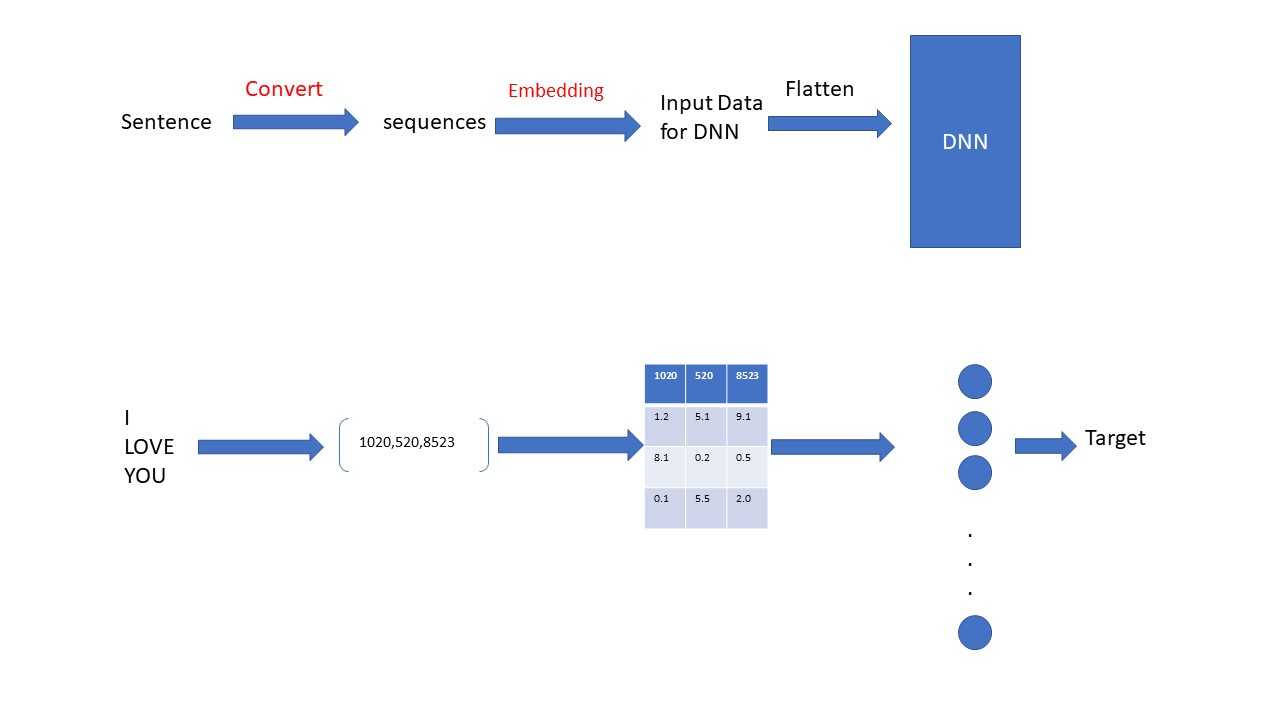
上面的图片我不但展示了用DNN的方式来求Embedding的流程并且应用这个embedding来训练model的流程,同时我还配了一个例子来解释这个流程。这个过程中,大家一定要注意的一点就是这里的Embedding 即作为这个模型的Input data,同时也是作为这个模型的parameters来不断学习更新的。 那么咱们现在就来解释这个模型学习的流程吧,首先第一步将咱们的语言sentence通过encoding的方式转成sequences, 具体这个过程是如何实现的呢?其实是想根据咱们的语义集(text corpus)生成tokenizer, 然后用这个tokenizer来做encoding的工作,具体的代码我会在最后的应用部分展示。然后第二步咱们来到咱们的embedding中找到前面sequences相对应的数据,并且将这些数据提出来,这里的embedding咱们根据用户自定义它有多少个words多少个维度,然后这个embedding会随机初始化一些数据出来;第三步咱们将咱们前面从embedding中提取出来的数据进行flatten处理,以便于咱们将数据feed到后面的DNN中;最后一步就是咱们的DNN训练的过程,在这个训练的过程中,咱们不但会训练DNN自己的paramets,它同时会训练并且更新前面从embedding中提取的数据。那么这个流程就是咱们用DNN的方式来计算embedding的方式。上面的I LOVE YOU在这里叫做context words, 用上面的方式来计算并且训练embedding的时候,咱们的context words的数量一定得是固定的,否则咱们没办法flatten咱们的数据feed到同一个neural network(因为同一个neural network的input layer的units是固定的)。同时具体要选择几个context words也是随便用户自己定义的,但是一旦选定了context words,则后面的context words必须要遵循前面的规则,规则必须一致。例如咱们即可以选择target的前4个words作为context words, 也可以选择target前面的2个words作为context words,甚至可以选择target的后2个数据作为context words。但是一旦选择了,后面就必须一致。当然了,如果咱们data中的context words的长度不够,咱们可以通过padded的方式补齐。
- Embedding - Skip-Grams
还有一种常用的embedding的算法,那就是应用Skip-Gram算法来计算咱们的embedding和模型。那么到底它是如何工作的呢?首先咱们还是先看一下这个算法的流程图,然后咱们详细解释一下流程哈
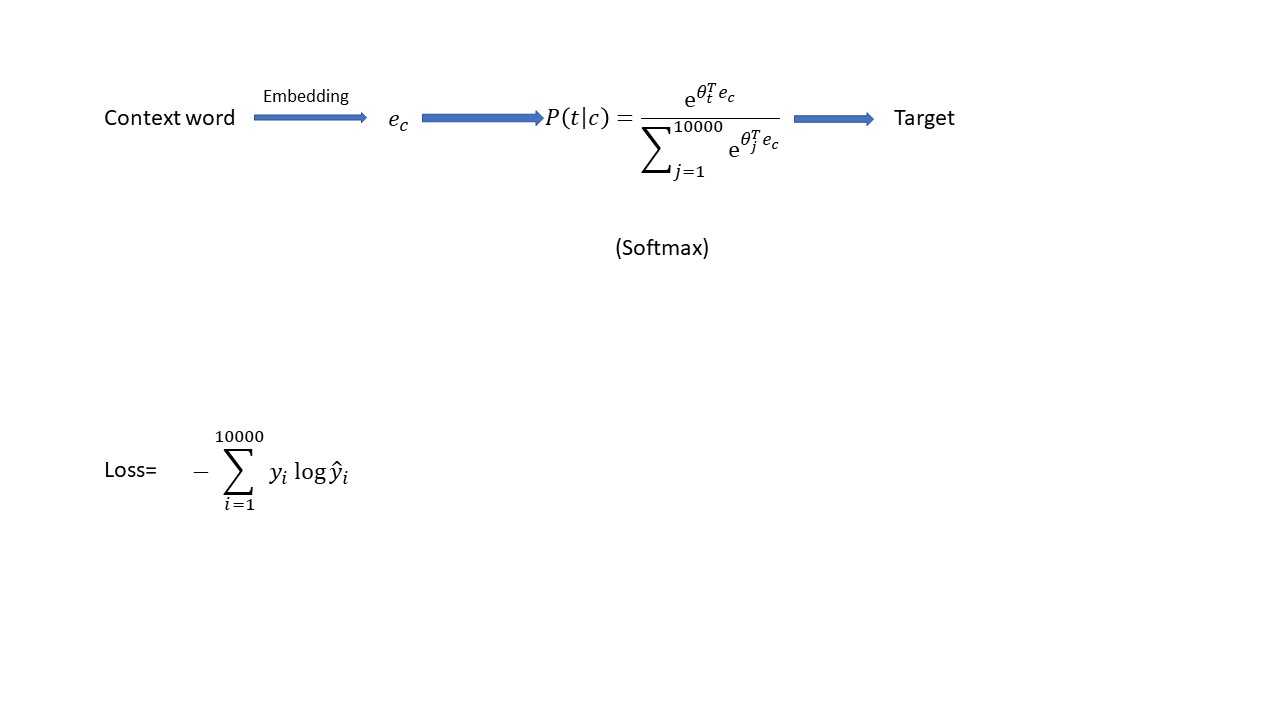
咱们的skip-gram的算法,首先第一步是咱们在training data(text corpus)中的的sentence中任意选择一个Word作为context Word;其次在咱们初始化的embedding中找到这个context Word对应的值ec,然后将咱们的ec 值带入到咱们的softmax model中,softmax会计算咱们vocabulary所有的词汇的概率,然后选择概率最大的那个Word就是咱们根据这个模型选择出来的target Word。上面是咱们应用skip-Grams的步骤,实际中的softmax model中的参数还有embedding是咱们通过上图中的Loss函数的gradient descent来不断的学习出来的。在这个算法中同样的embedding即作为咱们softmax模型的input data同时也作为咱们softmax模型的参数parameter。这里面的关系容易混淆啊,上图的softmax模型P(t|c)是咱们定义的模型,这个模型里面的参数和embedding是通过上图中的Loss函数不断的gradient descent得来的,咱们的training data是在咱们的text corpus中的每一行sentence中随机选择出来的一个context Word和在这个context Word前后一定范围内随机选择的一个target Word。这就是这个Skip-Grams算法的核心,当然啦,如果要实践这个算法,里面还有很多的细节需要处理的,但是这里面最核心的思想就是上面提到的步骤了。但是这个算法也有一个致命的弱点,那就是,这个算法需要大量的运算,咱们每走一个gradient descent,咱们就得计算出咱们所有的10000个words的值,实际中咱们word可能还远远不止10000个,可能是百万都有可能。
- TensorFlow应用之Embedding (Text sentiment analysis)
上面说了半天的理论内容,着实有点无聊,现在咱们来看看如何用TensorFlow来用Embedding吧,虽然上面的理论内容很枯燥无聊,但其实还是很重要的,一来咱们偶尔可以装B用,二来如果你不理解上面的理论,咱们在应用的时候你连参数都不知道怎么调,你怎么去优化你的模型啊??所以啊,这一块还是有必要理解一下滴。好了,那咱们就来看一个用TensorFlow应用embedding的例子,假设咱们的需求是判断大家对一部电影的review是好还是坏。谷歌自带的dataset中给了咱们这些数据,咱们可以直接下载下来直接用的。这一个例子其实也是咱们的NLP中常用的一个场景叫做text sentiment analysis。好吧, 那咱们开始吧。
第一步:加载咱们的数据
import tensorflow as tf import tensorflow_datasets as tfds import numpy as np imdb,info = tfds.load("imdb_reviews",with_info=True,as_supervised=True) train_data = imdb["train"] test_data = imdb["test"]
这一步很简单,就是直接从咱们的谷歌的tfds中加载movie reviews的数据。
第二步:将dataset从TensorFlow中的数据对象转成Python list并且分割出features 和 labels。
training_sentences = [] training_labels = [] test_sentences = [] test_labels = [] for s,l in train_data: training_sentences.append(str(s.numpy())) training_labels.append(l.numpy()) for s,l in test_data: test_sentences.append(str(s.numpy())) test_labels.append(l.numpy())
上面的代码是遍历了咱们training dataset和test dataset中的数据,并且把它们加载到Python中的list,同时将咱们数据中的features和labels分开。这一步算是数据准备阶段, 接下来就是咱们来配置咱们的tokenizer参数的时候了
第三部:配置tokenizer信息
from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences max_length = 120 trunc_type="post" oov_tok = "<OOV>" #initialize a tokenizer tokenizer = Tokenizer(num_words = vocab_size,oov_token = oov_tok) #fit the text to create word index, result a dict of the word:index key-values tokenizer.fit_on_texts(training_sentences) word_index = tokenizer.word_index #create a sequences of the training sentences based on the dictionary above(word-index) training_sequences = tokenizer.texts_to_sequences(training_sentences) #pad the sequences training_padded_sequences = pad_sequences(training_sequences,maxlen=max_length,truncating=trunc_type) #create a sequences of the test sentences based on the dictionary above(word-index) test_sequences = tokenizer.texts_to_sequences(test_sentences) #pad the sequences test_padded_sequences = pad_sequences(test_sequences,maxlen=max_length,truncating=trunc_type)
这一步的主要功能是讲咱们上面得到的原始的data(text)转化成咱们的计算机熟悉的数字格式,从而每一个句子都是一个数字的sequence。其实就是encoding的过程,首先把咱们上面的training_sentences中所有出现的Word都赋予一个数字,这一步是通过fit_on_texts()函数来实现的,这一步咱们生成了一个dict对象word_index, 这个dict将training_sentences中出现的每一个Word(不重复)作为key, 每一个Word都对应一个value(不重复)。接下来第二步就是通过texts_to_sequences()这个函数,将咱们的所有的sentence都根据上面的word_index来一一对应从text转化成数字的sequence。上面的代码主要就是这两个功能,整个过程,咱们称之为encoding。这里有一个小细节,那就是咱们在配置tokenizer的时候设置了一个oov_tok参数,这个参数是干什么的呢?咱们虽然根据traininig dataset编码了很多的word, 但是实际中总有一些词是咱们training dataset中没有出现过的,那么这种情况下,咱们就需要一个out-of-value (oov)来表示这些未见过的word啦,所以这里咱们就配置了oov_tok = "<oov>", 就是一旦将来遇到了生词,咱们一致用“<oov>”这个词表示,并且它在咱们的word_index中也有键值对,一般情况下,它个value是1。还有一个细节就是pad_sequences()函数,因为咱们的text的长度是不一样的,为了保证将来能正确的feed到咱们的DNN中,它们的长度必须一样长,这时候咱们就得用到pad技术了,他会将咱们所用的text同补充到max_length那么长。
第四步:配置神经网络和embedding
这一步就是咱们的核心部分了,那就是配置咱们的embedding信息和咱们的DNN网络
vocab_size = 10000 embedding_dim = 16 #define model structure model = tf.keras.Sequential([ tf.keras.layers.Embedding(vocab_size,embedding_dim,input_length=max_length), tf.keras.layers.Flatten(), tf.keras.layers.Dense(64,activation="relu"), tf.keras.layers.Dense(1,activation="sigmoid") ]) model.compile(loss="binary_crossentropy",optimizer="Adam",metrics=["accuracy"]) model.summary()
上面的embedding咱们配置的是一个10000长度,16个维度的embedding,这个embedding里面每一个Word都有16个维度。因为咱们的是一个binary classification的问题,output layer只有一个node,并且activation是sigmoid。通过summary()函数咱们看一下咱们的整个的网络结构
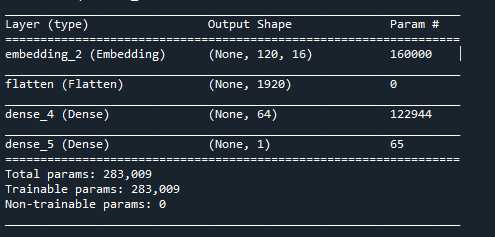
上面可以完整的看到咱们定义的网络结构和一些参数。
第五步:train model
咱们既然已经有了复合格式的数据,也定义了咱们的模型,那么接下来咱们就用咱们的数据来训练咱们的模型了
#training the model model.fit( training_padded_sequences, training_labels_final, epochs=10, validation_data=(test_padded_sequences,test_labels_final) )
这一步跟前面章节讲个训练过程一模一样,也很简单这里就不细讲了。上面五个步骤之后,咱们已经训练好了咱们模型了,也是咱们在遇到text sentiment analysis这一类问题的主要流程,就是从数据加载,encoding,模型定义和训练这几个步骤。
以上是关于机器学习-NLP之Word embedding 原理及应用的主要内容,如果未能解决你的问题,请参考以下文章
预训练在自然语言处理的发展: 从Word Embedding到BERT模型
DeepNLP的核心关键/NLP语言模型 /词的分布式表示/word embedding/word2vec
Embeddings from Language Models(ELMo)
Embeddings from Language Models(ELMo)